1 from numpy import *
2 import matplotlib
3 from os import listdir
4 import kNN
5 def img2vector(filename):
6 returnVect = zeros((1,1024))
7 fr = open(filename)
8 for i in range(32):
9 lineStr = fr.readline()
10 for j in range(32):
11 returnVect[0,32*i+j] = int(lineStr[j])
12 return returnVect
13 def handwritingClassTest():
14 hwLabels = []
15 trainingFileList = listdir('trainingDigits') #load the training set
16 m = len(trainingFileList)
17 trainingMat = zeros((m,1024))
18 for i in range(m):
19 fileNameStr = trainingFileList[i]
20 fileStr = fileNameStr.split('.')[0] #take off .txt 0_0.txt 将整个文件名以 . 分开 取第一部分也就是0_0
21 classNumStr = int(fileStr.split('_')[0]) #将 0_0 以 _ 分开 取第一部分也就是0
22 hwLabels.append(classNumStr)
23 trainingMat[i,:] = img2vector('trainingDigits/%s' % fileNameStr)
24 testFileList = listdir('testDigits') #iterate through the test set
25 errorCount = 0.0
26 mTest = len(testFileList)
27 for i in range(mTest):
28 fileNameStr = testFileList[i]
29 fileStr = fileNameStr.split('.')[0] #take off .txt
30 classNumStr = int(fileStr.split('_')[0])
31 vectorUnderTest = img2vector('testDigits/%s' % fileNameStr)
32 classifierResult = kNN.classify0(vectorUnderTest, trainingMat, hwLabels, 3)
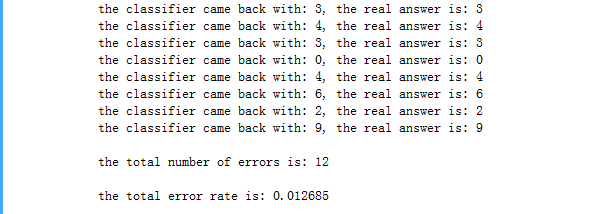
33 print "the classifier came back with: %d, the real answer is: %d" % (classifierResult, classNumStr)
34 if (classifierResult != classNumStr): errorCount += 1.0
35 print "\nthe total number of errors is: %d" % errorCount
36 print "\nthe total error rate is: %f" % (errorCount/float(mTest))
37 handwritingClassTest()