

从RNN到BERT
一、文本特征编码
1. 标量编码
美国:1 中国:2 印度:3 … 朝鲜:197
标量编码问题:美国 + 中国 = 3 = 印度
2. One-hot编码
美国:[1,0,0,0,…,0]
中国:[0,1,0,0,…,0]
印度:[0,0,1,0,…,0]
美国 + 中国 = [1,1,0,0,…,0],代表拥有美国和中国双重国籍
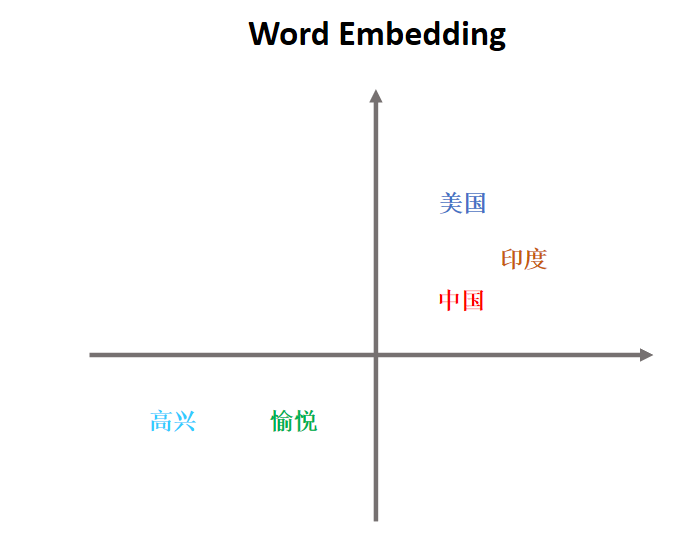
3. Embedding编码
二、文本序列化表示
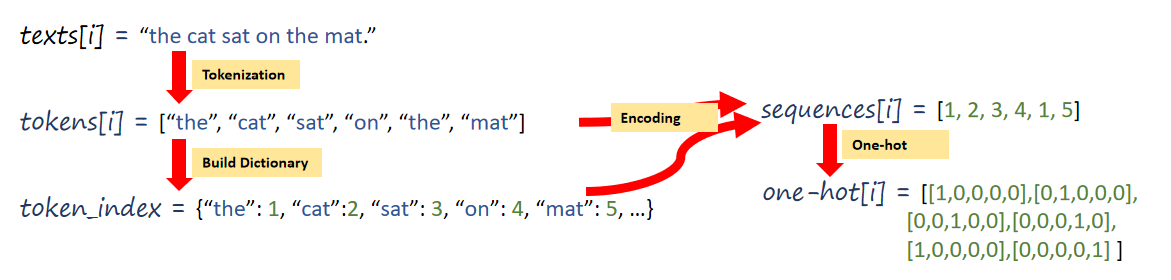
1、Tokenization

2、Build Dictionary


3、One-hot encoding
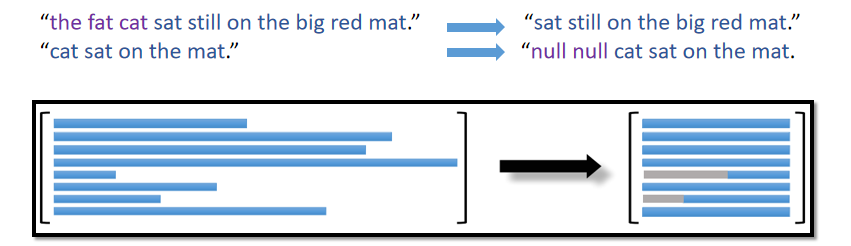
4、Align Sequences
三、RNN模型
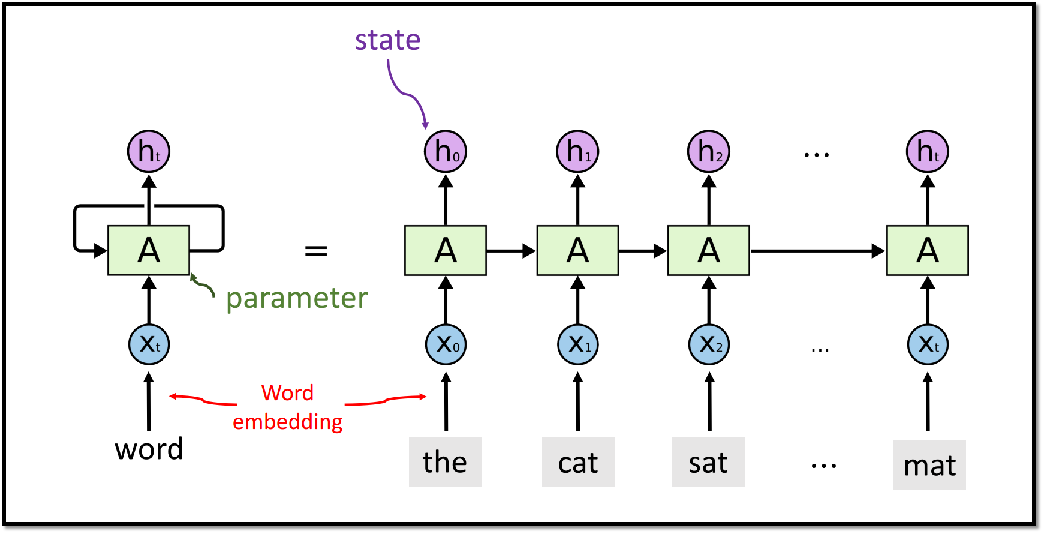
整个RNN只有一个参数矩阵A。RNN 在大规模的数据集上已经过时,不如Transformer模型,但在小规模数据集上,RNN还是很有用的。
3.1 RNN模型结构
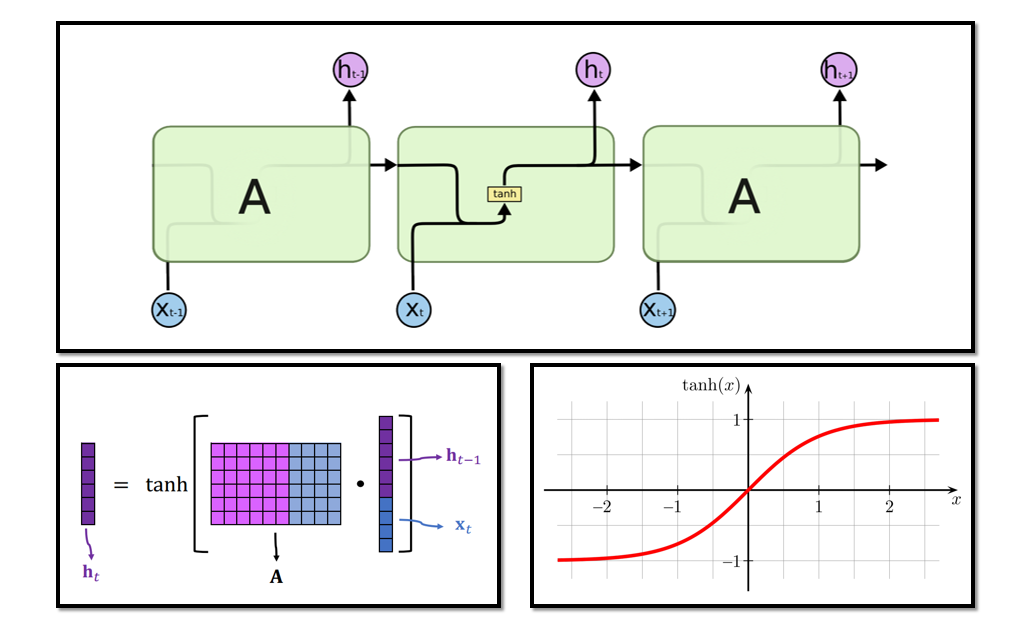
3.2 为什么用双曲正切?是否可去掉?

3.3 RNN的模型参数
参数矩阵A的行: shape(h)
参数矩阵A的列: shape(h)+shape(x)
总参数数量: shape(h)× [shape(h)+shape(x)] (未考虑偏移量bias)
输入x 的维度(词嵌入向量)应该通过交叉验证的方式选择 输出状态向量h的维度也应该通过交叉验证的方式选择。
3.4 基于RNN的分类任务
可以使用多个状态向量进行下游任务:
3.4.1 只使用最后一个状态向量

- Training Accuracy: 89.2%
- Validation Accuracy: 84.3%
- Test Accuracy: 84.4%
3.4.2 使用所有状态向量
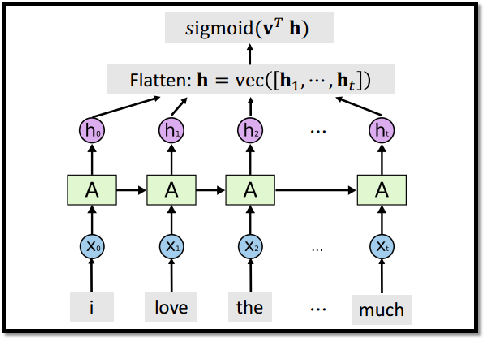
- Training Accuracy: 96.3%
- Validation Accuracy: 85.4%
- Test Accuracy: 84.7%
3.5 RNN的局限
RNN 在状态向量ht中积累xt及之前的所有信息,ht可以看作整个输入序列中抽取的特征向量
RNN 记忆比较短,会遗忘很久之前的输入x 。
四、LSTM模型
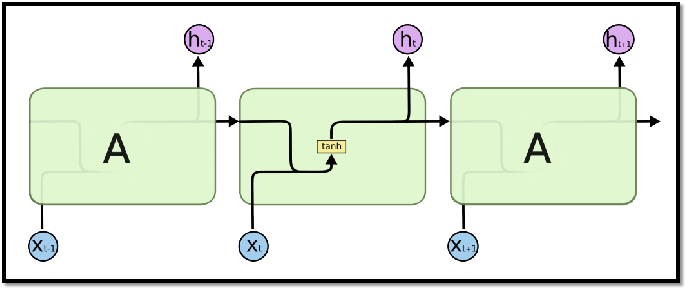
4.1 RNN与LSTM网络结构比较
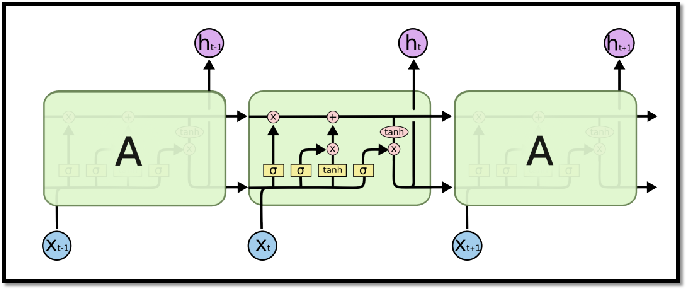
4.2 LSTM传送带
过去的信息直接流向未来。 LSTM使用“传送带”C 来获得比RNN更长的记忆。

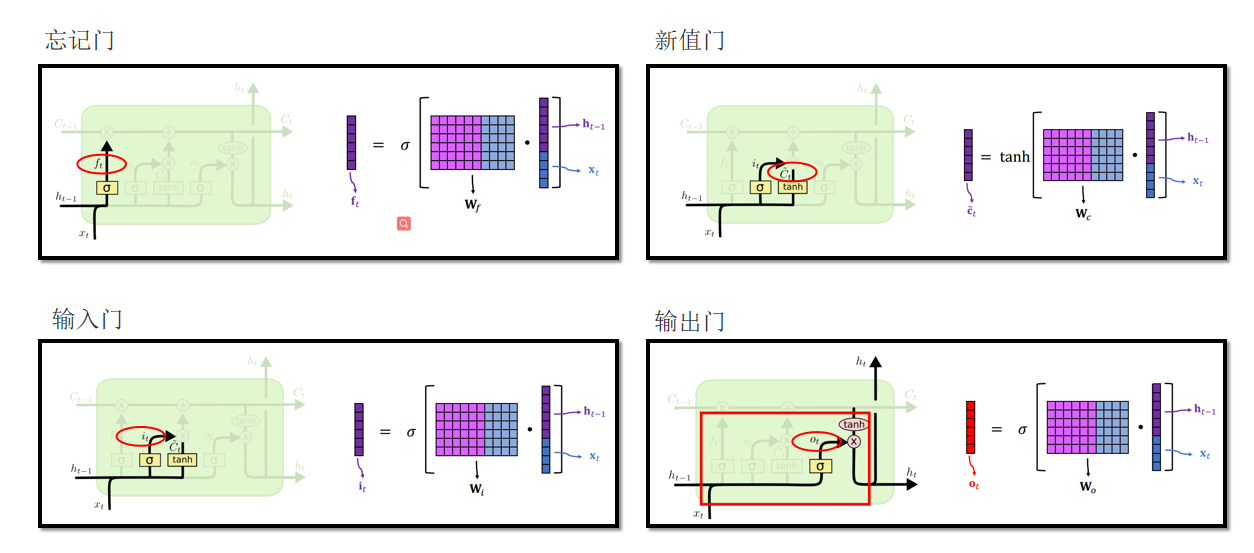
4.3 LSTM 门
4.4 Bi-LSTM
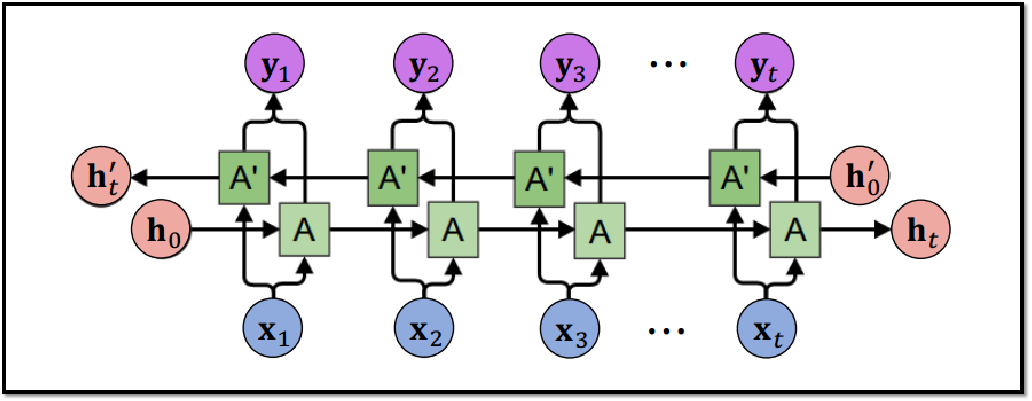
可以使用RNN或LSTM进行更为复杂的任务,例如机器翻译,下面会介绍机器翻译模型Seq2Seq。
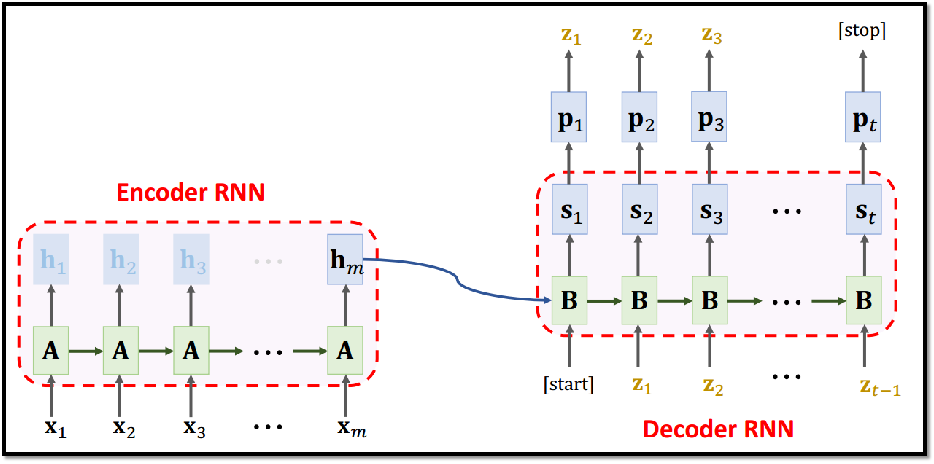
五、Seq2Seq模型
Seq2Seq模型用来进行句子翻译,Seq2Seq包括Encoder编码器以及Decoder 解码器 两部分,最早的Seq2Seq模型由两个RNN模型组成,如下图所示。
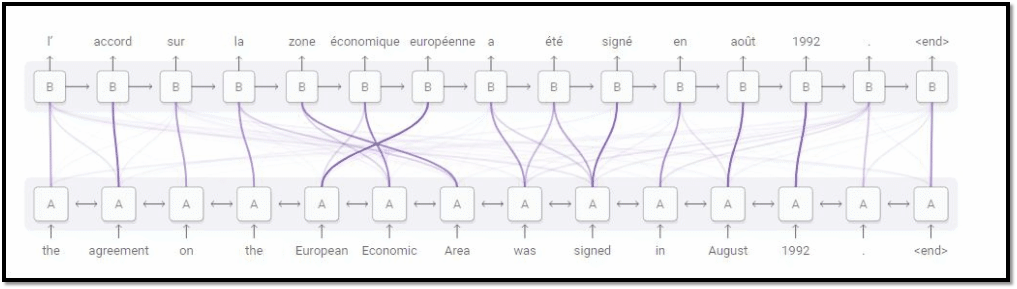
Attention对Seq2Seq网络的提升十分明显,如下图所示(BLEU:机器翻译评价指标,“双语评估替补”)

5.1 基于Attention的Seq2Seq模型
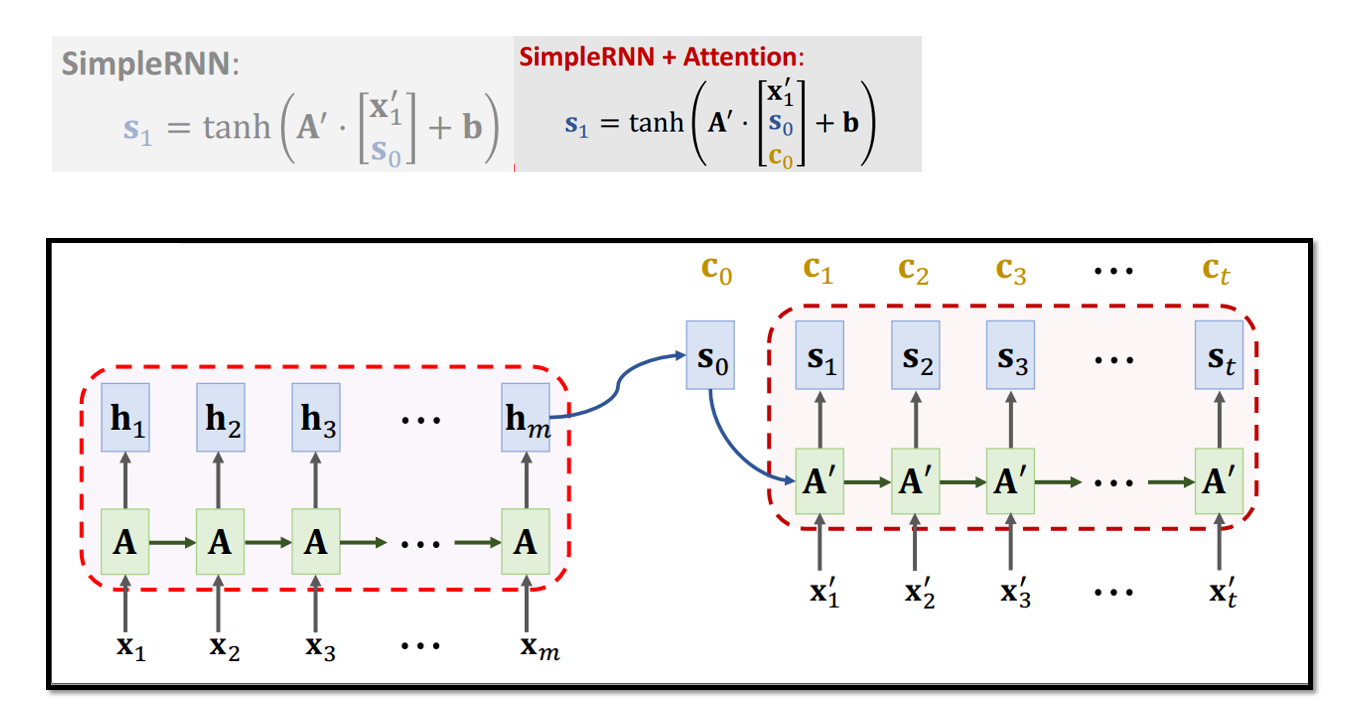
5.2 基于Attention的Seq2Seq模型参数计算
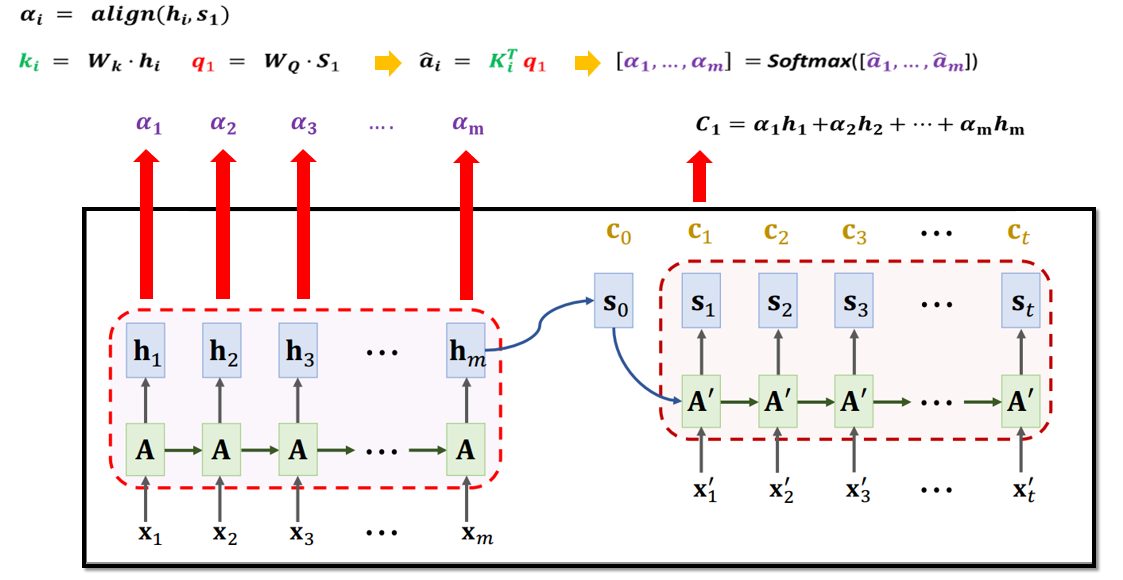
5.3 Attention的可解释性
无论输入多长,Attention都可以获得所有输入信息,且由于计算每个输出与所有输入的状态向量的相关性,所以会对相关的输入产生较高相关性,也就具备了一定的可解释性
六、Attention模型
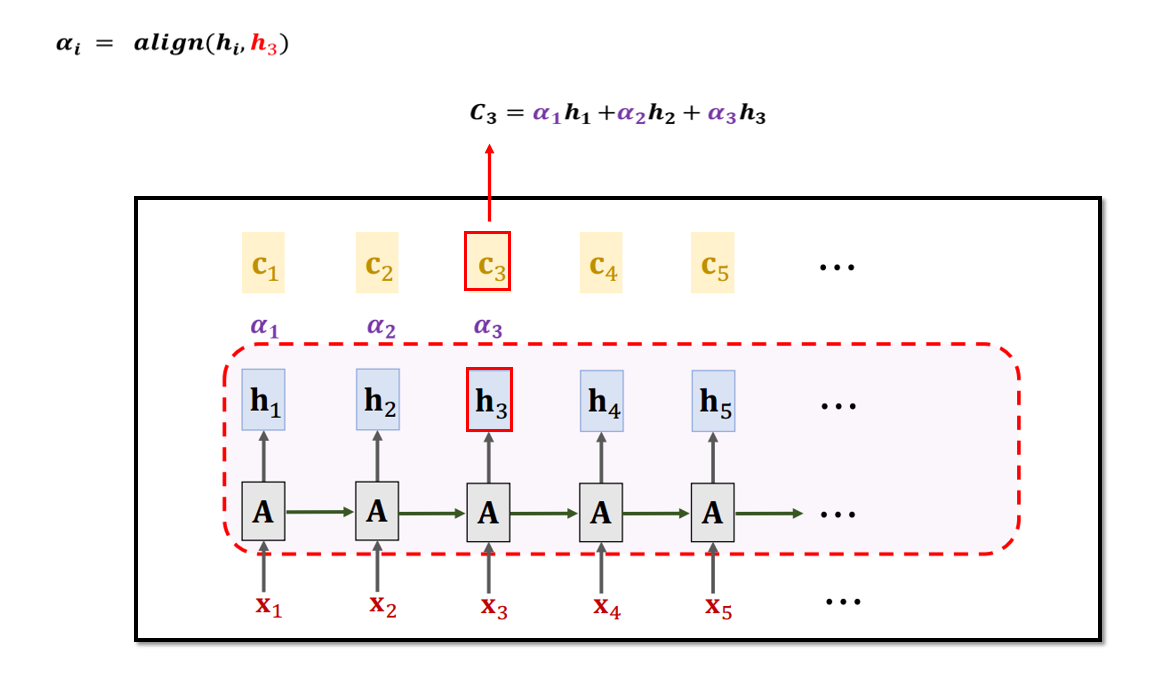
6.1 基于RNN的Self-Attention
Attention可以用来做句子翻译。 而Self-Attention可以用来代替RNN。 Self-Attention是Attention的特殊形式。Self-Attention模型其实就是在序列内部做Attention,寻找序列内部的联系。
例如输入一个句子,那么里面的每个词都要和该句子中的所有词进行attention计算。目的是学习句子内部的词依赖关系,捕获句子的内部结构。
Self-Attention和RNN最大的区别是不使用状态向量h,而是采用状态向量c 去更新下一个状态h。

6.2 基于RNN的Self-Attention参数计算
七、Transformer模型
- Transformer完全基于Self- Attention 和Attention Transformer 是一个 Seq2Seq 模型
- 不是 RNN
- 仅包含Self-Attention层 、Attention层 和全连接层
- Transformer完爆最好的RNN+Attention模型
7.1 Transformer中的Attention
Transformer中的Attention剔除了RNN,即没有循环部分。
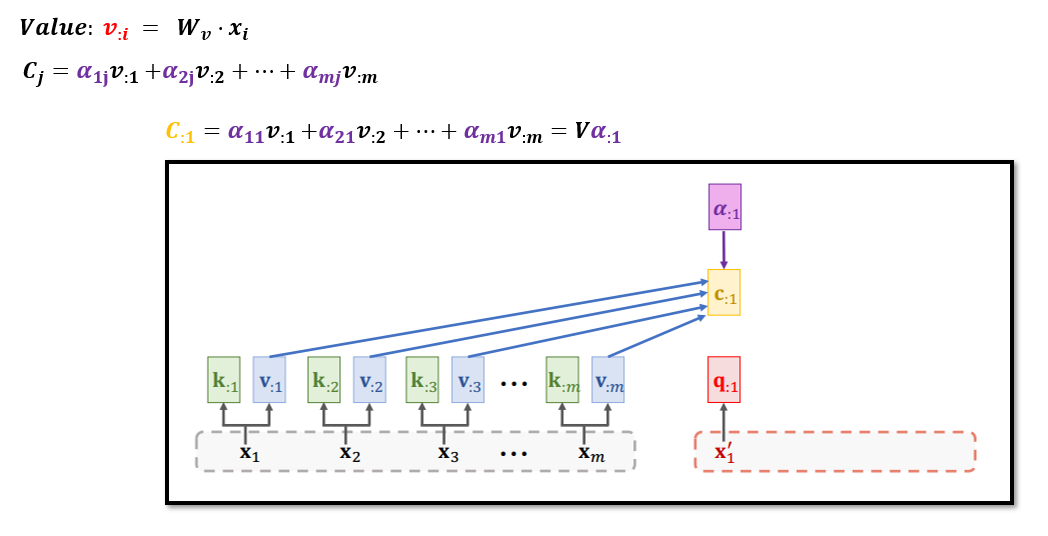
Attention层接收两个输入序列,分别为输入序列:𝒙_𝟏 , 𝒙_𝟐 , 𝒙_𝟑 ,…, 𝒙_(𝒎,)
输出序列:𝒙’_𝟏 , 𝒙‘_𝟐 , 𝒙’_𝟑 ,…, 𝒙′_𝒕
使用参数矩阵Wq生成q1,具体计算方式如下:
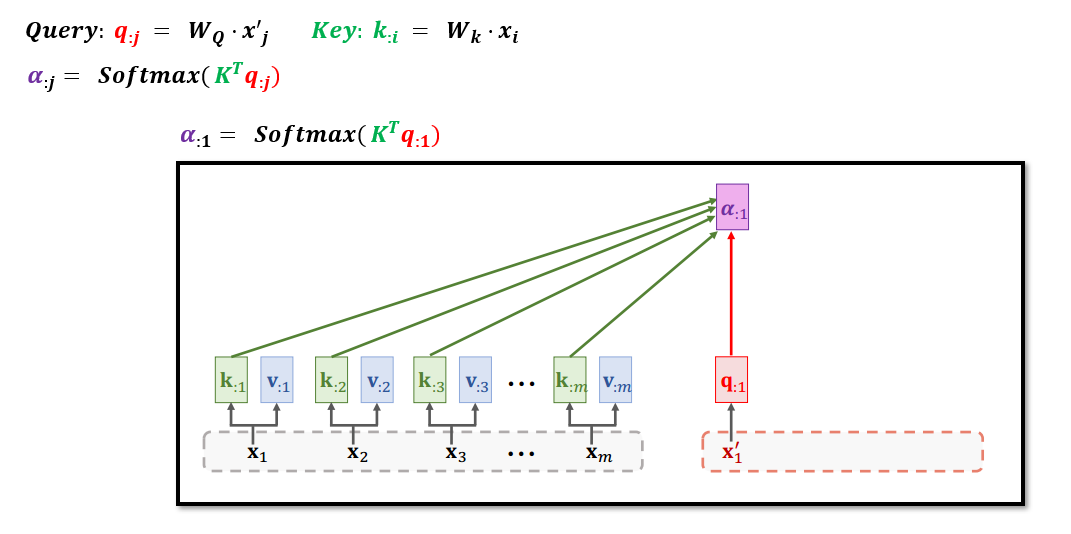
C1 依赖于所有的输入x1,x2,…,xm 以及当前的输入x’_1,具体计算方式如下:
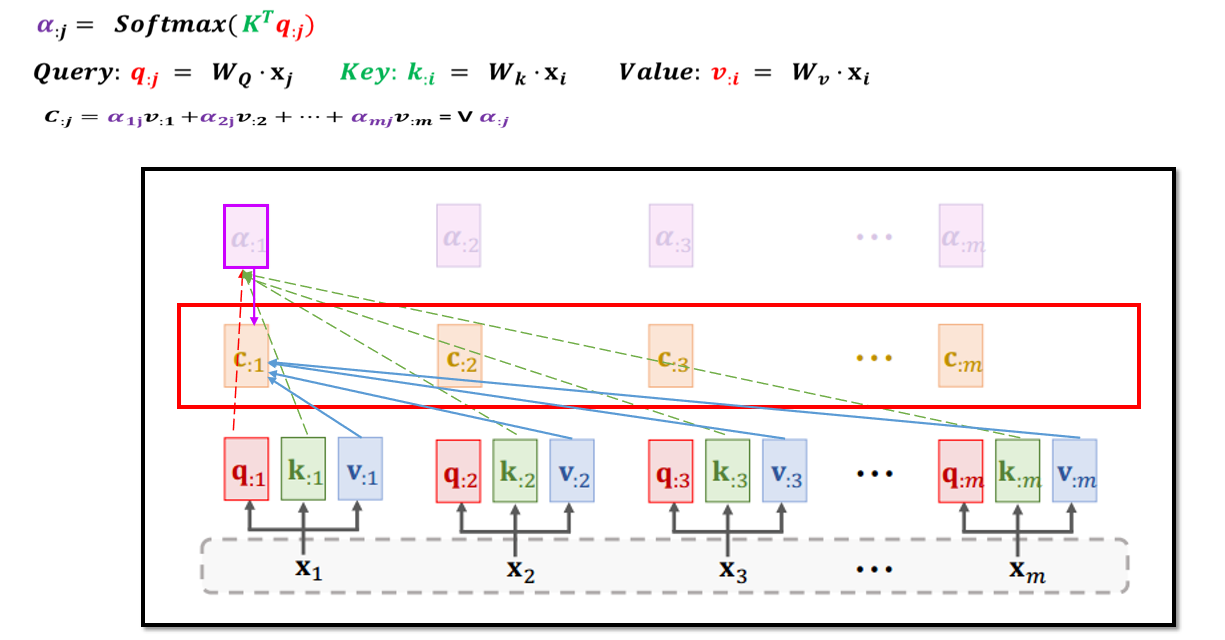
7.2 Transformer中的Self-Attention
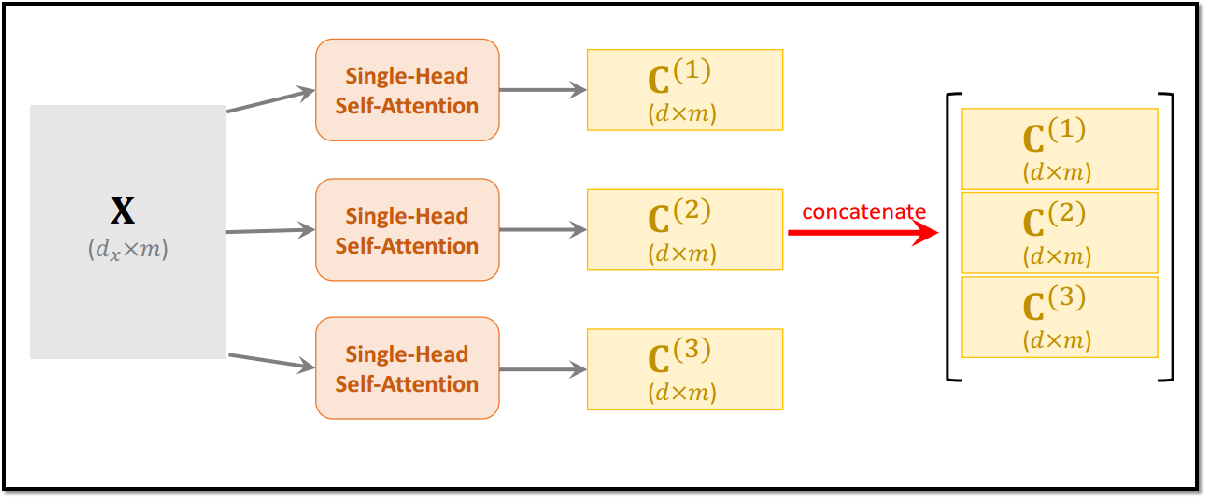
7.3 Transformer Multi-Head
7.4 Transformer Encoder
利用Self-Attention Layer + Dense Layer 构造Transformer模型的Encoder模块:
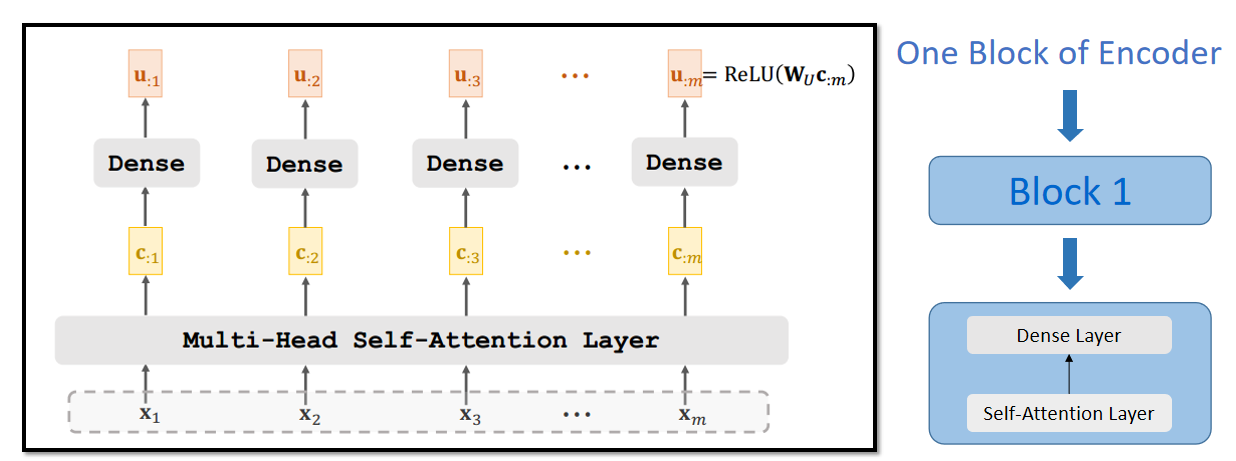
7.5 Transformer Encoder Block
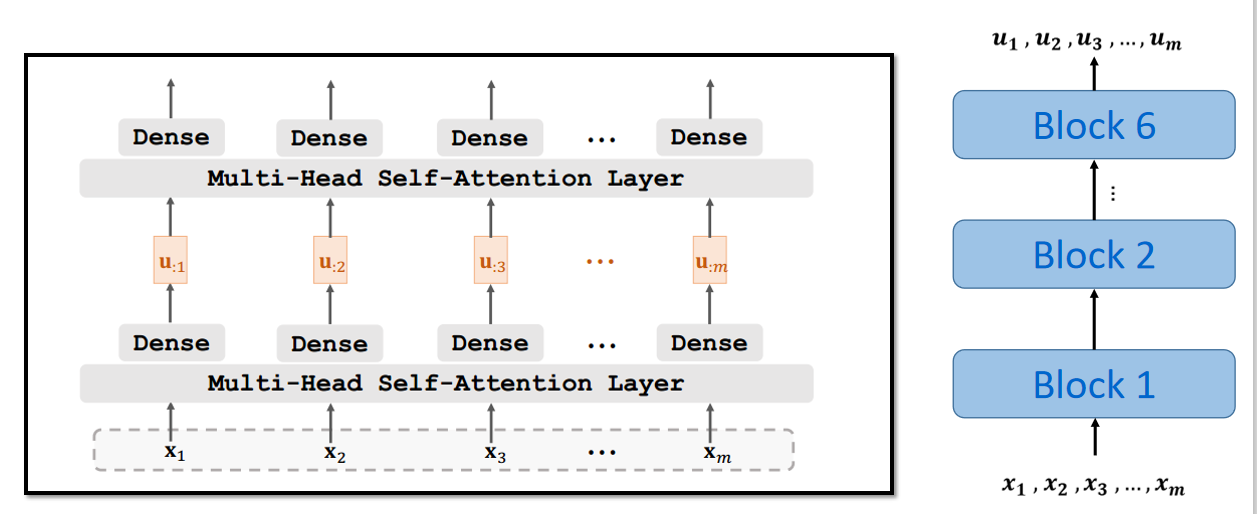
7.6 Transformer Decoder Block
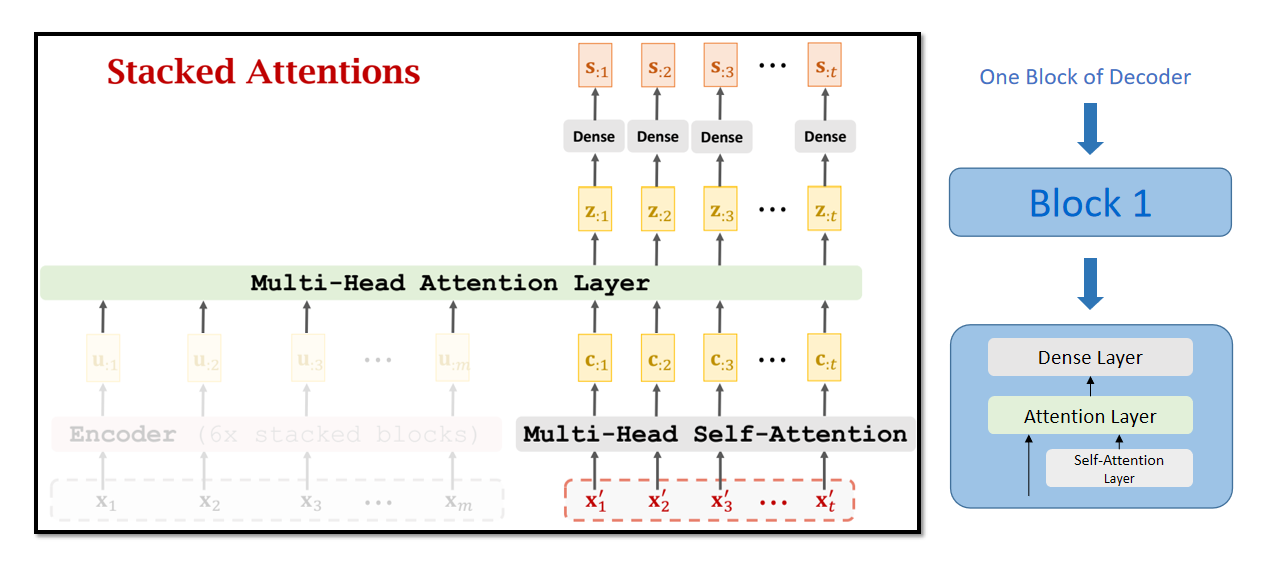
7.7 Transformer模型
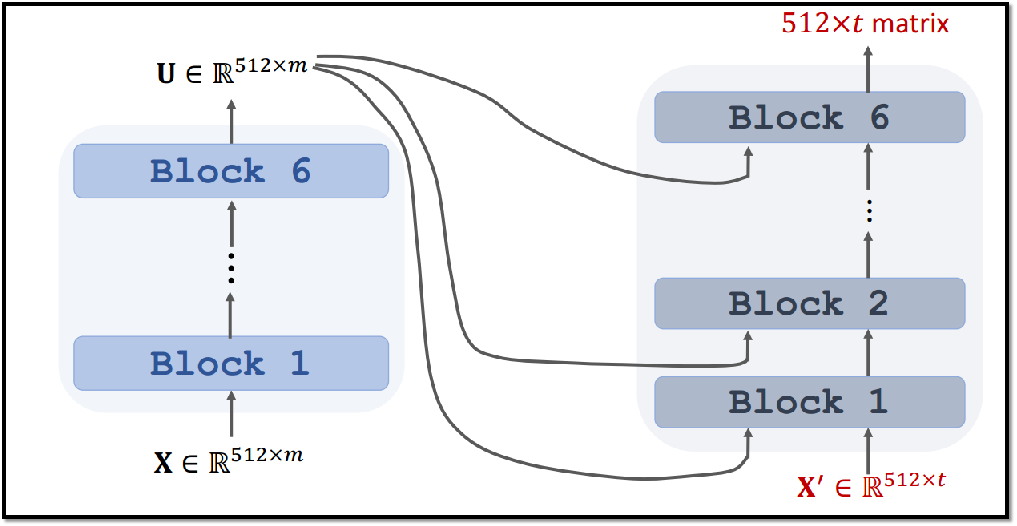
八、BERT
BERT的全称为Bidirectional Encoder Representations from Transformers 。
BERT 用来预训练Transformer模型的Encoder网络 两个基本任务: 1、预测被遮挡的单词: 随机遮挡单/多个单词,根据上下文预测被遮挡的单词。 2、预测两句话是否在原文里真实相邻。

8.1 BERT任务
8.1.1 任务一: 预测被遮挡的单词
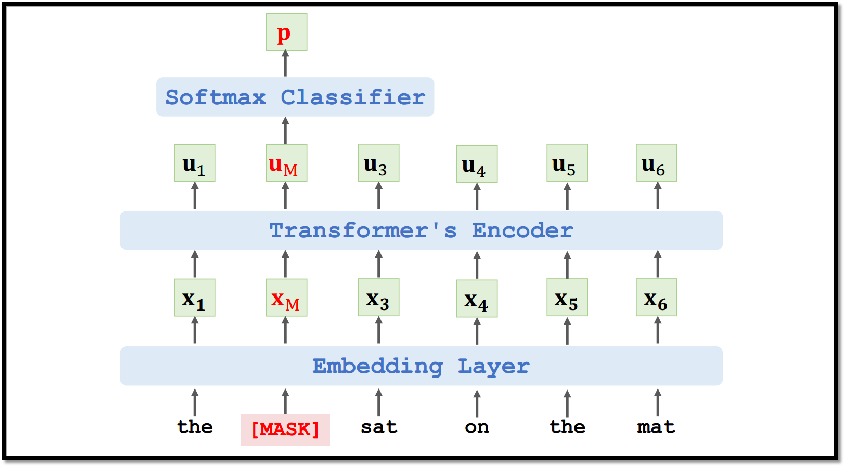
8.1.2 任务二: 预测两句话是否在原文里真实相邻
两句子拼接 训练数据构造 50%为真实相邻的句子,label=True(1); 50%为随机选择的句子,label=False(0)
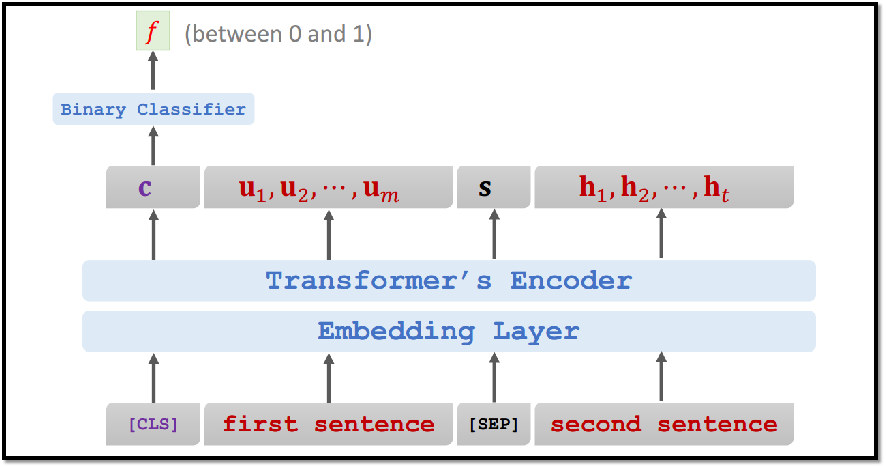
8.2 BERT如何改造下游任务
Bert具备广泛的通用性,就是说绝大部分NLP任务都可以采用类似的两阶段模式直接去提升效果。
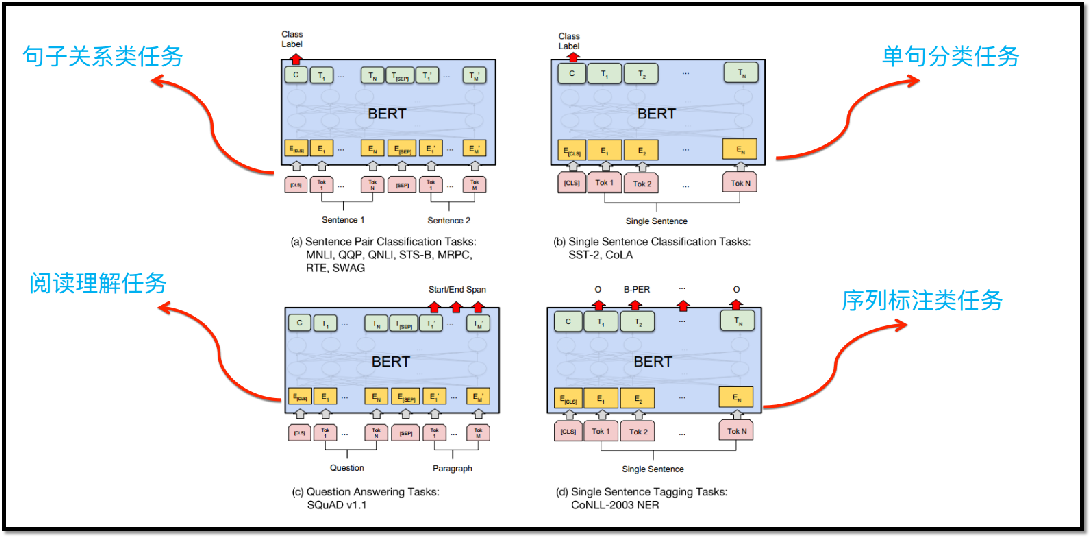
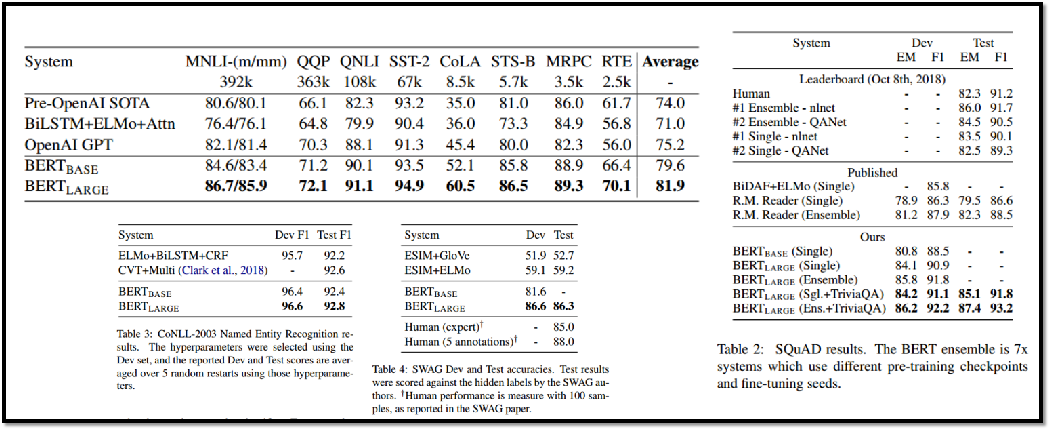
8.3 BERT效果
从模型创新角度看一般,创新不算大。但效果太好了,基本刷新了很多NLP的任务的最好性能。 Bert最大的亮点在于效果好及普适性强,几乎所有NLP任务都可以套用Bert这种两阶段解决思路,而且效果应该会有明显提升。
我的博客即将同步至腾讯云+社区,邀请大家一同入驻:https://cloud.tencent.com/developer/support-plan?invite_code=eji4i5y8xjp

