《花100块做个摸鱼小网站! 》第九篇—我的小网站被攻击了!
⭐️基础链接导航⭐️
服务器 → ☁️ 阿里云活动地址
看样例 → 🐟 摸鱼小网站地址
学代码 → 💻 源码库地址
一、前言
大家好呀,我是summo,最近不是被裁员了嘛,找工作又难找,老是心烦意乱的,也导致了一个多月断更,不好意思哈。虽然工作没了,但是小网站的故事却一直在发生,比如阿里云RDS到期导致我的小网站崩了一个月(已经修复);比如我重构了一下设计和代码(代码已上传Gitee);比如有些“好心人”刷我的接口,给我提高访问量(本篇会讲的故事)... ...
还有一些更有意思的,比如济南有位老板看中了我的小网站希望我可以根据他的一些需求进行二次开发(一期已经做好上线了);比如通过这个小网站让我赚到1千多的外快(意外之喜)等等。
工作是一时的,兴趣是一辈子的,无论如何,从今天开始,我会继续更新小网站的故事,这一篇主题:我的小网站被攻击了!
二、被攻击的过程
在我小网站的右侧有一块访问统计的展示,显示着今日PV,今天UV、总PV和总UV(PV:页面浏览量,访问一次我加一次;UV:独立访客数,一个IP我算一个),如下图:

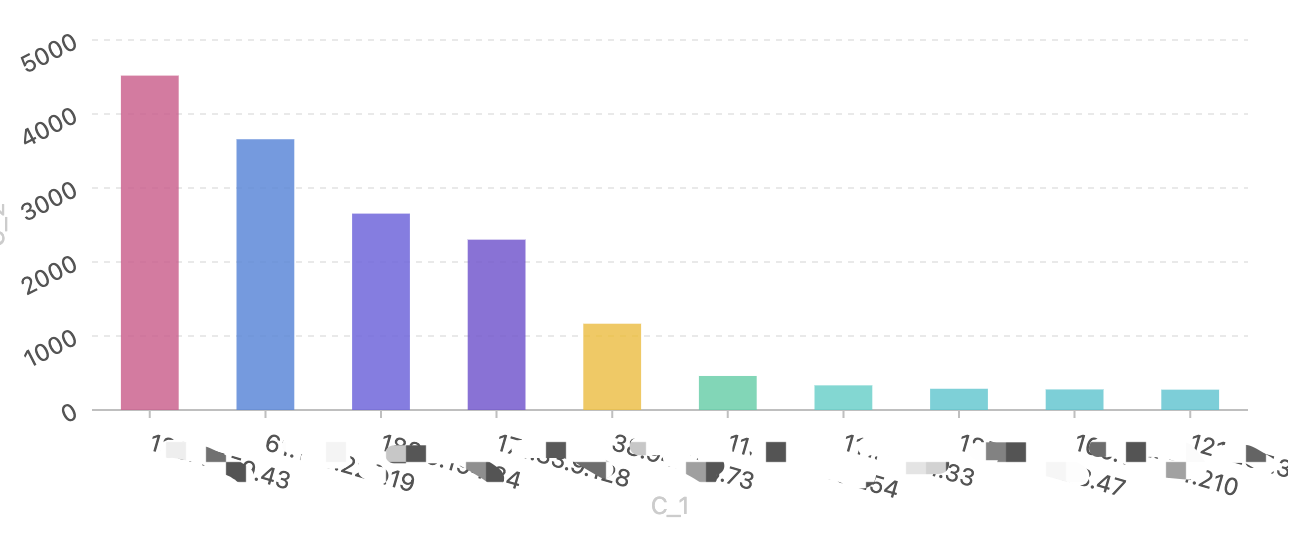
这是2024-11-22截的图,总UV才2W多,但是PV已经8W多了,相当于每个用户平均访问了小网站4次,虽然看起来也不算很离谱,但实际上有几个“好心人”单独就贡献了1.5W次的访问,如下图:
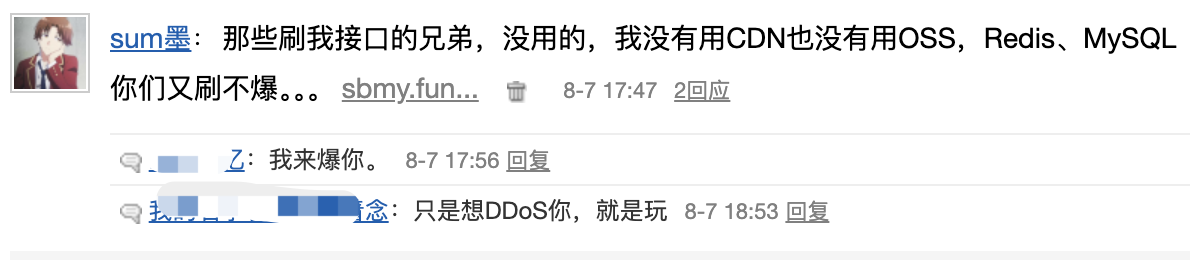
至于他们为什么攻击我,跟我也是有很大关系,我曾经在博客园的闪存“大放厥词”:
三、小网站的统计规则
之前我们在第七篇—谁访问了我们的网站?中介绍了小网站的统计逻辑,核心逻辑就是加了一个@VisitLog注解,使用切面的方式记录访问的IP地址。然后将这个注解放在了IndexController.java的index方法上,如下:
@Controller
public class IndexController {
@GetMapping("/")
@VisitLog
public String index(HttpServletRequest request) {
if (isFromMobile(request)) {
return "mp/index";
} else {
return "web/index";
}
}
}
也就是说,只要你们疯狂调用https://sbmy.fun,就会不断地增加访问记录。正如我前面所说的我并没有使用CDN、OSS这种按按流量计费的组件,无论你们怎么刷都是不会给我造成资损的,但是有一个问题我不得不处理一下:
前端的资源来自于我的应用,资源包括js、css、图片、字体等文件,这些资源还都不小,尤其是chunk-vendors.js,体积达到了1.2M,如下图:
阿里云的ECS公网IP带宽默认只有3M,也就是说小网站同时有三个人访问就会出现访问效率问题,问题其实也不大,浏览器只要访问一次这些资源就会将它们缓存下来,后续再刷新也不会很慢。但是如果被攻击了呢,那就麻烦了,正常用户想访问都不行了... ... 所以我必须得想个法子了。

四、限流大法好
像我们这种小网站,流量也不大,被攻击了好像也没啥意义,有些攻击纯粹就是兄弟们开的玩笑,搞着玩的。但既然兄弟们出招了,我这边也得想个法子解决不是?其实很简单,搞个滑动窗口限流就可以了。
我先讲一下什么是限流,王者荣耀大家都玩过吧,里面的英雄都有一个攻击间隔,当我们连续的点击普通攻击的时候,英雄的攻速并不会随着我们点击的越快而更快的攻击。这个就是限流,英雄会按照自身攻速的系数执行攻击,我们点的再快也没用。
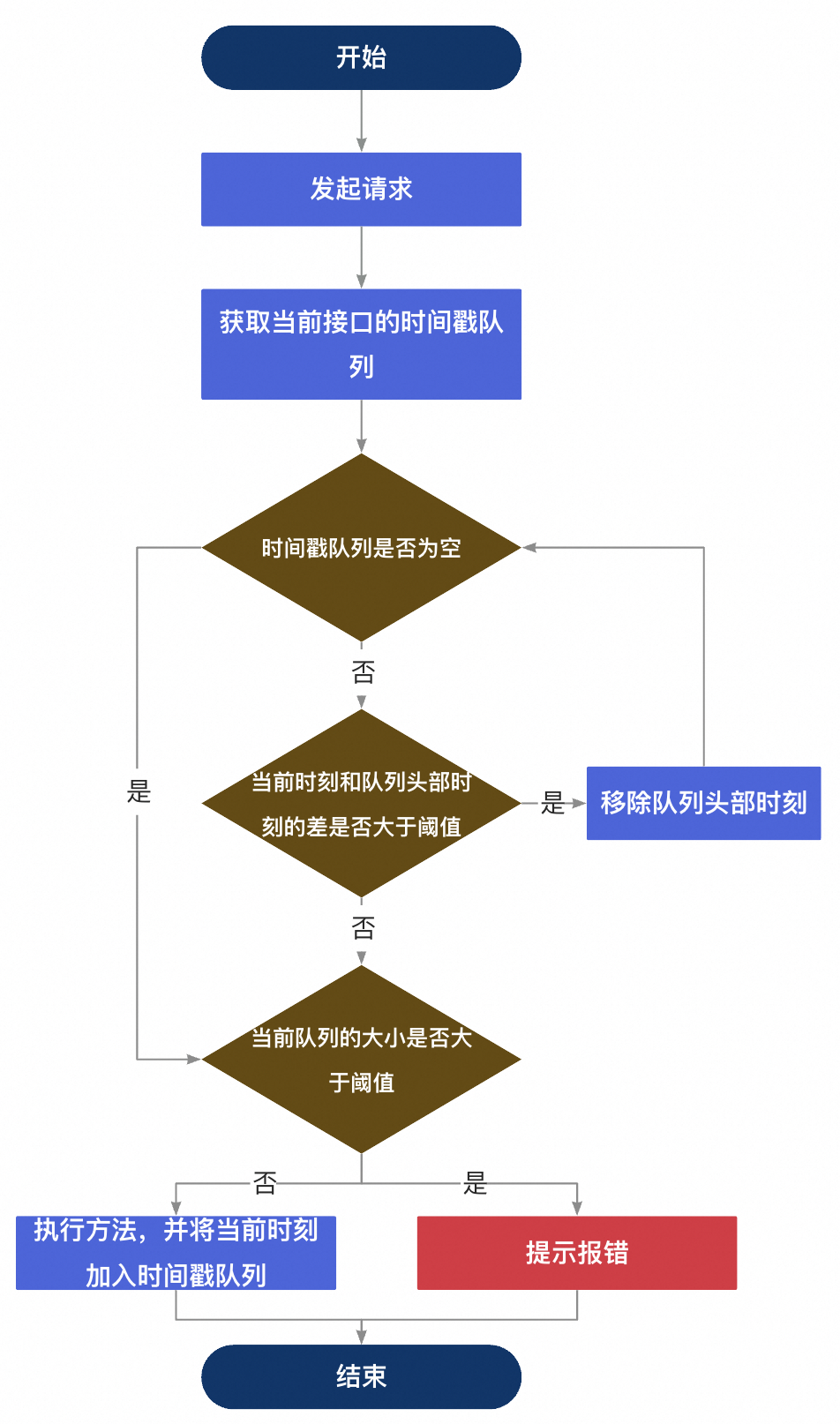
1、滑动窗口限流
先上一张流程图,帮助大家理解原理
2、原理说明
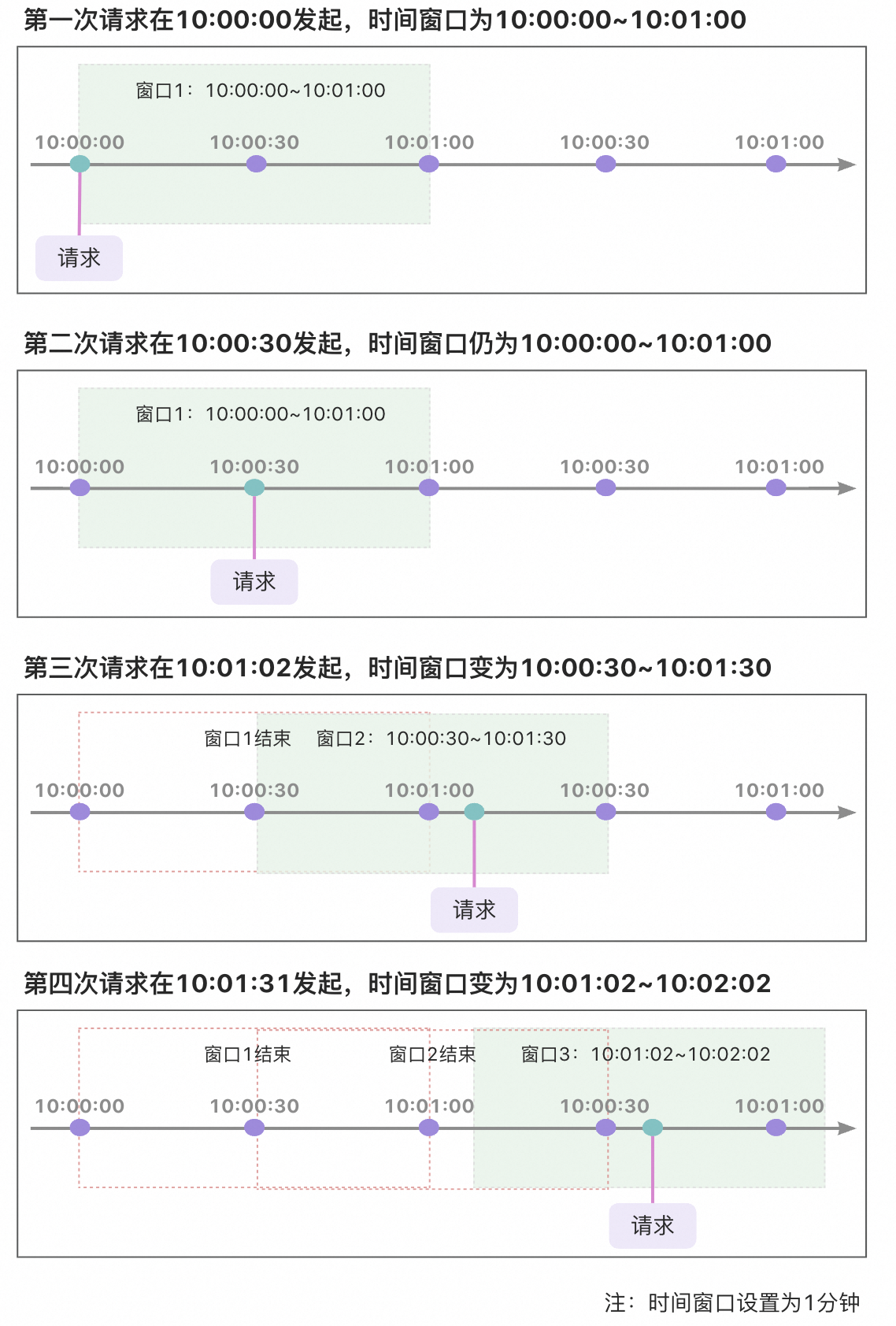
从图上可以看到时间创建是一种滑动的方式前进, 滑动窗口限流策略能够显著减少临界问题的影响,但并不能完全消除它。滑动窗口通过跟踪和限制在一个连续的时间窗口内的请求来工作。与简单的计数器方法不同,它不是在窗口结束时突然重置计数器,而是根据时间的推移逐渐地移除窗口中的旧请求,添加新的请求。
举个例子:假设时间窗口为10s,请求限制为3,第一次请求在10:00:00发起,第二次在10:00:05发起,第三次10:00:11发起,那么计数器策略的下一个窗口开始时间是10:00:11,而滑动窗口是10:00:05。所以这也是滑动窗口为什么可以减少临界问题的影响,但并不能完全消除它的原因。
如果大家想详细了解一些常用的限流算法,可以看我这篇文章:《优化接口设计的思路》系列:第七篇—接口限流策略。
3、代码实现
SlidingWindowRateLimit.java
package com.summo.demo.config.limitstrategy.slidingwindow;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
public @interface SlidingWindowRateLimit {
/**
* 请求的数量
*
* @return
*/
int requests();
/**
* 时间窗口,单位为秒
*
* @return
*/
int timeWindow();
}
SlidingWindowRateLimitAspect.java
package com.summo.sbmy.common.limit.slidingwindow;
import com.summo.sbmy.common.util.HttpContextUtil;
import com.summo.sbmy.common.util.IpUtil;
import lombok.extern.slf4j.Slf4j;
import org.aspectj.lang.ProceedingJoinPoint;
import org.aspectj.lang.annotation.Around;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.reflect.MethodSignature;
import org.springframework.core.annotation.Order;
import org.springframework.stereotype.Component;
import java.lang.reflect.Method;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.ConcurrentLinkedQueue;
import java.util.concurrent.TimeUnit;
@Slf4j
@Aspect
@Component
@Order(5)
public class SlidingWindowRateLimitAspect {
/**
* 使用 ConcurrentHashMap 保存每个方法的请求时间戳队列
*/
private final ConcurrentHashMap<String, ConcurrentHashMap<String, ConcurrentLinkedQueue<Long>>> METHOD_IP_REQUEST_TIMES_MAP = new ConcurrentHashMap<>();
@Around("@annotation(com.summo.sbmy.common.limit.slidingwindow.SlidingWindowRateLimit)")
public Object rateLimit(ProceedingJoinPoint joinPoint) throws Throwable {
MethodSignature signature = (MethodSignature) joinPoint.getSignature();
Method method = signature.getMethod();
// 获取客户端IP地址
String clientIp = IpUtil.getIpAddr(HttpContextUtil.getHttpServletRequest());
SlidingWindowRateLimit rateLimit = method.getAnnotation(SlidingWindowRateLimit.class);
// 允许的最大请求数
int requests = rateLimit.requests();
// 滑动窗口的大小(秒)
int timeWindow = rateLimit.timeWindow();
// 获取方法名称字符串
String methodName = method.toString();
// 如果不存在当前方法和IP的请求时间戳队列,则初始化一个新的队列
ConcurrentHashMap<String, ConcurrentLinkedQueue<Long>> ipRequestTimesMap = METHOD_IP_REQUEST_TIMES_MAP.computeIfAbsent(methodName, k -> new ConcurrentHashMap<>());
ConcurrentLinkedQueue<Long> requestTimes = ipRequestTimesMap.computeIfAbsent(clientIp, k -> new ConcurrentLinkedQueue<>());
// 当前时间
long currentTime = System.currentTimeMillis();
// 计算时间窗口的开始时间戳
long thresholdTime = currentTime - TimeUnit.SECONDS.toMillis(timeWindow);
// 这一段代码是滑动窗口限流算法中的关键部分,其功能是移除当前滑动窗口之前的请求时间戳。这样做是为了确保窗口内只保留最近时间段内的请求记录。
// requestTimes.isEmpty() 是检查队列是否为空的条件。如果队列为空,则意味着没有任何请求记录,不需要进行移除操作。
// requestTimes.peek() < thresholdTime 是检查队列头部的时间戳是否早于滑动窗口的开始时间。如果是,说明这个时间戳已经不在当前的时间窗口内,应当被移除。
while (!requestTimes.isEmpty() && requestTimes.peek() < thresholdTime) {
// 移除队列头部的过期时间戳
requestTimes.poll();
}
// 检查当前时间窗口内的请求次数是否超过限制
if (requestTimes.size() < requests) {
// 未超过限制,记录当前请求时间
requestTimes.add(currentTime);
return joinPoint.proceed();
} else {
// 超过限制,抛出限流异常
throw new RuntimeException("Too many requests, please try again later.");
}
}
}
使用方式
@Controller
public class IndexController {
@GetMapping("/")
@VisitLog
@SlidingWindowRateLimit(requests = 2, timeWindow = 2)
public String index(HttpServletRequest request) {
if (isFromMobile(request)) {
return "mp/index";
} else {
return "web/index";
}
}
}
五、小结一下
上面的限流使用的是ConcurrentHashMap来存储每个方法的请求时间戳队列,适用于单机,如果是分布式的环境则可以换成Redis。通过在资源接口上加一个限流的方式我们可以防止单个IP刷爆我们的index接口,防止带宽打满,我试了下应该是用的,就是不知道实战如何。
番外:腾讯热搜爬虫
1. 爬虫方案评估
腾讯热搜的接口返回的是json串,这个最简单,只需要取值就行了。
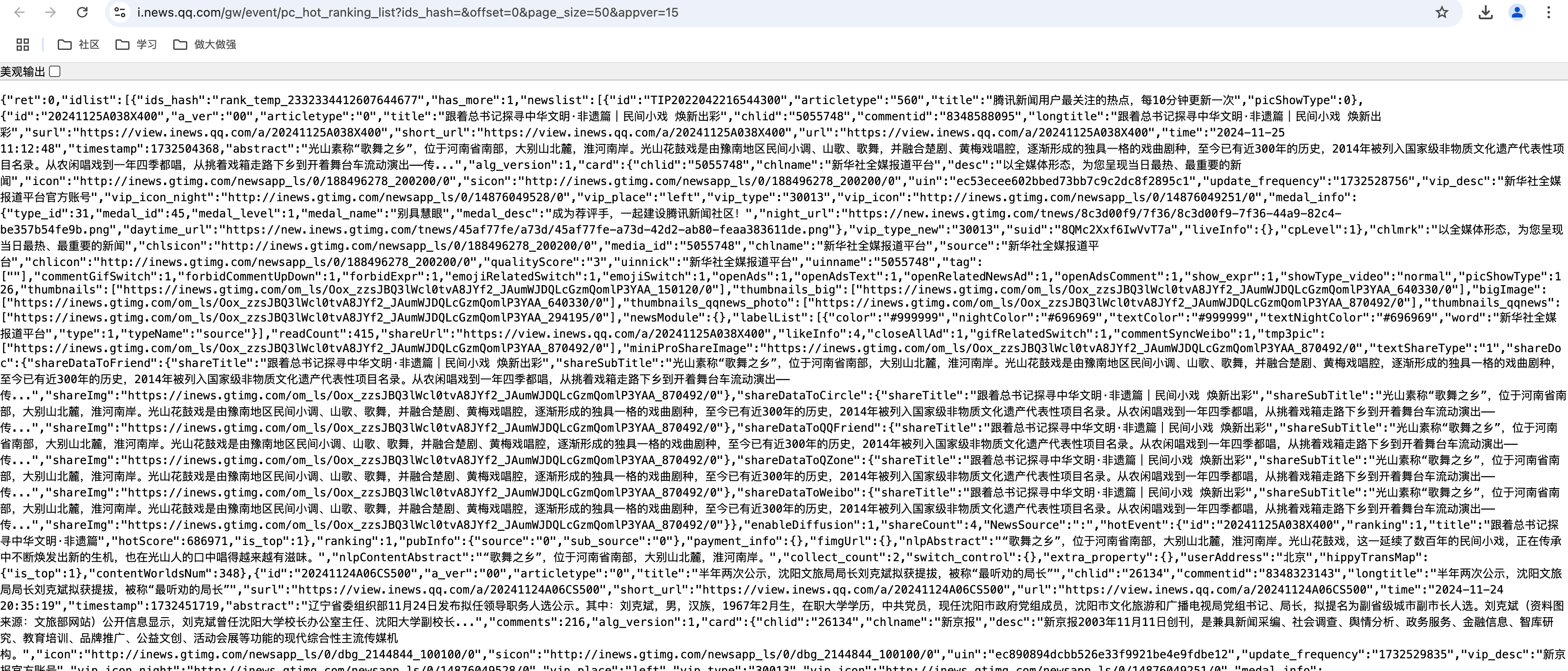
2. 网页解析代码
TencentHotSearchJob.java
package com.summo.sbmy.job.tencent;
import com.alibaba.fastjson.JSONArray;
import com.alibaba.fastjson.JSONObject;
import com.google.common.collect.Lists;
import com.summo.sbmy.common.model.dto.HotSearchDetailDTO;
import com.summo.sbmy.dao.entity.SbmyHotSearchDO;
import com.summo.sbmy.service.SbmyHotSearchService;
import com.summo.sbmy.service.convert.HotSearchConvert;
import com.xxl.job.core.biz.model.ReturnT;
import com.xxl.job.core.handler.annotation.XxlJob;
import lombok.extern.slf4j.Slf4j;
import okhttp3.OkHttpClient;
import okhttp3.Request;
import okhttp3.Response;
import org.apache.commons.collections4.CollectionUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import javax.annotation.PostConstruct;
import java.io.IOException;
import java.util.Calendar;
import java.util.Comparator;
import java.util.List;
import java.util.concurrent.atomic.AtomicInteger;
import java.util.stream.Collectors;
import static com.summo.sbmy.cache.hotSearch.HotSearchCacheManager.CACHE_MAP;
import static com.summo.sbmy.common.enums.HotSearchEnum.TENCENT;
/**
* @author summo
* @version TencentHotSearchJob.java, 1.0.0
* @description 腾讯热搜Java爬虫代码
* @date 2024年08月09
*/
@Component
@Slf4j
public class TencentHotSearchJob {
@Autowired
private SbmyHotSearchService sbmyHotSearchService;
@XxlJob("tencentHotSearchJob")
public ReturnT<String> hotSearch(String param) throws IOException {
log.info("腾讯热搜爬虫任务开始");
try {
//查询腾讯新闻热搜数据
OkHttpClient client = new OkHttpClient().newBuilder().build();
Request request = new Request.Builder().url("https://i.news.qq.com/gw/event/pc_hot_ranking_list?ids_hash=&offset=0&page_size=50&appver=15" + ".5_qqnews_7.1.60&rank_id=hot").method("GET", null).build();
Response response = client.newCall(request).execute();
JSONObject jsonObject = JSONObject.parseObject(response.body().string());
JSONArray array = jsonObject.getJSONArray("idlist").getJSONObject(0).getJSONArray("newslist");
List<SbmyHotSearchDO> sbmyHotSearchDOList = Lists.newArrayList();
for (int i = 1, len = array.size(); i < len; i++) {
//获取腾讯热搜信息
JSONObject object = (JSONObject) array.get(i);
//构建热搜信息榜
SbmyHotSearchDO sbmyHotSearchDO = SbmyHotSearchDO.builder().hotSearchResource(TENCENT.getCode()).build();
//设置知乎三方ID
sbmyHotSearchDO.setHotSearchId(object.getString("id"));
//设置文章连接
sbmyHotSearchDO.setHotSearchUrl(object.getString("surl"));
//设置文章标题
sbmyHotSearchDO.setHotSearchTitle(object.getString("title"));
//设置作者名称
sbmyHotSearchDO.setHotSearchAuthor(object.getString("chlname"));
//设置文章封面
sbmyHotSearchDO.setHotSearchCover(object.getString("miniProShareImage"));
//热搜热度
sbmyHotSearchDO.setHotSearchHeat(object.getString("readCount"));
sbmyHotSearchDOList.add(sbmyHotSearchDO);
}
// 使用自定义的Comparator进行排序
AtomicInteger count = new AtomicInteger(1);
// 先判断是否为空,然后转换成数值进行比较,按照倒序排序,空值放在最后。
sbmyHotSearchDOList = sbmyHotSearchDOList.stream().sorted(Comparator.comparing((SbmyHotSearchDO hotSearch) -> hotSearch.getHotSearchHeat() != null).reversed().thenComparing(hotSearch -> {
try {
return Integer.parseInt(hotSearch.getHotSearchHeat());
} catch (NumberFormatException | NullPointerException e) {
// 将无法解析的字符串和空值视为最小值
return Integer.MIN_VALUE;
}
// 对解析的数值进行倒序排序
}, Comparator.reverseOrder())).map(sbmyHotSearchDO -> {
sbmyHotSearchDO.setHotSearchOrder(count.getAndIncrement());
return sbmyHotSearchDO;
}).collect(Collectors.toList());
if (CollectionUtils.isEmpty(sbmyHotSearchDOList)) {
return ReturnT.SUCCESS;
}
//数据加到缓存中
CACHE_MAP.put(TENCENT.getCode(), HotSearchDetailDTO.builder()
//热搜数据
.hotSearchDTOList(sbmyHotSearchDOList.stream().map(HotSearchConvert::toDTOWhenQuery).collect(Collectors.toList()))
//更新时间
.updateTime(Calendar.getInstance().getTime()).build());
//数据持久化
sbmyHotSearchService.saveCache2DB(sbmyHotSearchDOList);
log.info("腾讯热搜爬虫任务结束");
} catch (IOException e) {
log.error("获取腾讯数据异常", e);
}
return ReturnT.SUCCESS;
}
@PostConstruct
public void init() {
// 启动运行爬虫一次
try {
hotSearch(null);
} catch (IOException e) {
log.error("启动爬虫脚本失败", e);
}
}
}
本文来自博客园,作者:sum墨,转载请注明原文链接:https://www.cnblogs.com/wlovet/p/18558518

 浙公网安备 33010602011771号
浙公网安备 33010602011771号