


JDK1.8之HashMap基础
原始HashMap没有引入红黑色树,现在的JDK1.8重新改造了,将其纳入其中。为什么要纳入?
因为红黑树增删改的效率都很高
知识简单回顾
什么是hash函数,什么是hash算法,什么是Hash桶?
hash函数其实就是你无论传入什么参数,最后都给出一个固定长度的值,其实就是一种签名。有什么特点,不可逆,是单项的。
hash算法一般通过位移补码等手法实现,而hash函数就是hash算法的具体体现。
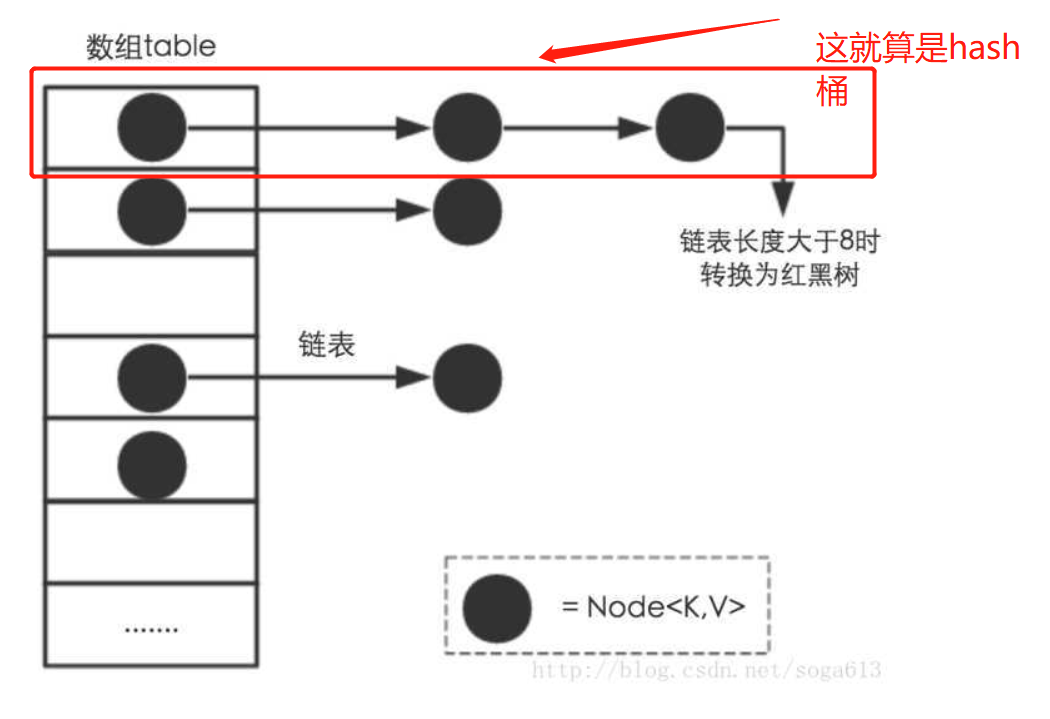
Hash桶其实就是通过hash函数后,输入一个值,这个值就是桶的index。用hashMap解释,给图如下:
什么是Hash碰撞?
就是输入不同的参数,可是却得到了相同的hashCode,碰撞了
如果HashMap发生了Hash碰撞,如何解决?
使用链表的策略,在后面放一个,前面的值给予一个指向引用,桶里数量太多,超过7个就应该转为红黑树存储了
修正:有的人在自己博客上说8个,不要人云亦云啊,代码如下:
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
TREEIFY_THRESHOLD - 1=7啊,所以当binCount为7的时候就以及要转红黑树了
------------------------------分割线--------------------------------------
好了,继续总结
HashMap的使用流程?
把任意长度的对象作为参数,参入hashCode函数,变换成固定长度的输出,该输出就是哈希值(hashCode),Hashmap用它做出哈希表。
HashCode作为数组下标,把该下标对应的位置作为键值对的存储位置,通过该方法建立的数组就叫做哈希表,而这个存储位置就叫做hash桶,见上图。
哈希表选用哈希函数计算哈希值时,可能不同的 key 会得到相同的结果,一个地址怎么存放多个数据呢?这就是哈希冲突。Hashmap使用拉链法
:将键值对对象封装为一个node结点,新增了next指向,这样就可以将碰撞的结点链接成一条单链表,保存在该地址(数组位置)中,超过7个,来blackTreee。
下一节重点看看hashMap的源码
