
数据采集第三次作业
目录:
指定一个网站,爬取这个网站中的所有的所有图片,例如中国气象网(http://www.weather.com.cn)。分别使用单线程和多线程的方式爬取。(限定爬取图片数量为学号后4位)
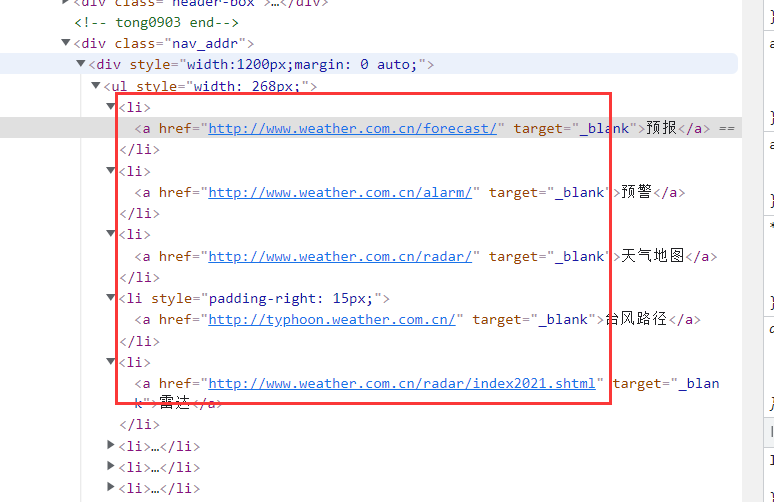
由图片可知,网页的href地址获取如下:
href = re.findall(r'<a href=\"(.*?)\"', html)在获取的每个href地址中获取图片:
由于我在运行过程中只要出现 href = javascript:vvoid(0),后续都无法提取图片url,故修改如下:
for i in range(len(href)):
path = href[i].strip()
# 如果path= 'javascript:void(0)'
# 将略过该href,否则后续无法获得图片url
if path == 'javascript:void(0)':
continue
print("href路径:" + path)
html = getHTMLText(path)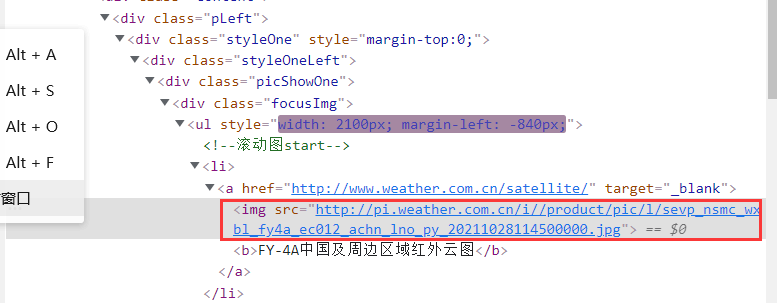
经过观察发现,图片地址大部分都在img src 中,故提取图片地址:
jpg1 = re.findall(r'<img src=\"(.*?)\"', html)
t = t + 1
for i in range(len(jpg1)):
path = jpg1[i].strip()
print("图片路径:"+path)
pic = requests.get(path, timeout=10).content
https://gitee.com/wjz51/wjz/blob/master/project_3/3_1_2.py
多线程核心部分:
# target是要执行的线程函数,args是一个元组或者列表为target的函数提供参数
T = threading.Thread(target=savejpg,args=(pic,i+t))
# 非守护线程,也称为前台线程
T.setDaemon(False)
# 然后调用T.start()就开始了线程
T.start()
threads.append(T)
https://gitee.com/wjz51/wjz/blob/master/project_3/3_1_1.py
此次实验我巩固了多线程爬取,和掌握了如何在网页中打开href链接。
遇到的问题是只要出现 href = javascript:vvoid(0),后续都无法提取图片url;
解决办法是
if path == 'javascript:void(0)':
continue使用scrapy框架复现作业①。
class WeatherItem(scrapy.Item):
# 爬取图片并保存需要的字段
image_urls = scrapy.Field()
images = scrapy.Field()
image_paths = scrapy.Field()class WeaSpider(scrapy.Spider):
name = 'wea'
allowed_domains = ['weather.com.cn']
start_urls = ['http://www.weather.com.cn/']
def parse(self, response):
divs = response.xpath("//img")
for div in divs:
item = WeatherItem()
path = div.xpath("./@src").get()
item["image_urls"] = [path]#图片路径
yield item
# 下一页地址
for url in response.xpath('//a/@href').extract():
yield scrapy.Request(url, callback=self.parse, dont_filter=False)# Obey robots.txt rules
ROBOTSTXT_OBEY = False # false 表示不遵循robot.txt 协议
# 注释:表示没有开启cookie, false:表示使用setting里设置的cookie, true: 表示使用自定义的cookie
COOKIES_ENABLED = True图片保存目录地址:
ITEM_PIPELINES = {
'weather.pipelines.WeatherImgDownloadPipeline': 300,
}
IMAGES_STORE = 'E:\\数据采集作业\\image' # 设置保存图片的根目录class WeatherImgDownloadPipeline(ImagesPipeline):
count = 0
# 设置下载文件请求的请求头
default_headers = {
'referer': 'http://www.weather.com.cn/',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36',
}
# 伪装成站内请求,反反爬
def get_media_requests(self, item, info):
for image_url in item['image_urls']:
self.default_headers['referer'] = image_url
yield Request(image_url, headers=self.default_headers)
# 自定义 文件路径 和 文件名
def file_path(self, request, item, response=None, info=None):
if WeatherImgDownloadPipeline.count >= 137:
WeatherImgDownloadPipeline.count = 0
WeatherImgDownloadPipeline.count += 1
image_guid = str(WeatherImgDownloadPipeline.count)
return f'/{image_guid}.jpg'
# 获取文件的存放路径
def item_completed(self, results, item, info):
image_paths = [x['path'] for ok, x in results if ok]
if not image_paths:
raise DropItem("Item contains no images")
item['image_paths'] = image_paths
return item
https://gitee.com/wjz51/wjz/tree/master/project_3/3_2
在该作业中巩固了scrapy框架爬取数据方法以及xpath爬取信息的方法,收获颇丰
爬取豆瓣电影数据使用scrapy和xpath,并将内容存储到数据库,同时将图片存储在
imgs路径下。
class DoubanItem(scrapy.Item):
# define the fields for your item here like:
num = scrapy.Field()#排名
name = scrapy.Field()#电影名称
director = scrapy.Field()#导演
actor = scrapy.Field()#主演
title = scrapy.Field()#简介
rank = scrapy.Field()#评分
# 爬取图片并保存需要的字段
url = scrapy.Field()
image_urls = scrapy.Field()
images = scrapy.Field()
image_paths = scrapy.Field()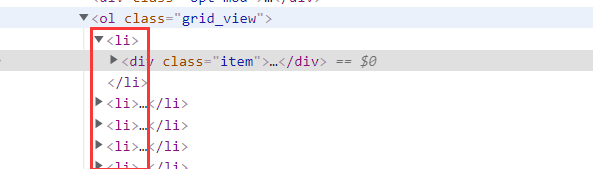
观察发现,所有信息均在li下:
divs = response.xpath("//ol[@class='grid_view']//li")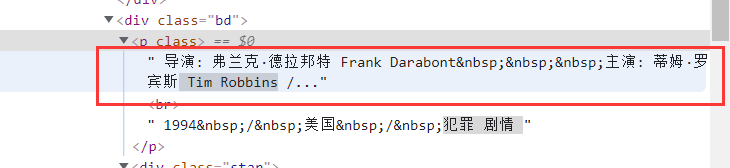
由于要提取的导演和主演在一个信息里面,所以我用了split处理
在运行过程中出现了空值情况,所以做了如下修改:
acts = div.xpath("div//p[1]/text()").get()
act = acts.split("主演:")
if len(act)==2:
dir = act[0].split("导演:")
item['director'] = dir[1] # 导演
item['actor'] = act[1] # 主演
else:
dir = act[0].split("导演:")
item['director'] = dir[1] # 导演
item['actor'] = ' ' # 主演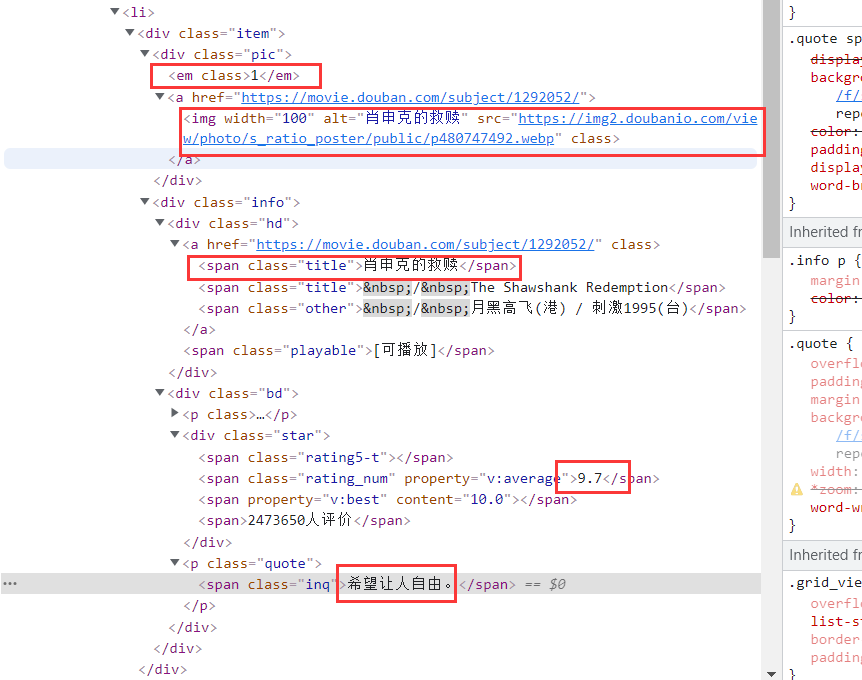
观察上图,提取要求信息
divs = response.xpath("//ol[@class='grid_view']//li")
for div in divs:
item = DoubanItem()
item['num'] = div.xpath("div//div[1]//em/text()").get()
item['name'] = div.xpath("div//a//span[1]/text()").get() # 电影名称
acts = div.xpath("div//p[1]/text()").get()
act = acts.split("主演:")
if len(act)==2:
dir = act[0].split("导演:")
item['director'] = dir[1] # 导演
item['actor'] = act[1] # 主演
else:
dir = act[0].split("导演:")
item['director'] = dir[1] # 导演
item['actor'] = ' ' # 主演
item['title'] = div.xpath("div//p[@class='quote']//span/text()").get() # 简介
item['rank'] = div.xpath("div//div[@class='star']//span[2]/text()").get() # 评分
path = div.xpath("div//a//@src").get() #图片地址
item['url'] = path
item["image_urls"] = [path]
yield itemFEED_EXPORT_ENCODING = 'utf-8'
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36 SLBrowser/7.0.0.9231 SLBChan/23'
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
}数据库和图片下载
ITEM_PIPELINES = {
'douban.pipelines.DoubanPipeline': 300,#数据库
'douban.pipelines.DoubanImgDownloadPipeline': 300,#图片下载
}
IMAGES_STORE = 'E:\\数据采集作业\\imgs' # 设置保存图片的根目录需要注意的是,我在运行过程中,使用 create table movies 只会存入一行数据,故使用 create table if not exists movies
self.cursor.execute(
"create table if not exists movies (排名 varchar(16),电影名称 varchar(16),导演 varchar(16),\
主演 varchar(16),简介 varchar(16),电影评分 varchar(16),电影封面 varchar(16) )")数据库打开、插入、关闭部分如下
class DB:
#打开数据库的方法
def openDB(self):
self.con = sqlite3.connect("movies3.db")
self.cursor = self.con.cursor()
try:
self.cursor.execute(
"create table if not exists movies (排名 varchar(16),电影名称 varchar(16),导演 varchar(16),主演 varchar(16),简介 varchar(16),电影评分 varchar(16),电影封面 varchar(16) )")
except:
self.cursor.execute("delete from movies")
#关闭数据库的方法
def closeDB(self):
self.con.commit()
self.con.close()
#插入数据的方法
def insert(self, num,name, director, actor, title, rank, url):
try:
self.cursor.execute("insert into movies (排名,电影名称,导演,主演,简介,电影评分,电影封面) values (?,?,?,?,?,?,?)",( num,name, director, actor, title, rank, url))
except Exception as err:
print(err)
插入数据到数据库:
class DoubanPipeline:
def process_item(self, item, spider):
self.db = DB()
self.db.openDB()
self.db.insert(item["num"], item["name"], item["director"], item["actor"], item["title"],
item["rank"], item["url"])
self.db.closeDB()
return item
下载图片:
class DoubanImgDownloadPipeline(ImagesPipeline):
count = 0
# 设置下载文件请求的请求头
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36 SLBrowser/7.0.0.9231 SLBChan/23'
# 自定义 文件路径 和 文件名
def file_path(self, request, item, response=None, info=None):
DoubanImgDownloadPipeline.count += 1
image_guid = str(DoubanImgDownloadPipeline.count)
return f'/{image_guid}.jpg'
# 获取文件的存放路径
def item_completed(self, results, item, info):
image_paths = [x['path'] for ok, x in results if ok]
if not image_paths:
raise DropItem("Item contains no images")
item['image_paths'] = image_paths
return item
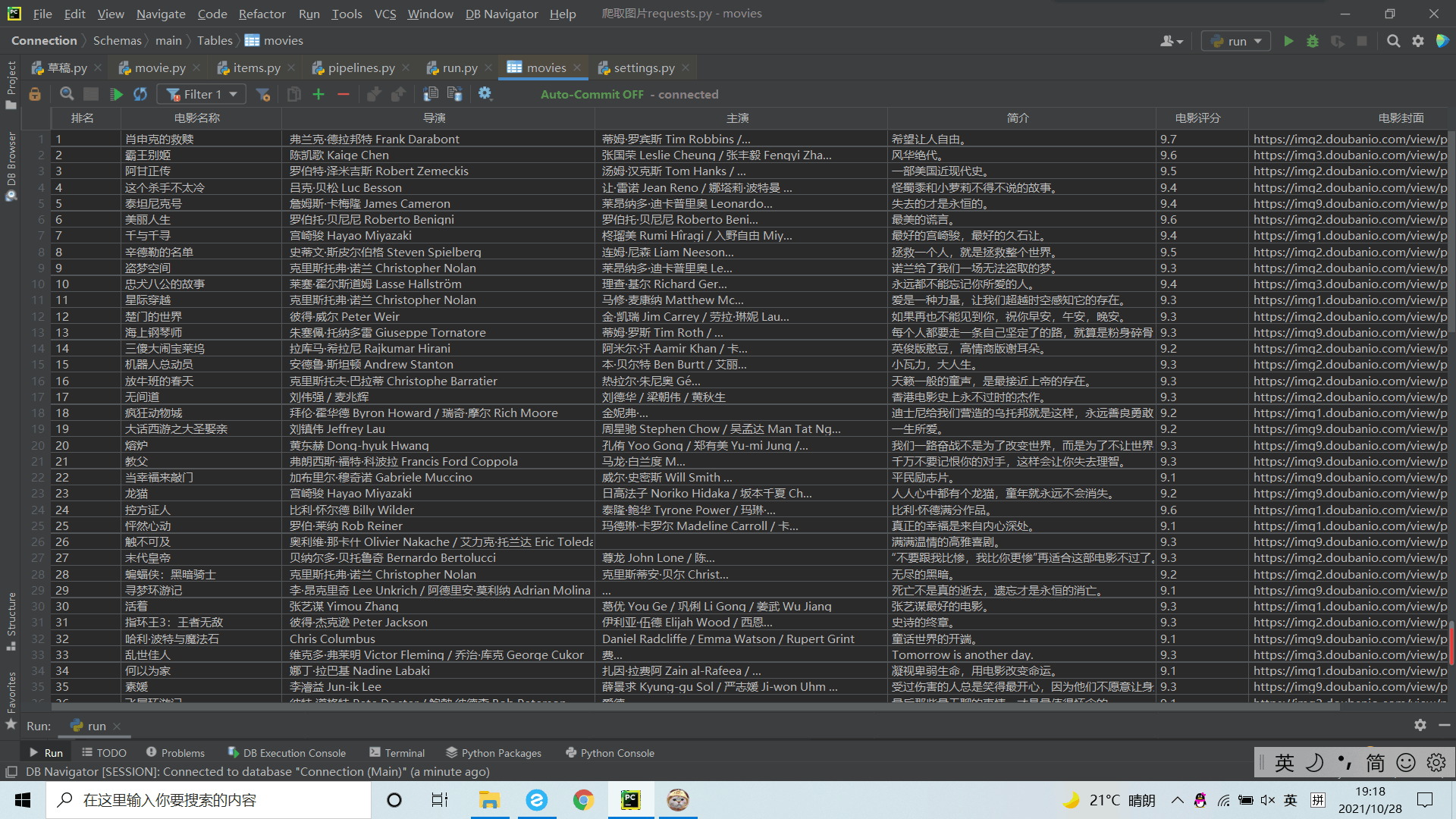
https://gitee.com/wjz51/wjz/tree/master/project_3/3_3
学习了对爬取的数据存在不完整性或缺陷的处理;
巩固了数据库相关知识点以及scrapy框架爬取数据方法以及xpath爬取信息的方法
