大数据概述
一.列举Hadoop生态的各个组件及其功能、以及各个组件之间的相互关系,以图呈现并加以文字描述。
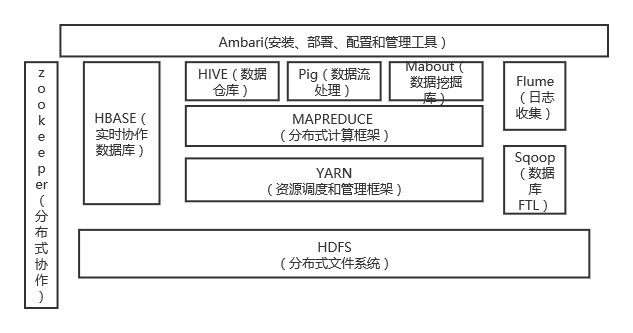
1.HDFS分布式文件系统
hadoop分布式文件系统HDFS是针对谷歌分布式文件系统(Google File System,GFS)的开源实现,它是Hadoop两大核心组成部分之一,提供了在廉价服务器集群中进行大规模分布式文件存储的能力。
2.MAPREDUCE 分布式计算框架
MapReduce 是一种分布式并行编程模型,用于大规模数据集(大于1TB)的并行运算,它将复杂的、运行于大规模集群上的并行计算过程高度抽象到两个函数:Map和Reduce。MapReduce极大方便了分布式编程工作,编程人员在不会分布式并行编程的情况下,也可以很容易将自己的程序运行在分布式系统上,完成海量数据集的计算。
3.YARN资源调度和管理框架
3.YARN资源调度和管理框架
YARN 是负责集群资源调度管理的组件。YARN 的目标就是实现“一个集群多个框架”,即在一个集群上部署一个统一的资源调度管理框架YARN,在YARN之上可以部署其他各种计算框架,比如MapReduce、Tez、Storm、Giraph、Spark、OpenMPI等,由YARN为这些计算框架提供统一的资源调度管理服务(包括 CPU、内存等资源),并且能够根据各种计算框架的负载需求,调整各自占用的资源,实现集群资源共享和资源弹性收缩。
4.4.HBase
HBase 是针对谷歌 BigTable 的开源实现,是一个高可靠、高性能、面向列、可伸缩的分布式数据库,主要用来存储非结构化和半结构化的松散数据。
HBase可以支持超大规模数据存储,它可以通过水平扩展的方式,利用廉价计算机集群处理由超过10亿行元素和数百万列元素组成的数据表
4.4.HBase
HBase 是针对谷歌 BigTable 的开源实现,是一个高可靠、高性能、面向列、可伸缩的分布式数据库,主要用来存储非结构化和半结构化的松散数据。
HBase可以支持超大规模数据存储,它可以通过水平扩展的方式,利用廉价计算机集群处理由超过10亿行元素和数百万列元素组成的数据表
5.Hive
Hive是一个基于Hadoop的数据仓库工具,可以用于对存储在Hadoop文件中的数据集进行数据整理、特殊查询和分析处理。
6.Flume
Flume 是 Cloudera 公司开发的一个高可用的、高可靠的、分布式的海量日志采集、聚合和传输系统。Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接收方的能力。
7.Sqoop
Sqoop是SQL-to-Hadoop的缩写,主要用来在Hadoop和关系数据库之间交换数据,可以改进数据的互操作性。
通过Sqoop,可以方便地将数据从MySQL、Oracle、PostgreSQL等关系数据库中导入Hadoop(比如导入到HDFS、HBase或Hive中),或者将数据从Hadoop导出到关系数据库,使得传统关系数据库和Hadoop之间的数据迁移变得非常方便。
通过Sqoop,可以方便地将数据从MySQL、Oracle、PostgreSQL等关系数据库中导入Hadoop(比如导入到HDFS、HBase或Hive中),或者将数据从Hadoop导出到关系数据库,使得传统关系数据库和Hadoop之间的数据迁移变得非常方便。
8. Sqoop 与 Pig
通过 Sqoop(SQL-to-Hadoop)就能实现,它主要用于传统数据库和 Hadoop 之间传输数据。数据的导入和导出本质上是 MapreDuce 程序,充分利用了 MR 的并行化和容错性。
Pig 与 Hive 类似,它定义了一种数据流语言,即 Pig Latin,它是 MapReduce 编程的复杂性的抽象,Pig Latin 可以完成排序、过滤、求和、关联等操作,支持自定义函数。Pig 自动把 Pig Latin 映射为 MapReduce 作业,上传到集群运行,减少用户编写 Java 程序的苦恼。
9.ZooKeeper(分布式协作服务)
对集群技术应该并不陌生,就拿最简单的双机热备架构来说,双机热备主要用来解决单点故障问题,传统的方式是采用一个备用节点,这个备用节点定期向主节点发送 ping 包,主节点收到 ping 包以后向备用节点发送回复信息,当备用节点收到回复的时候就会认为当前主节点运行正常,让它继续提供服务。而当主节点故障时,备用节点就无法收到回复信息了,此时,备用节点就认为主节点宕机,然后接替它成为新的主节点继续提供服务。
通过 Sqoop(SQL-to-Hadoop)就能实现,它主要用于传统数据库和 Hadoop 之间传输数据。数据的导入和导出本质上是 MapreDuce 程序,充分利用了 MR 的并行化和容错性。
Pig 与 Hive 类似,它定义了一种数据流语言,即 Pig Latin,它是 MapReduce 编程的复杂性的抽象,Pig Latin 可以完成排序、过滤、求和、关联等操作,支持自定义函数。Pig 自动把 Pig Latin 映射为 MapReduce 作业,上传到集群运行,减少用户编写 Java 程序的苦恼。
9.ZooKeeper(分布式协作服务)
对集群技术应该并不陌生,就拿最简单的双机热备架构来说,双机热备主要用来解决单点故障问题,传统的方式是采用一个备用节点,这个备用节点定期向主节点发送 ping 包,主节点收到 ping 包以后向备用节点发送回复信息,当备用节点收到回复的时候就会认为当前主节点运行正常,让它继续提供服务。而当主节点故障时,备用节点就无法收到回复信息了,此时,备用节点就认为主节点宕机,然后接替它成为新的主节点继续提供服务。
10.Ambari(大数据运维工具)
Ambari 是一个大数据基础运维平台,它实现了 Hadoop 生态圈各种组件的自动化部署、服务管理和监控告警,Ambari 通过 puppet 实现自动化安装和配置,通过 Ganglia 收集监控度量指标,用 Nagios 实现故障报警。目前 Ambari 已支持大多数 Hadoop 组件,包括 HDFS、MapReduce、Oozie、Hive、Pig、 Hbase、ZooKeeper、Sqoop、Kafka、Spark、Druid、Storm 等几十个常用的 Hadoop 组件。
二.对比Hadoop与Spark的优缺点。
Ambari 是一个大数据基础运维平台,它实现了 Hadoop 生态圈各种组件的自动化部署、服务管理和监控告警,Ambari 通过 puppet 实现自动化安装和配置,通过 Ganglia 收集监控度量指标,用 Nagios 实现故障报警。目前 Ambari 已支持大多数 Hadoop 组件,包括 HDFS、MapReduce、Oozie、Hive、Pig、 Hbase、ZooKeeper、Sqoop、Kafka、Spark、Druid、Storm 等几十个常用的 Hadoop 组件。
二.对比Hadoop与Spark的优缺点。
hadoop:两步计算在磁盘存储
Spark:多布计算,内存存储
Hadoop的优点:
1、高可靠性2、高扩展性3、高效性4、高容错性。
Hadoop的不足
Hadoop作为一个处理大数据的软件框架,虽然受到众多商业公司的青睐,但是其自身的技术特点也决定了它不能完全解决大数据问题。在当前Hadoop的设计中,所有的metadata操作都要通过集中式的NameNode来进行,NameNode有可能是性能的瓶颈。当前Hadoop单一NameNode、单一Jobtracker的设计严重制约了整个Hadoop可扩展性和可靠性。
Spark的优缺点
首先,Spark 把中间数据放到内存中,迭代运算效率高。MapReduce 中计算结果需要落地,保存到磁盘上,这样势必会影响整体速度,而 Spark 支持 DAG 图的分布式并行计算的编程框架,减少了迭代过程中数据的落地,提高了处理效率。(延迟加载)
其次,Spark 容错性高。Spark 引进了弹性分布式数据集 RDD (Resilient DistributedDataset) 的抽象,它是分布在一组节点中的只读对象集合,这些集合是弹性的,如果数据集一部分丢失,则可以根据“血统”(即允许基于数据衍生过程)对它们进行重建。另外在RDD 计算时可以通过 CheckPoint 来实现容错。
最后,Spark 更加通用。mapreduce 只提供了 Map 和 Reduce 两种操作,Spark 提供的数据集操作类型有很多,大致分为:Transformations 和 Actions 两大类。Transformations包括 Map、Filter、FlatMap、Sample、GroupByKey、ReduceByKey、Union、Join、Cogroup、MapValues、Sort 等多种操作类型,同时还提供 Count, Actions 包括 Collect、Reduce、Lookup 和 Save 等操作
其次,Spark 容错性高。Spark 引进了弹性分布式数据集 RDD (Resilient DistributedDataset) 的抽象,它是分布在一组节点中的只读对象集合,这些集合是弹性的,如果数据集一部分丢失,则可以根据“血统”(即允许基于数据衍生过程)对它们进行重建。另外在RDD 计算时可以通过 CheckPoint 来实现容错。
最后,Spark 更加通用。mapreduce 只提供了 Map 和 Reduce 两种操作,Spark 提供的数据集操作类型有很多,大致分为:Transformations 和 Actions 两大类。Transformations包括 Map、Filter、FlatMap、Sample、GroupByKey、ReduceByKey、Union、Join、Cogroup、MapValues、Sort 等多种操作类型,同时还提供 Count, Actions 包括 Collect、Reduce、Lookup 和 Save 等操作
三.如何实现Hadoop与Spark的统一部署?
Hadoop和Spark的统一部署
一方面,由于Hadoop生态系统中的一些组件所实现的功能,目前还是无法由Spark取代的,比如,Storm可以实现毫秒级响应的流计算,但是,Spark则无法做到毫秒级响应。另一方面,企业中已经有许多现有的应用,都是基于现有的Hadoop组件开发的,完全转移到Spark上需要一定的成本。因此,在许多企业实际应用中,Hadoop和Spark的统一部署是一种比较现实合理的选择。
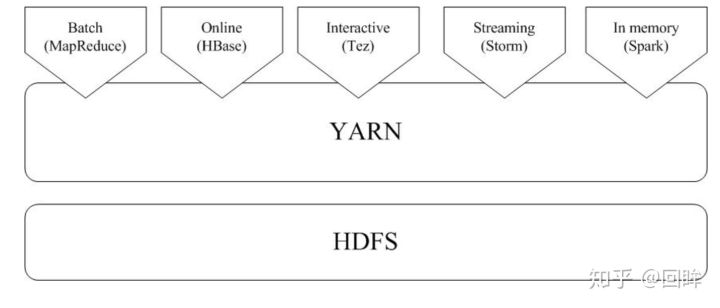
由于Hadoop MapReduce、HBase、Storm和Spark等,都可以运行在资源管理框架YARN之上,因此,可以在YARN之上进行统一部署(如图9-16所示)。这些不同的计算框架统一运行在YARN中,可以带来如下好处: