

聊聊超卖
聊聊超卖
焦点: 这篇文章,主要是想聊一聊 “超卖” 这个场景,并且借此,串一下整个电商的交易流程,加深对电商交易的认真。
电商交易流程
我们先看下电商的交易流程:
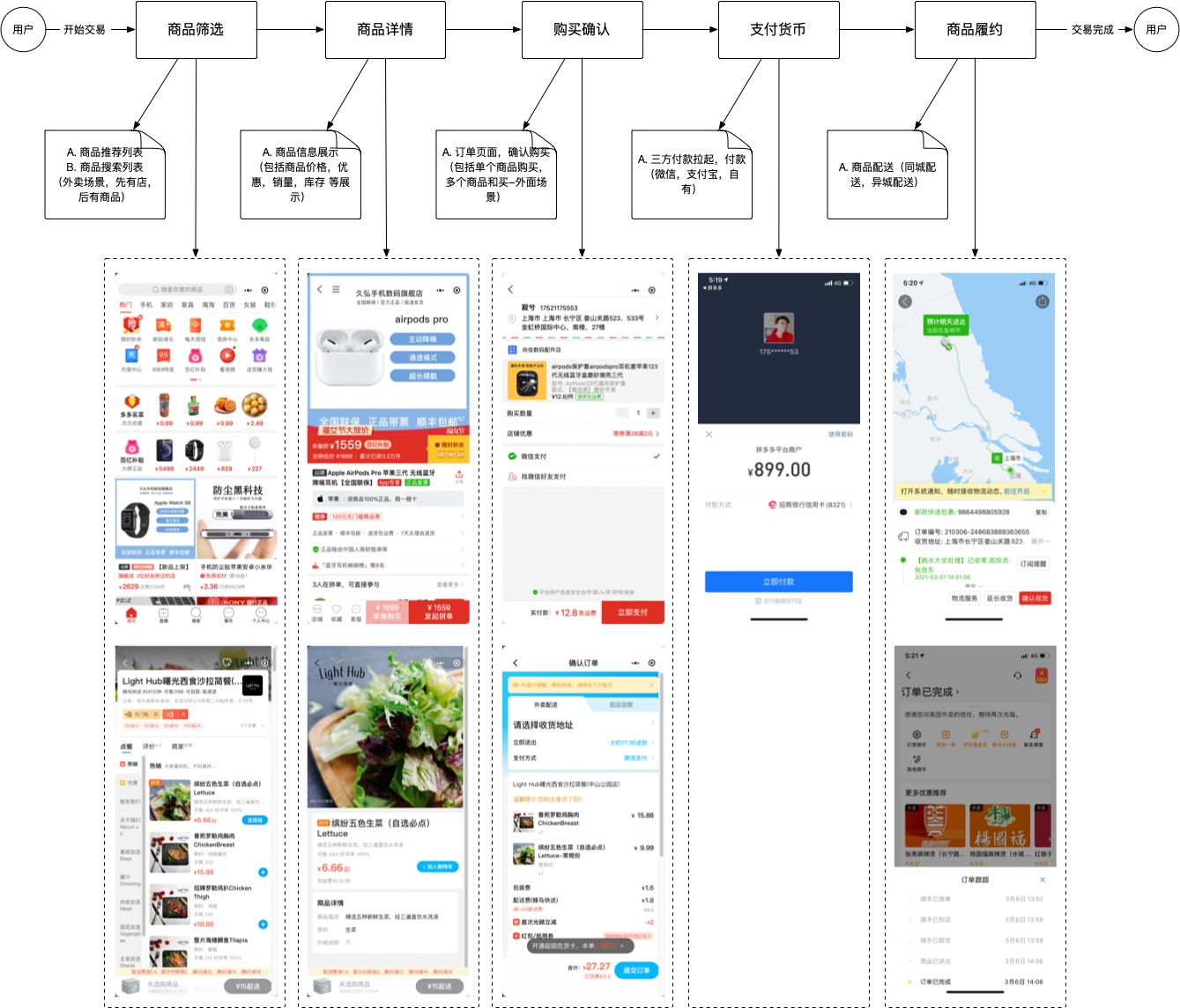
不管是同城外卖场景,还是异城的的传统电商购物,主要流程都不会有太多区别。
- 商品筛选
交易的实体是商品,而商品筛选是最先经历的一环,用户的目的是从无数的商品中,筛选(搜索)出自己想要买的那一款,所以搜索这一环是平台必须提供的能力,而平台的目的,就是在无数的商品中,尽可能的将用户要买的商品摆到用户面前,这也就是所谓的 “推荐“
根据业务场景不同,外卖电商会有很强的商家概念,所谓“很强”,就是会在用户端凸显商家的存在,用户第一选择的主体是商铺,然后才是商铺中的商品。而普通电商并不是没有商家,而是商家不会在用户端被很强的凸显出来。
- 商品详情
对交易实体-商品的详细介绍,包括商品图片,商品介绍,商品价格等等,目的是让用户能够对商品本身有个更清晰的认知,一些特殊的技术如:全景,模拟,视频,等都在努力丰富用户对产品的认知。
- 购买确认
用户选好商品后准备购买的二次确认操作,无论是选一件商品,还是选多件商品,都需要用户确认,本质上来说,买一件商品和买多件商品并没有区别,但在存储上,根据业务场景不同,会有不同的实现手段,比如外卖电商是只能在一个店铺下进行多商品购买的(方便后面配送履约),普通电商是可以跨店购买商品的(后面的逻辑是拆单,将不同店铺的商品,拆成不同单)。二次确认主要是让用户再次明确:商品价格、优惠政策、配送地址等,也叫预签合同,当用户对此合同支付完成之后,合同便开始生效(创建订单,订单状态开始流转),直到商品配送到用户手里,用户满意后确认收货,合同完成(订单完结)
- 支付货币
有自主钱包的,可以免跳转第三方支付,没有自主钱包的平台,都会跳转三方支付平台进行支付,用户确认付款后。
- 商品履约
商品配送可以分为本地生活类的骑手配送(商家送,自取等),和快递类的全国送(得益于国家强大,基建完善:中国邮政无处不在),履约也有可能有自身的状态流转(比如待接单,接单送出,商品送达等),所以仔细一点的电商 平台都会有区别于“用户单”的“履约单”,履约单又是一大堆的细节,这里不做细节讨论。
超卖是什么
超卖本身是一个股票概念,不知道为什么出现在电商交易中,而在电商交易中,超卖指:卖出商品的数量 大于 商品可卖库存。
还原真实场景,看下什么时候,卖出的商品数量 大于 商品可卖库存。打个比方 A是商户,手里有10个苹果,每个1块钱;B、C、D是买家,都要买苹果,不过B、C、D的需求各不相同,用表格来具体一下数据。
| 人 | 类型| 动作| 苹果数量|
|:—😐:—😐:—😐:—😐
|A|商户|出售|10|
|B|用户|购买|5|
|C|用户|购买|4|
|D|用户|购买|2|
在看几种有意思的交易流程:
场景(一) 顺序交易,先付款,后交货,无逆向
- B准备买5个苹果,然后把5块钱给了A,A收了钱后发现自己还有10个苹果,就把其中5个给了B,B交易完成
- C准备买4个苹果,然后把4块钱给了A,A收了钱后发现自己还有5个苹果,就把其中4个给了C,C交易完成
- D准备买2个苹果,然后把2块钱给了A,A收了钱后发现自己还有1个苹果,就把钱还给了A,说库存不够了,A交易停止
- A剩余1个苹果
场景(二)顺序交易,先交货,后付款,无逆向
- B准备买5个苹果,A发现自己有10个苹果,就拿出5个给了B,B给了A 5块钱,B交易完成
- C准备买4个苹果,A发现自己有5个苹果,就拿出4个给了C,C给了A 4块钱,C交易完成
- D准备买2个苹果,A发现自己有1个苹果,就说库存不够,B交易停止
- A剩余1个苹果
场景(三)顺序交易,先交货,后付款,有逆向
- B准备买5个苹果,A发现自己有10个苹果,就拿出5个给了B,B给了A 5块钱,B交易完成
- C准备买4个苹果,A发现自己有5个苹果,就拿出4个给了C,C不想付款了,就把4个苹果还给了A,C交易停止
- D准备买2个苹果,A发现自己有5个苹果,就拿出2个给了D,D给了A 2块钱,D交易完成
- A剩余3个苹果
场景(四)并发交易,先交货,后付款,有逆向
- B准备买5个苹果,A发现自己有10个苹果,就拿出5个给了B,B给了A 5块钱,B交易完成
- C和D同时来买苹果,C要4个,D要2个,A先给C拿出4个,又准备给D拿出2个,发现库存不足,D交易停止,C不想付款了,C把4个苹果还给了A,C交易停止
- A剩余5个苹果
所以,现实场景中,根本 不会发生 超卖, 由于业务是现实场景的反馈,所以,业务上也 不会发生 超卖
业务上不会发生超卖
把准备交易比作“创建订单”,把A拿出苹果比作“扣减库存”,把B交钱给A比作“付款”, 那上面的场景可以简化为:
- 创建订单,支付成功,扣减库存(可简称 支付后扣库存)
- 创建订单,扣减库存,支付成功(可简称 创单后扣库存)
- 创建订单,扣减库存,支付取消,回滚库存
为什么会有超卖
上面说了,业务上不会发生超卖,可大家一直谈论的“交易超卖”是什么呢?还是要分两个方面看:
- 业务超卖
- 技术超卖
业务超卖
刚说了“业务上不会发生超卖”,为什么会有“业务超卖”呢? 是因为一些公司,在正常的流程中,人为的改变了一些业务因素,才会导致。
举个例子,拼多多的电商场景,是以用户为主的,原则是大力维护用户利益,在发生交易的时候,如果用户付款之后,平台发现商品已经没有库存了,宁可想办法补调商品(可能会损失平台利益),争取让用户购买到,即特殊情况除外,不会主动发生退款现象(即不会发生场景一,D购买的情况)
那,根据拼多多电商场景,默认不主动退款,而支付后扣库存的场景,我们模拟一个超卖的逻辑:
场景(五)并发交易,先付款,后交货,不主动退款
- B准备买5个苹果,然后把5块钱给了A,A收了钱后发现自己还有10个苹果,就把其中5个给了B,B交易完成
- C和D同时来买苹果,C给A 4块钱,要买4个,D给A 2块钱要买2个,A收了C和D的钱,A发现还剩5个苹果,就先给A了4个,然后A发现就剩1个了,不足以支付D 2个苹果,但是因为 不主动退款 的原则,只能想办法掉(或者自己从其他人那买)1个进来,然后再给D 2个苹果。对A来说,超卖了1个(计划卖10个,但是卖了11个)
所谓的业务超卖,就是在正常交易场景下,因为一些业务原因,导致部分环节不执行,导致超卖
支付后扣库存, 不主动退款的情况下,会超卖
下单后扣库存,不主动拦截下单的情况下,会超卖
其中逻辑,耐人寻味
技术超卖
为了变量单一,我们假设业务流程正常,即无业务超卖,单从技术上来看,如何发生超卖?如何避免超卖?
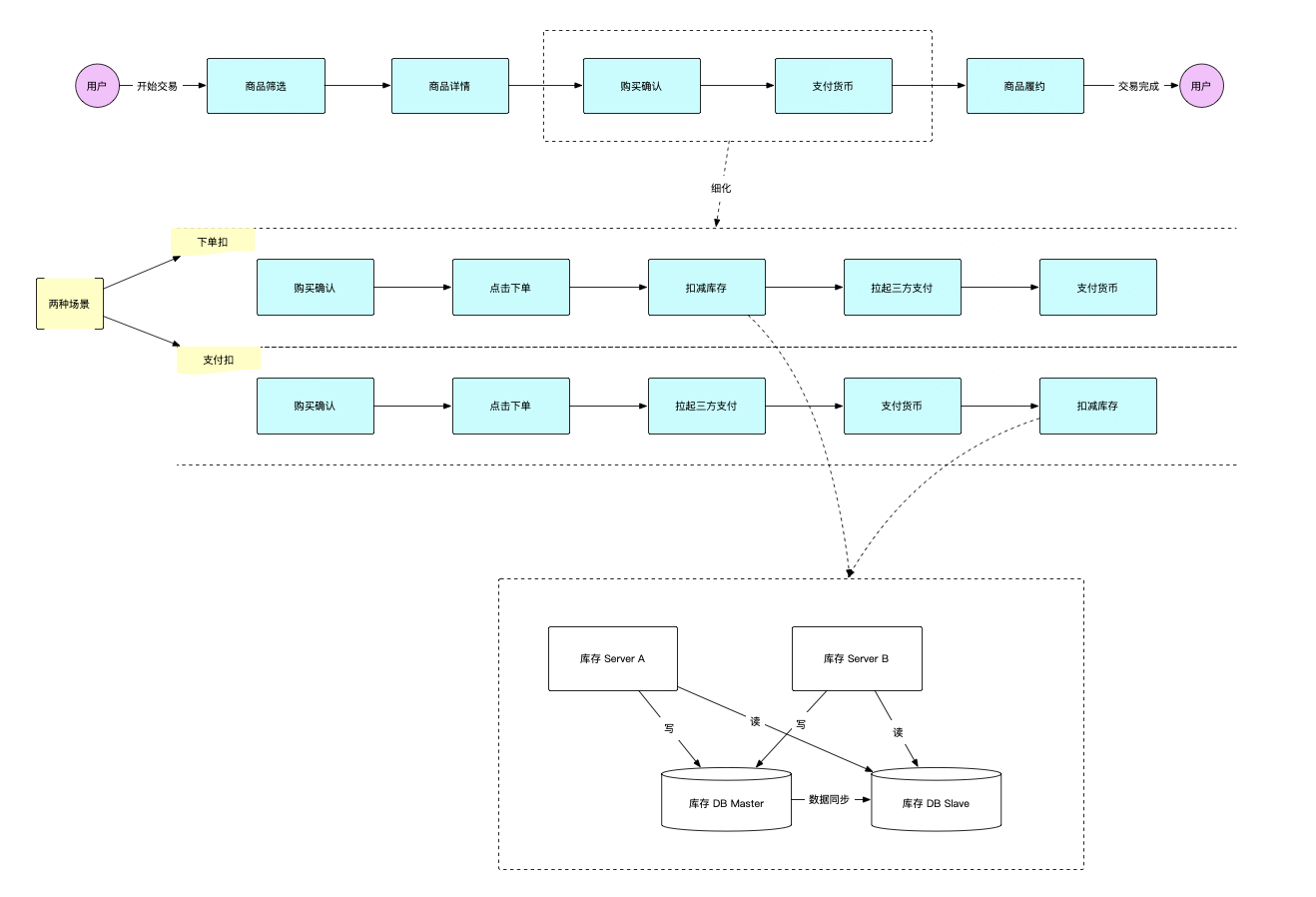 

把流程聚焦,在交易链路中,存在两种顺序的扣库存行为,一种是下单之后扣库存,一种是支付之后扣库存,由于这两种场景都属于业务场景,业务场景不发生超卖的前提下,只考虑技术导致超卖,那超卖只会发生在「扣减库存」这个点上。
把「扣减库存」这个点放大,可以看到最简单的扣库存架构,将扣库存流程做到最简化,时序图如下:


假设两种场景:
场景一:顺序操作
初始化条件:商品A有1个库存
- 订单服务第一次请求库存服务,查询商品还有库存,要求对商品A减少1个库存,库存DB执行
update goods_stock quantity = quantity - 1 where goods_id = A之后,quantity 字段为0,下单成功 - 订单服务第二次请求库存服务,查询商品没有库存,则下单失败
场景二:并发操作
初始化条件:商品A有1个库存
- 订单第一次扣库存请求和第二次扣库存请求,都同时到了 库存服务,查询都有库存,都进行
update goods_stock quantity = quantity - 1 where goods_id = A之后,quantity 字段为-1,两次下单都成功
场景二会导致多卖一件,即发生超卖
发生超卖的原因:查询拦截 和 扣减库存 是两个割裂开的动作,并非一个原子操作, 解决办法,也比较简单, 将查询拦截 和 扣减库存 两个动作 做成原子的,有很多办法
小并发防超卖
如果并发比较小(扣库存操作的OPS < 库存DB能够承担的 OPS)最简单的可能是利用sql对数据的影响条数来判断
可用sql:update goods_stock quantity = quantity - 1 where goods_id = A and quantity >0
判断依据:影响行数 >0 则说明扣减成功,影响行数 <=0 则说明扣减失败,拦截订单
大并发防超卖
如果并发比较大(扣库存操作的OPS > 库存DB能够承担的 OPS),单用 DB 做原子操作,对DB的压力比较大,所以要想个办法,既能让 库存判断 和 库存扣减 组成一个原子操作,又能承受很高的OPS。
最先想到的就是用Redis来代替DB支持高OPS。但是用Redis就需要考虑如下几个场景:
- DB 和 Redis 数据同步(什么时候将DB数据同步到Redis, 什么时候将Redis数据同步DB)
- 查询拦截 和 扣减库存 两个操作,如何用Redis做成原子化?
Redis在高并发场景下的使用姿势基本是固定的,先不考虑 更新DB 和 更新Redis 失败的情况,在保证 更新DB 和 更新Redis 这两个操作都能成功的情况下,更新Redis的 Design Pattern有四种:
- Cache Aside
- Read Through
- Write Through
- Write Behind Caching
简单说下四种模式的区别:
Cache aside,查询:应用程序从cache中取数据,取到后返回; 没有得到,则从数据库中取数据,成功后,放到缓存中。跟新:先把数据存到数据库中,成功后,再让缓存失效。
Read Through Pattern, 套路就是在查询操作中更新缓存,也就是说,当缓存失效的时候(过期或LRU换出),Cache Aside是由调用方负责把数据加载入缓存,而Read Through则用缓存服务自己来加载,从而对应用方是透明的。
Write Through Pattern,套路和Read Through相仿,不过是在更新数据时发生。当有数据更新的时候,如果没有命中缓存,直接更新数据库,然后返回。如果命中了缓存,则更新缓存,然后再由Cache自己更新数据库(这是一个同步操作)
Write Behind Caching 在更新数据的时候,只更新缓存,不更新数据库,而我们的缓存会异步地批量更新数据库。这个设计的好处就是让数据的I/O操作飞快无比(因为直接操作内存嘛 ),因为异步,write backg还可以合并对同一个数据的多次操作,所以性能的提高是相当可观的。
再说明一点:所有 Redis 跟新 Desing Pattern 都是会有问题的,在软件设计上,我们基本上不可能做出一个没有缺陷的设计,软件设计从来都是取舍
根据上面四种模式,基本能看出, Write Behind Caching 是我们需要的模式,在请求中,只更新缓存,异步更新数据库,至于异步的逻辑,也有提到(可以是单条处理,可以是批处理)
那有个问题,由于库存以redis为准,何时初始化redis数据?redis过期时间怎么处理? 是否全部都以Redis为准?
先思考个问题,是所有商品都会有大并发的扣库存操作(爆品)?还是部分商品是爆品?成为爆品是否可预测 ?
在我了解的电商场景里面,这个几个问题的答案是:不是所有的商品都是爆品,爆品可预测。 经验来看,仅秒杀场景(定时开售,高性价比)商品所产生的库存扣减流量,才会导致DB承受不住扣减库存OPS。
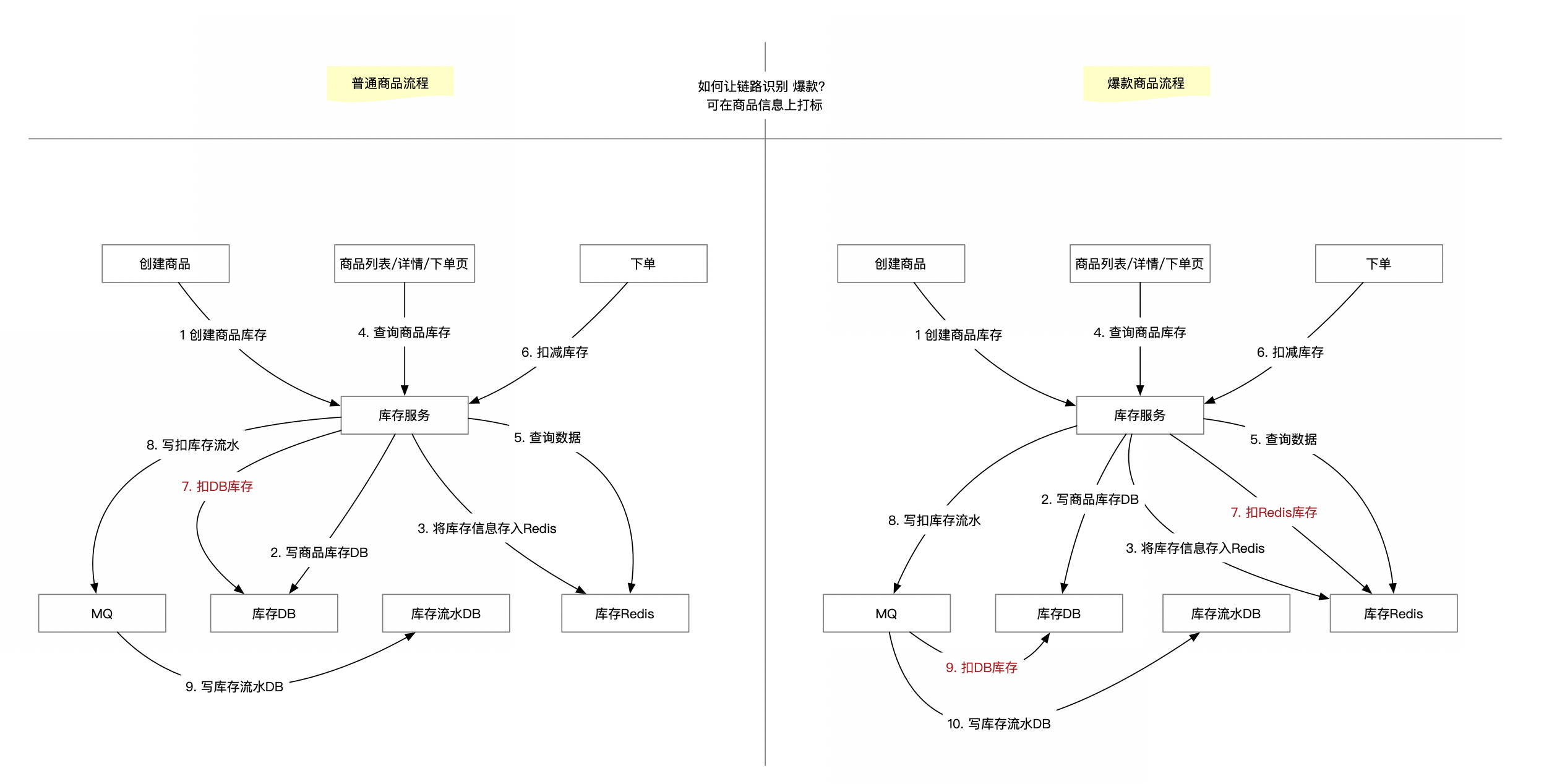
上图是整个操作流程,看图再回答下上面的问题:
- 何时初始化redis数据? 在创建商品的时候,可把数据设置进去
- redis过期时间怎么处理? 随着商品被删除、售罄 等动作删除,也可以用job来做数据兜底,比如check删除的商品,缓存是否都被删除了
- 是否全部都以Redis为准? 爆款商品以redis为准,普通商品以DB为准(扣库存DB是正规操作,为了维稳,只能针对爆款(少数)商品 以Redis为准
再说下这个问题:查询拦截 和 扣减库存 两个操作,如何用Redis做成原子化?
Redis对命令是原子化的(因为对命令处理是单线程的),所以使用lua脚本把 查询拦截 和 扣减库存 做成一个命令,保证原子化。
| public class StockService { | |
| /** | |
| * Redis 客户端 | |
| */ | |
| private RedisTemplate<String, Object> redisTemplate; | |
| /** | |
| * 执行扣库存的脚本 | |
| */ | |
| public static final String STOCK_LUA; | |
| static { | |
| /** | |
| * | |
| * @desc 扣减库存Lua脚本 | |
| * 库存(stock)0:表示扣库存失败,没有可用库存 | |
| * 库存(stock)1:表示扣库存成功 | |
| */ | |
| StringBuilder sb = new StringBuilder(); | |
| sb.append("if (redis.call('exists', KEYS[1]) == 1) then"); | |
| sb.append(" local stock = tonumber(redis.call('get', KEYS[1]));"); | |
| sb.append(" local num = tonumber(ARGV[1]);"); | |
| sb.append(" if (stock >= num) then"); | |
| sb.append(" redis.call('incrby', KEYS[1], 0 - num);"); | |
| sb.append(" return 1; | |
| sb.append(" end;"); | |
| sb.append(" return 0;"); | |
| sb.append("end;"); | |
| sb.append("return 0;"); | |
| STOCK_LUA = sb.toString(); | |
| } | |
| /** | |
| * 扣库存 | |
| * | |
| * @param key 库存key | |
| * @param num 扣减库存数量 | |
| * @return true 扣成功;false 扣失败 | |
| */ | |
| private boolean decrStock(String key, int num) { | |
| // 脚本里的KEYS参数 | |
| List<String> keys = new ArrayList<>(); | |
| keys.add(key); | |
| // 脚本里的ARGV参数 | |
| List<String> args = new ArrayList<>(); | |
| args.add(Integer.toString(num)); | |
| long result = redisTemplate.execute(new RedisCallback<Long>() { | |
| @Override | |
| public Long doInRedis(RedisConnection connection) throws DataAccessException { | |
| Object nativeConnection = connection.getNativeConnection(); | |
| // 集群模式和单机模式虽然执行脚本的方法一样,但是没有共同的接口,所以只能分开执行 | |
| // 集群模式 | |
| if (nativeConnection instanceof JedisCluster) { | |
| return (Long) ((JedisCluster) nativeConnection).eval(STOCK_LUA, keys, args); | |
| } | |
| // 单机模式 | |
| else if (nativeConnection instanceof Jedis) { | |
| return (Long) ((Jedis) nativeConnection).eval(STOCK_LUA, keys, args); | |
| } | |
| } | |
| }); | |
| return result == 1; | |
| } | |
| } | |
总结
- 超卖分为 业务导致超卖 和 技术导致超卖
- 只要业务流程正规,则不会导致业务超卖
- 只要保证 查询拦截 和 扣减库存 两个操作能被一个原子操作包裹,则不会导致技术超卖
- 保证 查询拦截 和 扣减库存 两个操作能被一个原子操作包裹, 在大并发 和 小并发 场景,分别有不同的实现方案
转 https://www.cnblogs.com/sutgc/p/17643963.html上述均个人观点,欢迎拍砖,有问题可 留言/邮件 讨论。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享4款.NET开源、免费、实用的商城系统
· 全程不用写代码,我用AI程序员写了一个飞机大战
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· 白话解读 Dapr 1.15:你的「微服务管家」又秀新绝活了
· 上周热点回顾(2.24-3.2)
2022-08-25 彻底了解线程池的原理——40行从零开始自己写线程池
2022-08-25 不安装运行时运行.NET程序
2022-08-25 基于.NET6、FreeSql、若依UI、LayUI、Bootstrap构建插件式的CMS
2022-08-25 【原创】只用Asp.NET Core Web API与Vue 3.0搭建前后分离项目
2022-08-25 学长告诉我,大厂MySQL都是通过SSH连接的
2022-08-25 你有对象类,我有结构体,Go lang1.18入门精炼教程,由白丁入鸿儒,go lang结构体(struct)的使用EP06
2022-08-25 面试突击73:IoC 和 DI 有什么区别?