为你的机器学习模型创建API服务
1. 什么是API
当调包侠们训练好一个模型后,下一步要做的就是与业务开发组同学们进行代码对接,以便这些‘AI大脑’们可以顺利的被使用。然而往往要面临不同编程语言的挑战,例如很常见的是调包侠们用Python训练模型,开发同学用Java写业务代码,这时候,Api就作为一种解决方案被使用。
简单地说,API可以看作是顾客与商家之间的联系方式。如果顾客以预先定义的格式提供输入信息,则商家将获得顾客的输入信息并向其提供结果。
从本质上讲,API非常类似于web应用程序,但它没有提供一个样式良好的HTML页面,而是倾向于以标准数据交换格式返回数据,比如JSON、XML等。
接下来让我们看看如何将机器学习模型(在Python中开发的)封装为一个API。
首先需要明白什么是Web服务?Web服务是API的一种形式,只是它假定API驻留在服务器上,并且可以使用。Web API、Web服务——这些术语通常可以互换使用。
Flask——Python中的Web服务框架。它不是Python中唯一的一个Web框架,其它的例如Django、Falcon、Hug等。Flask框架带有一个内置的轻量级Web服务器,它需要最少的配置,因此在本文中将使用Flask框架来开发我们的模型API。
2. 创建一个简单模型
以一个kaggle经典的比赛项目:泰坦尼克号生还者预测为例,训练一个简单的模型。
以下是整个机器学习模型的API代码目录树:
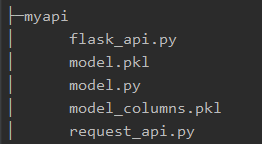
首先,我们需要导入训练集并选择特征。因为本文主要是介绍机器学习模型API的编写,所以模型训练过程并不做为重点内容,因此我们只选择其中的'Age', 'Sex', 'Embarked', 'Survived' 这四个特征来构造训练集。
import pandas as pd # 导入训练集并选择特征 url = "http://s3.amazonaws.com/assets.datacamp.com/course/Kaggle/train.csv" df = pd.read_csv(url) include = ['Age', 'Sex', 'Embarked', 'Survived'] df_ = df[include]
然后,是一个简单的数据处理过程。
这里主要是对类别型特征进行One-hot编码,对连续型特征进行空缺值填充。
categoricals = [] for col, col_type in df_.dtypes.iteritems(): if col_type == 'O': categoricals.append(col) else: df_[col].fillna(0, inplace=True) df_ohe = pd.get_dummies(df_, columns=categoricals, dummy_na=True)
最后,是模型的训练以及持久化保存。
模型采用的是逻辑回归,使用sklearn.externals.joblib将模型保存为序列化文件.pkl。需要注意的是,如果传入的请求不包含所有可能的category变量值,那么在预测时,get_dummies()生成的dataframe的列数比训练得到分类器的列数少,这会导致运行报错发生。所以在模型训练期间还需要持久化训练集One-hot后的列名列表。
from sklearn.linear_model import LogisticRegression from sklearn.externals import joblib dependent_variable = 'Survived' x = df_ohe[df_ohe.columns.difference([dependent_variable])] y = df_ohe[dependent_variable] lr = LogisticRegression() lr.fit(x, y) # 保存模型 joblib.dump(lr, 'model.pkl') print("Model dumped!") # 把训练集中的列名保存为pkl model_columns = list(x.columns) joblib.dump(model_columns, 'model_columns.pkl') print("Models columns dumped!")
到此,我们的model.py的代码部分构造完毕。
3. 基于Flask框架创建API服务
使用Flask部署模型服务,需要写一个函数predict(),并完成以下两件事:
- 当应用程序启动时,将已持久化的模型加载到内存中;
- 创建一个API站点,该站点接受输入变量的请求后,将输入转换为适当的格式,并返回预测。
更具体地说,需要API的输入如下(一个由JSON组成的列表):
[
{"Age": 85, "Sex": "male", "Embarked": "S"},
{"Age": 24, "Sex": '"female"', "Embarked": "C"},
{"Age": 3, "Sex": "male", "Embarked": "C"},
{"Age": 21, "Sex": "male", "Embarked": "S"}
]
而模型API的输出如下:
{"prediction": [0, 1, 1, 0]}
import traceback import sys import pandas as pd from flask import request from flask import Flask from flask import jsonify app = Flask(__name__) @app.route('/predict', methods=['POST']) # Your API endpoint URL would consist /predict def predict(): if lr: try: json_ = request.json query = pd.get_dummies(pd.DataFrame(json_)) query = query.reindex(columns=model_columns, fill_value=0) prediction = list(lr.predict(query)) return jsonify({'prediction': str(prediction)}) except: return jsonify({'trace': traceback.format_exc()}) else: print('Train the model first') return 'No model here to use'
我们已经在“/predict”API中包含了所有必需的元素,现在只需编写主类即可。
from sklearn.externals import joblib if __name__ == '__main__': try: port = int(sys.argv[1]) except: port = 8000 lr = joblib.load('model.pkl') # Load "model.pkl" print('Model loaded') model_columns = joblib.load('model_columns.pkl') # Load "model_columns.pkl" print('Model columns loaded') app.run(host='192.168.100.162', port=port, debug=True)
到此,我们的机器学习模型API已经创建完毕,flask_api.py的代码部分也已构造完毕。但在进一步深入之前,让我们回顾一下之前的所有操作:
- 加载了泰坦尼克数据集并选择了四个特征。
- 进行了必要的数据预处理。
- 训练了一个逻辑回归分类器模型并将其序列化。
- 持久化训练集中的列名的列表。
- 使用Flask编写了一个简单的API,该API通过接收一个由JSON组成的列表,预测一个人是否在沉船中幸存。
4. API的有效性测试
首先运行我们的模型API服务,我们通过Pycharm来启动上一小节编写完成的flask_api.py:
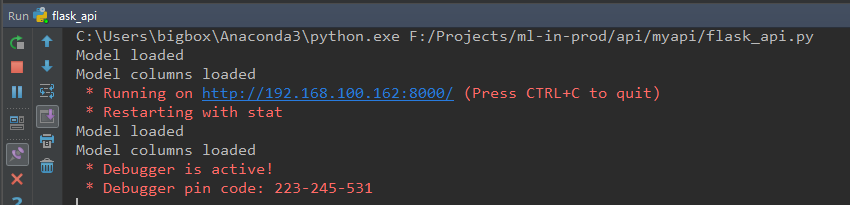
可以看到,在启动API服务后,模型以及列名被顺利的加载到了内存中。
之后可以通过Postman软件模拟网页请求,通过传递测试数据来观察模型API是否能正常返回预测信息。具体操作如下:
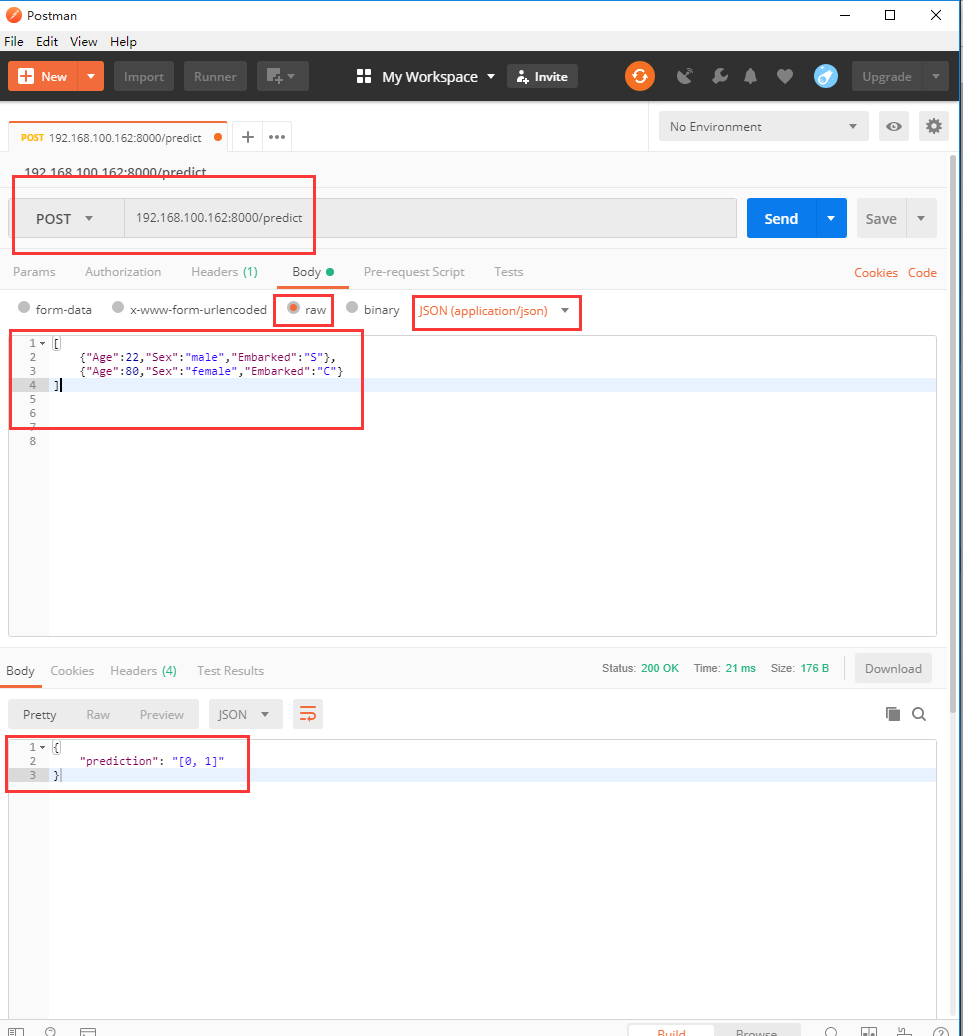
可以看到,模型API顺利的接收到了POST请求并发送预测结果。
当然,除了Postman以外,我们也可以编写Python脚本request_api.py完成API测试:
import requests years_exp = [{"Age": 22, "Sex": "male", "Embarked": "S"}, {"Age": 22, "Sex": "female", "Embarked": "C"}, {"Age": 80, "Sex": "female", "Embarked": "C"}, {"Age": 22, "Sex": "male", "Embarked": "S"}, {"Age": 22, "Sex": "female", "Embarked": "C"}, {"Age": 80, "Sex": "female", "Embarked": "C"}, {"Age": 22, "Sex": "male", "Embarked": "S"}, {"Age": 22, "Sex": "female", "Embarked": "C"}, {"Age": 80, "Sex": "female", "Embarked": "C"}, {"Age": 22, "Sex": "male", "Embarked": "S"}, {"Age": 22, "Sex": "female", "Embarked": "C"}, {"Age": 80, "Sex": "female", "Embarked": "C"}, {"Age": 22, "Sex": "male", "Embarked": "S"}, {"Age": 22, "Sex": "female", "Embarked": "C"}, {"Age": 80, "Sex": "female", "Embarked": "C"}, ] response = requests.post(url='http://192.168.100.162:8000/predict', json=years_exp) result = response.json() print('model API返回结果:', result)
同样我们顺利地接收到了模型的返回结果:

这证明我们的机器学习API已经顺利开发完毕,接下来要做的就是交给业务开发组的同学来使用了。
5. 总结
本文介绍了如何从机器学习模型构建一个API。尽管这个API很简单,但描述的还算相对清晰。
此外,除了可以对模型预测部分构建API以外,也可以对训练过程构建一个API,包括通过发送超参数、发送模型类型等让客户来构建属于自己的机器学习模型。当然,这也将是我下一步要做的事情。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号