《机器学习实战》KNN算法实现
本系列都是参考《机器学习实战》这本书,只对学习过程一个记录,不做详细的描述!
注释:看了一段时间Ng的机器学习视频,感觉不能光看不练,现在一边练习再一边去学习理论!
KNN很早就之前就看过也记录过,在此不做更多说明,这是k-means之前的记录,感觉差不多:http://www.cnblogs.com/wjy-lulu/p/7002688.html
1.简单的分类
代码:
1 import numpy as np 2 import operator 3 import KNN 4 5 def classify0(inX,dataSet,labels,k): 6 dataSetSize = dataSet.shape[0] #样本个数 7 diffMat = np.tile(inX,(dataSetSize,1)) - dataSet#样本每个值和测试数据做差 8 sqDiffMat = diffMat**2#平方 9 sqDistances = sqDiffMat.sum(axis=1)#第二维度求和,也就是列 10 distances = sqDistances**0.5#平方根 11 sortedDistIndicies = distances.argsort()#下标排序 12 classCount = {} 13 14 for i in range(k): 15 voteIlabel = labels[sortedDistIndicies[i]]#得到距离最近的几个数 16 classCount[voteIlabel] = classCount.get(voteIlabel,0)+1#标签计数 17 sortedClassCount = sorted(classCount.items(),key=operator.itemgetter(1),reverse=True)#按照数值排序operator.itemgetter(1)代表第二个域 18 #上面排序之后就不是字典了,而是一个列表里面包含的元组[('c',2),('a',3)] 19 return sortedClassCount[0][0] 20 21 if __name__ == '__main__': 22 group,labels = KNN.createDataSet() 23 result = classify0([0,0.5],group,labels,1) 24 print (result)
KNN.Py文件
1 import numpy as np 2 import operator 3 4 5 def createDataSet(): 6 group = np.array([[1.0, 1.1], [1.0, 1.0], [0, 0], [0, 0.1]]) 7 labels = ['A', 'B', 'C', 'D'] 8 return group, labels
2.约会网站的预测
下面给出每个部分的代码和注释:
A.文本文件转换为可用数据
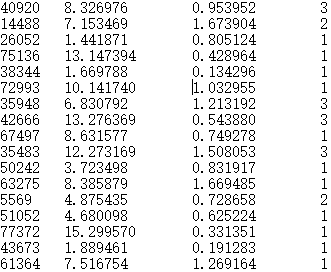
上面的文本中有空格和换行,而且样本和标签都在一起,必须的分开处理成矩阵才可以进行下一步操作。
1 def file2matrix(filename):#把文件转化为可操作数据 2 fr = open(filename)#打开文件 3 arrayOLines = fr.readlines()#读取每行文件 4 numberOfLines = len(arrayOLines)#行数量 5 returnMat = np.zeros([numberOfLines,3])#存储数据 6 classLabelVector = [] 7 index = 0 8 for line in arrayOLines: 9 line = line.strip()#去除换行符 10 listFromLine = line.split('\t')#按照空格去分割 11 returnMat[index,:] = listFromLine[0:3]#样本 12 classLabelVector.append(int(listFromLine[-1]))#labels 13 index += 1 14 return returnMat,classLabelVector#返回数据和标签
B.归一化
数据大小差异太明显,比如有三个特征:a=[1,2,3],b=[1000,2000,3000],c=[0.1,0.2,0.3],我们发现c和a根本没啥作用,因为b的值太大了,或者说b的权重太大了,Ng中可以用惩罚系数去操作,或者正则化都可以处理这类数据,当然这是题外话。
1 def autoNorm(dataSet):#归一化函数 2 #每列的最值 3 minValue = dataSet.min(0) 4 maxValue = dataSet.max(0) 5 range = maxValue - minValue 6 #创建最小值矩阵 7 midData = np.tile(minValue,[dataSet.shape[0],1]) 8 dataSet = dataSet - midData 9 #创建range矩阵 10 range = np.tile(range,[dataSet.shape[0],1]) 11 dataSet = dataSet / range #直接相除不是矩阵相除 12 return dataSet,minValue,maxValue
C.预测
KNN的方法就是距离,计算K个距离,然后排序看哪个占得比重大就选哪个类。
1 def classify0(inX, dataSet, labels, k):#核心分类程序 2 dataSetSize = dataSet.shape[0] # 样本个数 3 diffMat = np.tile(inX, (dataSetSize, 1)) - dataSet # 样本每个值和测试数据做差 4 sqDiffMat = diffMat ** 2 # 平方 5 sqDistances = sqDiffMat.sum(axis=1) # 第二维度求和,也就是列 6 distances = sqDistances ** 0.5 # 平方根 7 sortedDistIndicies = distances.argsort() # 下标排序 8 classCount = {} 9 10 for i in range(k): 11 voteIlabel = labels[sortedDistIndicies[i]] # 得到距离最近的几个数 12 classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1 # 标签计数 13 sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), 14 reverse=True) # 按照数值排序operator.itemgetter(1)代表第二个域 15 # 上面排序之后就不是字典了,而是一个列表里面包含的元组[('c',2),('a',3)] 16 return sortedClassCount[0][0]
D.性能测试
比如1000个数据,900个用做样本,100用做测试,看看精确度是多少?
1 def datingClassTest(): 2 hoRatio = 0.2 3 datingDataMat , datingLabels = file2matrix('datingTestSet2.txt') 4 normMat = autoNorm(datingDataMat) 5 n = normMat.shape[0] 6 numTestVecs = int(n*hoRatio)#测试数据和样本数据的分割点 7 erroCount = 0.0 8 #numTestVecs:n样本,[i,numTestVecs]测试 9 for i in range(numTestVecs): 10 classfiResult = classify0(normMat[i,:],normMat[numTestVecs:n,:], 11 datingLabels[numTestVecs:n],3) 12 if (classfiResult!=datingLabels[i]): erroCount+=1.0 13 print ("the totle error os: %f" %(erroCount/float(numTestVecs)))
E.实战分类
注意输入的数据也得归一化
1 def classfiPerson(): 2 resultList = ['not at all','in small doses','in large doses'] 3 personTats = float(input('please input video game \n')) 4 ffMiles = float(input('please input flier miles \n')) 5 iceCream = float(input('please input ice cream \n')) 6 datingData,datingLabels = file2matrix('datingTestSet2.txt') 7 normData,minData,maxData = autoNorm(datingData) 8 inputData = np.array([personTats,ffMiles,iceCream])#转化为矩阵 9 inputData = (inputData - minData)/(maxData - minData)#输入归一化 10 result = classify0(inputData,normData,datingLabels,3) 11 print('等级是:',result)
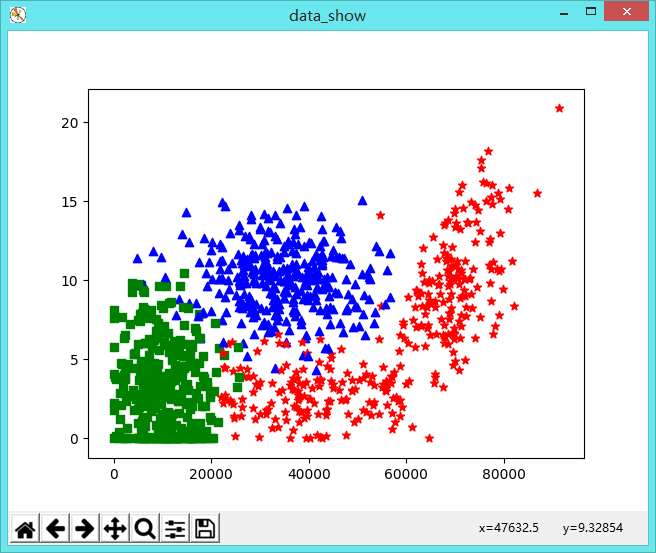
F.可视化显示
1 datingDatas, datingLabels = KNN.file2matrix('datingTestSet2.txt') 2 #可视化样本数据显示 3 fig = plt.figure('data_show') 4 ax = fig.add_subplot(111) 5 for i in range(datingDatas.shape[0]): 6 if datingLabels[i]==1: 7 ax.scatter(datingDatas[i, 0], datingDatas[i, 1], marker="*",c='r') # 用后两个特征绘图 8 9 if datingLabels[i]==2: 10 ax.scatter(datingDatas[i, 0], datingDatas[i, 1], marker="s", c='g') # 用后两个特征绘图 11 12 if datingLabels[i]==3: 13 ax.scatter(datingDatas[i, 0], datingDatas[i, 1], marker="^", c='b') # 用后两个特征绘图 14 plt.show()
G.完整代码
1 import numpy as np 2 import operator 3 #from numpy import * 4 5 def createDataSet():#创建简单测试的几个数 6 group = np.array([[1.0, 1.1], [1.0, 1.0], [0, 0], [0, 0.1]]) 7 labels = ['A', 'B', 'C', 'D'] 8 return group, labels 9 10 def autoNorm(dataSet):#归一化函数 11 #每列的最值 12 minValue = dataSet.min(0) 13 maxValue = dataSet.max(0) 14 range = maxValue - minValue 15 #创建最小值矩阵 16 midData = np.tile(minValue,[dataSet.shape[0],1]) 17 dataSet = dataSet - midData 18 #创建range矩阵 19 range = np.tile(range,[dataSet.shape[0],1]) 20 dataSet = dataSet / range #直接相除不是矩阵相除 21 return dataSet,minValue,maxValue 22 23 def file2matrix(filename):#把文件转化为可操作数据 24 fr = open(filename)#打开文件 25 arrayOLines = fr.readlines()#读取每行文件 26 numberOfLines = len(arrayOLines)#行数量 27 returnMat = np.zeros([numberOfLines,3])#存储数据 28 classLabelVector = [] 29 index = 0 30 for line in arrayOLines: 31 line = line.strip()#去除换行符 32 listFromLine = line.split('\t')#按照空格去分割 33 returnMat[index,:] = listFromLine[0:3]#样本 34 classLabelVector.append(int(listFromLine[-1]))#labels 35 index += 1 36 return returnMat,classLabelVector#返回数据和标签 37 38 def classify0(inX, dataSet, labels, k):#核心分类程序 39 dataSetSize = dataSet.shape[0] # 样本个数 40 diffMat = np.tile(inX, (dataSetSize, 1)) - dataSet # 样本每个值和测试数据做差 41 sqDiffMat = diffMat ** 2 # 平方 42 sqDistances = sqDiffMat.sum(axis=1) # 第二维度求和,也就是列 43 distances = sqDistances ** 0.5 # 平方根 44 sortedDistIndicies = distances.argsort() # 下标排序 45 classCount = {} 46 47 for i in range(k): 48 voteIlabel = labels[sortedDistIndicies[i]] # 得到距离最近的几个数 49 classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1 # 标签计数 50 sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), 51 reverse=True) # 按照数值排序operator.itemgetter(1)代表第二个域 52 # 上面排序之后就不是字典了,而是一个列表里面包含的元组[('c',2),('a',3)] 53 return sortedClassCount[0][0] 54 55 def datingClassTest(): 56 hoRatio = 0.2 57 datingDataMat , datingLabels = file2matrix('datingTestSet2.txt') 58 normMat = autoNorm(datingDataMat) 59 n = normMat.shape[0] 60 numTestVecs = int(n*hoRatio)#测试数据和样本数据的分割点 61 erroCount = 0.0 62 #numTestVecs:n样本,[i,numTestVecs]测试 63 for i in range(numTestVecs): 64 classfiResult = classify0(normMat[i,:],normMat[numTestVecs:n,:], 65 datingLabels[numTestVecs:n],3) 66 if (classfiResult!=datingLabels[i]): erroCount+=1.0 67 print ("the totle error os: %f" %(erroCount/float(numTestVecs))) 68 69 def classfiPerson(): 70 resultList = ['not at all','in small doses','in large doses'] 71 personTats = float(input('please input video game \n')) 72 ffMiles = float(input('please input flier miles \n')) 73 iceCream = float(input('please input ice cream \n')) 74 datingData,datingLabels = file2matrix('datingTestSet2.txt') 75 normData,minData,maxData = autoNorm(datingData) 76 inputData = np.array([personTats,ffMiles,iceCream])#转化为矩阵 77 inputData = (inputData - minData)/(maxData - minData)#输入归一化 78 result = classify0(inputData,normData,datingLabels,3) 79 print('等级是:',result)
3.手写数字识别
A.转换文件
1 def img2vector(filename): 2 returnVector = np.zeros([32,32]) 3 fr = open(filename) 4 lineData = fr.readlines() 5 count = 0 6 for line in lineData: 7 line = line.strip()#去除换行符 8 for j in range(len(line)): 9 returnVector[count,j] = line[j] 10 count += 1 11 returnVector = returnVector.reshape(1,1024).astype(int)#转化为1X1024 12 return returnVector
B.识别分类
1 def handWriteringClassTest(): 2 #--------------------------读取数据--------------------------------- 3 hwLabels = [] 4 trainingFileList = os.listdir('trainingDigits')#获取文件目录 5 m = len(trainingFileList)#获取目录个数 6 trainingMat = np.zeros([m,1024])#全部样本 7 for i in range(m): 8 fileNameStr = trainingFileList[i] 9 fileStr = fileNameStr.split('.')[0]#得到不带格式的文件名 10 classNumStr = int(fileStr.split('_')[0])#得到最前面的数字类别0-9 11 hwLabels.append(classNumStr)#存储 12 dirList = 'trainingDigits/' + fileNameStr#绝对目录信息 13 vectorUnderTest = img2vector(dirList)#读取第i个数据信息 14 trainingMat[i,:] = vectorUnderTest #存储 15 #--------------------------测试数据-------------------------------- 16 testFileList = os.listdir('testDigits') 17 errorCount = 0.0 18 m = len(testFileList) 19 for i in range(m): 20 fileNameStr = testFileList[i] 21 fileInt = fileNameStr.split('.')[0].split('_')[0] 22 dirList = 'testDigits/' + fileNameStr # 绝对目录信息 23 vectorUnderTest = img2vector(dirList) # 读取第i个数据信息 24 if int(fileInt) != int(classify0(vectorUnderTest,trainingMat,hwLabels,3)): 25 errorCount += 1 26 print('error count is : ',errorCount) 27 print('error Rate is : ', (errorCount/m))
C.完整代码
1 import numpy as np 2 import operator 3 import os 4 #from numpy import * 5 6 def createDataSet():#创建简单测试的几个数 7 group = np.array([[1.0, 1.1], [1.0, 1.0], [0, 0], [0, 0.1]]) 8 labels = ['A', 'B', 'C', 'D'] 9 return group, labels 10 11 def autoNorm(dataSet):#归一化函数 12 #每列的最值 13 minValue = dataSet.min(0) 14 maxValue = dataSet.max(0) 15 range = maxValue - minValue 16 #创建最小值矩阵 17 midData = np.tile(minValue,[dataSet.shape[0],1]) 18 dataSet = dataSet - midData 19 #创建range矩阵 20 range = np.tile(range,[dataSet.shape[0],1]) 21 dataSet = dataSet / range #直接相除不是矩阵相除 22 return dataSet,minValue,maxValue 23 24 def file2matrix(filename):#把文件转化为可操作数据 25 fr = open(filename)#打开文件 26 arrayOLines = fr.readlines()#读取每行文件 27 numberOfLines = len(arrayOLines)#行数量 28 returnMat = np.zeros([numberOfLines,3])#存储数据 29 classLabelVector = [] 30 index = 0 31 for line in arrayOLines: 32 line = line.strip()#去除换行符 33 listFromLine = line.split('\t')#按照空格去分割 34 returnMat[index,:] = listFromLine[0:3]#样本 35 classLabelVector.append(int(listFromLine[-1]))#labels 36 index += 1 37 return returnMat,classLabelVector#返回数据和标签 38 39 def classify0(inX, dataSet, labels, k):#核心分类程序 40 dataSetSize = dataSet.shape[0] # 样本个数 41 diffMat = np.tile(inX, (dataSetSize, 1)) - dataSet # 样本每个值和测试数据做差 42 sqDiffMat = diffMat ** 2 # 平方 43 sqDistances = sqDiffMat.sum(axis=1) # 第二维度求和,也就是列 44 distances = sqDistances ** 0.5 # 平方根 45 sortedDistIndicies = distances.argsort() # 下标排序 46 classCount = {} 47 48 for i in range(k): 49 voteIlabel = labels[sortedDistIndicies[i]] # 得到距离最近的几个数 50 classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1 # 标签计数 51 sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), 52 reverse=True) # 按照数值排序operator.itemgetter(1)代表第二个域 53 # 上面排序之后就不是字典了,而是一个列表里面包含的元组[('c',2),('a',3)] 54 return sortedClassCount[0][0] 55 56 def datingClassTest(): 57 hoRatio = 0.2 58 datingDataMat , datingLabels = file2matrix('datingTestSet2.txt') 59 normMat = autoNorm(datingDataMat) 60 n = normMat.shape[0] 61 numTestVecs = int(n*hoRatio)#测试数据和样本数据的分割点 62 erroCount = 0.0 63 #numTestVecs:n样本,[i,numTestVecs]测试 64 for i in range(numTestVecs): 65 classfiResult = classify0(normMat[i,:],normMat[numTestVecs:n,:], 66 datingLabels[numTestVecs:n],3) 67 if (classfiResult!=datingLabels[i]): erroCount+=1.0 68 print ("the totle error os: %f" %(erroCount/float(numTestVecs))) 69 70 def classfiPerson(): 71 resultList = ['not at all','in small doses','in large doses'] 72 personTats = float(input('please input video game \n')) 73 ffMiles = float(input('please input flier miles \n')) 74 iceCream = float(input('please input ice cream \n')) 75 datingData,datingLabels = file2matrix('datingTestSet2.txt') 76 normData,minData,maxData = autoNorm(datingData) 77 inputData = np.array([personTats,ffMiles,iceCream])#转化为矩阵 78 inputData = (inputData - minData)/(maxData - minData)#输入归一化 79 result = classify0(inputData,normData,datingLabels,3) 80 print('等级是:',result) 81 82 def img2vector(filename): 83 returnVector = np.zeros([32,32]) 84 fr = open(filename) 85 lineData = fr.readlines() 86 count = 0 87 for line in lineData: 88 line = line.strip()#去除换行符 89 for j in range(len(line)): 90 returnVector[count,j] = line[j] 91 count += 1 92 returnVector = returnVector.reshape(1,1024).astype(int)#转化为1X1024 93 return returnVector 94 95 def img2vector2(filename): 96 returnVect = np.zeros([1,1024]) 97 fr = open(filename) 98 for i in range(32): 99 lineStr = fr.readline() 100 for j in range(32): 101 returnVect[0,32*i+j] = int(lineStr[j]) 102 return returnVect 103 104 def handWriteringClassTest(): 105 #--------------------------读取数据--------------------------------- 106 hwLabels = [] 107 trainingFileList = os.listdir('trainingDigits')#获取文件目录 108 m = len(trainingFileList)#获取目录个数 109 trainingMat = np.zeros([m,1024])#全部样本 110 for i in range(m): 111 fileNameStr = trainingFileList[i] 112 fileStr = fileNameStr.split('.')[0]#得到不带格式的文件名 113 classNumStr = int(fileStr.split('_')[0])#得到最前面的数字类别0-9 114 hwLabels.append(classNumStr)#存储 115 dirList = 'trainingDigits/' + fileNameStr#绝对目录信息 116 vectorUnderTest = img2vector(dirList)#读取第i个数据信息 117 trainingMat[i,:] = vectorUnderTest #存储 118 #--------------------------测试数据-------------------------------- 119 testFileList = os.listdir('testDigits') 120 errorCount = 0.0 121 m = len(testFileList) 122 for i in range(m): 123 fileNameStr = testFileList[i] 124 fileInt = fileNameStr.split('.')[0].split('_')[0] 125 dirList = 'testDigits/' + fileNameStr # 绝对目录信息 126 vectorUnderTest = img2vector(dirList) # 读取第i个数据信息 127 if int(fileInt) != int(classify0(vectorUnderTest,trainingMat,hwLabels,3)): 128 errorCount += 1 129 print('error count is : ',errorCount) 130 print('error Rate is : ', (errorCount/m))

作者:影醉阏轩窗
-------------------------------------------
个性签名:衣带渐宽终不悔,为伊消得人憔悴!
如果觉得这篇文章对你有小小的帮助的话,记得关注再下的公众号,同时在右下角点个“推荐”哦,博主在此感谢!


