
Linux内核分析_课程学习总结报告
请您根据本课程所学内容总结梳理出一个精简的Linux系统概念模型,最大程度统摄整顿本课程及相关的知识信息,模型应该是逻辑上可以运转的、自洽的,并举例某一两个具体例子(比如读写文件、分配内存、使用I/O驱动某个硬件等)纳入模型中验证模型。
谈谈您对课程的心得体会,改进建议等。
1.冯·诺依曼计算机体系中,操作系统的功能及必要性
冯·诺依曼体系结构计算机中,计算机分为五个部分:运算器、控制器、存储器、输入设备和输出设备,各个部分之间由总线相互连接。存储器负责存储计算所需的数据和程序指令,因为指令和数据都可以以二进制形式存储。该体系结构的工作流程是,程序和操作数通过输入设备从外界接收并存于存储器内。当计算机工作时,控制器和存储器之间通过一个名为程序计数器(PC)的寄存器而相互关联,该寄存器内存储将要执行的下一条指令的存储地址,控制器以次为依据通过总线与存储器交互,获取所需的指令内容,后解析指令,得知执行指令所需的操作数,再通过多种寻址策略从存储器中取得所需的操作数,交给运算器执行。最后根据指令的含义,将执行结果进行适当的处理,PC自增,执行下一条指令,循环此过程即可实现计算机自动执行大量指令。
说易行难。上述过程仅仅存在于一个抽象的理论框架,要想在现实中实现这一切需要解决很多问题。
首先第一个问题:用户怎样把程序和数据通过输入设备输入计算机内?换种说法,如何提供一种用户与计算机进行方便交互的接口?
第一个问题还引申出更为复杂的问题——当用户需要输入数据的时候,正赶上计算机正在运行其他程序,用户怎样进行输入才能使计算机正常运转不被干扰?
第三个问题:计算机硬件门类众多,用户编程需要经常调用底层各种硬件,极为复杂且不安全。如何解决此问题?是否可以考虑提供对底层调用的通用接口,解放用户编程中最危险的部分,将最麻烦且最危险的步骤交给计算机处理?
第四个问题:随着计算机应用领域的广泛以及需求愈加复杂,越来越多的情况下需要计算机及时处理突发状况。当计算机遇到紧急任务急需处理,如何安全地保留当前执行任务的现场,并且尽快转而处理更紧急的任务?
第五个问题:用户输入数据的速度远慢于CPU执行的速度,这导致大量时间被浪费在I/O操作上,工作效率极低。现在对计算机提出更高的要求:如何使计算机进行多任务+批处理?
第六个问题:程序和数据在存储器空间中不是随意存储的。如何管理存储器的存储空间,才能高效运行?
解决上述问题需要一个落于底层硬件上层,但是位于其他应用程序下层,负责和底层硬件进行多种交互的应用程序,也就是操作系统。
考虑上述问题,其中第问题二、三、四、五的本质都是一样的——如何让计算机在执行一任务的时刻转而执行另一任务。做到这一点的是中断机制。
此外,问题三的解决需要操作系统区分内核态与用户态,并利用系统调用机制。
问题五的解决需要引入进程与线程,并且解决进程间调度、通信、同步与防死锁的问题。
问题四涉及到实时操作系统的调度策略。
问题一的解决,需要操作系统为用户提供一套与计算机交互的接口,如shell命令接口;或者GUI图形界面。此外也需要操作系统提供文件管理+I/O设备管理机制。
问题六的解决,需要操作系统提供内存管理机制。
综上所述,操作系统的必要性体现在——
1.操作系统是计算机系统资源的管理者;
2.操作系统为用户与计算机硬件系统之间提供接口。
操作系统提供的功能包括:进程管理、内存管理、文件管理、I/O设备管理等。
2. 进程管理
2.1进程的描述
在操作系统原理中,我们通过进程控制块PCB描述进程。为了管理进程,内核要描述进程的结构,我们也称其为进程描述符,进程描述符直接或间接提供了进程相关的所有信息。
2.2 进程的状态

2.3 进程链表、进程的父子兄弟关系
2.4 进程的创建

库函数fork是⽤户态创建⼀个⼦进程的系统调⽤API接⼝。fork系统调⽤把当前进程⼜复制了⼀个⼦进程,也就⼀个进程变成了两个进程,两个进程执⾏相同的代码,只是fork系统调⽤在⽗进程和⼦进程中的返回值不同。
fork也是⼀个系统调⽤,和前述⼀般的系统调⽤执⾏过程⼤致是⼀样的。尤其从⽗进程的⻆度来看,fork的执⾏过程与前述描述完全⼀致。
fork系统调⽤创建了⼀个⼦进程,⼦进程复制了⽗进程中所有的进程信息,包括内核堆栈、进程描述符等,⼦进程作为⼀个独⽴的进程也会被调度,当⼦进程获得CPU开始运⾏时,它是从哪⾥开始运⾏的呢?从⽤户态空间来看,就是fork系统调⽤的下⼀条指令。但是,对于⼦进程来讲,fork系统调⽤在内核处理程序中是从何处开始执⾏的呢?
进程的创建过程⼤致是⽗进程通过fork系统调⽤进⼊内核_do_fork函数,采⽤写时复制技术复制进程描述符及相关进程资源、分配⼦进程的内核堆栈并对内核堆栈和thread等进程关键上下⽂进⾏初始化,最后将⼦进程放⼊就绪队列,fork系统调⽤返回;⽽⼦进程则在被调度执⾏时根据设置的内核堆栈和thread等进程关键上下⽂开始执⾏。
换种说法,fork和其他系统调⽤不同之处是它在陷⼊内核态之后有两次返回,第⼀次返回到原来的⽗进程的位置继续向下执⾏,这和其他的系统调⽤是⼀样的。在⼦进程中fork也返回了⼀次,会返回到⼀个特定的点——ret_from_fork。
2.5 可执行程序
程序从源代码到可执⾏⽂件的编译步骤⼤致分为:预处理、编译、汇编、链接。每一步对应的shell命令如下:

汇编后形成的.o格式的⽂件已经是ELF格式⽂件了。程序编译后⽣成的⽬标⽂件⾄少含有3个节区,分别为.text、.data和.bss。BSS段通常是指⽤来存放程序中未初始化的全局变量,该节不占用文件空间;数据段通常是指⽤来存放程序中已初始化的全局变量;代码段通常是指⽤来存放程序执⾏代码。
而最后一步链接,是将各种代码和数据部分收集起来并组合成为⼀个单⼀⽂件的过程,本质上是节的拼接。链接分为静态链接和动态链接两种,各有优劣。动态链接又分为装载时动态链接和运行时动态链接。一个可执行文件被装载入内存后执行,其实是调用了exec系统调用。
在内核⾥⾯⽤do_execve加载可执⾏⽂件,把当前进程的可执⾏程序给覆盖掉。当execve系统调⽤返回时,返回的已经不是原来的那个可执⾏程序了,⽽是新的可执⾏程序。execve返回的是新的可执⾏程序执⾏的起点。
2.6 进程调度时机
Linux内核通过schedule函数实现进程调度,调⽤schedule函数的时机主要分为两类:1、中断处理过程中的进程调度时机;2、内核线程主动调⽤schedule()。换种说法,进程调度时机就是内核调用schedule函数的时机,它包括两种情况:1、⽤户进程上下⽂中主动调⽤特定的系统调⽤进⼊中断上下⽂,系统调⽤返回⽤户态之前进⾏进程调度、或者内核线程或可中断的中断处理程序,执⾏过程中发⽣中断进⼊中断上下⽂,在中断返回前进⾏进程调度;2、内核线程主动调⽤schedule函数进⾏进程调度。
2.7 进程调度策略
包括先进先出FIFO,短距离作业优先算法,时间片调度等。
我们以在shell中输入ls命令为例,总结Linux系统的进程调度过程。
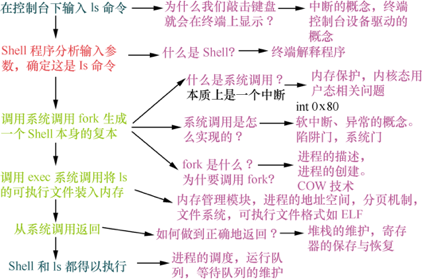
3.中断机制和系统调用
3.1 系统调用是一种特殊的中断
中断分外部中断(硬件中断)和内部中断(软件中断),内部中断⼜称为异常(Exception),异常⼜分为故障(fault)和陷阱(trap)。系统调⽤就是利⽤陷阱(trap)这种软件中断⽅式主动从⽤户态进⼊内核态的。⼀般来说,从⽤户态进⼊内核态是由中断触发的,可能是硬件中断,在⽤户态进程执⾏时,硬件中断信号到来,进⼊内核态,就会执⾏这个中断对应的中断服务例程。也可能是⽤户态程序执⾏过程中,调⽤了⼀个系统调⽤,陷⼊了内核态,叫作陷阱(trap)。所以,系统调⽤是特殊的中断。
此外,这里必须明确系统调用与普通的库函数API调用二者之间的区别。这二者间最明显的区别在于,系统调用会进入内核态,而库函数则未必。
3.2 系统调用的传参方式
系统调⽤从⽤户态切换到内核态,在⽤户态和内核态这两种执⾏模式下使⽤的是不同的堆栈,即进程的⽤户态堆栈和进程的内核态堆栈,传递参数⽅法⽆法通过参数压栈的⽅式,⽽是通过寄存器传递参数的⽅式。寄存器传递参数的个数是有限制的,⽽且每个参数的⻓度不能超过寄存器的⻓度,32位x86体系结构下寄存器的⻓度最⼤32位。除了EAX⽤于传递系统调⽤号外,参数按顺序赋值给EBX、ECX、EDX、ESI、EDI、EBP(64位机为RDI、RSI、RDX、RCX、R8、R9这6个寄存器),参数的个数不能超过6个,即上述6个寄存器。如果超过6个就把某⼀个寄存器作为指针。
3.3 中断过程中中断上下文的切换过程(以系统调用为例)
int $0x80指令或syscall指令触发系统调⽤机制会在堆栈上保存⼀些寄存器的值,会保存中断发⽣时当前执⾏程序的栈顶地址(ESP、RSP)、当时的状态字(EFlags、RFlags)、当时的 CS:EIP/RIP 的值。同时会将当前进程内核态的栈顶地址、内核态的状态字放⼊ CPU 对应的寄存器,并且 CS:EIP/RIP 寄存器的值会指向中断处理程序的⼊⼝。中断保存了⽤户态 CS:EIP 的值,以及当前的堆栈段寄存器的栈顶,在 EFLAGS 寄存器的当前的值保存到内核堆栈⾥。然后执行SAVE_ALL ,完成中断服务,发⽣进程调度。如果没有发⽣进程调度,就直接 restore_all 恢复中断现场,然后 iret 返回到原来的状态。
总的来说,中断的全过程是当⼀个中断信号发⽣时,CPU把当前正在执⾏的进程X的CS:RIP寄存器和RSP寄存器等都压栈到了⼀个叫内核堆栈的地⽅,然后把CS:RIP指向⼀个中断处理程序的⼊⼝,做保存现场的⼯作,然后去执⾏其他进程⽐如Y,等重新回来时再恢复现场。
4.课程总结与心得体会
经过半学期的网课学习,在孟老师和李老师的细心授课下,我由原来对linux一无所知到有了一定的认识,了解了linux内核运行的方式,进程创建和切换的运行模式等,对以后学习linux操作系统有很大的帮助。这门课的学习,加深了我对操作系统理论的理解十分感谢孟老师和李老师的辛勤付出!

