多模态学习之论文阅读:《Multi-modal Learning with Missing Modality in Predicting Axillary Lymph Node Metastasis 》
《Multi-modal Learning with Missing Modality in Predicting Axillary Lymph Node Metastasis 》
(一)要点
- 研究背景:多模态学习在医学图像分析中的重要性,尤其是乳腺癌早期患者的腋窝淋巴结转移(ALNM)诊断。
- 问题陈述:临床信息的收集困难,导致多模态模型在实际应用中受限。
- 研究目标:提出一种新的多模态学习框架,解决在预测腋窝淋巴结转移时临床信息可能缺失的问题,提高模型在实际临床环境中的可用性。
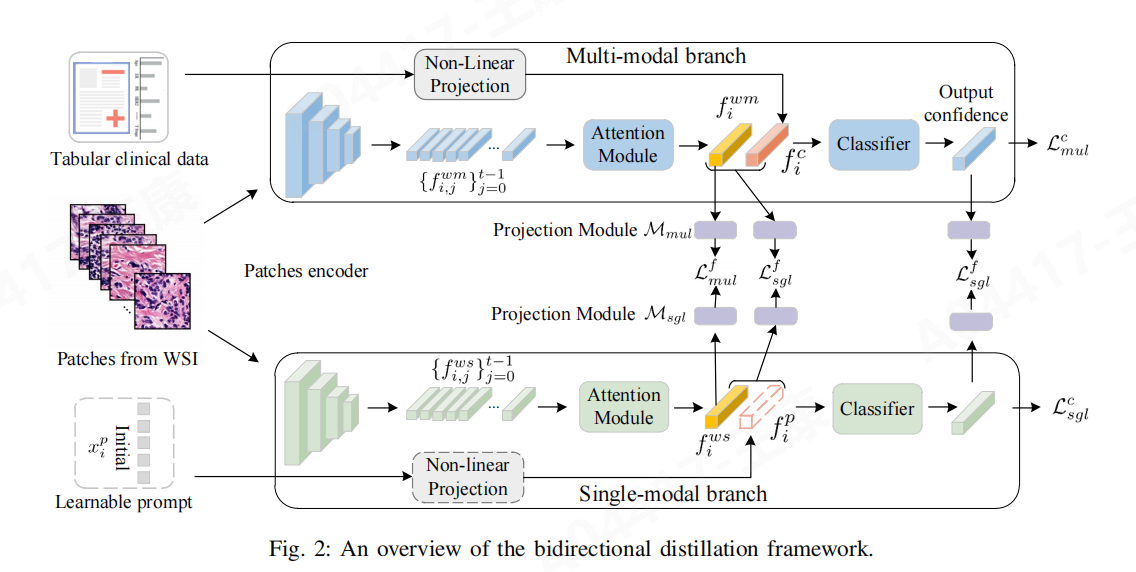
- 概述:提出一个双向蒸馏(Bidirectional Distillation, BD)框架,该框架由单模态分支和多模态分支组成。单模态分支能够从多模态分支获取完整的多模态知识,而多模态分支则从单模态分支学习WSI(全切片图像)的鲁棒特征,两个分支通过知识蒸馏相互交流,以提高模型对缺失模态的鲁棒性,并与Filling、AE、Ensemble这三种处理多模态学习中缺失模态问题的方法进行了对比。
- 灵活性:能够在测试时根据模态的完整性灵活地开启或关闭单模态分支。
- 知识蒸馏:通过引入可学习的提示(learnable prompt)在多模态分支和单模态分支之间进行知识转移。
- 鲁棒性:即使在临床信息大量缺失的情况下,也能保持较高的性能。
(二)步骤
- 问题定义:识别在测试阶段可能缺失的临床信息模态,并定义训练集和测试集。
- 方法设计:开发双向蒸馏(BD)框架,包含单模态和多模态分支,通过知识蒸馏实现模态间的信息传递。
- 网络结构设计:
3.1 多模态分支(Multi-modal Branch)
- 输入:接收全切片图像(WSI)和临床数据
- WSI处理:WSI被分割成多个小区域(patches),输入到编码器中提取深度特征
- 临床表格数据处理:通过映射转换为相应的特征表示
- 融合:使用注意力机制将不同区域的WSI特征融合为单一的深度特征表示,并通过一个可学习的非线性投影函数 H(⋅)进行聚合,生成融合特征

- 分类器:融合后的特征输入到分类器中,进行最终的分类任务。
3.2 单模态分支(Single-modal Branch)
- 输入:仅接收全切片图像(WSI)
- 处理:类似于多模态分支,提取WSI的深度特征
- 知识蒸馏:通过引入可学习的提示(prompt),模拟临床数据的缺失,并从多模态分支接收相关知识
3.3 可学习的提示(prompt):
作用:在单模态分支中,当临床数据缺失时,提示用于模拟这部分数据的缺失,并帮助模型记住相关信息
实现:通过非线性函数,将提示向量转换为与临床数据特征维度相同的特征表示,并与WSI的深度特征结合,参与模型的预测
3.4 知识蒸馏机制
- 目的:确保单模态分支在缺失临床数据时,仍能获得多模态分支的知识
- 实现:通过定义蒸馏损失函数,将多模态分支的输出与单模态分支的输出进行比较,引导单模态分支学习
- 从多模态到单模态:将多模态分支学到的临床数据知识传递给单模态分支,帮助单模态分支在缺失临床数据时也能做出准确的预测
- 从单模态到多模态:将单模态分支学到的鲁棒特征传递给多模态分支,增强多模态分支对WSI的表示能力
3.5 损失函数设计
- 分类损失:使用交叉熵损失(Cross-Entropy Loss)来衡量模型预测与实际标签之间的差距。

- 蒸馏损失:用于知识从多模态分支到单模态分支的传递,以及反过来从单模态分支到多模态分支的鲁棒特征提取。使用均方误差(MSE)或散度(KL)等度量方法,来衡量两个分支输出之间的差异。

- 多模态分支的总体损失函数:结合了分类损失Lc和蒸馏损失Lf,用于同时优化模型的分类能力和知识传递能力。
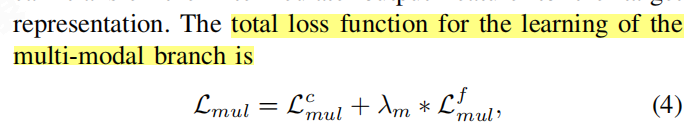
- 单模态分支的总体损失函数:结合了分类损失Lc和蒸馏损失Lf,但重点在于使用单模态数据模拟多模态情况,并从多模态分支中学习。
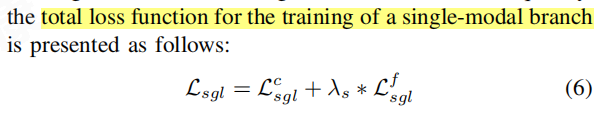
- 模型训练与测试
训练:两个分支同时训练,利用随机梯度下降等优化算法调整模型参数。
测试:根据模态的完整性,灵活选择使用单模态分支或多模态分支进行预测。
- 性能评估:通过AUC和F1分数评估模型在不同临床信息缺失率下的性能。
- 对比:
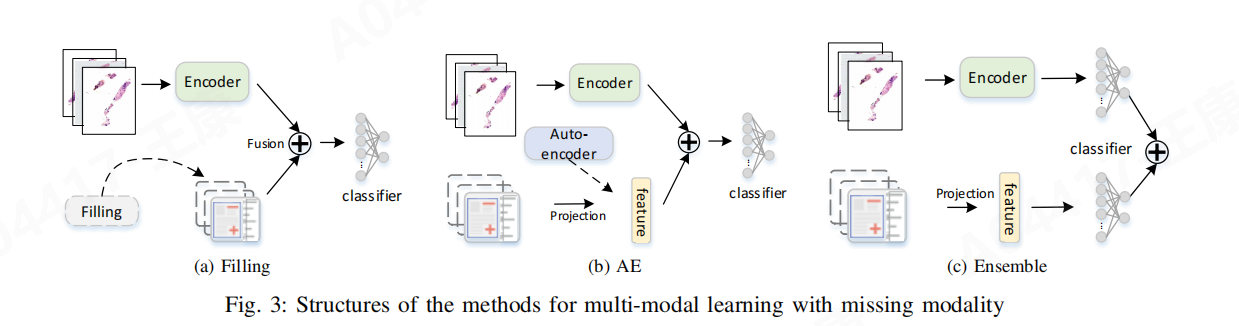
论文展示了Filling、AE、Ensemble共三种处理多模态学习中缺失模态问题的方法。
6.1 Filling(填充):在用零向量填充缺失的临床数据。这种方法假设缺失的数据值为零,从而保持模型输入的维度一致性。
- 原理:在模态完整时,这种方法与LNMP模型相同;在测试时模态缺失的情况下,使用零向量替代缺失的临床数据。
- 局限性:这种方法简单直接,但可能不会提供有关缺失数据的有价值信息,导致性能下降。
6.2 AE(自编码器):是一种生成模型,用于自动生成缺失的深度特征。
- 原理:该模型分为两个阶段训练。首先,训练一个LNMP模型,该模型在模态完整的训练集上学习。然后,训练一个自编码器来生成缺失的特征,自编码器的输入和输出分别是WSI的特征和临床数据的特征。
- 优势:能够学习如何从存在的数据中生成缺失的临床数据的表示。
6.3 Ensemble(集成方法):两个独立的网络,一个是WSI识别网络,另一个是临床数据的分类网络。
- 原理:WSI识别网络输出预测概率,临床数据的分类网络也输出预测概率,最终通过融合这两个概率得到最终的预测结果。如果没有临床数据输入,只使用WSI识别网络。
- 优势:在模态完整或不完整的情况下,通过集成两个网络的预测来提高性能。
这三种方法在论文中被用来与提出的双向蒸馏(BD)框架进行比较,以展示在处理临床数据缺失时的不同性能。通过实验结果,作者证明了BD框架在不同缺失率下的性能优于Filling、AE和Ensemble方法。
(三)提升
- 知识蒸馏:通过从多模态分支到单模态分支的知识传递,增强了模型对缺失数据的鲁棒性。
- 灵活性:BD框架能够根据测试数据的模态完整性灵活调整,提高了模型的实用性。
- 性能:在临床信息大量缺失的情况下,模型仍能保持较高的诊断性能。
(四)不足
- 泛化能力:论文未详细讨论模型在不同类型的医学图像和临床数据上的泛化能力。
- 临床验证:缺乏实际临床环境中的验证,模型的临床适用性尚未得到充分证实。
- 计算效率:论文未讨论模型的计算效率和在实际医疗系统中的部署问题。
(五)心得
多模态学习的重要性:理解了多模态数据融合在提高医学图像分析准确性方面的重要性。
知识蒸馏的应用:学习了知识蒸馏作为一种提高模型鲁棒性的有效技术。
本博文欢迎转载,转载请注明出处和作者。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号