创建对象的几种方式
1、new关键字
Student student1 = new Student(); //无参构造函数创建
Student student2 = new Student(18,"zs"); //有参构造函数创建
通过new关键字创建对象使用起来很简单,其内部是通过JVM实现的,实现的过程主要有以下五步:
-
类加载检查
JVM在读取一条new指令时候,首先检查能否在常量池中定位到这个类的符号引用,并且检查这个符号引用代表的类是否被加载、解析和初始化。如果没有,则会先执行相应的类加载过程
-
内存分配
在通过类加载检查后,则开始为新生的对象分配内存。该对象所需的内存大小在类加载完成后便可确定,为对象分配内存空间的任务等同于把一块确定大小的内存从堆中划分出来。而分配方式主要有以下两种:
-
指针碰撞:
-
应用场景:堆内存规整(没有内存碎片,就是用过的内存被整齐充分的利用,用过的内存放在一边,没有用过的放在另外一边,而中间利用一个分界指针对这两边的内存进行分界,从而掌握内存分配情况)。
将堆内存这样划分的代表的GC收集器算法有:Serial,ParNew
-
-
空闲列表
-
应用场景;堆内存不规整(虚拟机会维护一个列表,该列表中会记录哪些内存块是可用的,在这些内存块中将一块足够大的内存块分配给对象实例,同时更新列表记录)
将堆内存这样划分的代表的GC收集器算法有:CMS
-
-
-
初始化零值
在完成内存分配之后,紧接着,虚拟机需要将分配到的内存空间都进行初始化(即给一些默认值),这是为了保证对象实例的字段在Java代码中可以在不赋初值的情况下使用。程序可以访问到这些字段对用数据类型的默认值。
-
设置对象头
在初始化零值完成后,虚拟机会对对象进行一些简单设置,如标记该对象是哪个类的实例,这个对象的hash码,该对象所处的年龄段等等(这些可以理解为对象实例的基本信息)。这些信息被存放在对象头中。JVM根据当前的运行状态,会给出不同的设置方式。
-
执行初始化方法
在设置对象头完成后,从虚拟机的角度来看,一个新的对象已经产生了,但从 Java 程序的视角来看,对象创建才刚开始,
<init>方法还没有执行,所有的字段都还为零。所以一般来说,执行 new 指令之后会接着执行<init>方法,把对象按照开发人员的设计进行初始化,一个对象便创建出来了。
并发环境下如何保证线程安全问题:
-
CAS(compare and swap):比较并交换,这是一种乐观锁的实现方式,每次不加锁而是假设没有冲突而去完成某项操作,如果因为冲突失败就重试,直到成功为止;
-
TLAB: 为每一个线程预先在 Eden 区分配一块儿内存,JVM 在给线程中的对象分配内存时,首先在 TLAB 分配,当对象大于 TLAB 中的剩余内存或 TLAB 的内存已用尽时,再采用上述的 CAS 进行内存分配
2、克隆生成
java中的对象克隆方式又可以分为浅拷贝和深拷贝
浅拷贝:对于值类型的字段会复制一份,对于引用类型的字段复制的是引用地址,并不会生成新的对象;
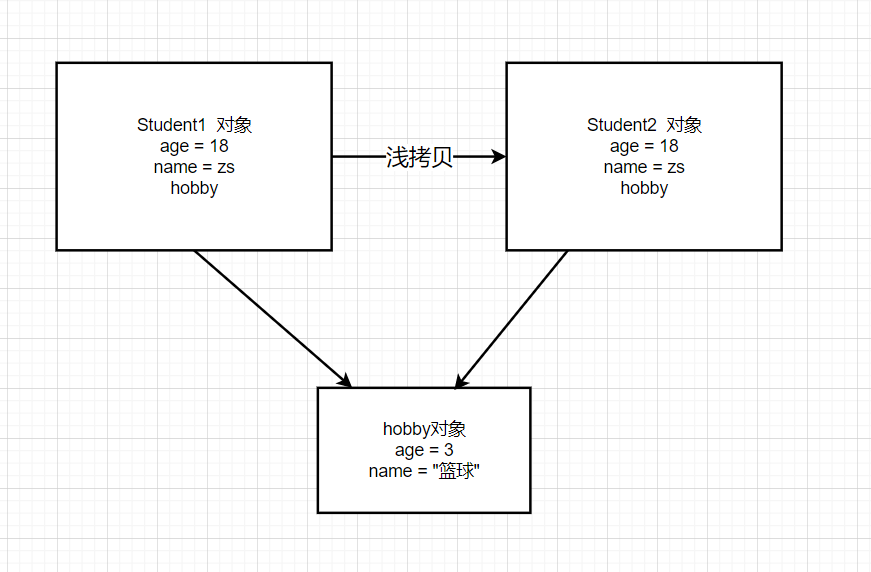
图中的age,name对象会复制一份新的值,但是两个对象中的hobby对象还是引用的同一个对象
代码验证:
Hobby hobby = new Hobby(3, "篮球");
Student student1 = new Student(18,"zs",hobby);
Student student2 = (Student) student1.clone();
System.out.println(student1 == student2);
System.out.println(student1.toString());
System.out.println(student2.toString());
student1.setAge(19);
hobby.setName("足球");
student1.setHobby(hobby);
System.out.println(student1.toString());
System.out.println(student2.toString());
/*
输出结果:
false
Student{age=18, name='zs', hobby=Hobby{age=3, name='篮球'}}
Student{age=18, name='zs', hobby=Hobby{age=3, name='篮球'}}
Student{age=19, name='zs', hobby=Hobby{age=3, name='足球'}}
Student{age=18, name='zs', hobby=Hobby{age=3, name='足球'}}
*/
首先student1 == student2 为false,所以说明浅拷贝产生了两个不同的对象;
当修改student1的age属性(值类型)时,对student2中的age并不会产生影响;但是当修改了hobby(引用类型)中的name属性时,student2中的hobby属性也随之修改,说明两个student对象中的hobby对象引用地址是一样的。
注意:要进行拷贝的对象(如Student对象)需要实现Cloneable接口并重写clone方法,否则会报CloneNotSupportedException异常
public class Student implements Cloneable{
private int age;
private String name;
private Hobby hobby;
@Override
protected Object clone() throws CloneNotSupportedException {
return super.clone();
}
}
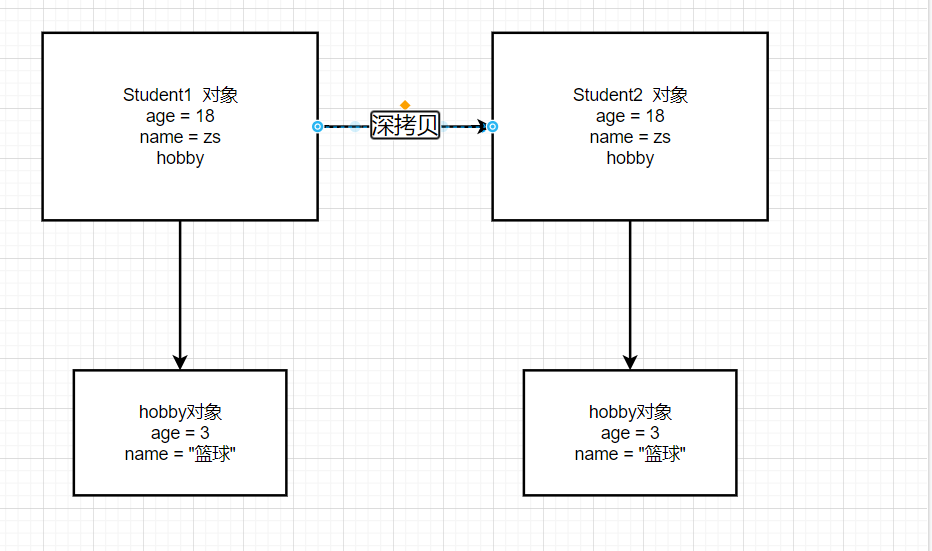
深拷贝:无论是值类型还是引用类型都会复制一个新的对象
代码验证:
@Override
protected Object clone() throws CloneNotSupportedException {
Student student = (Student) super.clone();
student.hobby = (Hobby) hobby.clone();
return student;
}
/*
false
Student{age=18, name='zs', hobby=Hobby{age=3, name='篮球'}}
Student{age=18, name='zs', hobby=Hobby{age=3, name='篮球'}}
Student{age=19, name='zs', hobby=Hobby{age=3, name='足球'}}
Student{age=18, name='zs', hobby=Hobby{age=3, name='篮球'}}
*/
将Hobby对象也是先Cloneable接口,重写clone方法,并修改Student类中的clone方法,重新运行原来的test代码,可以得到以上的结果,说明已经产生两个完全独立的对象了,两者之间互不影响。
3、反射生成
又可以分为使用Class类的newInstance方法和Constructor类的newInstance()方法
反射(Reflection),是指程序在运行期可以拿到一个对象的所有信息。
在反射中有多种方式可以拿到Class对象:
Class<Student> aClass1 = Student.class;
Class<? extends Student> aClass2 = student1.getClass();
Class<?> aClass3 = Class.forName("com.wkf.day05.Student");
Student student3 = aClass1.newInstance(); // 通过无参构造创建对象
Constructor<Student> declaredConstructor = aClass1.getDeclaredConstructor(Integer.class, String.class); // 获取指定参数指定的构造函数
Student student4 = declaredConstructor.newInstance(19, "ls"); // 通过该构造函数生成指定的对象
System.out.println(student3.toString());
System.out.println(student4.toString());
//输出结果
//Student{age=null, name='null'}
//Student{age=19, name='ls'}
//说明通过反射方式已经成功生成所需的对象了
4、反序列化生成
无论何时我们对一个对象进行反序列化,Java虚拟机都会为我们创建一个单独的对象,在反序列化中,Java虚拟机不会使用任何构造函数来创建对象

 浙公网安备 33010602011771号
浙公网安备 33010602011771号