机器学习-——损失函数
###基础概念
损失函数(loss function)是用来估量你模型的预测值f(x)与真实值Y的不一致程度,换句话,可以解释为我们构建模型得到的预测值与真实值之间的差距。它是一个非负实值函数,通常使用L(Y, f(x))来表示,损失函数越小,模型的鲁棒性就越好。损失函数是经验风险函数的核心部分,也是结构风险函数重要组成部分。模型的结构风险函数包括了经验风险项和正则项,通常可以表示成如下式子:
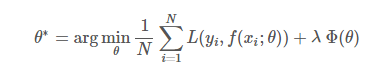
整个公式分为两个部分,前面部分是损失函数,后面部分是正则项,正则项常用的有L1和L2正则项,目的是防止过拟合。
###常用的损失函数
###均方误差(MSE)
均方误差(MSE)是最常用的回归损失函数。MSE是目标变量和预测值之间的平方距离之和。
均方差损失公式:
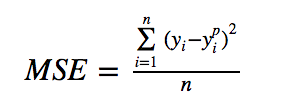
其中yip是预测结果,而yi是目标变量的真实值,二者的差值称之为残差。
###绝对误差(MAE)
平均绝对误差(MAE)是用于回归模型的另一个损失函数。MAE是目标和预测变量之间的绝对差异的总和。因此,它测量一组预测中的平均误差大小,而不考虑它们的方向。
平均绝对误差公式:
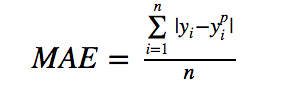
其中yip是预测结果,而yi是目标变量的真实值,二者的差值称之为残差。
###Huber Loss
Huber Loss是均方误差损失和绝对误差损失的综合体。
其公式为:
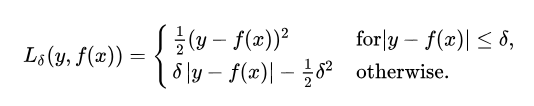
该误差是否逼近二次方取决于可以调整的超参数δ(delta)。当δ~0时, Huber损失接近MAE,当δ~∞(大数)时, Huber损耗接近MSE。
使用MAE训练神经网络的一个大问题是其持续的大梯度,可能导致损失函数不能收敛(错过最小值)。对于MSE,随着损失接近其最小值,梯度减小,使其更精确,但整体训练速度会比较慢。
Huber损失集成了二者的优点。
###0-1损失
0-1损失常用于二分类问题,0-1损失不连续、非凸,优化困难,0-1损失对每个错分类点都施以相同的惩罚,这样那些“错的离谱“ 的点并不会收到大的关注,这在直觉上不是很合适,因而常使用其他的代理损失函数进行优化。
0-1损失公式:
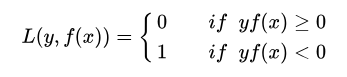
其中yf(x) > 0 ,则样本分类正确, yf(x) < 0 则分类错误,而相应的分类决策边界即为 f(x) = 0 。
###对数损失函数
对数损失, 即对数似然损失(Log-likelihood Loss), 也称逻辑斯谛回归损失(Logistic Loss)或交叉熵损失(cross-entropy Loss), 是在概率估计上定义的.它常用于逻辑回归和神经网络,以及一些期望极大算法的变体. 可用于评估分类器的概率输出.
对数损失的公式为:
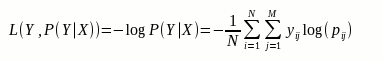
其中, Y 为输出变量, X为输入变量, L 为损失函数. N为输入样本量, M为类别数, yij 是表示类别 j 是否是输入实例 xi 的真实类别. pij 为模型或分类器预测输入实例 xi 属于类别 j 的概率。
如果目标是进行二分类,则损失函数可以简化为:
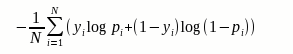
###指数损失函数
指数损失是在原有的损失函数上套一层指数,在adaboost上使用的就是指数损失,在加性模型中指数损失的主要吸引点在于计算上的方便。
指数损失公式:
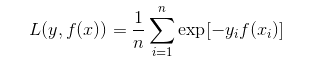
其中n为样本数量,yi是样本的真实值,f(xi)是第i次迭代模型的权重。
参考资料: https://heartbeat.fritz.ai/5-regression-loss-functions-all-machine-learners-should-know-4fb140e9d4b0

 浙公网安备 33010602011771号
浙公网安备 33010602011771号