Rethinking Training from Scratch for Object Detection
Rethinking Training from Scratch for Object Detection
一. 概述
正常训练目标检测的流程分为以下几种:
- 在imagenet上进行预训练,然后在特定数据集进行tune
- 直接在数据集上进行从头训练
两种方式各有千秋,前者可以很快收敛(在特定数据集收敛快),但是训练复杂(预训练实际长)。后者直接训练较为容易(尤其在修改模型结构时),但是训练周期较长(比tune阶段长很多)。这篇文章就是解决从头训练的时长问题,从而达到集成两者的优点(夸大其词的说法)。
二. 流程
论文比较简单,这里进行总结如下:
- 精度和 \(batchsize\) 有关,且在一定范围内,越大越好。
- 精度和图像的分辨率(大小)有关,且图像越大分辨率越好,图像过小对精度影响较小。
- 精度和缩放有关,按照分类的缩放进行,不仅提高速度,且精度也比正常缩放效果好。
- 精度和BN层有关,正相关。
按照上述的总结,论文进行改进的训练如下:
-
使用BN层(当前网络基础结构)
-
Pretrained先用小尺度图像进行训练,\(batchsize\)设置较大
-
数据处理部分-->先将图像缩放到 \((H,W)\times(1.0,1.2)\) ,随机RandomCrop-->\((H,W)\),最后进行Padding到 \((h,W)\)
-
Finetune阶段按照正常训练即可
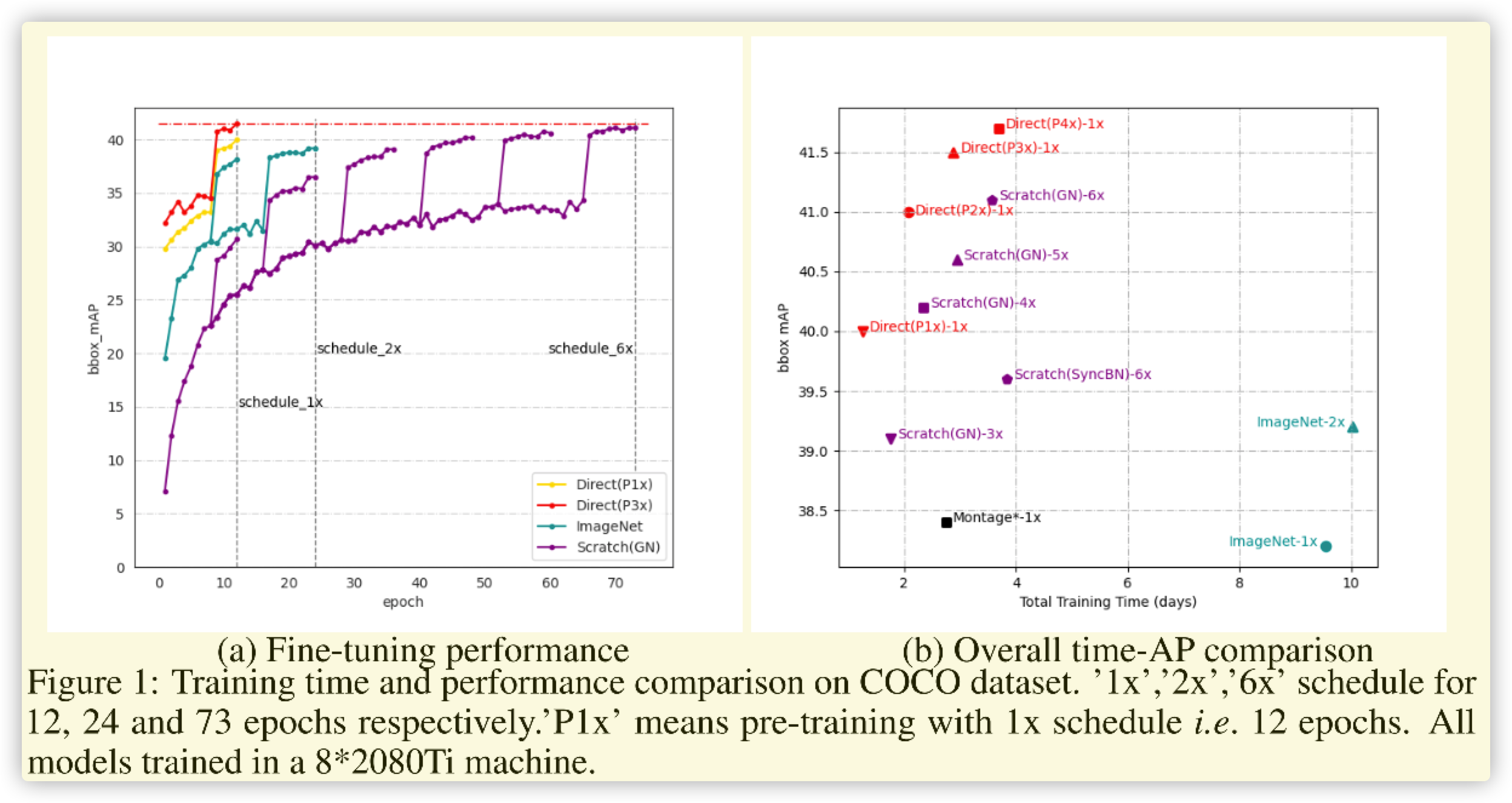
三. 总结
- 有一定使用意义,对于大数据集,直接使用此方法较好。
- 对于小的数据集,还是重新训练imagenet比较好
- VOC的数据集太小,而且分布较为散乱,这里对比意义不大。
- 笔者会在实际数据集上尝试之后进行补充(TODO)
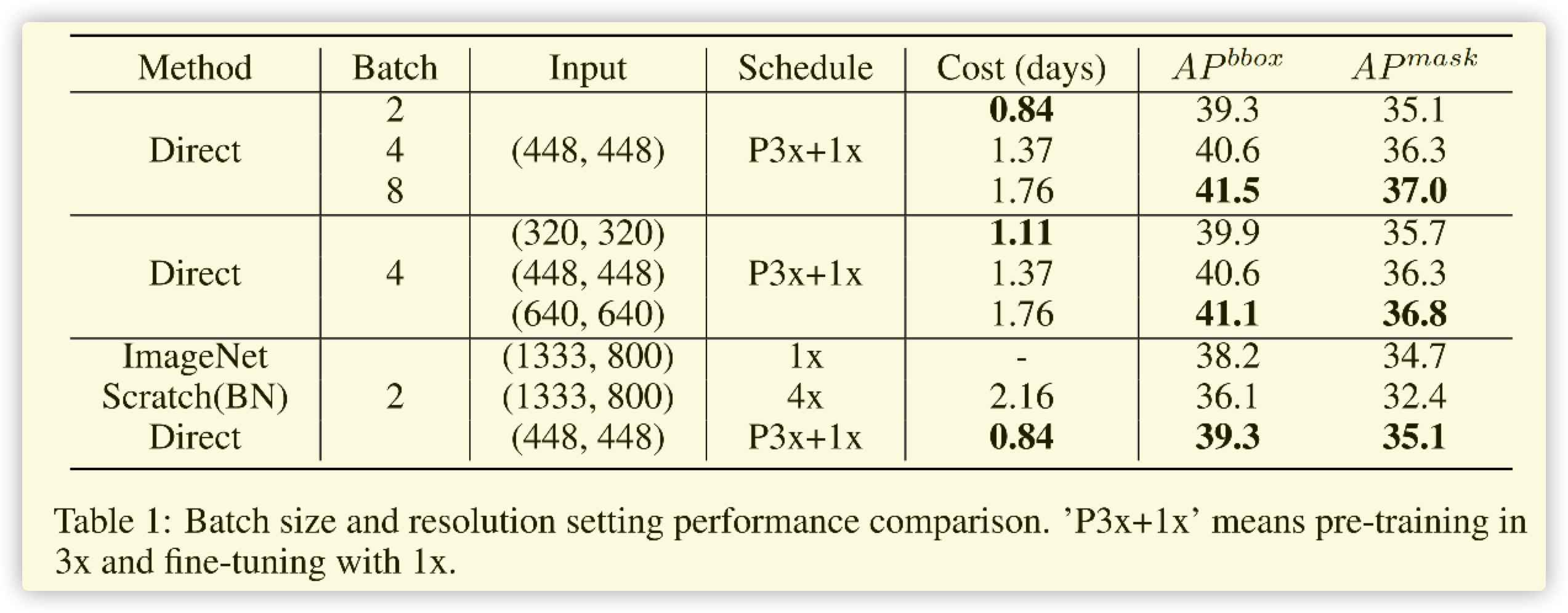
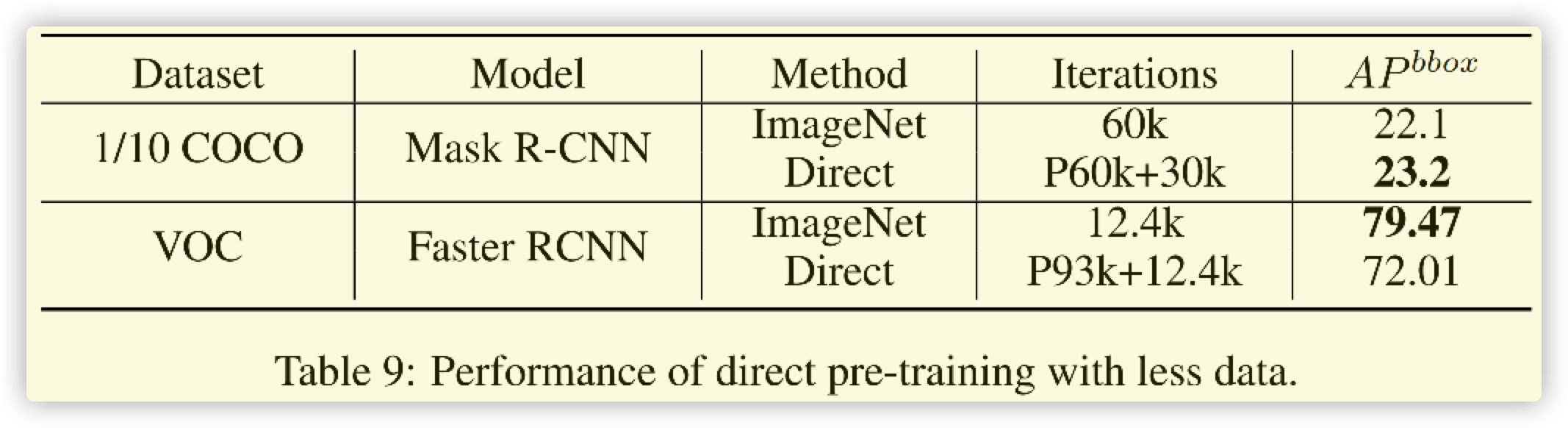
2021.6.22补充:
使用YOLOV5-Small在mmdetection环境下,第一阶段完全按照作者的方式进行,训练100Epoch,初始学习率0.01,最终降低到0.01/20。第二阶段修改为1)20%概率Mosaic数据增强。2)输入大小修改为800。3)增加100%颜色扰动。学习率和第一个阶段相同,训练100Epoch。\(mAP=0.28\)
直接进行训练,不使用预训练模型,学习率相同,训练300epoch,\(mAP=29.6\)
总结: 由于参数和论文有所差异,所以这个实验不完全准确。但是可以确定的是==>此论文方案可以加快训练速度,但是精度需要调参才能提高,而且和数据集关系较大!笔者建议缺卡的学生可以使用,其它情况没必要在这浪费时间。
-------------------------------------------
个性签名:衣带渐宽终不悔,为伊消得人憔悴!
如果觉得这篇文章对你有小小的帮助的话,记得关注再下的公众号,同时在右下角点个“推荐”哦,博主在此感谢!


