


| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/gdgy/CSGrade22-34 |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/gdgy/CSGrade22-34/homework/13229 |
| 这个作业的目标 | 独立完成论文查重的个人项目 |
GitHub地址:
https://github.com/wklay-77/Wklay-77
一、psp表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 25 |
| · Estimate | · 估计这个任务需要多少时间 | 15 | 30 |
| Development | 开发 | 630 | 870 |
| · Analysis | · 需求分析 (包括学习新技术) | 180 | 240 |
| · Design Spec | · 生成设计文档 | 20 | 30 |
| · Design Review | · 设计复审 | 60 | 45 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 15 | 20 |
| · Design | · 具体设计 | 35 | 35 |
| · Coding | · 具体编码 | 400 | 360 |
| · Code Review | · 代码复审 | 40 | 55 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 80 | 100 |
| Reporting | 报告 | 140 | 120 |
| · Test Repor | · 测试报告 | 50 | 55 |
| · Size Measurement | · 计算工作量 | 30 | 55 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 20 | 60 |
| · 合计 | 1745 | 2070 |
二、需求分析
题目:论文查重
描述如下:
设计一个论文查重算法,给出一个原文文件和一个在这份原文上经过了增删改的抄袭版论文的文件,在答案文件中输出其重复率。
原文示例:今天是星期天,天气晴,今天晚上我要去看电影。
抄袭版示例:今天是周天,天气晴朗,我晚上要去看电影。
要求输入输出采用文件输入输出,规范如下:
从命令行参数给出:论文原文的文件的绝对路径。
从命令行参数给出:抄袭版论文的文件的绝对路径。
从命令行参数给出:输出的答案文件的绝对路径。
总结为以下两点:
1.对输入的原文文件和抄袭版文件进行重复率分析计算;
2.使用命令行将重复率输出到答案文件内,其中数字精确到小数点后两位。
3.答案文件中输出的答案为浮点型,精确到小数点后两位
三、计算模块接口的设计与实现:
分为四个类:Main , MainTest , SimilarityMain ,SimilarityMainTest .
包含的方法:main(String[] args) 方法,testSimilarity() 方法,setUp() 方法,calculateVector(String str, int index) 方法,cosineSimilarity() 方法,similarity()方法,testMain 方法等
类的执行流程:
1.用户首先运行 Main 类中的 main 方法。
2.main 方法中创建了一个 Scanner 对象,用于从控制台获取用户输入的文件路径。
3.用户输入原始论文文件路径、抄袭版论文文件路径和要保存相似度结果的文件路径。
4.如果用户输入的文件路径为空,则程序输出相应的提示信息并结束。
5.否则,程序会创建一个 DecimalFormat 实例,然后使用输入的文件路径创建 SimilarityMain 实例。
6.SimilarityMain 实例的 similarity() 方法被调用来计算两篇论文的相似度。
7.计算得到的相似度结果会被打印到控制台。
8.程序将相似度结果写入用户指定的输出文件,并在控制台上显示操作结果。
9.如果在写入文件时出现异常(IOException),则捕获异常并输出错误信息。
四、计算模块接口部分的性能改进
改进计算模块思路:
在这个地方花费的时间较多,改进时我增加了异常处理机制,引入了语义信息。
性能分析图:
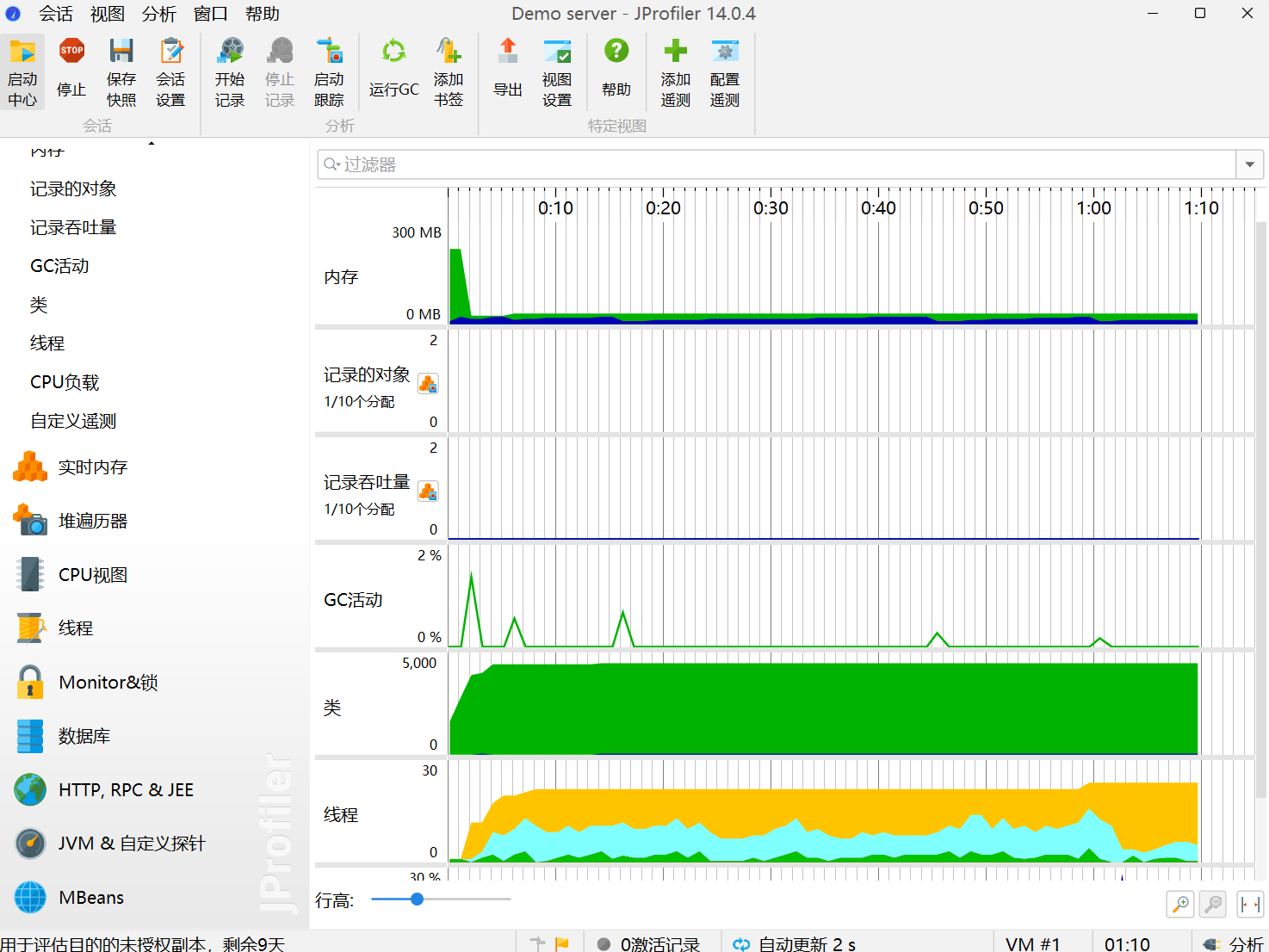
Memory占用图:
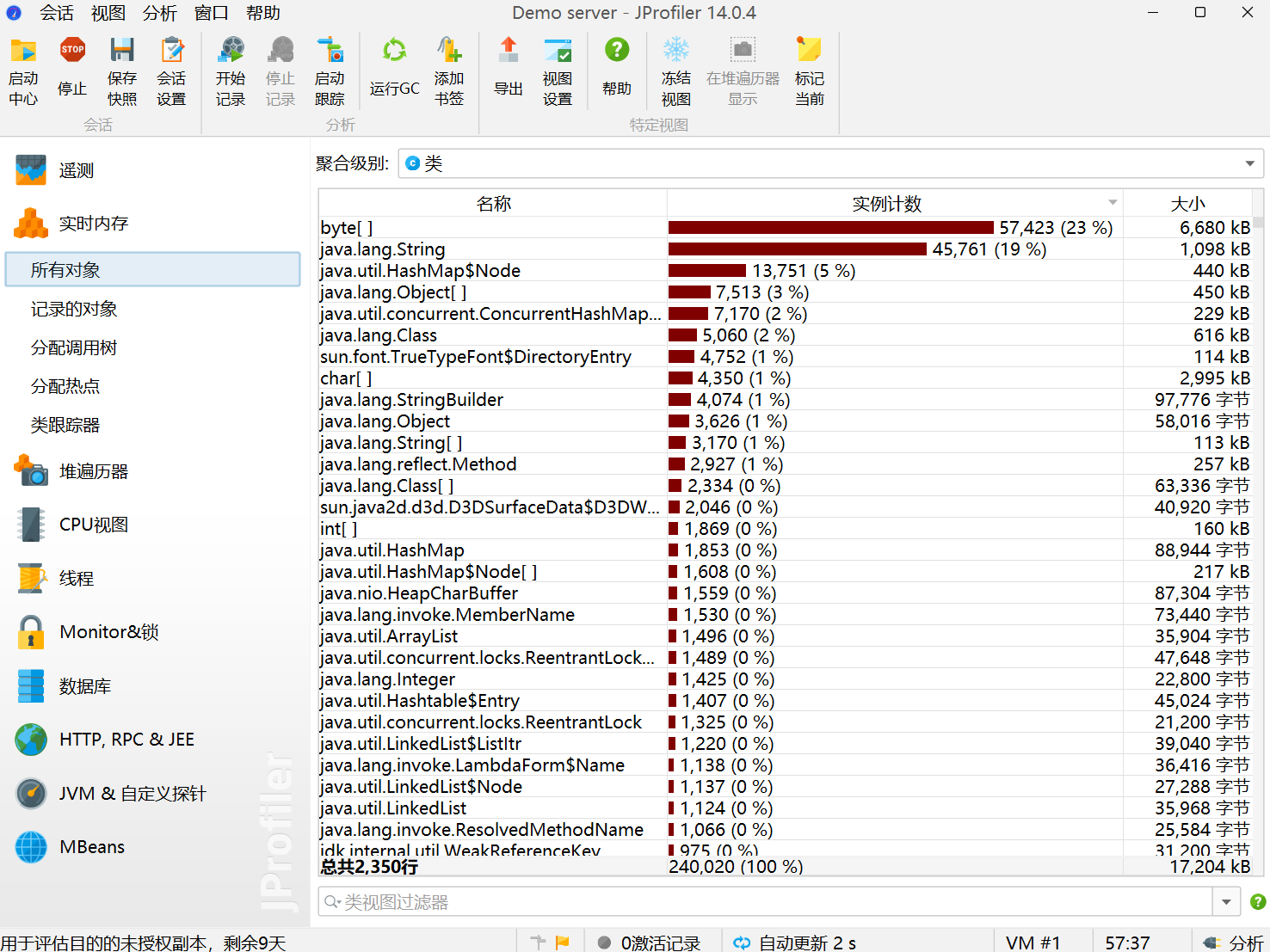
五、计算模块部分单元测试展示
部分单元测试代码:
@Test
public void testSimilarity() {
// 运行测试
final double result = similarityMainUnderTest.similarity();// 调用待测试对象的 similarity 方法得到相似度计算结果:
// 验证结果
double expected = 0.4364357804719848;// 预期的相似度计算结果
assertEquals(expected, result, 0.001);// 使用断言验证实际结果和预期结果是否一致,允许误差为0.001
// 打印实际结果和预期结果
System.out.println("实际结果:" + result);
System.out.println("预期结果:" + expected);
}
测试的函数: testSimilarity函数
构建测试数据的思路:
测试数据:在这个测试中,测试数据主要是一个已经初始化好的vectorMap对象,其中包含了字符及其对应的向量。
思路:
1.在setUp方法中,首先创建一个vectorMap对象,并使用put方法将字符及其对应的向量加入到vectorMap中。
2.使用反射将创建的实际vectorMap对象设置到SimilarityMain类中的vectorMap字段中。
3.在testSimilarity方法中,通过调用待测试对象的similarity方法得到实际的相似度计算结果。
4.将预期结果赋值给expected变量,即预计的相似度计算结果。
5.使用assertEquals断言来比较实际结果和预期结果是否相等,允许误差为0.001。
6.打印实际结果和预期结果,用于查看测试结果。
部分测试结果截图:
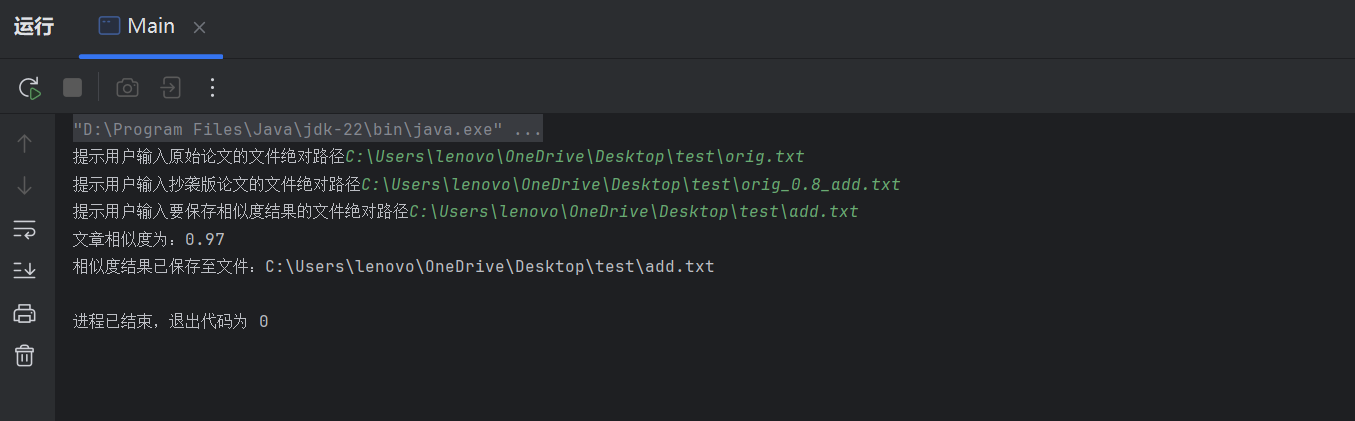
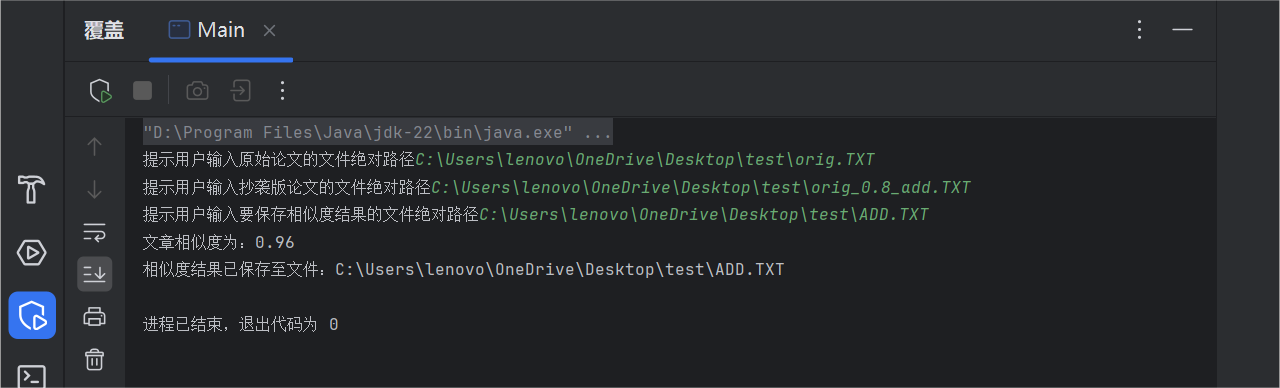
代码覆盖率:

六、测试单元的异常处理
@Test
@Timeout(value = 2000, unit = TimeUnit.MILLISECONDS)
public void testMain() {
DecimalFormat df = new DecimalFormat("0.00");
double d1 = 0.342453;
String formattedValue = df.format(d1);
// 检查格式化后的值是否符合预期
assertEquals("0.34", formattedValue);
}
}
这个测试中,我一开始断言 assertEquals(0.0, result, 0.0001), 导致 java.lang.AssertionError,我调整精度:增大允许的误差范围,即调整最后一个参数(delta)的值,以容忍更大的差异。并且使用更合适的方法来比较浮点数,同时更改了d1的值。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 通过 API 将Deepseek响应流式内容输出到前端
· AI Agent开发,如何调用三方的API Function,是通过提示词来发起调用的吗