jdbc元数据DataBaseMetaData查询数据库表信息详解
一 . 得到这个对象的实例
Connection con ;
con = DriverManager.getConnection(url,userName,password);
DatabaseMetaData dbmd = con.getMetaData();
二. 方法getTables的用法
原型:
ResultSet DatabaseMetaData.getTables(String catalog,String schema,String tableName,String []type)
此方法可返回结果集合ResultSet ,结果集中有5列, 超出会报越界异常
功能描述:得到指定参数的表信息
参数说明:
参数:catalog:目录名称,一般都为空.
参数:schema:数据库名,对于oracle来说就用户名
参数:tablename:表名称
参数:type :表的类型(TABLE | VIEW)
注意:在使用过程中,参数名称必须使用大写的。否则得到什么东西。
检索给定目录中可用表的描述。仅返回与目录、模式、表名称和类型条件匹配的表描述。它们按 TABLE_TYPE、TABLE_CAT、TABLE_SCHEM 和 TABLE_NAME 排序。
/**
* 检索给定目录中可用表的描述。
* 只有与目录、模式、表匹配的表描述
* 返回名称和类型标准。他们被订购
* <code>TABLE_TYPE</code>, <code>TABLE_CAT</code>,
* <code>TABLE_SCHEM</code> 和 <code>TABLE_NAME</code>。
* <P>
* 每个表描述都有以下列:
* <OL>
* <LI><B>TABLE_CAT</B> String {@code =>} 表目录(可能是<code>null</code>)
* <LI><B>TABLE_SCHEM</B> 字符串 {@code =>} 表模式(可能是 <code>null</code>)
* <LI><B>TABLE_NAME</B> 字符串 {@code =>} 表名
* <LI><B>TABLE_TYPE</B> 字符串 {@code =>} 表类型。典型的类型是“TABLE”,
*“视图”、“系统表”、“全局临时”、
*“本地临时”、“别名”、“同义词”。
* <LI><B>REMARKS</B> String {@code =>} 对表格的解释性注释
* <LI><B>TYPE_CAT</B> String {@code =>} 类型目录(可能是<code>null</code>)
* <LI><B>TYPE_SCHEM</B> String {@code =>} 类型模式(可能是 <code>null</code>)
* <LI><B>TYPE_NAME</B> String {@code =>} 类型名称(可能是<code>null</code>)
* <LI><B>SELF_REFERENCING_COL_NAME</B> String {@code =>} 指定名称
* 类型表的“标识符”列(可能是 <code>null</code>)
* <LI><B>REF_GENERATION</B> String {@code =>} 指定值如何在
* 创建 SELF_REFERENCING_COL_NAME。值为
*“系统”、“用户”、“派生”。 (可能是 <code>null</code>)
* </OL>
*
* <P><B>注意:</B>有些数据库可能不会返回信息
* 所有表格。
*
* @param catalog 一个目录名;必须与目录名称匹配
* 存储在数据库中; "" 检索那些没有目录的;
* <code>null</code> 表示不应该使用目录名称来缩小搜索
* @param schemaPattern 模式名称模式;必须与架构名称匹配
* 因为它存储在数据库中; "" 检索那些没有模式的;
* <code>null</code> 表示不应该使用模式名称来缩小范围搜索
* @param tableNamePattern 一个表名模式;必须匹配存储在数据库中的表名
* @param types 表类型列表,必须来自表类型列表
* 从 {@link #getTableTypes} 返回,包括; <code>null</code> 返回所有类型
* @return <code>ResultSet</code> - 每行是一个表描述
* @exception SQLException 如果发生数据库访问错误
* @see #getSearchStringEscape
*/
参数:
String catalog: mysql下就是数据库名称,oracle下就是instance名;可以为null,可以为“”。解释参见@param catalog
String schemaPattern:mysql下就是数据库名称,oracle中就是用户名.解释参见@param schemaPattern
String tableNamePattern: 数据表名称
String[] types: 查询的表类型,参考注解中的解释
三. 方法getColumns的用法
功能描述:得到指定表的列信息。
原型:
ResultSet DatabaseMetaData getColumns(String catalog,String schema,String tableName,String columnName)
参数说明:
参数catalog : 类别名称
参数schema : 用户方案名称
参数tableName : 数据库表名称
参数columnName : 列名称
/**
* 检索可用的表列的描述
* 指定目录。
*
* <P>只有与目录、模式、表匹配的列描述
* 和列名条件被返回。他们被订购
* <code>TABLE_CAT</code>,<code>TABLE_SCHEM</code>,
* <code>TABLE_NAME</code> 和 <code>ORDINAL_POSITION</code>。
*
* <P>每列描述都有以下列:
* <OL>
* <LI><B>TABLE_CAT</B> String {@code =>} 表目录(可能是<code>null</code>)
* <LI><B>TABLE_SCHEM</B> 字符串 {@code =>} 表模式(可能是 <code>null</code>)
* <LI><B>TABLE_NAME</B> 字符串 {@code =>} 表名
* <LI><B>COLUMN_NAME</B> 字符串 {@code =>} 列名
* <LI><B>DATA_TYPE</B> int {@code =>} 来自 java.sql.Types 的 SQL 类型
* <LI><B>TYPE_NAME</B> String {@code =>} 数据源依赖类型名称,
* 对于 UDT,类型名称是完全限定的
* <LI><B>COLUMN_SIZE</B> int {@code =>} 列大小。
* <LI><B>BUFFER_LENGTH</B> 未使用。
* <LI><B>DECIMAL_DIGITS</B> int {@code =>} 小数位数。对于其中的数据类型返回 Null
* DECIMAL_DIGITS 不适用。
* <LI><B>NUM_PREC_RADIX</B> int {@code =>} 基数(通常为 10 或 2)
* <LI><B>NULLABLE</B> int {@code =>} 允许为 NULL。
* <UL>
* <LI> columnNoNulls - 可能不允许 <code>NULL</code> 值
* <LI> columnNullable - 绝对允许 <code>NULL</code> 值
* <LI> columnNullableUnknown - 可空性未知
* </UL>
* <LI><B>REMARKS</B> String {@code =>} 注释描述列(可能是<code>null</code>)
* <LI><B>COLUMN_DEF</B> String {@code =>} 列的默认值,当值用单引号括起来时应解释为字符串(可能为<code>null</code >)
* <LI><B>SQL_DATA_TYPE</B> int {@code =>} 未使用
* <LI><B>SQL_DATETIME_SUB</B> int {@code =>} 未使用
* <LI><B>CHAR_OCTET_LENGTH</B> int {@code =>} 用于 char 类型
* 列中的最大字节数
* <LI><B>ORDINAL_POSITION</B> int {@code =>} 表中列的索引
*(从 1 开始)
* <LI><B>IS_NULLABLE</B> String {@code =>} ISO 规则用于确定列的可空性。
* <UL>
* <LI> YES --- 如果列可以包含 NULL
* <LI> NO --- 如果列不能包含 NULL
* <LI> 空字符串 --- 如果
* 列未知
* </UL>
* <LI><B>SCOPE_CATALOG</B> String {@code =>} 范围表的目录
* 引用属性(如果 DATA_TYPE 不是 REF,则为 <code>null</code>)
* <LI><B>SCOPE_SCHEMA</B> String {@code =>} 范围表的模式
* 引用属性(如果 DATA_TYPE 不是 REF,则为 <code>null</code>)
* <LI><B>SCOPE_TABLE</B> String {@code =>} 这个范围的表名
* 引用属性(如果 DATA_TYPE 不是 REF,则为 <code>null</code>)
* <LI><B>SOURCE_DATA_TYPE</B> 短 {@code =>} 不同类型或用户生成的源类型
* Ref 类型,来自 java.sql.Types 的 SQL 类型(<code>null</code> if DATA_TYPE
* 不是 DISTINCT 或用户生成的 REF)
* <LI><B>IS_AUTOINCREMENT</B> String {@code =>} 表示该列是否自动递增
* <UL>
* <LI> YES --- 如果列是自动递增的
* <LI> NO --- 如果列不是自动递增的
* <LI> 空字符串 --- 如果无法确定列是否自动递增
* </UL>
* <LI><B>IS_GENERATEDCOLUMN</B> String {@code =>} 表示这是否是生成列
* <UL>
* <LI> YES --- 如果这是一个生成的列
* <LI> NO --- 如果这不是生成的列
* <LI> 空字符串 --- 如果无法确定这是否是生成的列
* </UL>
* </OL>
*
* <p>COLUMN_SIZE 列指定给定列的列大小。
* 对于数值数据,这是最大精度。对于字符数据,这是字符长度。
* 对于日期时间数据类型,这是字符串表示的字符长度(假设
* 小数秒组件的最大允许精度)。对于二进制数据,这是以字节为单位的长度。对于 ROWID 数据类型,
* 这是以字节为单位的长度。对于其中的数据类型返回 Null
* 列大小不适用。
* @param catalog 一个目录名; 必须与目录名称匹配
* 存储在数据库中; "" 检索那些没有目录的;
* <code>null</code> 表示不应该使用目录名称来缩小搜索
* @param schemaPattern 模式名称模式;
* 必须与架构名称匹配因为它存储在数据库中;
* "" 检索那些没有模式的;
* <code>null</code> 表示不应该使用模式名称来缩小范围搜索
* @param tableNamePattern 一个表名模式; 必须匹配
* 存储在数据库中的表名
* @param columnNamePattern 列名模式; 必须与列匹配
* 名称,因为它存储在数据库中
* @return <code>ResultSet</code> - 每行是一个列描述
* @exception SQLException 如果发生数据库访问错误
* @see #getSearchStringEscape
*/
参数
String catalog: mysql下就是数据库名称,oracle下就是instance名;可以为null,可以为“”。解释参见@param catalog
String schemaPattern:mysql下就是数据库名称,oracle中就是用户名.解释参见@param schemaPattern
String tableNamePattern: 数据表名称
String columnNamePattern: 列名模式,参考注解中的解释
四、方法getPrimaryKeys的用法
功能描述:得到指定表的主键信息。
原型:
ResultSet DatabaseMetaData getPrimaryKeys(String catalog,String schema,String tableName)
参数说明:
参数catalog : 类别名称
参数schema : 用户方案名称
参数tableName : 数据库表名称
备注:一定要指定表名称,否则返回值将是什么都没有。
五、方法.getTypeInfo()的用法
功能描述:得到当前数据库的数据类型信息。
六、方法getExportedKeys的用法
功能描述:得到指定表的外键信息。
参数描述:
参数catalog : 类别名称
参数schema : 用户方案名称
参数tableName : 数据库表名称
DatabaseMetaData对象提供的是关于数据库的各种信息,这些信息包括:
1、数据库与用户,数据库标识符以及函数与存储过程。
2、数据库限制。
3、数据库支持不支持的功能。
4、架构、编目、表、列和视图等。
通过调用DatabaseMetaData的各种方法,程序可以动态的了解一个数据库。由于这个类中的方法非常的多那么就介绍几个常用的方法来给大家参考。
DatabaseMetaData实例的获取方法是,通过连接来获得的
Connection conn = //创建的连接。
DatabaseMetaData dbmd = Conn.getMetaData();
创建了这个实例,就可以使用他的方法来获取数据库得信息。首先是数据库中用户标识符的信息的获得,主要使用如下的方法:
getDatabaseProductName()用以获得当前数据库是什么数据库。比如oracle,access等。返回的是字符串。
getDatabaseProductVersion()获得数据库的版本。返回的字符串。
getDriverVersion()获得驱动程序的版本。返回字符串。
supportsResultSetType(ResultSet.resultype)是判定是否支持这种结果集的类型。比如参数如果是Result.TYPE_FORWARD_ONLY,那就是判定是否支持,只能先前移动结果集的指针。返回值为boolean,true表示支持。
上面介绍的只是几个常用的方法,这个类中还有很多方法,可以到jdk的帮助文档中去查看类java.sql.DatabaseMetaData。
这个类中还有一个比较常用的方法就是获得表的信息。使用的方法是:
getTables(String catalog,String schema,String tableName,String[] types),
这个方法带有四个参数,他们表示的含义如下:
String catalog——要获得表所在的编目。串“”””意味着没有任何编目,Null表示所有编目。
String schema——要获得表所在的模式。串“”””意味着没有任何模式,Null表示所有模式。该参数可以包含单字符的通配符(“_”),也可以包含多字符的通配符(“%”)。
String tableName——指出要返回表名与该参数匹配的那些表,该参数可以包含单字符的通配符(“_”),也可以包含多字符的通配符(“%”)。
String types——一个指出返回何种表的数组。可能的数组项是:”TABLE”,”VIEW”,”SYSTEM TABLE”,”GLOBAL TEMPORARY”,”LOCAL TEMPORARY”,”ALIAS”,“SYSNONYM”。
通过getTables()方法返回一个表的信息的结果集。这个结果集包括字段有:TABLE_CAT表所在的编目。TABLE_SCHEM表所在的模式,TABLE_NAME表的名称。TABLE_TYPE标的类型。REMARKS一段解释性的备注。通过这些字段可以完成表的信息的获取。
还有两个方法一个是获得列getColumns(String catalog,String schama,String tablename,String columnPattern)一个是获得关键字的方法getPrimaryKeys(String?catalog, String?schema, String?table)这两个方法中的参数的含义和上面的介绍的是相同的。凡是pattern的都是可以用通配符匹配的。getColums()返回的是结果集,这个结果集包括了列的所有信息,类型,名称,可否为空等。getPrimaryKey()则是返回了某个表的关键字的结果集。
通过getTables(),getColumns(),getPrimaryKeys()就可以完成表的反向设计了。主要步骤如下:
1、通过getTables()获得数据库中表的信息。
2、对于每个表使用,getColumns(),getPrimaryKeys()获得相应的列名,类型,限制条件,关键字等。
3、通过1,2获得信息可以生成相应的建表的SQL语句。
通过上述三步完成反向设计表的过程。
1 获取DataBaseMetadata对象
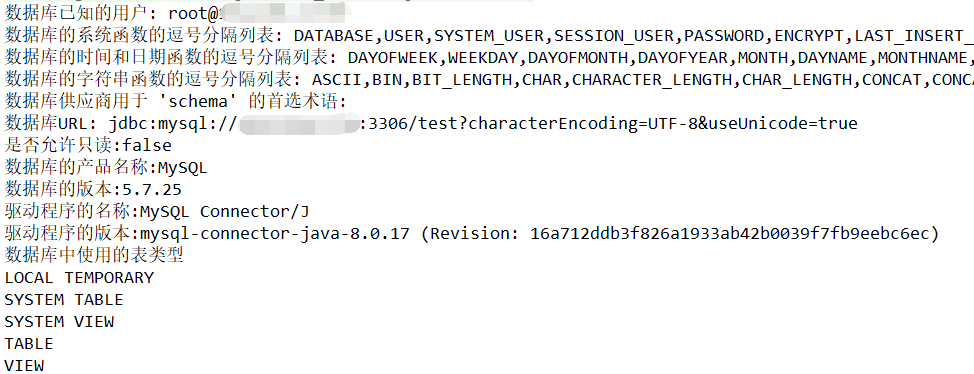
我们需用使用Connection对象的getMetaData方法来获取DataBaseMeta对象,如下示例代码,我们演示获取DataBaseMetadata对象,并从DataBaseMetadata对象中获取数据库信息。
程序执行我们可以在控制台看到如下所示的输出
2 getTables
原型:ResultSet DatabaseMetaData.getTables(String catalog,String schemaPattern,String tableNamePattern,String[] types)
功能描述:得到指定参数的表信息
参数说明:
参数catalog: 目录名称,一般都为空,在MySQL中代表数据库名称
参数schemaPattern: 数据库名称模式匹配,null表示不缩小搜索范围数据库名,对于oracle来说就用户名
参数tableNamePattern: 表名称模式匹配字符,
参数types: 表类型列表,包含值(TABLE | VIEW),null返回所有类型
来看下面的演示示例:
演示结果如下图所示

3 getColumns
功能描述:得到指定表的列信息。
原型:ResultSet DatabaseMetaData getColumns(String catalog,String schemaPattern,String tableNamePattern,String columnNamePattern)
参数说明:
参数catalog: 目录名称,一般都为空,在MySQL中代表数据库名称
参数schemaPattern: 数据库名称模式匹配,null表示不缩小搜索范围数据库名,对于oracle来说就用户名
参数tableNamePattern: 表名称模式匹配字符
参数columnNamePattern: 列名模式匹配字符
下面来看一个演示示例