Prometheus监控
流程:
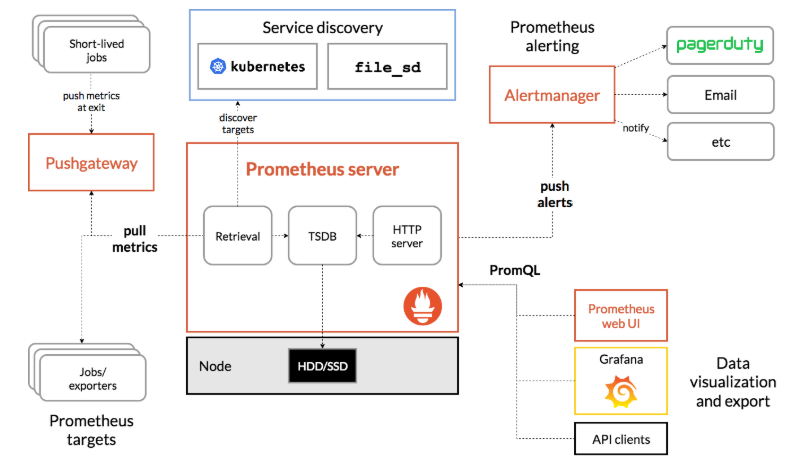
prometheus根据配置定时去拉取各个节点的数据,默认使用的拉取方式是pull,也可以使用pushgateway提供的push方式获取各个监控节点的数据。将获取到的数据存入TSDB,一款时序型数据库。此时prometheus已经获取到了监控数据,可以使用内置的PromQL进行查询。它的报警功能使用Alertmanager提供,Alertmanager是prometheus的告警管理和发送报警的一个组件。prometheus原生的图标功能过于简单,可将prometheus数据接入grafana,由grafana进行统一管理。
特点:
多维数据模型,时间序列由metric名字和K/V标签标识
灵活的查询语言(PromQL)
单机模式,不依赖分布式存储
基于HTTP采用pull方式收集数据
支持push数据到中间件(pushgateway)
通过服务发现或静态配置发现目标
多种图表和仪表盘
注意:由于数据采集可能会有丢失,所以 Prometheus 不适用对采集数据要 100% 准确的情形。但如果用于记录时间序列数据,Prometheus 具有很大的查询优势,此外,Prometheus 适用于微服务的体系架构。
组件:
Prometheus生态系统由多个组件构成,其中多是可选的,根据具体情况选择
Prometheus server - 收集和存储时间序列数据
Client Library: 客户端库,为需要监控的服务生成相应的 metrics 并暴露给 Prometheus server。当 Prometheus server 来 pull 时,直接返回实时状态的 metrics。
pushgateway - 对于短暂运行的任务,负责接收和缓存时间序列数据,同时也是一个数据源
exporter - 各种专用exporter,面向硬件、存储、数据库、HTTP服务等
alertmanager - 处理报警
webUI等,其他各种支持的工具

 浙公网安备 33010602011771号
浙公网安备 33010602011771号