


机器学习方法概述与数据加载
一、机器学习概述
机器学习是从已有的观察数据中学习规律,从而获得知识,建立数学模型,并利用模型对新的观察数据做出预测或解释。机器学习的关键是从已有的观察数据中学习模型,并不断调整参数,使模型拟合已有的观察数据,从而建立合适的数学模型。
从输入的数据特性来分,机器学习算法大体上分为有监督学习和无监督学习。有监督学习主要用于分类和回归;无监督学习主要用于聚类、特征提取和降维。
1.1、有监督学习
有监督学习是指利用机器学习算法,从带有标签的输入数据中学习模型,并使用该模型对新的输入数据计算新的输出来作为新数据关联的预测值。带标签的数据是指每条输入记录有对应的已知输出,这个输出称为标签。每条数据记录是一个数据样本。从已知数据模型中学习得到的模型描述了输入与标签之间的关系,当新的输入到来时,就可以用这个模型来计算相应的输出作为预测标签。
1.2、无监督学习
有监督学习中用于学习的训练数据必须有已知的结果。如果学习算法只需要输入数据,没有与之对应的标签数据,这类机器学习称为无监督学习。无监督学习主要用于聚类和降维,通常用于探索性分析,探索并发现数据之间的隐藏的关系。
聚类是根据输入数据的特征,将数据划分为不同的组,同一组内的数据尽可能相似,不同组之间的数据差别的数据差别尽可能大。通过聚类,发现数据样本之间的关系。
降维是指接受包含较多特征的高维数据,找出特征之间的关系,用较少的特征来描述数据,并尽可能保留原有数据的描述能力。在降维处理中,发现特征之间的关系,去掉冗余的特征,用尽可能少的特征来描述数据,降维数据的复杂程度。无监督学习的降维可用于数据预处理中的特征降噪,去除噪声特征,有利于提高数据处理速度。通过降维,也可以将高维数据投影到二维或三维空间,实现数据在二维或三维空间中的可视化。
二、scikit-learn
scikit-learn认为最好使用二维表来表示数据。可以用二维数组或矩阵表示二维表。每行称为一个样本,每列表示一个特征。每个样本表示一个对象某一时刻的特征。每个特征表示样本某个特征的观测值,可以是离散的值,也可以是连续的值。
以下的数据是在UCI上找寻的数据,这是官网:https://archive.ics.uci.edu/datasets
UCI是专门用于机器学习的数据集,大家可以在这里面下载数据学习。
#分离红酒特征矩阵喝标签数据
import pandas as pd
#设置DataFrame以右对齐方式打印输出
pd.set_option('display.unicode.east_asian_width',True)
#读取csv文件
df = pd.read_csv('winequality-red.csv',sep=';')
#使用iloc切片方法
"""
iloc方法:
通过行或列的位置序号来切片
"""
print("原始数据前3行、后5列:\n",df.iloc[:3,-5:],sep='')
print("原始数据形状:",df.shape) #(1599, 12)
#使用drop()删除方法
"""
drop方法:
drop()删除指定的行或列
drop(self,labels=None,axis=0,index=None,columns=None,level=None,inplace=False,errors='raise')
"""
X = df.drop("quality",axis=1)
print("特征部分前3行、后5列:\n",X.iloc[:3,-5:],sep='')
print("特征数据形状:",X.shape)
y = df['quality']
print("目标数据前3行:\n",y[:3],sep='')
print("目标数据形状:",y.shape)
原始数据前3行、后5列:
density pH sulphates alcohol quality
0 0.9978 3.51 0.56 9.4 5
1 0.9968 3.20 0.68 9.8 5
2 0.9970 3.26 0.65 9.8 5
原始数据形状: (1599, 12)
特征部分前3行、后5列:
total sulfur dioxide density pH sulphates alcohol
0 34.0 0.9978 3.51 0.56 9.4
1 67.0 0.9968 3.20 0.68 9.8
2 54.0 0.9970 3.26 0.65 9.8
特征数据形状: (1599, 11)
目标数据前3行:
0 5
1 5
2 5
Name: quality, dtype: int64
目标数据形状: (1599,)
1、scikit-learn中的机器学习基本步骤
scikit-learn为各种机器学习提供了统一的接口,学习算法被封装为类。机器学习的任务用一串基本算法实现。
步骤:(获取数据后)
1、首先要进行数据预处理
2、将数据分为特征矩阵和目标数据
3、将样本分为训练集和测试集
如果某个特征的方差远大于其他特征值的方差,那么它在算法学习中将占据主导位置,会导致算法不能学习其他特征或者降低了其他特征在模型中的作用,从而导致模型的收敛速度慢甚至不收敛,因此需要先对特征数据进行标准化或归一化的缩放处理。
如果数据的特征较多,为了提高计算机速度,可能需要特征选择和特征提取。
三、数据加载
数据是机器学习建立模型的基础,也是预测的根据。原始数据通常以各种形式存在。为了方便学习,也会用到scikit-learn中的内置数据集和仿真数据集。
3.1、使用scikit-learn构造仿真数据集
1、利用make_blobs()函数生成聚类数据集
sklearn.datasets模块下的make_blobs(n_sample=100,n_features=2,*,centers=None,cluster_std=1.0,center_box=(-10.0,10.0),shuffle=True,random_state=None,return_centers=False)
该函数用来生成服从高斯分布的聚类数据集。
函数形式参数中单独的一个星号是位置标志位,表示该位置之后的参数在函数调用时只能以关键参数的形式赋值,该星号本身不是参数。
n_sample如果是整数int类型,则表示在集群中平均分配的总数据点数量;如果是类似于数组的值,每个元素分别表示各个集群的样本数量。
n_features表示每个样本的特征数量,也就是自变量的个数。
centers表示生成的聚类中心数或固定的聚类中心位置。
2、利用make_classification()函数生成分类数据集
sklearn.datasets模块中的函数make_classification(n_sample=100,n_features=20,*,n_informative=2,n_redundant=2,n_classes=2,shuffle=True)
n_sample表示要创建的样本数量,默认为100
n_features表示总特征个数,默认为20
n_classes表示类别个数
shuffle表示是否打乱样本和特征,默认为True。
3、利用make_regression()函数生成回归数据集
sklearn.datasets模块的函数make_regression(n_targets=1,bias=0.0,noise=0.0,coef=False)
n_targets表示回归目标的个数。默认情况下,输出的目标是标量。
bias表示线性模型中的偏差。
noise表示输出的高斯噪声的标准偏差
coef表示是否返回底层线性模型的系数。
4、加载其他的数据集
5、通过pandas-datareader导入金融数据
6、通过第三方平台API加载数据
Tushare大数据开放社区免费提供各类数据。用户注册后,生成一个token证书。有了证书可以方便获取数据。
四、划分数据分别用于训练和测试
4.1、有监督分类学习步骤示例
分类问题的目标是根据特征值确定样本类别。已知一组样本数据,每个样本表示一个用一组特征数据描述的对象,并且已知这些对象的类别,算法根据这组数据学习每个样本特征数据与类别标签数据的对应关系并建立相应的模型,然后将新数据的特征值输入模型中,计算新数据所对应的标签值。
1、准备数据
from sklearn.datasets import load_iris
iris_data = load_iris() #默认返回Bunch类型的对象
以上是加载sklearn自带的数据
还可以再UCI机器学习库下载数据并加载
2、将数据划分为训练集和测试集
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
iris_data = load_iris() #默认返回Bunch类型的对象
X_train,X_test,y_train,y_test = train_test_split(
iris_data.data,iris_data.target,
test_size=0.2,random_state=0)
print("训练集特征与标签数据形状:",X_train.shape,y_train.shape)
print("测试集特种与标签数据形状:",X_test.shape,y_test.shape)
#运行结果
训练集特征与标签数据形状: (120, 4) (120,)
测试集特种与标签数据形状: (30, 4) (30,)
3、可视化训练数据,直观了解训练数据的分布
绘制散点图可以直观地发现特征之间的关系。
X_train_df = pd.DataFrame(X_train,columns=iris_data.feature_names)
pd.plotting.scatter_matrix(X_train_df,c = y_train,
figsize=(10,8),hist_kwds={'bins':20},
alpha= .9,s=80)
plt.show()

4、构建模型
线性支持向量分类器
LinearSVC(sklearn. base. BaseEstimator. sklearn. ......)
class_model = LinearSVC(random_state=1,max_iter=10000) #构建模型对象,max_iter表示最大迭代次数
class_model.fit(X_train,y_train) #从训练数据中学习模型参数
5、评估模型
分类模型的predict()方法可以根据特征矩阵来预测样本类别。有监督学习中,可以将预测标签与真实标签进行比较来判断预测准确性。
分类模型score()方法返回模型的预测准确率。如果score()方法里面传入的是训练集数据,那么模型先利用训练好的模型计算X_train中各样本的预测分类结果,然后将此结果与真实的分类标签(y_train)进行比较,最后计算预测正确的样本数量占训练集总样本数量的比例,这个比例称为训练正确率;如果score()方法里面传入的是测试集数据,那么模型先利用训练好的模型计算X_test中各样本的预测分类结果,然后将此结果与真实的分类标签(y_test)进行比较,最后计算预测正确的样本数量占测试集总样本数量的比例,这个比例为测试集准确率。
y_train_predict = class_model.predict(X_train)
y_test_predict = class_model.predict(X_test)
print("测试集的预测分类:",y_train_predict)
print("测试集的真实分类:",y_test)
6、做出预测
利用模型,判断鸢尾花属于哪一个品种
X_new = np.array([[4.5,2.8,2.5,0.3]]) #测试用例
class_code = class_model.predict(X_new) #创建测试用例代码
print("类型代码:",class_code)
print("类型名称:",iris_data["target_names"][class_code])
4.2、有监督回归学习步骤示例
回归时根据输入的特征值计算输出值,该输出值是连续空间的某个值,不是固定的几个值。分类算法中的输出是固定的几个离散值。已知一组样本数据,每个样本表示一个用一组特征数据描述的对象,并且已知这些对象对应的输出值,算法根据这组数据学习每个样本特征数据与输出值的对应关系并建立相应的模型,然后将新数据的特征值输入模型中,计算新数据所对应的输出值,这就是回归学习的过程。
1、读取数据
2、划分训练集与测试集
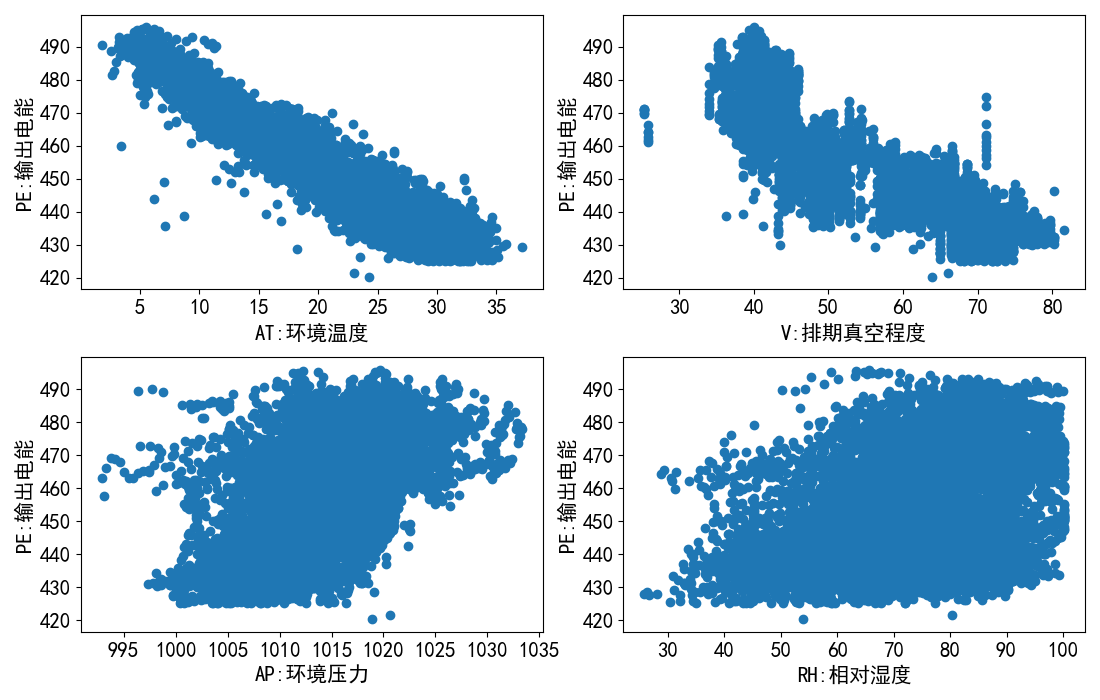
3、观察数据的基本关系
import pandas as pd
ccpp_data = pd.read_excel('Folds5x2_pp.xlsx',index_col=None)
# print(ccpp_data[:3])
x = ccpp_data.iloc[:,:4].values.astype(float)
y = ccpp_data.iloc[:,-1:].values.astype(float)
# print(x.shape)
# print(y.shape)
# print(x[:3])
# print(y[:3])
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.2,random_state=0)
# print(x_train.shape)
# print(x_test.shape)
import numpy as np
import matplotlib.pyplot as plt
#数组的水平组合
train_array = np.hstack((x_train,y_train))
#创建DataFrame对象
train_df = pd.DataFrame(train_array,columns=ccpp_data.columns)
#通过corr()方法计算每对属性之间的标准关系系数
corr_matrix = train_df.corr()
# print("皮尔逊系数矩阵:\n",corr_matrix)
# print("各特征属性与每小时电量输出之间的关系:\n",corr_matrix["PE"].sort_values(ascending=False),sep="")
#使用可视化方法
plt.rcParams['font.sans-serif'] = ['SimHei'] #用来正常显示中文
plt.rcParams["axes.unicode_minus"] = False #用来正常显示负号
d = {'AT':'环境温度','AP':'环境压力','RH':'相对湿度','V':'排期真空程度','PE':'输出电能'}
y_col_name = ccpp_data.columns[-1:][0]
#在一个图形的四个子图中输出
"""
subplot()函数绘制多轴图
将整个区域划分成rows行,cols列个子区域
fig为整个图形
axes为图形的列表
"""
fig,axes = plt.subplots(ncols=2,nrows=2,figsize=(11,7))
for ax,col_name in zip(axes.ravel(),ccpp_data.columns[:-1]):
print(type(train_df[col_name]))
ax.scatter(x=np.array(train_df[col_name]),y = np.array(train_df[y_col_name]))
plt.sca(ax)
plt.xticks(fontsize=15)
plt.yticks(fontsize=15)
plt.xlabel(xlabel=f"{col_name}:{d[col_name]}",fontsize=15)
plt.ylabel(ylabel=f"{y_col_name}:{d[y_col_name]}",fontsize=15)
#调整子图间距
plt.subplots_adjust(wspace=0.3,hspace=0.5)
plt.show()
4、创建模型
5、评估模型
6、用新的数据来预测输出
4.3、无监督聚类学习步骤示例
聚类是将样本对象划分为组,使得簇内的样本相似度尽可能高、簇间的样本相似度尽可能低。相似度可以用距离等指标来度量。聚类算法的目标是为每个样本分配一个数字来表示给样本属于哪个簇。
1、读取数据
2、观察特征数据的分布与区分度
3、数据预处理
如果某个特征属性的方差远大于其他特征的方差,那么它在算法学习中将占据主导位置,会导致算法不能学习其他特征属性或者降低了其他特征属性在模型中的作用,从而导致模型收敛速度慢甚至不收敛,因此需要先对特征数据进行标准化或归一化的缩放处理。
4、用k-均值聚类算法训练模型
五、scikit-learn编程接口风格
在创建模型对象阶段,大多数类提供了合理默认的参数值,方便快捷创建一个模型对象。
创建模型对象后,调用对象的fit()方法,并将待学习的数据集传递给它。fit()方法根据数据集的特征矩阵及其对应标签学得模型参数。
通过fit()方法学的模型参数后,调用模型对象的transform()方法。该方法根据fit()方法学得的参数将特征矩阵进行转换后根据特征矩阵计算每个样本对应的标签值。
执行transform()方法后,调用模型的predict()方法可以根据新数据来预测分类标签或回归值。
可以使用score()方法衡量模型的预测质量。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通