HRank模型剪枝
HRank: Filter Pruning using High-Rank Feature Map
概述
这篇文章非常简单,直接使用每层的 \(feature\) 结果去判断 \(filter-kernel\) 的重要程度:
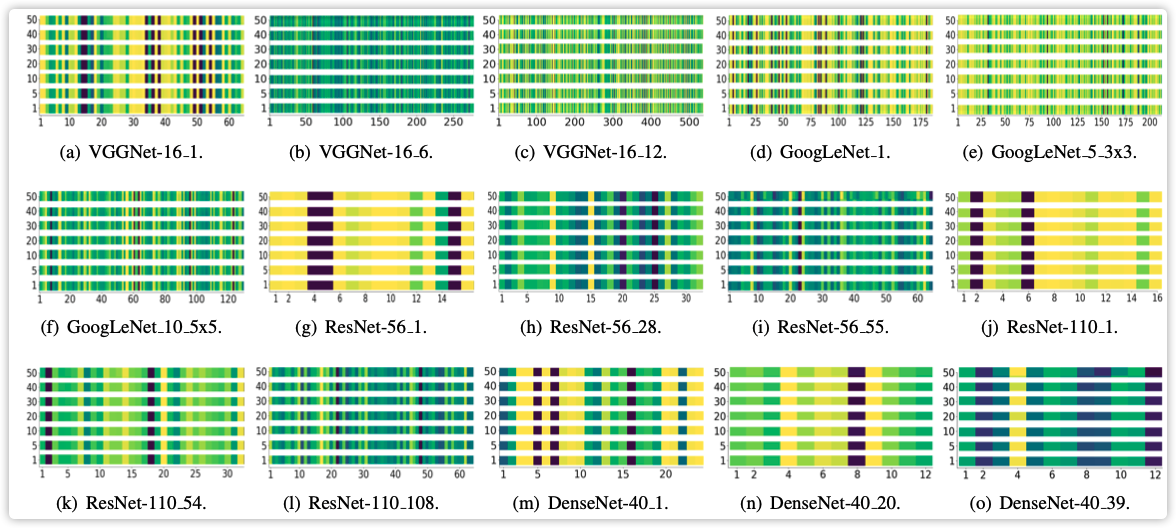
上图展示了网络每一层的特征重要程度分布情况,如何确定重要性?
\[\begin{aligned}\mathbf{o}_{j}^{i}(I,:,:) &=\sum_{i=1}^{r} \sigma_{i} \mathbf{u}_{i} \mathbf{v}_{i}^{T} \\&=\sum_{i=1}^{r^{\prime}} \sigma_{i} \mathbf{u}_{i} \mathbf{v}_{i}^{T}+\sum_{i=r^{\prime}+1}^{r} \sigma_{i} \mathbf{u}_{i} \mathbf{v}_{i}^{T}\end{aligned}
\]
看到上述公式就明白了,就是很简单的对 \(feature-map\) 进行特征分解,特征值排序获得 \(Rank\) 信息。
代码中直接使用矩阵的秩代替特征值(未懂特征值约等于矩阵的秩操作)
#get feature map of certain layer via hook
def get_feature_hook(self, input, output):
global feature_result
global entropy
global total
a = output.shape[0]
b = output.shape[1]
c = torch.tensor([torch.matrix_rank(output[i,j,:,:]).item() for i in range(a) for j in range(b)])
c = c.view(a, -1).float()
c = c.sum(0)
feature_result = feature_result * total + c
total = total + a
feature_result = feature_result / total
代码中对于每层的剪枝率都有设置,比如下图中的GoogleLeNet,为什么每层的剪枝率都不同,这比率如何设置?

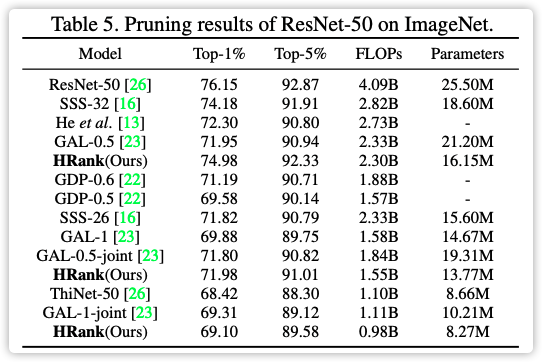
论文跑的结果效果可以,但是如果论文【18】也对不同的层设置不同的剪枝率,效果会不会不同?此论文如果设置全局剪枝率,而不是单独设置,会不会降低精度?
总结
- 模型剪枝真的太虚了,论文作者已经证明结构剪枝在不同层设置相同比例没有任何意思,但是还有很多人用\(Learning Efficient Convolutional Networks through Network Slimming\) 这篇早期论文。如果仅仅为了设置一个比例,和手动设置比例没有任何区别。
- 此论文不同的层设置不同比例,这点论文没有任何说明!试想一下,使用BN在不同层设置不同剪枝比例,多调试几个参数,相比也能得到这个性能。当出现一个新模型(GhostNet)如何去剪枝呢?为啥没人去剪枝ShuffleNetV2,是因为压缩到极限了?
作者:影醉阏轩窗
-------------------------------------------
个性签名:衣带渐宽终不悔,为伊消得人憔悴!
如果觉得这篇文章对你有小小的帮助的话,记得关注再下的公众号,同时在右下角点个“推荐”哦,博主在此感谢!

