Streamsets读取binlog数据实时同步到MySQL
原文:https://blog.csdn.net/maomaosi2009/article/details/108293217
1、说明
实时同步binlog数据到MySQL我使用了2种方式,
2、方式一
第一种方式较为繁琐,数据从binlog流出,经过JS数据解析器将必要的字段解析出来,流入操作选择器,根据具体需要执行的增删改操作选择最后的JDBC Producer,pipeline如下:
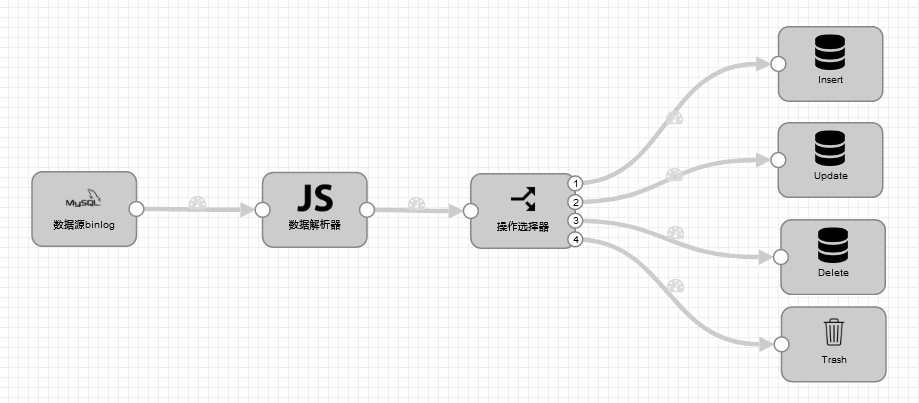
binlog数据到JS数据解析器之前是这样
{
"BinLogFilename": "mysql-bin.000001",
"Type": "INSERT",
"Table": "test",
"ServerId": 1,
"BinLogPosition": 3795464,
"Database": "test",
"Data": {
"address": "安徽蚌埠",
"name": "张张",
"update_at": 1585817413000,
"weight": 134.0,
"id": 14,
"create_at": 1585817413000,
"height": 177.0
},
"Timestamp": 1585788613000,
"Offset": "mysql-bin.000001:3795464"
} {
"BinLogFilename": "mysql-bin.000001",
"Type": "UPDATE",
"Table": "test",
"ServerId": 1,
"BinLogPosition": 3795837,
"Database": "test",
"OldData": {
"address": "美国",
"name": "守望",
"update_at": 1585763177000,
"weight": 166.0,
"id": 13,
"create_at": 1585763177000,
"height": 180.0
},
"Data": {
"address": "美国暴雪",
"name": "守望",
"update_at": 1585817417000,
"weight": 166.0,
"id": 13,
"create_at": 1585763177000,
"height": 180.0
},
"Timestamp": 1585788617000,
"Offset": "mysql-bin.000001:3795837"
}
binlog数据出JS数据解析器之后是这样的,Table、Database、Type、Offset这样的字段被解析到了record的attributes属性中,被留下的只有真实的数据,如果是INSERT或者UPDATE则取Data中的值,如果是DELETE则取OldData中的值
{
"address": "安徽蚌埠",
"name": "张张",
"update_at": 1585817413000,
"weight": 134.0,
"id": 14,
"create_at": 1585817413000,
"height": 177.0
}
{
"address": "美国",
"name": "守望",
"update_at": 1585763177000,
"weight": 166.0,
"id": 13,
"create_at": 1585763177000,
"height": 180.0
}
数据经过JS数据解析器解析之后流入操作选择器,根据record:attribute('Type')的具体值来执行具体的增删改操作,做到数据同步
但是这种方式较为繁琐,尤其是当数据想入到多个database的时候需要在操作选择器前面再加一个数据库选择器,根据不同的数据库流入不同的操作选择器,因为JDBC Producer中是没法动态声明数据库的,只能动态声明数据表。在请教同事之后他告诉我另一种简单的数据同步方式,见方式二。
3、方式二
方式二非常简单,数据从binlog流出,经过中间的Field Renamer进行字段名转换,然后直接就可以提供给JDBC Producer进行数据入库,不再需要人为判断操作类型,pipeline如下:
看一下Field Renamer1具体配置,General是基础配置
Rename配置栏才是我们需要配置的,INSERT操作只有Data节点,UPDATE节点Data和OldData节点都有,DELETE操作只有OldData节点。注意需要同时配置/OldData/(.*)和/Data/(.*),并且上下顺序不能错误
在最一开始的通过binlog数据同步到MySQL的时候我是希望只有2个stage,一个MySQL Binary Log产生数据,一个JDBC Producer输出数据到目的端,主要原因就是因为真正的MySQL数据字段是在record的Data节点里面,在JDBC Producer中我不想通过Field to Column Mapping将Data节点里面的属性一个个映射到目的端MySQL字段
{
"BinLogFilename": "mysql-bin.000001",
"Type": "INSERT",
"Table": "test",
"ServerId": 1,
"BinLogPosition": 3795464,
"Database": "test",
"Data": {
"address": "安徽蚌埠",
"name": "张张",
"update_at": 1585817413000,
"weight": 134.0,
"id": 14,
"create_at": 1585817413000,
"height": 177.0
},
"Timestamp": 1585788613000,
"Offset": "mysql-bin.000001:3795464"
}
如果将Data节点里面的属性都提取到根节点下,形似下面这种格式
{
"address": "安徽蚌埠",
"name": "张张",
"update_at": 1585817413000,
"weight": 134.0,
"id": 14,
"create_at": 1585817413000,
"height": 177.0
}
那这个record流入JDBC Producer的时候因为这些属性字段和MySQL中是一一对应的,因为不再需要我们手动配置Field to Column Mapping就可以自动适配上,这也是我在方式一中需要使用JavaScript数据解析器的原因。但是在这里我们使用了Field Renamer将Data节点和OldData节点下面的所有属性都提取到了根节点下,变成了这样
{
"Table": "test",
"address": "上海",
"OldData": {},
"weight": 110.0,
"Data": {},
"Timestamp": 1585873767000,
"Offset": "mysql-bin.000001:9166277",
"BinLogFilename": "mysql-bin.000001",
"Type": "UPDATE",
"ServerId": 1,
"BinLogPosition": 9166277,
"Database": "test",
"name": "囡囡",
"update_at": 1585873767000,
"id": 27,
"create_at": 1585820937000,
"height": 174.0
}
这样的话根节点里面的字段就可以和目的端的数据库字段对应上了,但是这样有个问题,JDBC Producer怎么知道该执行UPDATE还是INSERT、DELETE操作呢?我们看一下MySQL Binary Log的输出,除了必要的数据值外还有Record Header,里面包含了sdc.operation.type,这个就对应了具体数据库的增删改操作,这个sdc.operation.type我们只需要一直往后传递下去即可
在JDBC Producer中有个Default Operation,以前我们都是配置这里来执行具体的增删改操作,但是实际上这个操作是在record header中没有设置sdc.operation.type时才会执行的操作,也就是说如果我们的record header自带了sdc.operation.type值的话就会直接根据已有的来执行
配置好这个pipeline后运行测试了一下,发现数据可以正确的进行同步过来了。我们接着测试一下数据结构发生改变的情况
3.1、源端schema改变
我们在源表添加一个新的字段gender,观察pipeline运行情况,发现pipeline不报错,正常运行
我们现在插入一条新的数据,并且给gender一个值,注意这时候目标端还没有这个gender字段,发现整个pipeline运行正常,目标端新增的数据同步过来了,只是没有gender字段而且,其他已经有的字段值都被正确同步到了目标端。
我们修改源端一条数据记录的gender值,pipeline的dashboard上可以看到有一条数据input了,并且正确的output了,但是因为目标端这边还没有gender这个字段,所以实际上目标端这边数据并没有变化。我们修改源端一条数据记录的address值,这个字段在目标端这边是有的,发现数据被正确的同步更新了。
我们修改目标端schema,也增加一个gender字段,让两边的schema保持一致,测试修改源端记录中的gender值,发现pipeline虽然可以正常运行,但是目标端的gender值没有被同步过来,而修改其他字段值就可以正常同步。这时候往源端插入数据的时候即使两边schema已经一致了,gender值依旧无法同步过来。因为同时把File Renamer的输出数据也落地到本地了一份,所以可以看到File Renamer输出的数据中实际上是有gender值的,猜测是不是因为这个pipeline在启动的时候就把目标端的schema进行了缓存
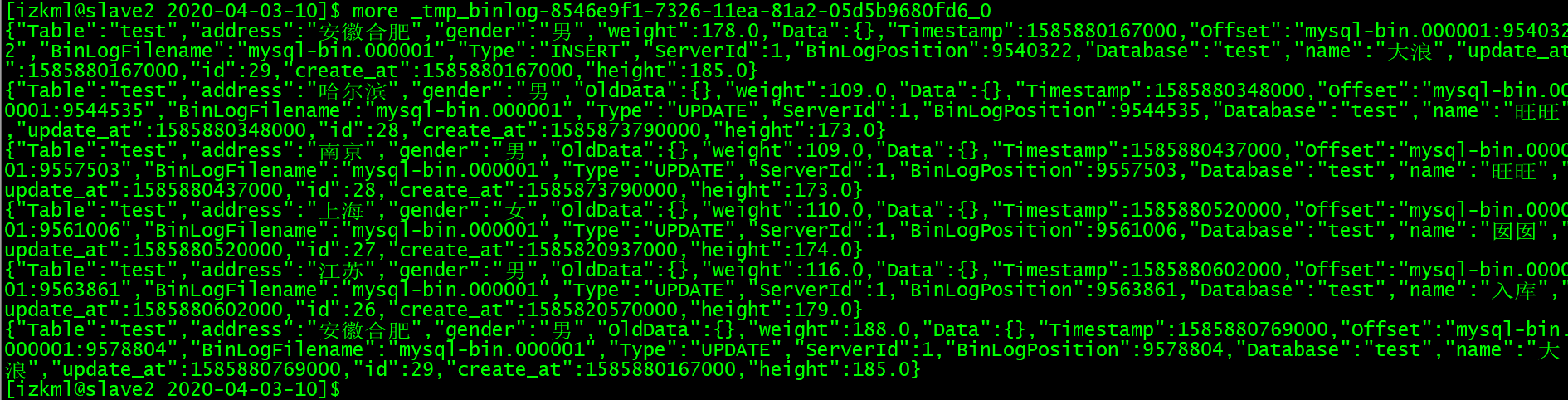
重启一下该pipeline,并重置offset为修改schema之前的值,发现所有update操作都同步过来了,目标端的gender值被正确更新,但是insert操作无法同步,因为主键重复而报错了。这时在源库插入数据的时候发现可以正确同步到目标端了。
针对删除字段而言的话如果源端先删除,目标端后删除,则pipeline同步数据没问题。
3.2、目标端schema改变
pipeline运行过程中在目标端添加一个字段department,pipeline运行无异常。往源端插入数据,修改数据,删除数据,都可以正确的同步。
修改源端schema,同样增加一个字段department,两边schema保持一直,pipeline运行无异常。但是新增的字段值无法同步。
针对删除字段而言的话如果目标端先删除,源端后删除,则pipeline可以继续运行,但是会出现error记录,因为源端字段在目标端找不到,即使不给这个字段赋值也会报错。
————————————————
版权声明:本文为CSDN博主「芦苇_」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/maomaosi2009/article/details/108293217

 浙公网安备 33010602011771号
浙公网安备 33010602011771号