《机器学习实战》朴素贝叶斯
1.朴素贝叶斯理论
注释:斯坦福大学课程有朴素贝叶斯,之前也看过相关文献,现在学起来比较省力。
http://www.cnblogs.com/wjy-lulu/p/7770450.html
理论部分直接看上面我之前写的博文就可以啦,如果没有点基础直接写代码有点麻烦!
2.代码实现
2.1构造特征向量
1 #建立数据和标签 2 def loadDataSet(): 3 postingList = [ 4 ['my','dog','has','has','flea','problems','help','please'] 5 ['maybe','not','take','him','to','dog','park','stupid'] 6 ['my','dalmation','is','so','cute','I','love','him'] 7 ['stop','posting','stupid','worthless','garbage'] 8 ['mr','licks','ate','my','steak','how','to','stop','him'] 9 ['quit','buying','worthless','dog','food','food','stupid'] 10 ] 11 classVec = [0,1,0,1,0,1]#标签 12 return postingList, classVec 13 #得到样本里面不同特征的数量 14 def creatVocaList(dataSet): 15 vocbSet = set([]) 16 for document in dataSet: 17 vocbSet = vocbSet | set(document) #求并集 18 return list(vocbSet) #转化为list输出 19 #对输入数据进行标记,这里看不懂的可以看博文首页的 20 #当然,如果你输入的数据要是样本没有的特征,那就GG 21 def setOfWord2Vec(vocabList,inputSet): 22 returnVec = [0]*len(vocabList) 23 for word in inputSet: 24 if word in vocabList: 25 returnVec[vocabList.index(word)] = 1 26 else: 27 print('the word : %s is not in my Vocabulary!',word) 28 return returnVec
2.2词向量计算概率
1 def trainNB0(trainMtraix,trainCategory): 2 #trainMtraix:标记好的样本 3 #trainCategory:标签 4 numTrainDocs = len(trainMtraix)#样本数量 5 numWords = len(trainMtraix[0])#每个样本的特征数 6 pAbusive = sum(trainCategory)/float(numTrainDocs)#侮辱类百分比,由于是二项分布所以1-P(A)就可以 7 p0Num = np.ones(numWords);p1Num = np.ones(numWords) 8 p0Denom = 2.0; p1Denom = 2.0 #除法之后变为浮点数 9 for i in range(numTrainDocs): 10 if trainCategory[i] == 1: 11 p1Num += trainMtraix[i] #侮辱类样本特征 12 p1Denom += sum(trainMtraix[i])#侮辱类样本数量 13 else: 14 p0Num += trainMtraix[i] 15 p0Denom += sum(trainMtraix[i]) 16 p1Vect = np.log(p1Num/p1Denom) #侮辱类特征百分比 17 p0Vect = np.log(p0Num/p0Denom) # 18 #侮辱类特征百分比/非侮辱类特征百分比/侮辱类样本百分比 19 return p0Vect, p1Vect, pAbusive
1 #这个函数细节见博文说明 2 def classfyNB(vec2Classfy,p0Vec,p1Vec,pClass1): 3 p1 = sum(vec2Classfy*p1Vec) + np.log(pClass1) 4 p0 = sum(vec2Classfy*p0Vec) + np.log(1.0-pClass1) 5 if p1 > p0 : return 1 6 return 0 7 #把数量加进去啦,这样更准确,这里博文开头链接已经说明 8 def begOfWordsVecMN(vocabList,inputSet): 9 returnVec = [0]*len(vocabList) 10 for words in inputSet: 11 if words in vocabList: 12 returnVec[vocabList.index(words)] += 1 13 return returnVec
2.3难点解析
书中的代码都是经过改进或者省略了中间的推到,直接使用或者编写有点难懂,下一课还有类似问题。
以下是改进之后的贝叶斯函数,整体加Log()不影响对结果的预测,作用是防止有的数太小,这个书中和网上都已经说明,但是没有具体的公式和具体的解释,可能大神都懂吧。不懂的人看下面具体每个参数含义,和代码完全匹配。
还有一个防止概率为0,这个在Ng的课程中是加一个1,具体的看连接:http://www.cnblogs.com/wjy-lulu/p/7765939.html
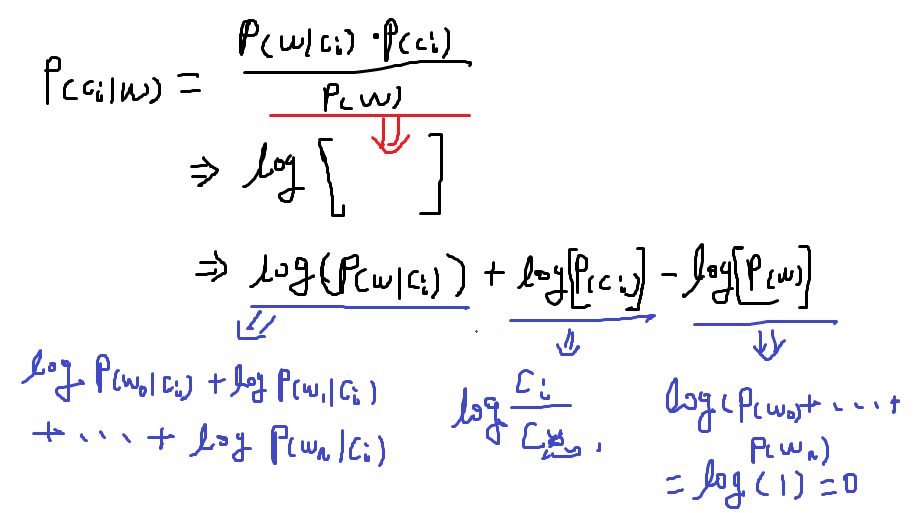
2.4总程序
1 import numpy as np 2 import operator 3 import matplotlib.pyplot as plt 4 5 #建立数据和标签 6 def loadDataSet(): 7 postingList = [ 8 ['my','dog','has','has','flea','problems','help','please'],\ 9 ['maybe','not','take','him','to','dog','park','stupid'],\ 10 ['my','dalmation','is','so','cute','I','love','him'],\ 11 ['stop','posting','stupid','worthless','garbage'],\ 12 ['mr','licks','ate','my','steak','how','to','stop','him'],\ 13 ['quit','buying','worthless','dog','food','food','stupid'] 14 ] 15 classVec = [0,1,0,1,0,1]#标签 16 return postingList, classVec 17 #得到样本里面不同特征 18 def creatVocaList(dataSet): 19 vocbSet = set([]) 20 for document in dataSet: 21 vocbSet = vocbSet | set(document) #求并集 22 return list(vocbSet) #转化为list输出 23 #对输入数据进行标记,这里看不懂的可以看博文首页的链接 24 #当然,如果你输入的数据要是样本没有的特征,那就GG 25 def setOfWord2Vec(vocabList,inputSet): 26 returnVec = [0]*len(vocabList) 27 for word in inputSet: 28 if word in vocabList: 29 returnVec[vocabList.index(word)] = 1 30 else: 31 print('the word : %s is not in my Vocabulary!',word) 32 return returnVec 33 34 def trainNB0(trainMtraix,trainCategory): 35 #trainMtraix:标记好的样本 36 #trainCategory:标签 37 numTrainDocs = len(trainMtraix)#样本数量 38 numWords = len(trainMtraix[0])#每个样本的特征数 39 pAbusive = sum(trainCategory)/float(numTrainDocs)#侮辱类百分比,由于是二项分布所以1-P(A)就可以 40 p0Num = np.ones(numWords);p1Num = np.ones(numWords) 41 p0Denom = 2.0; p1Denom = 2.0 #除法之后变为浮点数 42 for i in range(numTrainDocs): 43 if trainCategory[i] == 1: 44 p1Num += trainMtraix[i] #侮辱类样本特征 45 p1Denom += sum(trainMtraix[i])#侮辱类样本数量 46 else: 47 p0Num += trainMtraix[i] 48 p0Denom += sum(trainMtraix[i]) 49 p1Vect = np.log(p1Num/p1Denom) #侮辱类特征百分比 50 p0Vect = np.log(p0Num/p0Denom) # 51 #侮辱类特征百分比/非侮辱类特征百分比/侮辱类样本百分比 52 return p0Vect, p1Vect, pAbusive 53 #这个函数细节见博文说明 54 def classfyNB(vec2Classfy,p0Vec,p1Vec,pClass1): 55 p1 = sum(vec2Classfy*p1Vec) + np.log(pClass1) 56 p0 = sum(vec2Classfy*p0Vec) + np.log(1.0-pClass1) 57 if p1 > p0 : return 1 58 return 0 59 #把数量加进去啦,这样更准确,这里博文开头链接已经说明 60 def begOfWordsVecMN(vocabList,inputSet): 61 returnVec = [0]*len(vocabList) 62 for words in inputSet: 63 if words in vocabList: 64 returnVec[vocabList.index(words)] += 1 65 return returnVec 66 67 def textPharse(bigString): 68 import re 69 #标点符号分割 70 listOfTokens = re.split(r'\W*',bigString) 71 #标点符号去除 72 return [data.lower() for data in listOfTokens if len(data) > 2] 73 def spamTest(): 74 docList = [] 75 classList = [] 76 fullList = [] 77 for i in range(1,26): 78 wordList = textPharse(open('spam/'+str(i)+'.txt').read()) 79 docList.append(wordList) 80 fullList.extend(wordList) 81 #fullList = set(fullList)#提出重复特征 82 classList.append(1) 83 wordList = textPharse(open('ham/'+str(i)+'.txt').read()) 84 docList.append(wordList) 85 fullList.extend(wordList) 86 classList.append(0) 87 vocabList = creatVocaList(docList)#不同的特征 88 trainingSet = list(range(50)) 89 testSet = [] 90 #剔除10个测试集 91 for i in range(10): 92 randIndex = int(np.random.uniform(0,len(trainingSet)))#一个0-50的正太分布 93 #从trainingSet里面找,避免了再判断重复的麻烦 94 testSet.append(trainingSet[randIndex]) 95 del(trainingSet[randIndex]) 96 trainMat = [] 97 trainClassSet = [] 98 for docIndex in trainingSet: 99 trainMat.append(setOfWord2Vec(vocabList,docList[docIndex]))#训练数据转化,整合 100 trainClassSet.append(classList[docIndex])#训练标签跟进 101 p0V, p1V, pSpam = trainNB0(np.array(trainMat),np.array(trainClassSet)) 102 errorCount = 0 103 for docIndex in testSet: 104 wordVector = setOfWord2Vec(vocabList,docList[docIndex]) 105 if classfyNB(np.array(wordVector),p0V,p1V,pSpam) != classList[docIndex]: 106 errorCount += 1 107 print('the error rate is :',float(errorCount)/len(testSet)) 108 109 def calcMostFreq(vocabList,fullText): 110 import operator 111 freqDict = {} 112 #统计每个词出现的次数 113 for token in vocabList: 114 freqDict[token] = fullText.count(token) 115 sortedFreq = sorted(freqDict.items(),key=operator.itemgetter(1),reverse=True) 116 return sortedFreq[:5]#只要词出现最多的30个数据 117 def localWords(feed1,feed0): 118 import feedparser 119 docList = [] 120 classList = [] 121 fullText = [] 122 minLen = min(len(feed1['entries']),len(feed0['entries'])) 123 for i in range(minLen): 124 #第一个地域 125 wordList = textPharse(feed1['entries'][i]['summary']) 126 docList.append(wordList) 127 fullText.extend(wordList)#一维表示的总的数据 128 classList.append(1) 129 #第二个地域 130 wordList = textPharse(feed0['entries'][i]['summary']) 131 docList.append(wordList) 132 fullText.extend(wordList) 133 classList.append(0) 134 vocabList = creatVocaList(docList) #相互不同的特征 135 top30Words = calcMostFreq(vocabList,fullText) 136 #移除出现频率最多的30个特征 137 for pairW in top30Words: 138 if pairW[0] in vocabList : vocabList.remove(pairW[0]) 139 trainingSet = list(range(2*minLen))#其实总的特征为 2×minLen-30 140 testSet = [] 141 #分割数据,训练和测试分开 142 for i in range(10): 143 randIndex = int(np.random.uniform(0,len(trainingSet))) 144 testSet.append(trainingSet[randIndex]) 145 del(trainingSet[randIndex]) 146 #开始训练 147 trainMat = [] 148 trainClass = [] 149 for docIndex in trainingSet: 150 trainMat.append(begOfWordsVecMN(vocabList,docList[docIndex])) 151 trainClass.append(classList[docIndex]) 152 p0, p1, pSam = trainNB0(np.array(trainMat),np.array(trainClass)) 153 errorcount = 0.0 154 for docIndex in testSet: 155 wordsVect = begOfWordsVecMN(vocabList,docList[docIndex]) 156 if classfyNB(np.array(wordsVect),p0,p1,pSam) != classList[docIndex]: 157 errorcount += 1 158 print('error rate is : ',(1.0*errorcount)/float(len(testSet))) 159 return vocabList, p0, p1 160 def getTopWords(ny,sf): 161 import operator 162 vocabList, p0, p1 = localWords(ny,sf) 163 topNY = [] 164 topSF = [] 165 for i in range(len(p0)): 166 if p0[i] >-6.0 : topSF.append((vocabList[i],p0[i])) 167 if p1[i] >-6.0 : topNY.append((vocabList[i],p1[i])) 168 sortedSF = sorted(topSF,key=lambda num: num[1],reverse=True) 169 for i in sortedSF: 170 print('topSF : ',i,'\n') 171 sortedNY = sorted(topNY, key=lambda num: num[1], reverse=True) 172 for i in sortedNY: 173 print('topNY : ', i, '\n')
注释:这章节写的不好,因为现在计划早睡早起了,现在已经11点13分,还有几分钟就回去 了,稍微改一下就算了,不想占用明天的时间再去优化博客。。。
作者:影醉阏轩窗
-------------------------------------------
个性签名:衣带渐宽终不悔,为伊消得人憔悴!
如果觉得这篇文章对你有小小的帮助的话,记得关注再下的公众号,同时在右下角点个“推荐”哦,博主在此感谢!


