Python网络爬虫案例(二)——爬取招聘信息网站
利用Python,爬取 51job 上面有关于 IT行业 的招聘信息
版权声明:未经博主授权,内容严禁分享转载
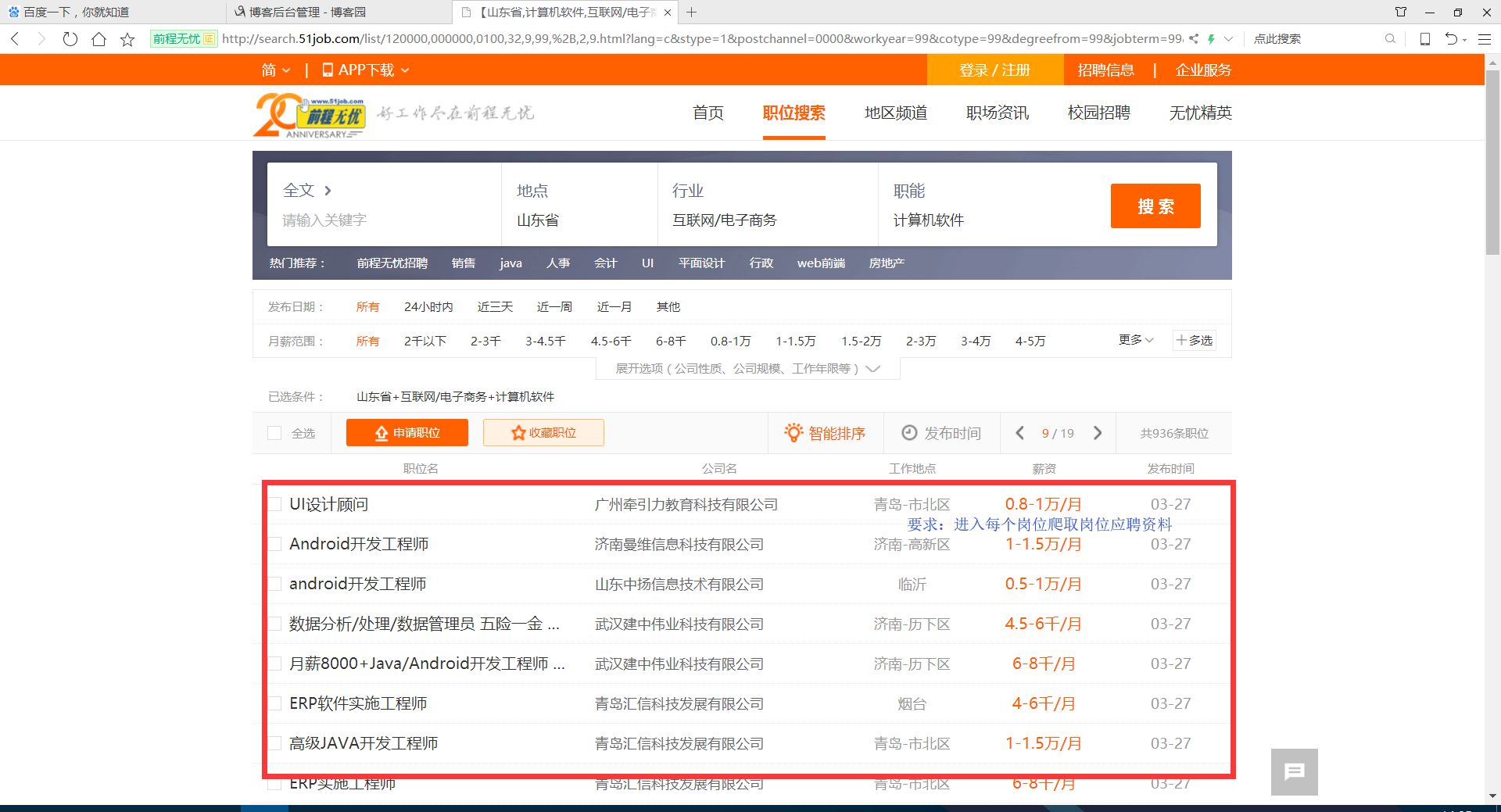
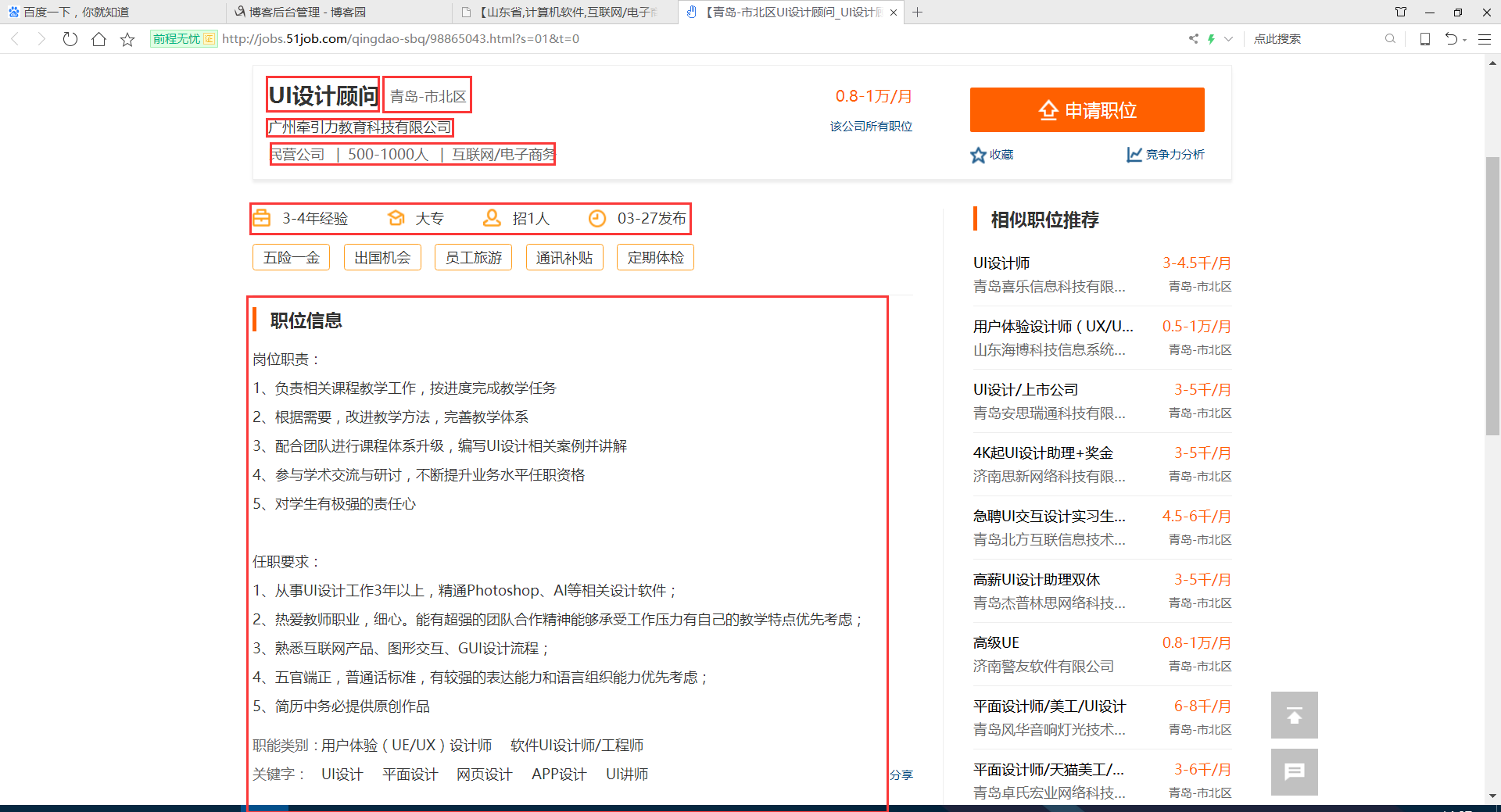
案例代码:

# __author : "J" # date : 2018-03-07 import urllib.request import re import pymysql connection = pymysql.connect(host='127.0.0.1', port=3306, user='root', password='******', db='51job', charset='utf8') cursor = connection.cursor() num = 0 textnum = 1 while num < 18: num += 1 # 51job IT行业招聘网址 需要翻页,大约800多条数据 request = urllib.request.Request( "http://search.51job.com/list/120000,000000,0100,32,9,99,%2B,2," + str( num) + ".html?lang=c&stype=1&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=1&dibiaoid=0&address=&line=&specialarea=00&from=&welfare=") response = urllib.request.urlopen(request) my_html = response.read().decode('gbk') # print(my_html) my_re = re.compile(r'href="(.*?)" onmousedown="">') second_html_list = re.findall(my_re, my_html) for i in second_html_list: second_request = urllib.request.Request(i) second_response = urllib.request.urlopen(second_request) second_my_html = second_response.read().decode('gbk') # 职位 地区 工资 公司名称 公司简介 # 工作经验 学历 招聘人数 发布时间 # 职位信息 联系方式 公司信息 second_my_re = re.compile('<h1 title=.*?">(.*?)<input value=.*?' + '<span class="lname">(.*?)</span>.*?' + '<strong>(.*?)</strong>.*?' + 'target="_blank" title=".*?">(.*?)<em class="icon_b i_link"></em></a>.*?' + '<p class="msg ltype">(.*?)</p>.*?</div>' , re.S | re.M | re.I) second_html_news = re.findall(second_my_re, second_my_html)[0] zhiwei = second_html_news[0].replace("\n|\t|\r|\r\n", '').replace(" ", '').replace(" ", '').replace( " ", '') diqu = second_html_news[1].replace("\n|\t|\r|\r\n", '').replace(" ", '').replace(" ", '').replace( " ", '') gongzi = second_html_news[2].replace("\n|\t|\r|\r\n", '').replace(" ", '').replace(" ", '').replace( " ", '') gongsimingcheng = second_html_news[3].replace("\n|\t|\r|\r\n", '').replace(" ", '').replace(" ", '').replace( " ", '') gongsijianjie = second_html_news[4].replace("\n|\t|\r|\r\n", '').replace(" ", '').replace(" ", '').replace( " ", '') # print(zhiwei,diqu,gongzi,gongsimingcheng,gongsijianjie) try: second_my_re = re.compile('<span class="sp4"><em class="i1"></em>(.*?)</span>' , re.S | re.M | re.I) yaoqiu = re.findall(second_my_re, second_my_html)[0] except Exception as e: pass try: second_my_re = re.compile('<span class="sp4"><em class="i2"></em>(.*?)</span>' , re.S | re.M | re.I) yaoqiu += ' | ' + re.findall(second_my_re, second_my_html)[0] except Exception as e: pass try: second_my_re = re.compile('<span class="sp4"><em class="i3"></em>(.*?)</span>' , re.S | re.M | re.I) yaoqiu += ' | ' + re.findall(second_my_re, second_my_html)[0] except Exception as e: pass try: second_my_re = re.compile('<span class="sp4"><em class="i4"></em>(.*?)</span>' , re.S | re.M | re.I) yaoqiu += ' | ' + re.findall(second_my_re, second_my_html)[0] except Exception as e: pass # print(yaoqiu) second_my_re = re.compile('<div class="bmsg job_msg inbox">(.*?)<div class="mt10">' , re.S | re.M | re.I) gangweizhize = re.findall(second_my_re, second_my_html)[0].replace("\r\n|\n|\t|\r", '').replace(" ", '').replace( " ", '').replace(" ", '') dr = re.compile(r'<[^>]+>', re.S) gangweizhize = dr.sub('', gangweizhize) second_my_re = re.compile('<span class="bname">联系方式</span>(.*?)<div class="tBorderTop_box">' , re.S | re.M | re.I) lianxifangshi = re.findall(second_my_re, second_my_html)[0].replace("\r\n|\n|\t|\r", '').replace(" ", '') dr = re.compile(r'<[^>]+>', re.S) lianxifangshi = dr.sub('', lianxifangshi) lianxifangshi = re.sub('\s', '', lianxifangshi) second_my_re = re.compile('<span class="bname">公司信息</span>(.*?)<div class="tCompany_sidebar">' , re.S | re.M | re.I) gongsixinxi = re.findall(second_my_re, second_my_html)[0].replace(" ", '') dr = re.compile(r'<[^>]+>', re.S) gongsixinxi = dr.sub('', gongsixinxi) gongsixinxi = re.sub('\s', '', gongsixinxi) print('第 '+str(textnum) + ' 条数据 **********************************************') print(zhiwei, diqu, gongzi, gongsimingcheng, gongsijianjie, yaoqiu, gangweizhize, lianxifangshi, gongsixinxi) textnum += 1 # try: # sql = "INSERT INTO `jobNews` (`position`,`region`,`Pay`,`company`,`Nature`,`Requirement`,`Job_information`,`Contact_information`,`Company_information`) VALUES ('" + zhiwei + "','" + diqu + "','" + gongzi + "','" + gongsimingcheng + "','" + gongsijianjie + "','" + yaoqiu + "','" + gangweizhize + "','" + lianxifangshi + "','" + gongsixinxi + "')" # cursor.execute(sql) # connection.commit() # print('存储成功!') # except Exception as e: # pass cursor.close() connection.close()
效果:
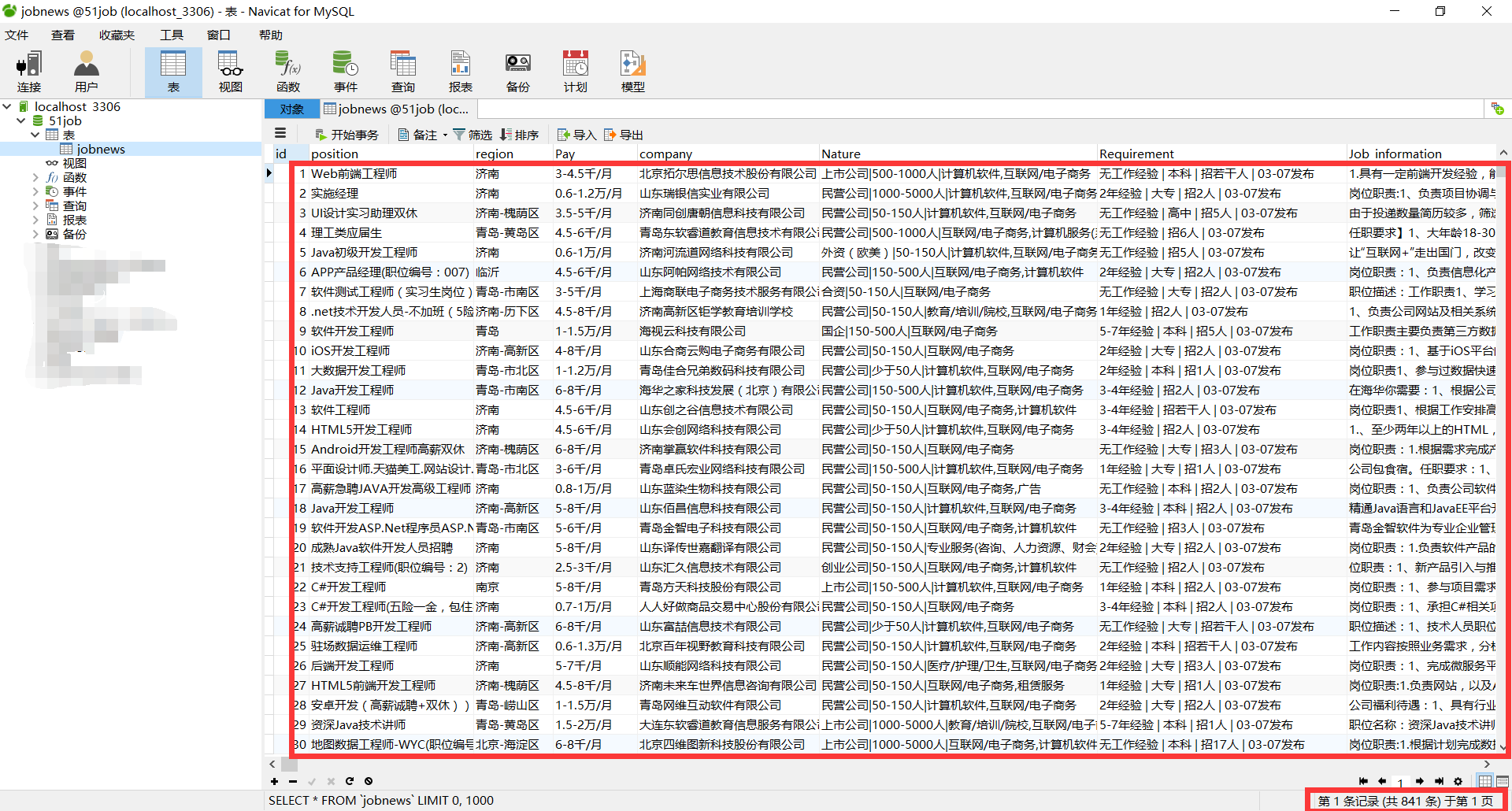
我正则表达式用的不好,所以写的很麻烦,接受建议~
【版权声明】本博文著作权归作者所有,任何形式的转载都请联系作者获取授权并注明出处!
【重要说明】博文仅作为本人的学习记录,论点和观点仅代表个人而不代表技术的真理,目的是自我学习和有幸成为可以向他人分享的经验,因此有错误会虚心接受改正,但不代表此刻博文无误!
【博客园地址】叫我+V : http://www.cnblogs.com/wjw1014
【CSDN地址】叫我+V : https://wjw1014.blog.csdn.net/
【Gitee地址】叫我+V :https://gitee.com/wjw1014
【重要说明】博文仅作为本人的学习记录,论点和观点仅代表个人而不代表技术的真理,目的是自我学习和有幸成为可以向他人分享的经验,因此有错误会虚心接受改正,但不代表此刻博文无误!
【博客园地址】叫我+V : http://www.cnblogs.com/wjw1014
【CSDN地址】叫我+V : https://wjw1014.blog.csdn.net/
【Gitee地址】叫我+V :https://gitee.com/wjw1014


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 零经验选手,Compose 一天开发一款小游戏!
· 一起来玩mcp_server_sqlite,让AI帮你做增删改查!!