solr8.6添加中文分词器
1.添加solr8 自带分词工具
(1)在solr安装文件夹下面找到这个lucene-analyzers-smartcn-8.6.0.jar包

(2)复制一份到 D:\solr-8.6.0\server\solr-webapp\webapp\WEB-INF\lib 这个目录下面

(3)接下来在你的项目conf下的配置文件managed-schema添加以下配置
<!-- ChineseAnalyzer 自带的中文分词器 --> <fieldType name="solr_cnAnalyzer" class="solr.TextField" positionIncrementGap="100"> <analyzer type="index"> <tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/> </analyzer> <analyzer type="query"> <tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/> </analyzer> </fieldType>
这样就配置好了类型名称是 solr_cnAnalyzer 的分词器。
2.外部分词器配置
(1)先下载solr8版本的ik分词器,下载地址:https://search.maven.org/search?q=com.github.magese
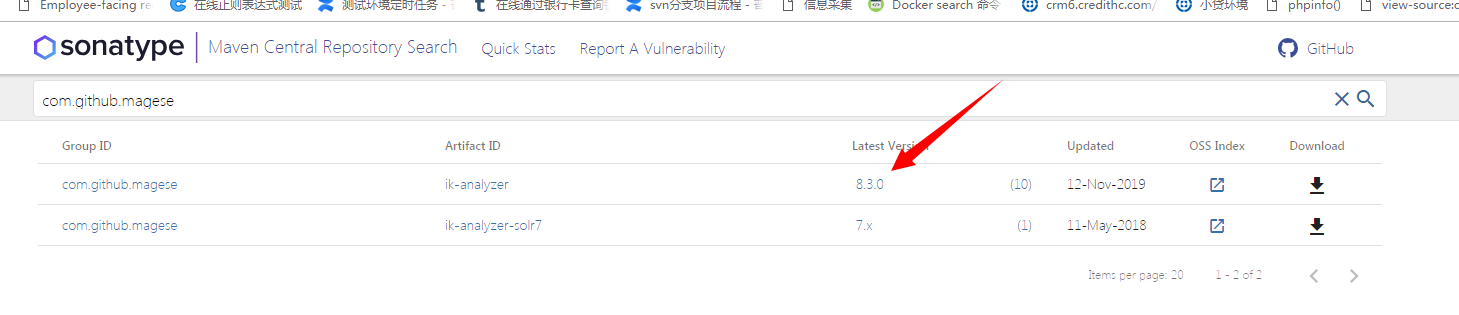
(2)将下载好的jar包放入solr-7.3.0/server/solr-webapp/webapp/WEB-INF/lib目录中
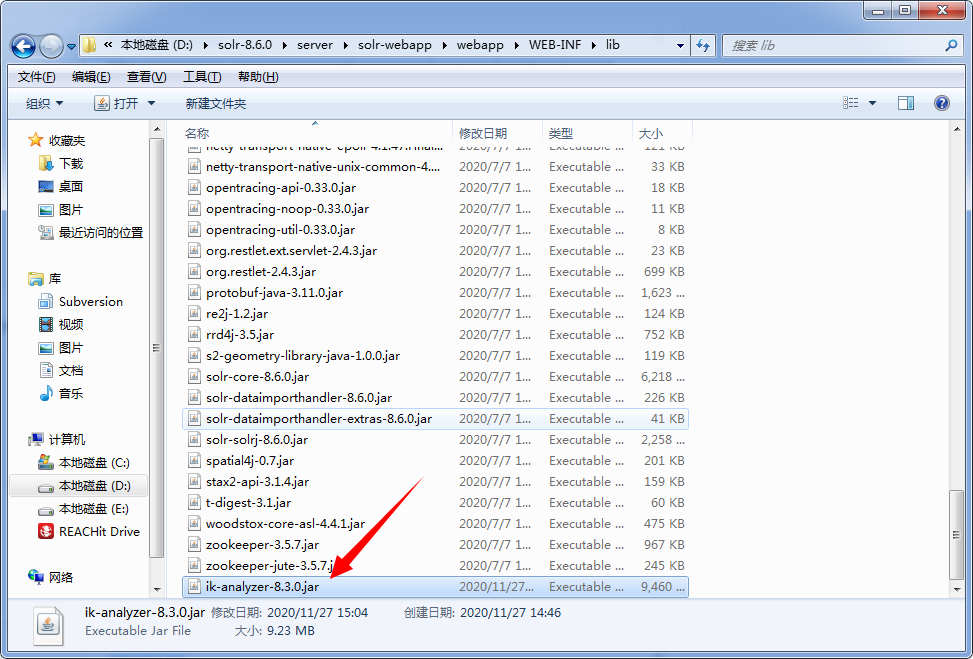
(3)接下来在你的项目conf下的配置文件managed-schema添加以下配置
<!-- ik分词器 --> <fieldType name="text_ik" class="solr.TextField"> <analyzer type="index"> <tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" conf="ik.conf"/> <filter class="solr.LowerCaseFilterFactory"/> </analyzer> <analyzer type="query"> <tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="true" conf="ik.conf"/> <filter class="solr.LowerCaseFilterFactory"/> </analyzer> </fieldType>
3.给需要做分词的的字段指定分词器
我给 name 字段指定了 solr_cnAnalyzer 分词器、content字段指定了 text_ik 分词器,其中 type 就是上面分词器的name值。
注意:indexed="true",solr默认下content这个字段的indexed的值是false,需要改成true,在搜索时这个字段才能用到上面的分词器。
<field name="name" type="solr_cnAnalyzer" indexed="true" stored="true"/>
<field name="content" type="text_ik" multiValued="true" indexed="true" stored="true"/>
4.配置完成后重启一次solr服务

再次刷新http://localhost:8983/solr页面
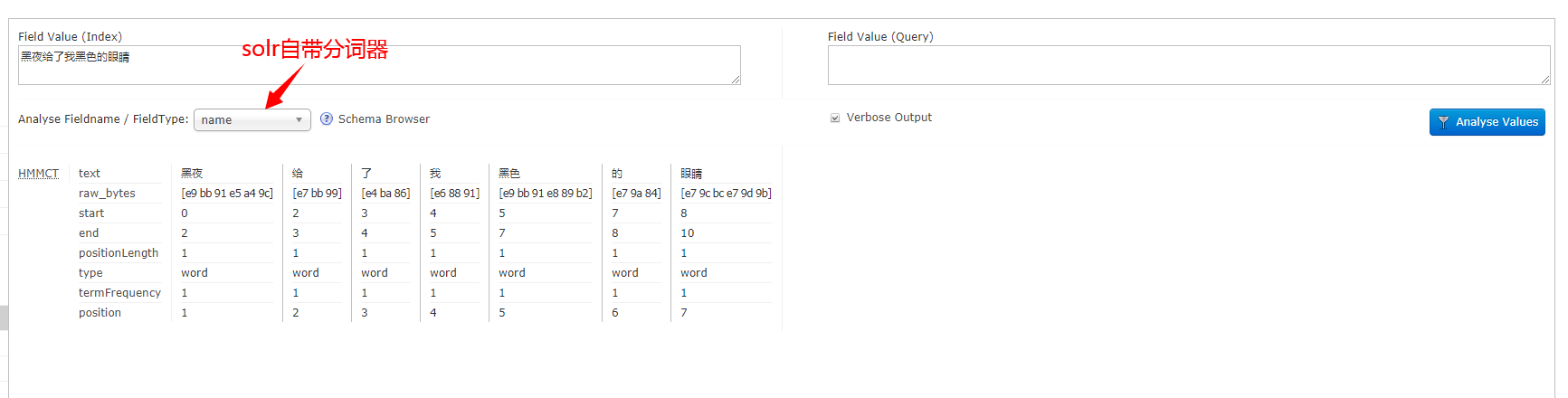
(1)选择test-> Analysis -> 选择分词器 content 输入 "黑夜给了我黑色的眼睛",点击"Analyse Values"按钮可以看到结果已经分词成功了。

(2)选择test-> Analysis -> 选择分词器 name 输入 "黑夜给了我黑色的眼睛",点击"Analyse Values"按钮可以看到结果已经分词成功了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号