mmcv阅读笔记
- 不清楚可以点击查看
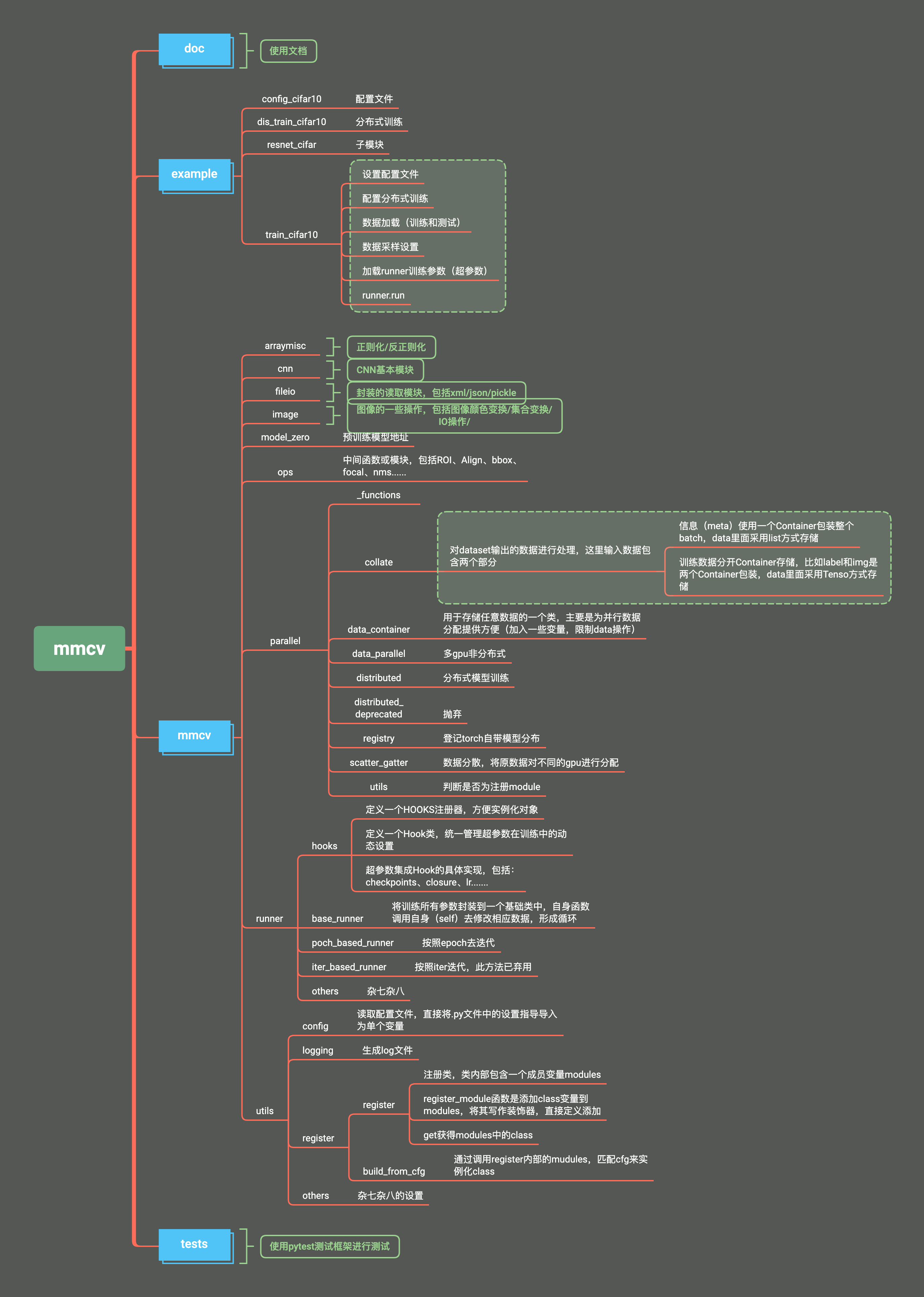
mmcv
- docs :文档
- example :一个训练的例子
- mmcv
-- arraymisc :两个函数(正则化和反正则化)
./mmcv.utils.registry.py 登记注册类,很重要的模块
class Registry:
***简单的地方省略***
def get(self, key):
# 获取存储在字典中的类(模块),在build的时候使用
"""Get the registry record.
Args:
key (str): The class name in string format.
Returns:
class: The corresponding class.
"""
return self._module_dict.get(key, None)
def _register_module(self, module_class, module_name=None, force=False):
# 将类(模型)加入到字典中
if not inspect.isclass(module_class):
raise TypeError('module must be a class, '
f'but got {type(module_class)}')
if module_name is None:
module_name = module_class.__name__
if not force and module_name in self._module_dict:
raise KeyError(f'{module_name} is already registered '
f'in {self.name}')
self._module_dict[module_name] = module_class
def deprecated_register_module(self, cls=None, force=False):
# 装饰器函数,将类(模型)加入到字典,同时返回当前的类(模型)
warnings.warn(
'The old API of register_module(module, force=False) '
'is deprecated and will be removed, please use the new API '
'register_module(name=None, force=False, module=None) instead.')
if cls is None:
return partial(self.deprecated_register_module, force=force)
self._register_module(cls, force=force)
return cls
def register_module(self, name=None, force=False, module=None):
"""Register a module.
A record will be added to `self._module_dict`, whose key is the class
name or the specified name, and value is the class itself.
It can be used as a decorator or a normal function.
Example:
方法一: 不带名字加入,默认为模型的名字
>>> backbones = Registry('backbone')
>>> @backbones.register_module()
>>> class ResNet:
>>> pass
方法二:带名字的加入
>>> backbones = Registry('backbone')
>>> @backbones.register_module(name='mnet')
>>> class MobileNet:
>>> pass
方法三:手动加入到字典
>>> backbones = Registry('backbone')
>>> class ResNet:
>>> pass
>>> backbones.register_module(ResNet)
Args:
name (str | None): The module name to be registered. If not
specified, the class name will be used.
force (bool, optional): Whether to override an existing class with
the same name. Default: False.
module (type): Module class to be registered.
"""
if not isinstance(force, bool):
raise TypeError(f'force must be a boolean, but got {type(force)}')
# NOTE: This is a walkaround to be compatible with the old api,
# while it may introduce unexpected bugs.
if isinstance(name, type):
return self.deprecated_register_module(name, force=force)
# use it as a normal method: x.register_module(module=SomeClass)
# 方法三的使用,直接加入字典
if module is not None:
self._register_module(
module_class=module, module_name=name, force=force)
return module
# raise the error ahead of time
if not (name is None or isinstance(name, str)):
raise TypeError(f'name must be a str, but got {type(name)}')
# use it as a decorator: @x.register_module()
# 方法一和二的使用,装饰器
def _register(cls):
self._register_module(
module_class=cls, module_name=name, force=force)
return cls
return _register
-- cnn: 不同层define、registry、build
-- bricks: 基础层(conv、relu、bn、padding..etc)
./mmcv.cnn.bricks.registry.py
from mmcv.utils import Registry
# 给每个层定义一个容器,相当于归类管理方便
CONV_LAYERS = Registry('conv layer')
NORM_LAYERS = Registry('norm layer')
ACTIVATION_LAYERS = Registry('activation layer')
PADDING_LAYERS = Registry('padding layer')
UPSAMPLE_LAYERS = Registry('upsample layer')
./mmcv.cnn.bricks.activation.py
以其中一个为代表举例说明:
import torch.nn as nn
from mmcv.utils import build_from_cfg
from .registry import ACTIVATION_LAYERS
# 将activation class全部加入dict
for module in [
nn.ReLU, nn.LeakyReLU, nn.PReLU, nn.RReLU, nn.ReLU6, nn.ELU,
nn.Sigmoid, nn.Tanh
]:
ACTIVATION_LAYERS.register_module(module=module)
# 注意:registry只是登记操作,将类名(地址)写入一个字典,相当于import
# build的作用是将registry实例化
def build_activation_layer(cfg):
"""Build activation layer.
Args:
cfg (dict): The activation layer config, which should contain:
- type (str): Layer type.
- layer args: Args needed to instantiate an activation layer.
Returns:
nn.Module: Created activation layer.
"""
return build_from_cfg(cfg, ACTIVATION_LAYERS)
-- utils: 一个计算flops,一个init函数
-- 剩下三个alexnet、resnet、vgg实际模型,未使用mmcv里面的东西
-- fileio
handlers: pickle、yml等文件的读取类
file_client.py: 0.6版本之后新增加的函数,主要是分布式的数据读取,针对比较大的数据进行加速。
io.py: 集成handlers的数据读取
-- image: 图像相关的操作,读取、处理、变换等
-- model_zero: 预训练模型在线加载地址
-- ops: 需要快速操作的函数->NMS、ROIPooling、ROIAligning、sync—BN...etc,具体使用mmdetection再过来看。
-- parallel: 重新封装了torch内部的并行计算,包括数据的collect、distribute、Scatter等,熟悉cuda的可以多了解。
-- runner: 包含hook和runner训练相关的类(重点)
-- hook: 训练的参数封装为Hook类,同时加入到registry之中
./mmcv/runner/hooks/hook.py
from mmcv.utils import Registry
# 全部的 hook 注册字典
HOOKS = Registry('hook')
# Hook基础子类,所有的hook都继承此类,包括:logger、checkpoint、iter、lr...etc
class Hook:
pass
hook的实现方式如下,其它相同:
./mmcv/runner/hooks/checkpoint.py
import os
from ..dist_utils import master_only
from .hook import HOOKS, Hook
# 将checkpoint的hook注册进HOOKS之中
@HOOKS.register_module()
class CheckpointHook(Hook):
@master_only # 多进程使用,仅保存rank=0的checkpoint
def after_train_epoch(self, runner):
pass
-- optimizer: 优化器模块
./mmcv.runner.optimizer.builder.py
import copy
import inspect
import torch
from ...utils import Registry, build_from_cfg
OPTIMIZERS = Registry('optimizer') # torch中标准优化器
OPTIMIZER_BUILDERS = Registry('optimizer builder') #mmcv优化器封装类,内部调用还是OPTIMIZERS,封装之后不同的层使用不用的lr和momentum
def register_torch_optimizers():
torch_optimizers = []
for module_name in dir(torch.optim):
if module_name.startswith('__'): # 排除其它不是优化器参数
continue
_optim = getattr(torch.optim, module_name)
if inspect.isclass(_optim) and issubclass(_optim,
torch.optim.Optimizer):
OPTIMIZERS.register_module()(_optim) # 优化器加入registry
torch_optimizers.append(module_name) # 存储在字典中
return torch_optimizers
TORCH_OPTIMIZERS = register_torch_optimizers() # 存储所有优化器的字典
def build_optimizer_constructor(cfg):
return build_from_cfg(cfg, OPTIMIZER_BUILDERS)
# 创建优化器
def build_optimizer(model, cfg):
optimizer_cfg = copy.deepcopy(cfg)
constructor_type = optimizer_cfg.pop('constructor',
'DefaultOptimizerConstructor')
paramwise_cfg = optimizer_cfg.pop('paramwise_cfg', None)
optim_constructor = build_optimizer_constructor(
dict(
type=constructor_type,
optimizer_cfg=optimizer_cfg,
paramwise_cfg=paramwise_cfg))
optimizer = optim_constructor(model)
return optimizer
./mmcv.runner.optimizer.default_constructor.py
@OPTIMIZER_BUILDERS.register_module()
class DefaultOptimizerConstructor:
# 封装之后的优化器,不同的层使用不同的lr和momentum
def add_params(self, params, module, prefix=''):
pass
./mmcv.runner.base_runner.py
class BaseRunner(metaclass=ABCMeta):
def __init__(self,batch_processor):
# batch_processor: 这是一个计算loss的函数,输入已经固定(model, data, train_mode),输出的loss是固定的在optimizer.py函数中after_train_iter进行反向传播,如果有多个loss,可以修改batch_processor函数,或者修改after_train_iter中的反向传播函数
pass
# 将hook登记进runner自带的list之内self._hooks
def register_hook(self, hook, priority='NORMAL'):
pass
# 调用指定的函数,注意:全部hook都得调用,无论有没有这个功能
def call_hook(self, fn_name):
for hook in self._hooks:
getattr(hook, fn_name)(self) # self表示当前runner
# 加载预训练模型
def load_checkpoint(self, filename, map_location='cpu', strict=False):
pass
# 恢复上一次训练状态
def resume():
pass
# 加载传入的config到hook
def register_training_hooks(...):
pass
# 加载指定hook,register_training_hooks的实际操作
def register_lr_hook(self, lr_config):
pass
#run train val下面详细说明
./mmcv.runnner.epoch_base_runner.py
# 按照epoch进行训练,还有一个函数是按照iter次数进行训练
def train(self, data_loader, **kwargs):
self.model.train()
self.mode = 'train'
self.data_loader = data_loader
self._max_iters = self._max_epochs * len(data_loader)
self.call_hook('before_train_epoch') # 训练epoch之前更新所有的Hook内部参数
time.sleep(2) # Prevent possible deadlock during epoch transition
for i, data_batch in enumerate(data_loader):
self._inner_iter = i
self.call_hook('before_train_iter') # 训练iter之前更新所有的Hook内部参数
if self.batch_processor is None:
outputs = self.model.train_step(data_batch, self.optimizer,
**kwargs) # 使用model自带的loss计算函数
else:
outputs = self.batch_processor(
self.model, data_batch, train_mode=True, **kwargs) # 使用传入的loss计算函数
if not isinstance(outputs, dict):
raise TypeError('"batch_processor()" or "model.train_step()"'
' must return a dict')
if 'log_vars' in outputs:
self.log_buffer.update(outputs['log_vars'],
outputs['num_samples'])
self.outputs = outputs
self.call_hook('after_train_iter') # 训练iter之后更新所有的Hook内部参数,loss的更新也在一步,位于optimizer之中
self._iter += 1
self.call_hook('after_train_epoch') # 训练epoch之后更新所有的Hook内部参数
self._epoch += 1
# 和train部分类似
def val(self, data_loader, **kwargs):
self.model.eval()
self.mode = 'val'
self.data_loader = data_loader
self.call_hook('before_val_epoch')
time.sleep(2) # Prevent possible deadlock during epoch transition
for i, data_batch in enumerate(data_loader):
self._inner_iter = i
self.call_hook('before_val_iter')
with torch.no_grad():
if self.batch_processor is None:
outputs = self.model.val_step(data_batch, self.optimizer,
**kwargs)
else:
outputs = self.batch_processor(
self.model, data_batch, train_mode=False, **kwargs)
if not isinstance(outputs, dict):
raise TypeError('"batch_processor()" or "model.val_step()"'
' must return a dict')
if 'log_vars' in outputs:
self.log_buffer.update(outputs['log_vars'],
outputs['num_samples'])
self.outputs = outputs
self.call_hook('after_val_iter')
self.call_hook('after_val_epoch')
def run(self, data_loaders, workflow, max_epochs, **kwargs):
"""Start running.
Args:
data_loaders (list[:obj:`DataLoader`]): Dataloaders for training
and validation.
workflow (list[tuple]): A list of (phase, epochs) to specify the
running order and epochs. E.g, [('train', 2), ('val', 1)] means
running 2 epochs for training and 1 epoch for validation,说的很清楚
iteratively.
max_epochs (int): Total training epochs.
"""
assert isinstance(data_loaders, list)
assert mmcv.is_list_of(workflow, tuple)
assert len(data_loaders) == len(workflow)
self._max_epochs = max_epochs
for i, flow in enumerate(workflow):
mode, epochs = flow
if mode == 'train':
self._max_iters = self._max_epochs * len(data_loaders[i])
break
work_dir = self.work_dir if self.work_dir is not None else 'NONE'
self.logger.info('Start running, host: %s, work_dir: %s',
get_host_info(), work_dir)
self.logger.info('workflow: %s, max: %d epochs', workflow, max_epochs)
self.call_hook('before_run')
while self.epoch < max_epochs:
for i, flow in enumerate(workflow):
mode, epochs = flow
if isinstance(mode, str): # self.train()
if not hasattr(self, mode):
raise ValueError(
f'runner has no method named "{mode}" to run an '
'epoch')
epoch_runner = getattr(self, mode) # self.train() or self.val()
else:
raise TypeError(
'mode in workflow must be a str, but got {}'.format(
type(mode)))
for _ in range(epochs):
if mode == 'train' and self.epoch >= max_epochs:
return
epoch_runner(data_loaders[i], **kwargs) # 调用self.train() or self.val()
time.sleep(1) # wait for some hooks like loggers to finish
self.call_hook('after_run')
def save_checkpoint(self,
out_dir,
filename_tmpl='epoch_{}.pth',
save_optimizer=True,
meta=None,
create_symlink=True):
"""Save the checkpoint.
Args:
out_dir (str): The directory that checkpoints are saved.
filename_tmpl (str, optional): The checkpoint filename template,
which contains a placeholder for the epoch number.
Defaults to 'epoch_{}.pth'.
save_optimizer (bool, optional): Whether to save the optimizer to
the checkpoint. Defaults to True.
meta (dict, optional): The meta information to be saved in the
checkpoint. Defaults to None.
create_symlink (bool, optional): Whether to create a symlink
"latest.pth" to point to the latest checkpoint.
Defaults to True.
"""
if meta is None:
meta = dict(epoch=self.epoch + 1, iter=self.iter)
else:
meta.update(epoch=self.epoch + 1, iter=self.iter)
filename = filename_tmpl.format(self.epoch + 1)
filepath = osp.join(out_dir, filename)
optimizer = self.optimizer if save_optimizer else None
save_checkpoint(self.model, filepath, optimizer=optimizer, meta=meta)
# in some environments, `os.symlink` is not supported, you may need to
# set `create_symlink` to False
if create_symlink:
mmcv.symlink(filename, osp.join(out_dir, 'latest.pth'))
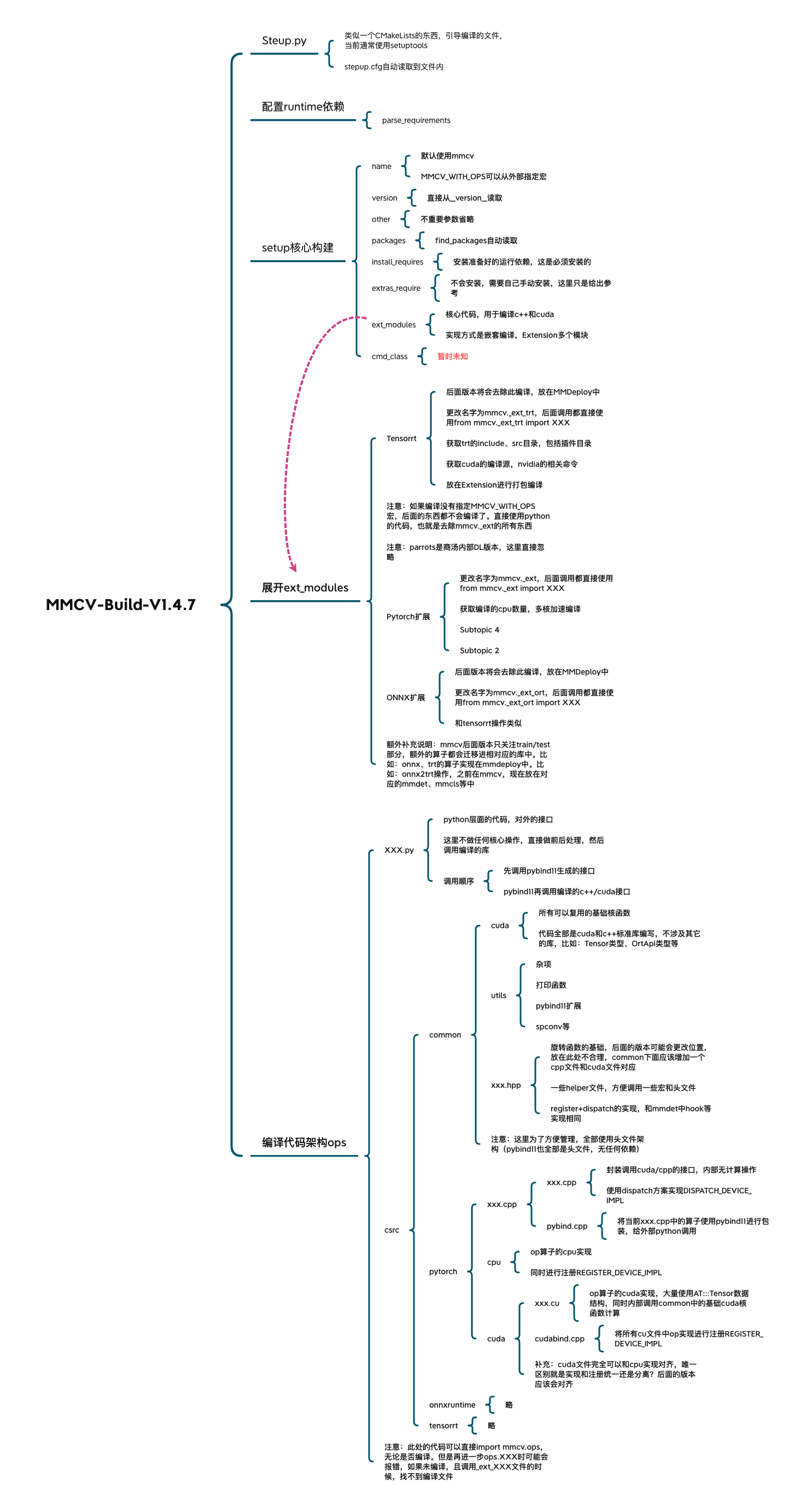
mmcv编译过程
-------------------------------------------
个性签名:衣带渐宽终不悔,为伊消得人憔悴!
如果觉得这篇文章对你有小小的帮助的话,记得关注再下的公众号,同时在右下角点个“推荐”哦,博主在此感谢!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号