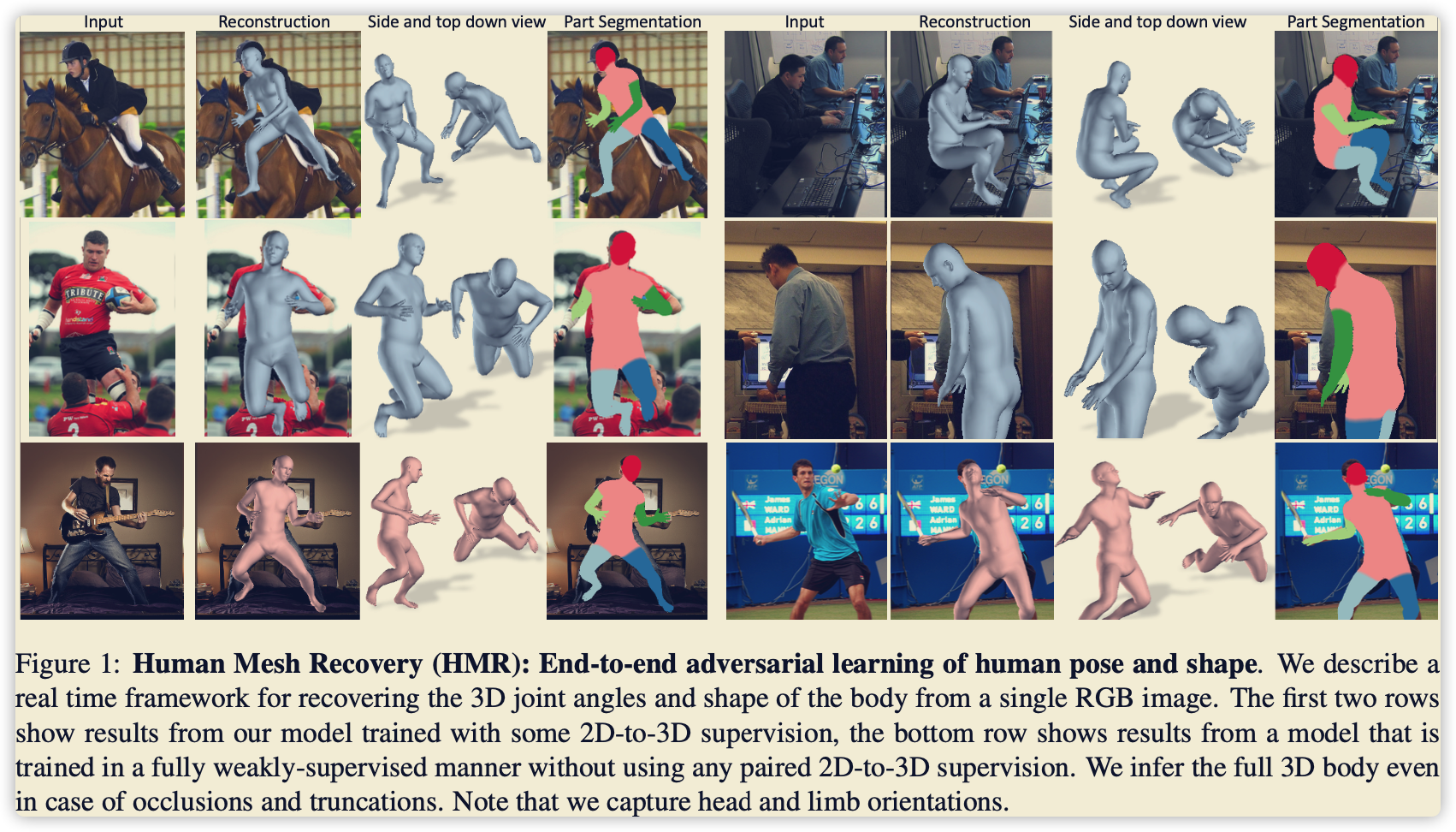
End to end recovery of human shape and pose
目录
End to end recovery of human shape and pose
一. 论文简介
从单张图像中恢复 2D keypoints + 3D keypoints + mesh + instrinsic(图像坐标系到相机坐标系,这里没有相机坐标系),主要在数据量不充足的情况下进行弱监督。
主要做的贡献如下(可能之前有人已提出):
- Mesh supervised weakly
- Iteration regression
- Discriminator
- projection
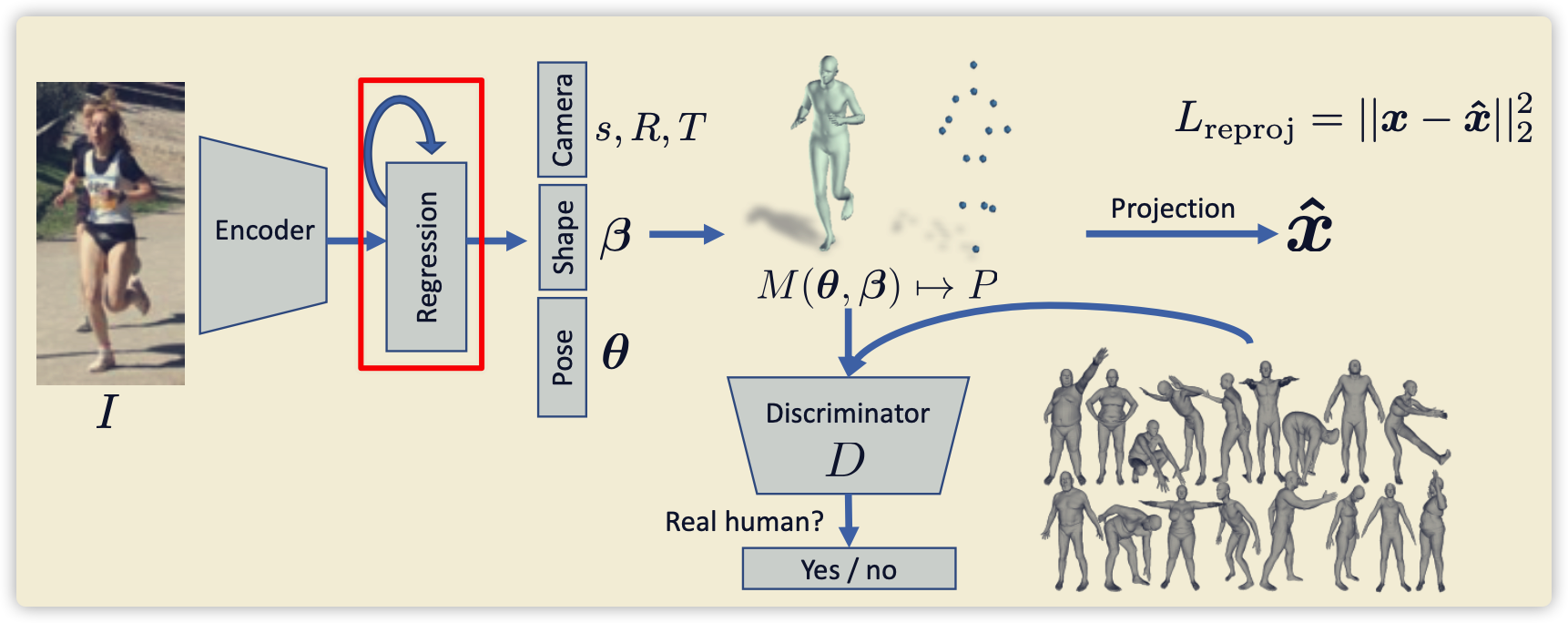
二. 模块详解
2.1 Mesh supervised weakly
论文未使用这部分做弱监督,在其它论文看见的,暂时略过。
2.2 Iteration regression
- 注意不是权重共享
- 注意每次迭代的结果都进行loss计算,不是最后的结果才做loss
- 前向计算同样需要做迭代
class ThetaRegressor(LinearModel):
def __init__(self, fc_layers, use_dropout, drop_prob, use_ac_func, iterations):
super(ThetaRegressor, self).__init__(fc_layers, use_dropout, drop_prob, use_ac_func)
self.iterations = iterations
batch_size = max(args.batch_size + args.batch_3d_size, args.eval_batch_size)
mean_theta = np.tile(util.load_mean_theta(), batch_size).reshape((batch_size, -1))
self.register_buffer('mean_theta', torch.from_numpy(mean_theta).float())
'''
param:
inputs: is the output of encoder, which has 2048 features
return:
a list contains [ [theta1, theta1, ..., theta1], [theta2, theta2, ..., theta2], ... , ], shape is iterations X N X 85(or other theta count)
'''
def forward(self, inputs):
thetas = []
shape = inputs.shape
theta = self.mean_theta[:shape[0], :]
for _ in range(self.iterations):
total_inputs = torch.cat([inputs, theta], 1)
theta = theta + self.fc_blocks(total_inputs) # 不共享权重
thetas.append(theta) # 迭代的theta全部做loss回传
return thetas
2.3 Discriminator
- Gan网络的基础
- 实际人体来自于SMPL模型
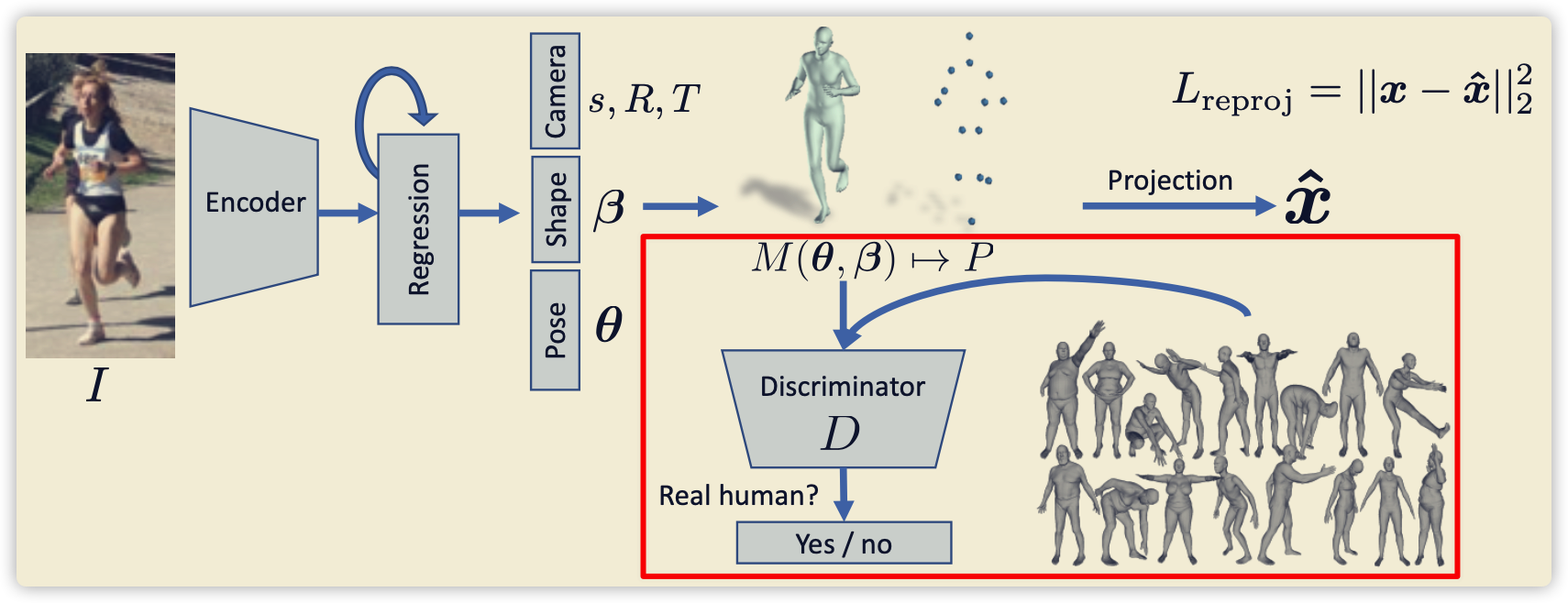
# Discriminator类的前向计算,就是FC层的一些变换,输出一个vector
def forward(self, thetas):
batch_size = thetas.shape[0]
cams, poses, shapes = thetas[:, :3], thetas[:, 3:75], thetas[:, 75:]
shape_disc_value = self.shape_discriminator(shapes)
rotate_matrixs = util.batch_rodrigues(poses.contiguous().view(-1, 3)).view(-1, 24, 9)[:, 1:, :]
pose_disc_value, pose_inter_disc_value = self.pose_discriminator(rotate_matrixs)
full_pose_disc_value = self.full_pose_discriminator(pose_inter_disc_value.contiguous().view(batch_size, -1))
return torch.cat((pose_disc_value, full_pose_disc_value, shape_disc_value), 1)
# 真实为1,错误为0
def batch_encoder_disc_l2_loss(self, disc_value):
k = disc_value.shape[0]
return torch.sum((disc_value - 1.0) ** 2) * 1.0 / k
2.4 projection
- 相机坐标系到图像坐标系的投影,使用2D Loss
- 如果有三维坐标,直接使用3D Loss (如果mesh生产的3D点和实际标注3D点不相同,以mesh为准)
s表示缩放比例,T代表平移,R表示旋转。其中s、T可以表示内参,R放在Mesh内部作为参数。- 弱相机模型:不使用小孔成像,直接使用正向投影。
- 弱相机模型:
-
- 优点-可以直接从相机坐标系(root-relate)直接转化到图像坐标系进行监督。
-
- 缺点:不知道
focal length的情况下,直接强行拟合正向投影存在误差(无法避免,由于存在一个尺度)。
- 缺点:不知道

def batch_orth_proj(X, camera):
'''
X is N x num_points x 3
'''
camera = camera.view(-1, 1, 3)
X_trans = X[:, :, :2] + camera[:, :, 1:]
shape = X_trans.shape
return (camera[:, :, 0] * X_trans.view(shape[0], -1)).view(shape)
# camera space to image space
def _calc_detail_info(self, theta):
cam = theta[:, 0:3].contiguous()
pose = theta[:, 3:75].contiguous()
shape = theta[:, 75:].contiguous()
verts, j3d, Rs = self.smpl(beta = shape, theta = pose, get_skin = True)
j2d = util.batch_orth_proj(j3d, cam)
return (theta, verts, j2d, j3d, Rs)
三. 缺点
- 直接回归内参较为困难
- 数据量小,使用Gan进行监督很难得到鲁棒的结果。可能反而效果更差。
- mesh部分没有进行监督,浪费资源
作者:影醉阏轩窗
-------------------------------------------
个性签名:衣带渐宽终不悔,为伊消得人憔悴!
如果觉得这篇文章对你有小小的帮助的话,记得关注再下的公众号,同时在右下角点个“推荐”哦,博主在此感谢!


