从Oracle迁移到MySQL方案汇总(转载)
转载自https://zhuanlan.zhihu.com/p/94254106
当企业内部使用的数据库种类繁杂时,或者有需求更换数据库种类时,都可能会做很多数据迁移的工作。有些迁移很简单,有些迁移可能就会很复杂,大家有没有考虑过为了顺利完成复杂的数据库迁移任务,都需要考虑并解决哪些问题呢?
在以前的工作中,我迁移过Oracle到Informix、Oracle和SQLServer、Oracle到MySQL。 在目前的公司又因为去O的关系,做了大量的迁移工作,栽了不少坑,所以和大家交流一下在迁移的过程中的一些实践。
分享大纲:
- 去O前的准备与考虑
- 确定目标数据库
- 表和数据对象的迁移及工具比较
- 其它对象的迁移
- 一些性能参数
一、去O前的准备与考虑

因为成本预算等多方面原因,公司决定要去O,在去O之前首先要决定拿什么来替代Oracle,拿什么工具将源数据库的数据导到目标数据库、怎么导等的。导的过程的增量数据怎么处理。导的时候源数据和目标,以及数据的数据类型差异如何处理,像视图、存储过程、触发器这种数据库对象之间的不同怎么解决,导的时候如何不影响源数据库性能。导完以后的数据比对以及数据无误后应用的性能问题都是要考虑的。
二、确定目标数据库

在我们做数据迁移之前先确认的就是target database ,就是要迁到什么数据库上,经过了一些调研,从速度、流行度等多个方面选择最终了MySQL。因为相信被Oracle收购后表现会越来越好。
当然也想过使用PosgreSQL,不过做了一个测试,发现MySQL5.7的QPS在比同样配置的PG要高,基于在线事务对性能的要求,最终还是选择了MySQL。选择了MySQL以后,对于MySQL的分支和版本的选择也很头痛。Percona增加了很多性能相关补丁,MariaDB支持更多的引擎,官方的版本也能满足目前的需求,从保守的原则上,我们的核心数据库最终还是使用了官方的版本,一些不是太核心的数据库,其它的分支也有在用。
因为MyCat的支持关系最终选择的是5.6的版本(目前MyCat1.6对MySQL5.7的支持不是太好),为了达到像Oracle的DG/OGG一样稳定的架构,我们把MySQL的架构做成了双机房的MHA,并且用了MyCat做了读写分离。同样的Oracle这边因为同时还有应用在跑,为了分散Oracle的压力,所有的同步作业也是在备库和异机房的OGG端进行的操作。
三、表和数据对象的迁移及工具对比

在选择了合适的DB来替换Oracle后,下一步就是选择一个合适的迁移工具来做迁移。我们在迁移工具的选择方面花费了大量时间和精力。迁移是一个漫长而困难的工作,我们在迁移的过程中也历经了不同的阶段,使用了不同的方法。从最初级的load csv升级成自已写的程序,再去找Oracle和MySQL官方推荐的工具,最后也尝试了一些 ETL的工具,被这么多工具摧残之后,幸运的是能够在不同的场情下使用不同的方式。
接下来我们对每一种都进行一个简单的介绍和使用中遇到的一些问题。
1、SQL LOAD

我们在最早的时候只是进行某个项目的迁移工作,因为时间的关系并没有进行迁移工具的选型以及使用,使用了最简单的方式就是SQL LOAD。
所有的操作步骤比把大象放进冰箱还要简单,简单得只要分两步,第一步把Oracle的数据导成CSV或者SQL,然后再load或者source到MySQL中就可以了。
把Oracle的数据导成CSV或者SQL可以用很多工具,比如SQL developer或者toad,不过我还是更推荐spool,大家应该都用过spool,他可以结合set把内容输出到指定的文件中,然后选择合理的行列分隔符,就可以产生csv文件了。
使用SQL LOAD的优点就是速度快和超级简单,不过同样的,它也会有很多弊端,它很难做成自动化和全面普及到很多张表上,每有一张表的操作就要写SQL拼CSV,然后还不能保证是一样的分隔符,大多数时候对lob字段操作也很麻烦。对类似于comments的评论字段也很难原样的copy过去。
我们来看一个简单的例子:
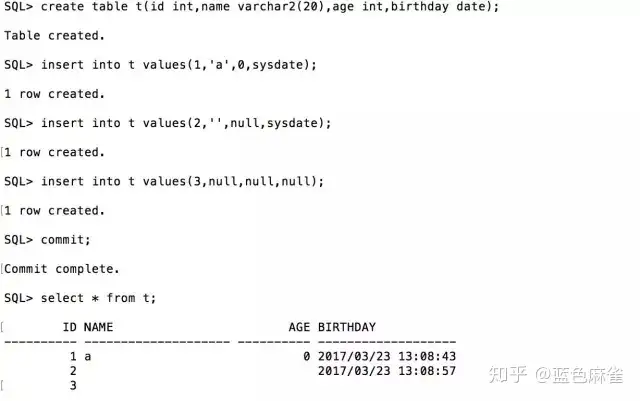
第一步我先在Oracle这边创建了一张表,很简单只有四列,然后insert了三条数据查看了一下内容。
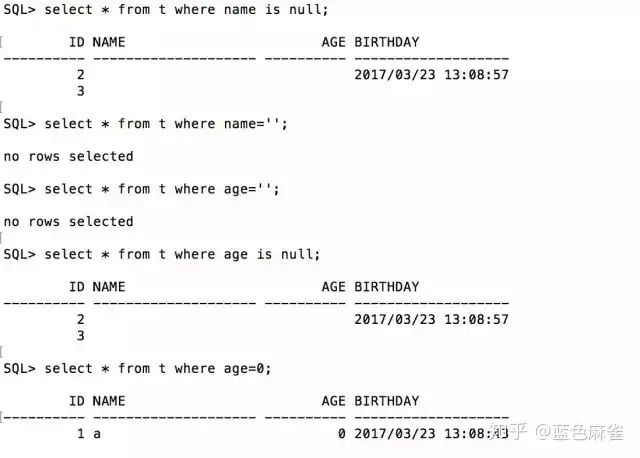
做了一些简单的可能会用到的查询。
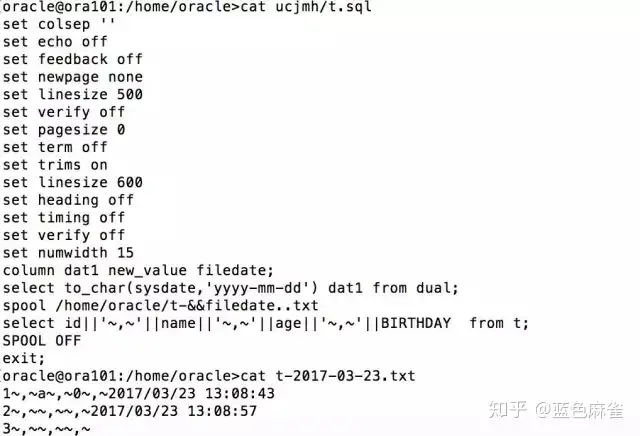
看一下导出用的spool的内容,实际用的时候肯定会比这个更复杂,要对换行、time、lob等进行更多的函数处理。然后把数据导了出来看一下。
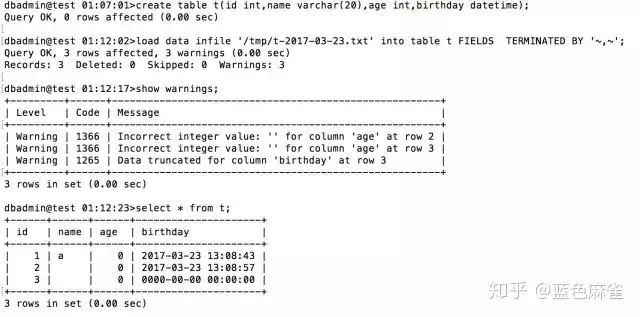
接着我又在MySQL创建一张一样的表把数据load了进去。load的语法不是我们今天要分享的重点,它的作用就是把file load into table.可以指定行列分隔符。 可以看到数据load进去了三行,同时也给出了三个警告,第二行一个,第三行两个,分别是int类型的列传了一个空字符串和时间类型的被截取了。查看一下表里的数据,发现和预期的不一样。

然后把刚刚在Oracle那边进行的查询再次查询一下,发现结果都变得不一样了。
这是因为在MySQL里int类型如果插入的为空,结果会自动转成0。
官方文档上有明确的说明:
An empty field value is interpreted different from a missing field:
For string types, the column is set to the empty string.
For numeric types, the column is set to 0.
For date and time types, the column is set to the appropriate “zero” value for the type.
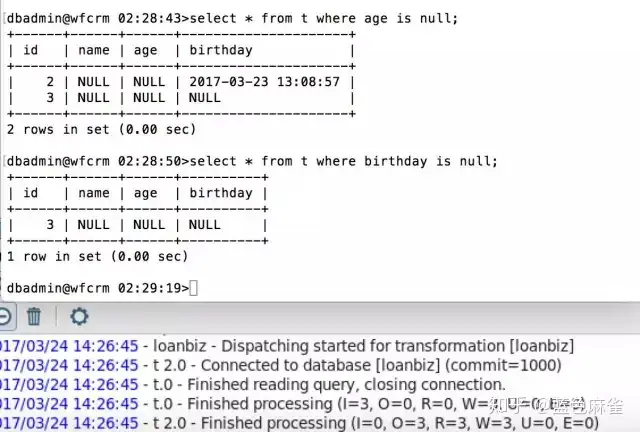
我们再看一下用etl工具迁移过来的数据,可以发现数据被insert成了null ,符合了Oracle的意思,其实这就是sqlload时一些弊端,数据类型可能弄得不是原来的数据了。同样的,我们也可以设置成严格的模式,int类型的不允许插入null,我们会在下面的sql_mode里讲到。
2、Python

迁了部分数据之后觉得load数据虽然简单和快,但是瑜不掩瑕,总是有这样那样的问题,迁移之后往往还会同时伴随着大量的数据修复工作。
很快的,我们就弃用了这种操作,在这里要说明一下SQL LOAD的操作因为速度又快又不依赖其它组件,所以适用于数据类型并不复杂的单表操作,然后就写了python代码来接替它来完成数据迁移的操作,使用python的话其实也很简单,可以分为三步,第一步就是建立配置表,同时和MySQL的表进行mapping,标识出是全量的还是增量的,如果是增量的,以什么做为增量来处理。第二步就是根据mapping进行code、code、code,最后根据不同的入参写好crontab就可以进行调度就可以了。
使用python处理的过程中可以对一些数据进行转换,也更加灵活地配置了一些选项,实现了较强的逻辑控制,当然也有一些缺点:它的速度慢了太多(不过也只比load慢,比起来后面要介绍的Java编写的软件还是快很多)。对于异常的处理也花费了大量的代码逻辑,同时也要会写代码。
我们可以简单来看一下它的实现:
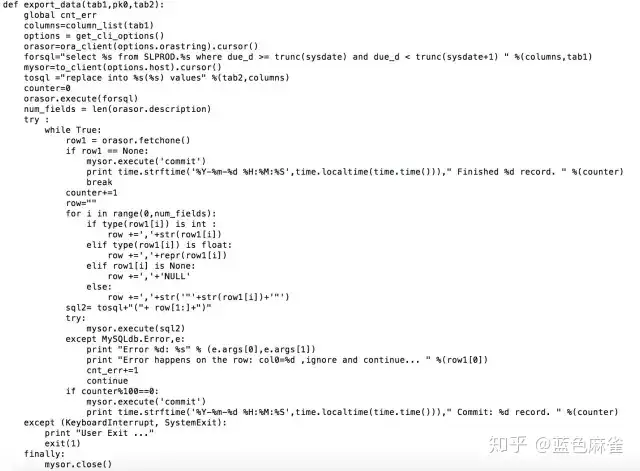
这一个代码片断,显示了增量同步每一天的数据逻辑。
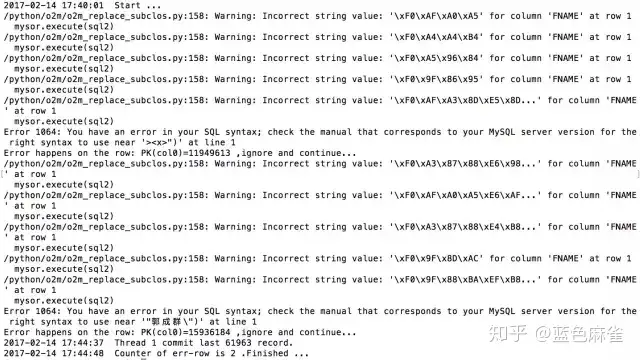
这是每天跑批之后生成的log,可以看出来把warning和error都列了出来,同时也对行数进行了统计。已经可以说是一个不错的小型产品了。可看出来6w条数据用了4s和load来比算是慢的,但是和Java之类的比算是快的了。
3、OGG

因为python开发的这一套东西虽然也不算太慢,但因为要自己用代码实现较强的逻辑,并且有些需求在Oracle的业务还没有完全下线之前要实时地同步到MySQL里来,所以我们又研究了一下OGG的做法。先提前说一下,OGG的应用场景就是那种要求实时并且可能需要回写数据的。
OGG的用法说起来很简单,只要配置好Oracle端,配置好MySQL端,然后对应的进程起起来就可以了。但用过OGG的人都知道配置一套OGG本身就很麻烦了,异构数据库之间再进行同步的话,调通并可用需要很久的配置时间,所以我大致说一下做法,除非真的有这种硬性需求,不然不推荐使用。

简单说一下用OGG的过程和注意事项:
1、 5.6版本需要12.1.2版本的OGG才支持
2、异构数据库之间不支持DDL复制
- 从Oracle同步到MySQL,属于异构架构,不支持DDL同步,包括添加和删除字段,添加和删除索引,重命名表,表分析统计数据。
- 若是涉及到源端和目标端DDL操作,需要进行源端和目标端同时手工操作。
3、必须要配置defgen,且文件必须放在相同的目录。
4、如果要是双向的话,就必须把MySQL端的binglog设置成row
binlog_format: This parameter sets the format of the logs. It must be set to the value of ROW, which directs the database to log DML statements in binary format. Any other log format (MIXED or STATEMENT) causes Extract to abend.
5、GoldenGate对MySQL只支持InnoDB引擎。所以,在创建MySQL端的表的时候,要指定表为InnoDB引擎。
create table MySQL (name char(10)) engine=innodb;
所有的帮助可以online help里去看
http://docs.Oracle.com/goldengate/c1221/gg-winux/GIMYS/system_requirements.htm#GIMYS122
4、MySQL Migration Toolkit

OGG是Oracle官方推荐的工具,使用原理就是基于日志的结构化数据复制,通过解析源数据库在线日志或归档日志获得数据的增量变化,再将这些变化应用到目标数据库,那MySQL官方没有提供工具呢?答应是肯定的。
MySQL官方同样也提供一个用于异构之间的数据迁移工具,从MySQL到其它数据库,或者从其它数据库到MySQL都是可以的。这个工具就是MySQL Migration Toolkit。这个工具可以单独被下载,也被集成到了MySQL wrokbench里。不过如果单独下载的话 只有windows的版本。
https://downloads.MySQL.com/archives/migration/
这是一个基于Java的程序,所以依赖于jar包,使用它的第一步就是load一个odbc.jar。接着就可以把源端和目标端进行配置连接,选择要导入的对象(可以包含视图,但是一般有子查询的会报错),进行导入就可以了。
使用它的优点就是可以在MySQL端自动创建表,但有可能自动convert的类型若有问题,需要人为参与一下进行处理,比如Oracle中通常会对Timestamp类型的数据设置默认值sysdate,但在MySQL中是不能识别的。
缺点就是只有windows的平台有,在导大数据量时,极有可能就hang住了。所以个人感觉它的适用场景就是一次性导入的小批量的数据。
5、KETTLE

上面提到的几种工具都是一步一个坑使用过之后发现并没有尽善尽美,总有这样或者那样的不足,接下来我们来推荐的就是终级必杀的好用的etl工具:KETTLE。
它是一款纯Java编写的软件,就像它的名字(水壶)一样,是用来把各种数据放到一个壶里,然后以一种指定的格式流出。当然你也可以使用DS(datastage)或者Informatica。不过这两个是收费的,而kettle是免费开源的。
这里只介绍它最简单的能满足我们把数据从Oracle迁移到MySQL的功能。
同理,第一步把jar包load进去,不同的是,这次要load的是MySQL的jar包。需要注意的是,如果你的MySQL版本不同可能需要load不同的jar包。第二步同也是配置连接信息,保证你的源和目标都连接成功,最后一步就是简单的拖拖拽拽。最后run一下就可以了。
它的优点就是配置起来比OGG快,但是同样可以通过job做到实时同步,处理速度和Python旗鼓相当,却不用自己来写mapping关系,并且提供了图形化界面。也能和Migration Toolkit一样同时创建表(新增一个Java脚本),进行类型转换,但日志更详细。只是可能学习成本高一点,要看的懂一些Java报错方便调试。
接下来我们简单看一个demo:
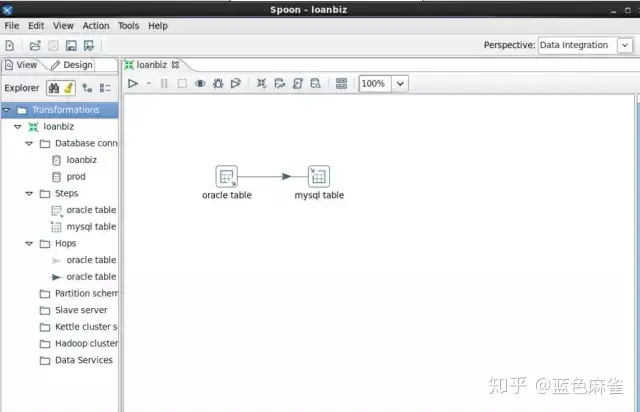
我们运行spoon.sh之后可以打开这个界面。view一界显示了这个转换的名字、数据源、处理步骤等,中间区域是你拖拽出来的操作,一个输入,一个输出。这就是一个简单的数据迁移的所有步骤。
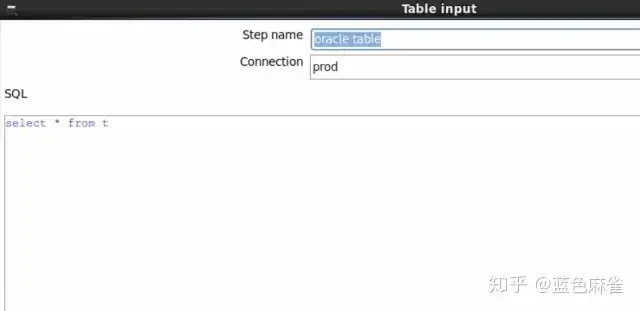
打开input的内容,就是很简单的一条SQL在哪个源数据库上抽取数据,当然这条SQL也可以是拖拽生成出来,类似于congos的拖拽生成报表。千万要注意的是,不要加分号!
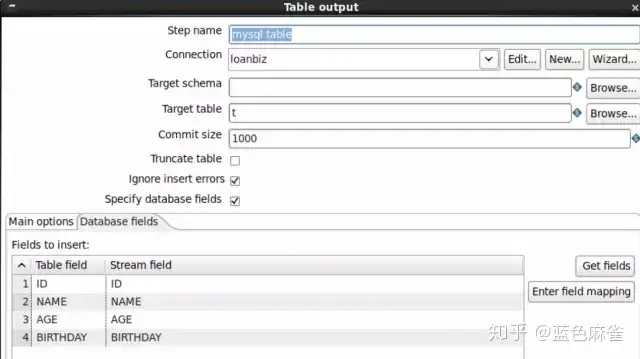
output的内容就显示丰富了很多,选择目标数据源,以及会自动的mapping列的信息,还有在迁移之间要不要先清空,迁移过程中如果遇到问题了会不会中止。
这里就是显示了它超越Migration tools的log最细粒度到行级别,可以更快地分析出问题。
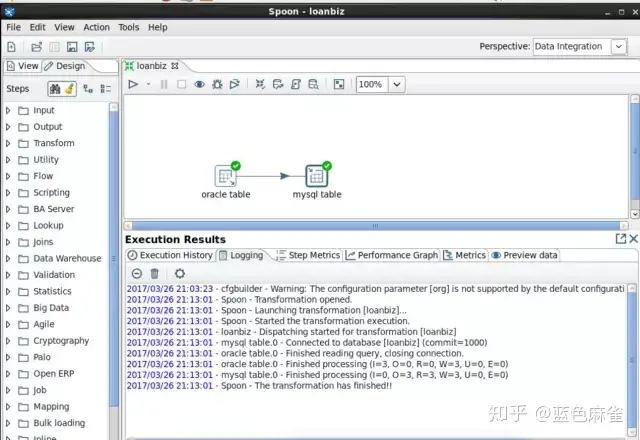
这里则是详细的日志输出。一般如果定时跑批处理的话,把它重定向到具体的log里,然后当做发送邮件。
四、其它对象的迁移

上面用了很长的篇幅介绍了一下几种迁移的工具,每种迁移的方式都是各有千秋,在合适的场景下选择适合自己的方法进行操作。不过刚刚迁移的都是表和数据对象。我们都知道在数据库还有一些其它的对象,像视图、物化视图、存储过程、函数、包,或者一个索引,同样的SQL是不是也需要改写,都是我们需要考虑到的一个因素。
接下来我们来看一下其它对象怎么迁移。
1、view
在MySQL里view是不可以嵌套子查询的:
create view v_test as select * from (select * from test) t;
ERROR 1349 (HY000): View's SELECT contains a subquery in the FROM clause
解决方法就是view的嵌套:
create view v_sub_test as select * from test;
Query OK, 0 rows affected (0.02 sec)
create view v_test as select * from v_sub_test;
Query OK, 0 rows affected (0.00 sec)
2、物化视图
物化视图用于预先计算并保存表连接或聚集等耗时较多的操作结果,这样在执行查询时,就可以避免进行这些耗时的操作,而从快速得到结果。但是MySQL里没有这个功能。通过事件调度和存储过程模拟物化视图,实现的难点在于更新物化视图,如果要求实时性高的更新,并且表太大的话,可能会有一些性能问题。
3、Trigger、存储过程、package

1)Oracle创建触发器时允许or,但是MySQL不允许。所以迁移时如果有需要写两个。
2)两种数据库定义变量的位置不同,而且MySQL里不支持%type。这个在Oracle中用得太频繁了,是个好习惯。
3)elseif的逻辑分支语法不同,并且MySQL里也没有for循环。
4)在MySQL中不可以返回cursor,并且声明时就要赋对象。
5)Oracle用包来把存储过程分门别类,而且在package里可以定义公共的变量/类型,既方便了编程,又减少了服务器的编译开销。可MySQL里根本没有这个概念。所以MySQL的函数也不可以重载。
6)预定义函数。MySQL里没有to_char() to_date()之类的函数,也并不是所有的Oracle都是好的,就像substring()和load_file()这样的函数,MySQL有,Oracle却没有。
7)MySQL里可以使用set和=号给变量赋值,但不可以使用:=。 而且在MySQL里没 || 来拼接字符串。
8)MySQL的注释必须要求-- 和内容之间有一个空格。
9)MySQL存储过程中只能使用leave退出当前存储过程,不可以使用return。
10)MySQL异常对象不同,MySQL同样的可以定义和处理异常,但对象名字不一样。

4、分页语句
MySQL中使用的是limit关键字,但在Oracle中使用的是rownum关键字。所以每有的和分页相关的语句都要进行调整。
5、JOIN
如果你的SQL里有大量的(+),这绝对是一个很头疼的问题。需要改写。
6、group by语句
Oracle里在查询字段出现的列一定要出现在group by后面,而MySQL里却不用。只是这样出来的结果可能并不是预期的结果。造成MySQL这种奇怪的特性的归因于sql_mode的设置,一会会详细说一下sql_mode。不过从Oracle迁移到MySQL的过程中,group by语句不会有跑不通的情况,反过来迁移可能就需要很长的时间来调整了。
7、bitmap位图索引
在Oracle里可以利用bitmap来实现布隆过滤,进行一些查询的优化,同时这一特性也为Oracle一些数据仓库相关的操作提供了很好的支持,但在MySQL里没有这种索引,所以以前在Oracle里利于bitmap进行优化的SQL可能在MySQL会有很大的性能问题。
目前也没有什么较好的解决方案,可以尝试着建btree的索引看是否能解决问题。要求MySQL提供bitmap索引在MySQL的bug库里被人当作一个中级的问题提交了上去,不过至今还是没有解决。
8、分区表(Partitioned table)
需要特殊处理,与Oracle的做法不同,MySQL会将分区键视作主键和唯一键的一部分。为确保不对应用逻辑和查询产生影响,必须用恰当的分区键重新定义目标架构。
9、角色
MySQL8.0以前也没有role的对象。在迁移过程中如果遇到的角色则是需要拼SQL来重新赋权。不过MySQL更好的一点是MySQL的用户与主机有关。
10、表情和特殊字符
在Oracle里我们一般都选择AL32UTF8的字符集,已经可以支付生僻字和emoji的表情了,因为在迁移的时候有的表包含了大量的表情字符,在MySQL里设置了为utf8却不行,导过去之后所有的都是问号,后来改成了utf8mb4才解决问题,所以推荐默认就把所有的DB都装成utf8mb4吧。
Oracle和MySQL差异远远不止这些,像闪回、AWR这些有很多,这里只谈一些和迁移工作相关的。
五、数据校验

当数据迁移完成后,如何确保数据的正确迁移、没有遗漏和错误是一个很难的问题。这里的难不是实现起来困难,而是要把它自动化,达到节省人力的目标有点难,因为两者的数据类型不同,数据量偏大,写一些脚本去做检查效果不大。
我们的数据校检工作主要分为在导入过程中的log和警告,在load的时候SHOW WARNINGS和errors,在使用Python、OGG、Kettle等工具时详细去看每个errors信息。
1、count(*)
迁移或增量操作完成以后,用最简单的count(*)去检查,在MySQL和Oracle上检查进行比对。如果数据量一致,再进行数据内容的验证。由于数据量太大,只进行了抽样检测。人工的手动检验如果没有问题了,可以使用应用程序对生产数据库的副本进行测试,在备库上进行应用程序的测试,从而进行再一次的验检。
2、etl工具
另外推荐的一种方式就是使用etl工具配置好MySQL和Oracle的数据源,分别对数据进行抽取,然后生成cube,进行多纬度的报表展现。数据是否有偏差,可以一目了然看清。
数据的完整性验证是十分重要的,千万不要怕验证到错误后要花好长时候去抽取同步的操作这一步。因为一旦没有验证到错误,让数据进行了使用却乱掉了,后果将更严重。
3、SQL_MODE

https://dev.MySQL.com/doc/refman/5.5/en/sql-mode.html
MySQL服务器能够工作在不同的SQL模式下,针对不同的客户端,以不同的方式应用这些模式。这样应用程序就能对服务器操作进行量身定制,以满足自己的需求。这类模式定义了MySQL应支持的SQL语法,以及应该在数据上执行何种确认检查。
TRADITIONAL
设置“严格模式”,限制可接受的数据库输入数据值(类似于其它数据库服务器),该模式的简单描述是当在列中插入不正确的值时“给出错误而不是警告”。
ONLY_FULL_GROUP_BY
在MySQL的sql_mode=default的情况下是非ONLY_FULL_GROUP_BY语义,也就是说一条select语句,MySQL允许target list中输出的表达式是除聚集函数、group by column以外的表达式,这个表达式的值可能在经过group by操作后变成undefined,无法确定(实际上MySQL的表现是分组内第一行对应列的值)
select list中的所有列的值都是明确语义。
简单来说,在ONLY_FULL_GROUP_BY模式下,target list中的值要么是来自于聚集函数的结果,要么是来自于group by list中的表达式的值。
Without Regard to any trailing spaces
All MySQL collations are of type PADSPACE. This means that all CHAR, VARCHAR, and TEXT values in MySQL are compared without regard to any trailing spaces. “Comparison” in this context does not include the LIKE pattern-matching operator, for which trailing spaces are significant.
MySQL校对规则属于PADSPACE,MySQL对CHAR和VARCHAR值进行比较都忽略尾部空格,和服务器配置以及MySQL版本都没关系。
- explicit_defauls_for_timestamp
MySQL中TIMESTAMP类型和其它的类型有点不一样(在没有设置explicit_defaults_for_timestamp=1的情况下),在默认情况下,如果TIMESTAMP列没有显式的指明null属性,那么该列会被自动加上not null属性(而其他类型的列如果没有被显式的指定not null,那么是允许null值的),如果往这个列中插入null值,会自动设置该列的值为current timestamp值,表中的第一个TIMESTAMP列,如果没有指定null属性或者没有指定默认值,也没有指定ON UPDATE语句,那么该列会自动被加上DEFAULT 。
CURRENT_TIMESTAMP和ON UPDATE CURRENT_TIMESTAMP属性。第一个TIMESTAMP列之后的其它的TIMESTAMP类型的列,如果没有指定null属性,也没有指定默认值,那该列会被自动加上DEFAULT '0000-00-00 00:00:00'属性。如果insert语句中没有为该列指定值,那么该列中插入'0000-00-00 00:00:00',并且没有warning。
如果我们启动时在配置文件中指定了explicit_defaults_for_timestamp=1,MySQL会按照如下的方式处理TIMESTAMP列。
此时如果TIMESTAMP列没有显式的指定not null属性,那么默认的该列可以为null,此时向该列中插入null值时,会直接记录null,而不是current timestamp。并且不会自动的为表中的第一个TIMESTAMP列加上DEFAULT CURRENT_TIMESTAMP 和ON UPDATE CURRENT_TIMESTAMP属性,除非你在建表时显式的指明。
六、一些性能参数

我们可以在导入数据的时候预先的修改一些参数,来获取最大性能的处理,比如可以把自适应hash关掉,Doublewrite关掉,然后调整缓存区,log文件的大小,把能变大的都变大,把能关的都关掉来获取最大的性能,我们接下来说几个常用的:
- innodb_flush_log_at_trx_commit
如果innodb_flush_log_at_trx_commit设置为0,log buffer将每秒一次地写入log file中,并且log file的flush(刷到磁盘)操作同时进行。该模式下,在事务提交时,不会主动触发写入磁盘的操作。
如果innodb_flush_log_at_trx_commit设置为1,每次事务提交时MySQL都会把log buffer的数据写入log file,并且flush(刷到磁盘)中去。
如果innodb_flush_log_at_trx_commit设置为2,每次事务提交时MySQL都会把log buffer的数据写入log file。但是flush(刷到磁盘)的操作并不会同时进行。该模式下,MySQL会每秒执行一次 flush(刷到磁盘)操作。
注意:由于进程调度策略问题,这个“每秒执行一次 flush(刷到磁盘)操作”并不是保证100%的“每秒”。
- sync_binlog
sync_binlog 的默认值是0,像操作系统刷其它文件的机制一样,MySQL不会同步到磁盘中去,而是依赖操作系统来刷新binary log。
当sync_binlog =N (N>0) ,MySQL 在每写N次 二进制日志binary log时,会使用fdatasync()函数将它的写二进制日志binary log同步到磁盘中去。
注:如果启用了autocommit,那么每一个语句statement就会有一次写操作;否则每个事务对应一个写操作。
- max_allowed_packet
在导大容量数据特别是CLOB数据时,可能会出现异常:“Packets larger than max_allowed_packet are not allowed”。这是由于MySQL数据库有一个系统参数max_allowed_packet,其默认值为1048576(1M),可以通过如下语句在数据库中查询其值:show VARIABLES like '%max_allowed_packet%';
修改此参数的方法是在MySQL文件夹找到my.cnf文件,在my.cnf文件[MySQLd]中添加一行:max_allowed_packet=16777216
- innodb_log_file_size
InnoDB日志文件太大,会影响MySQL崩溃恢复的时间,太小会增加IO负担,所以我们要调整合适的日志大小。在数据导入时先把这个值调大一点。避免无谓的buffer pool的flush操作。但也不能把 innodb_log_file_size开得太大,会明显增加 InnoDB的log写入操作,而且会造成操作系统需要更多的Disk Cache开销。
- innodb_log_buffer_size
InnoDB用于将日志文件写入磁盘时的缓冲区大小字节数。为了实现较高写入吞吐率,可增大该参数的默认值。一个大的log buffer让一个大的事务运行,不需要在事务提交前写日志到磁盘,因此,如果你有事务比如update、insert或者delete 很多的记录,让log buffer 足够大来节约磁盘I/O。
- innodb_buffer_pool_size
这个参数主要缓存InnoDB表的索引、数据、插入数据时的缓冲。为InnoDN加速优化首要参数。一般让它等于你所有的innodb_log_buffer_size的大小就可以,
innodb_log_file_size要越大越好。
- innodb_buffer_pool_instances
InnoDB缓冲池拆分成的区域数量。对于数GB规模缓冲池的系统,通过减少不同线程读写缓冲页面的争用,将缓冲池拆分为不同实例有助于改善并发性。
总结

- 一定要选择合适你的迁移工具,没有哪一个工具是最好的。
- 数据的检验非常重要,有的时候我们迁过去很开心,校验时发生错误,这个时候必须要重来。
- 重复地迁移是很正常的,合乎每次迁移可能需要很长时间,总会是有错误的,要做好再迁的心态。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号