《机器学习实战》ID3算法实现
注释:之前从未接触过决策树,直接上手对着书看源码,有点难,确实有点难~~
本代码是基于ID3编写,之后的ID4.5和CART等还没学习到
一.决策树的原理
没有看网上原理,直接看源码懂得原理,下面是我一个抛砖引玉的例子:
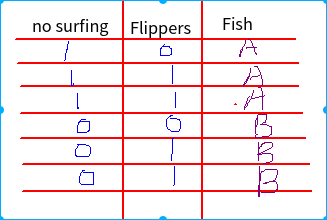
太丑了,在Linux下面操作实在不习惯,用的Kolourpqint画板也不好用,凑合看吧!
假设有两个特征:no surfing 、Flippers ,一个结果:Fish
现在假如给你一个测试:no surfing = 1, Flippers=0, 如何知道Fish的结果?太简单了Fish==A...
现在样本你不知道排序的情况下,那我们操作的步骤只能是两种:
1.no surfing = 1时判断Fish,直接得出结果Fish==A
2.Flippers=0时判断Fish,Fish可能是A也可能是B,再判断no surfing =1时,得出Fish == A
从上面我们可以看出,你选择的特征顺序对结果无影响,但是对计算的过程影响很大,我们能不能找到一种很好的途径去解决这个问题呢?
下面是两种方法:
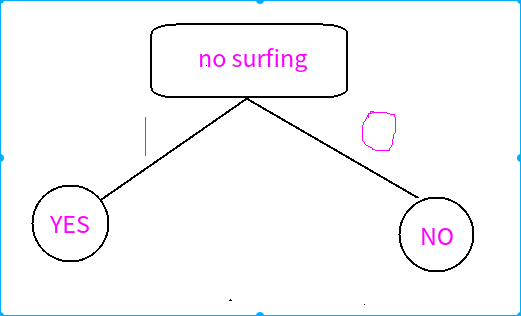
方法一
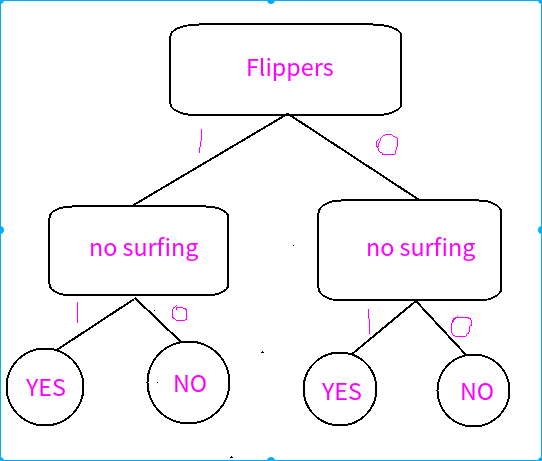
方法二
由以上的两种思路可以得出,不同的分类方法差距很大吧?
决策树就是用来解决如何选用最佳的方法的一种算法!!!
一点不了解的,先花几分钟看一下我“信息熵”,这是整个算法的核心。
二.决策树的实现
(1)计算信息熵
为什么计算“信息熵”?自己去看原理就懂了。
1 def claShannonEnt(setData): 2 lengthData = len(setData) 3 dicData = {} 4 for cnt in range(lengthData): 5 if setData[cnt,-1] not in dicData.keys(): 6 dicData[setData[cnt,-1]] = 0 7 dicData[setData[cnt,-1]] += 1 8 Hent = 0.0#输出信息ent 9 for key in dicData.keys(): 10 pData = float(dicData[key])/lengthData 11 Hent -= pData*math.log(pData,2) 12 return Hent
(2)划分数据集
划分之后计算部分的信息熵之和,信息熵越小越好,信息增益越大越好。
1 def splitData(setData,axis,value): 2 ''' setData: sample sata 3 axis : 轴的位置 4 value : 满足条件的值 5 ''' 6 lengthData = setData.shape[0] 7 resultMat = np.zeros([1,setData.shape[1]]) 8 for count in range(lengthData): 9 if int(setData[count,axis]) == int(value) : 10 resultMat = np.vstack((resultMat,setData[count,:])) 11 returnMat = resultMat[1:,:] 12 resultMat = np.hstack((returnMat[:,0:axis],returnMat[:,axis+1:])) 13 return resultMat
(3)选择最佳的划分方案
这里的原理就是划分之后的信息熵变小,信息增益变大,其中信息熵越小越好,也就是信息增益越大越好,循环比较每种划分之后的信息增益。
1 def chooseBestTeature(setData): 2 numFeature = setData.shape[1] - 1 #特征数量 3 baceEntropy = claShannonEnt(setData) #信息熵 4 bestGain = 0.0 #最好增益 5 bestFeature = 0 #最好特征 6 for i in range(numFeature): 7 #featList = [example[i] for example in setData] 8 featList = setData[:,i] 9 uniquaVals = set(featList) #不同的Value值,set之后就变成无序集合 10 newEntropy = 0.0 11 for value in uniquaVals: 12 subDataSet = splitData(setData,i,value)#分割特征 13 prob = len(subDataSet)/float(len(setData)) 14 newEntropy += prob * claShannonEnt(subDataSet)#平均信息熵 15 infoGain = baceEntropy - newEntropy 16 if (infoGain > bestGain):#求得最大增益 17 bestGain = infoGain 18 bestFeature = i 19 return bestFeature
(4)计算分类之后的标签
这里有点难理解,准备在下面程序讲解的,写到这里就直接讲解了。
这是为了分类不了的情况做的准备,比如:[1,1,'yes'],[1,1,'no'],[1,0,'no'],[1,0,'yes'],[0,0,'no'],[0,0,'yes'],[0,1,'no'],[0,1,'yes'],大家可以按照上面的方法动手试试怎么分割?
我们可以想象一下,就像以前中学学的解方程,Y1+Y2=10 && 2Y1 +2Y2 =10 ,你怎么求解Y1和Y2 ?两个有冲突的方程和上面的样本之间的冲突是一样的。
这明显是一个出错的样本导致的,那怎么解决呢?
再给出一组样本:[1,1,'yes'],[1,1,'yes'],[1,1,'no'],[1,1,'yes'],我们利用错误的样本为少数,多数的样本为正确的,所以[1,1] = 'YES'
1 #计算分类之后的标签 2 def majorityCnt(classList): 3 classCount = {} 4 for vote in classList: 5 if vote not in classCount.keys(): 6 classCount[vote] = 0 7 classCount[vote] += 1 8 sortedClassCount = sorted(classCount.items(),key=operator.itemgetter(1),reverse=True) 9 return sortedClassCount
(5)建立决策树
这里采用递归的方法进行划分
调出循环的条件是:
1.最后的标签相同--->>>也就是最后就省一个答案了,没必要划分直接得出结果了。
2.就是第四点说的无解题,那就多的保留,少的丢弃。
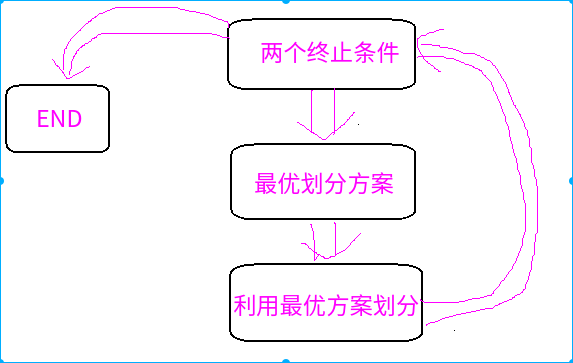
1 def creatTree(dataSet,labels): 2 classList = dataSet[:,-1] 3 #标签全部相等的时候退出 4 if list(classList).count(classList[0]) == len(list(classList)): 5 return classList[0] 6 #最后的标签不相同,这个时候没办法分割,所以只能选择一个占比例大的标签了,博客会给具体例子 7 if len(dataSet[0,:]) == 1: 8 return majorityCnt(classList) 9 bestFeat = chooseBestTeature(dataSet) 10 bestFeatLabel = labels[bestFeat] 11 myTree = {bestFeatLabel:{}} 12 del(labels[bestFeat]) 13 featValue = dataSet[:,bestFeat] 14 uniqueVals = set(featValue) 15 for value in uniqueVals: 16 subLabels = labels[:] 17 myTree[bestFeatLabel][value] = creatTree(splitData(dataSet,bestFeat,value),subLabels) 18 return myTree
(6)使用决策树
就像建立决策树一样,采用递归一层一层的去找到数据属于哪个类,看懂上面的建立之后现在这里不很简单
1 def classify(inputTrees,featLabels,testVec): 2 firstStr = list(inputTrees.keys())[0]#字典首元素 3 secondDict = inputTrees[firstStr]#下一个字典 4 featIndex = featLabels.index(firstStr)#标签中的位置 5 for key in secondDict.keys(): 6 if testVec[featIndex] == int(key):#分支 7 if type(secondDict[key]).__name__=='dict':#如果还是字典说明还得划分 8 classLabels = classify(secondDict[key],featLabels,testVec)#迭代划分 9 else: classLabels = secondDict[key]#不是字典说明已经分类 10 return classLabels
(7)存储决策树函数
(8)总程序设计
注意:我用的是Numpy数据,而不是List数据,这是有区别的,没有完全按照书上编写!
1 import numpy as np 2 import matplotlib.pyplot as ply 3 import math 4 import operator 5 6 def claShannonEnt(setData): 7 lengthData = len(setData) 8 dicData = {} 9 for cnt in range(lengthData): 10 if setData[cnt,-1] not in dicData.keys(): 11 dicData[setData[cnt,-1]] = 0 12 dicData[setData[cnt,-1]] += 1 13 Hent = 0.0#输出信息ent 14 for key in dicData.keys(): 15 pData = float(dicData[key])/lengthData 16 Hent -= pData*math.log(pData,2) 17 return Hent 18 19 def splitData(setData,axis,value): 20 ''' setData: sample sata 21 axis : 轴的位置 22 value : 满足条件的值 23 ''' 24 lengthData = setData.shape[0] 25 resultMat = np.zeros([1,setData.shape[1]]) 26 for count in range(lengthData): 27 if int(setData[count,axis]) == int(value) : 28 resultMat = np.vstack((resultMat,setData[count,:])) 29 returnMat = resultMat[1:,:] 30 resultMat = np.hstack((returnMat[:,0:axis],returnMat[:,axis+1:])) 31 return resultMat 32 33 def chooseBestTeature(setData): 34 numFeature = setData.shape[1] - 1 #特征数量 35 baceEntropy = claShannonEnt(setData) #信息熵 36 bestGain = 0.0 #最好增益 37 bestFeature = 0 #最好特征 38 for i in range(numFeature): 39 #featList = [example[i] for example in setData] 40 featList = setData[:,i] 41 uniquaVals = set(featList) #不同的Value值,set之后就变成无序集合 42 newEntropy = 0.0 43 for value in uniquaVals: 44 subDataSet = splitData(setData,i,value)#分割特征 45 prob = len(subDataSet)/float(len(setData)) 46 newEntropy += prob * claShannonEnt(subDataSet)#平均信息熵 47 infoGain = baceEntropy - newEntropy 48 if (infoGain > bestGain):#求得最大增益 49 bestGain = infoGain 50 bestFeature = i 51 return bestFeature 52 53 #计算分类之后的标签 54 def majorityCnt(classList): 55 classCount = {} 56 for vote in classList: 57 if vote not in classCount.keys(): 58 classCount[vote] = 0 59 classCount[vote] += 1 60 sortedClassCount = sorted(classCount.items(),key=operator.itemgetter(1),reverse=True) 61 return sortedClassCount 62 63 def creatTree(dataSet,labels): 64 classList = dataSet[:,-1] 65 #标签全部相等的时候退出 66 if list(classList).count(classList[0]) == len(list(classList)): 67 return classList[0] 68 #最后的标签不相同,这个时候没办法分割,所以只能选择一个占比例大的标签了,博客会给具体例子 69 if len(dataSet[0,:]) == 1: 70 return majorityCnt(classList) 71 bestFeat = chooseBestTeature(dataSet) 72 bestFeatLabel = labels[bestFeat] 73 myTree = {bestFeatLabel:{}} 74 del(labels[bestFeat]) 75 featValue = dataSet[:,bestFeat] 76 uniqueVals = set(featValue) 77 for value in uniqueVals: 78 subLabels = labels[:] 79 myTree[bestFeatLabel][value] = creatTree(splitData(dataSet,bestFeat,value),subLabels) 80 return myTree
1 import numpy as np 2 import trees 3 4 if __name__ == '__main__': 5 testData = np.array([[1,1,'yes'],[1,1,'no'],[1,0,'no'],[1,0,'yes'],[0,0,'no'],[0,0,'yes'],[0,1,'no'],[0,1,'yes']]) 6 myTree = trees.creatTree(testData,['no surfacing','flippers'])#['yes','yes','no','no','no'] 7 print(myTree)
-------------------------------------------
个性签名:衣带渐宽终不悔,为伊消得人憔悴!
如果觉得这篇文章对你有小小的帮助的话,记得关注再下的公众号,同时在右下角点个“推荐”哦,博主在此感谢!

