

石铁大软工Hive极限测试
这周二我们20级软工进行了Hive数据清洗分析可视化的极限测试。
本来这是一个5个小时完成的项目,我整整做了两天还要多一点,而且我之前已经配置好了所有的环境。做的过程中心态一定要好,不要轻易破防!!!
这次测试的流程主要分为五个步骤。
1、数据导入
2、数据清洗
3、数据分析处理
4、Sqoop导入Hive数据到MySQL
5、通过javaweb+echarts进行数据可视化
下面是我做的具体流程代码。
一、数据导入:
建表:

create table sales_sample_20170310 ( `day_id` string comment '时间', `sale_nbr` string comment '卖出方', `buy_nbr` string comment '买入方', `cnt` int comment '数量', `round` int comment '金额') row format delimited fields terminated by ',' lines terminated by '\n';
csv数据导入:
load data local inpath '/root/hivedata/sales_sample_20170310.csv' into table sales_sample_20170310;
导入成功后验证
select * from sales_sample_20170310 limit 10000;
二、数据清洗
要求将day_id一列中的数值清洗为真实的日期格式,可用字符串表示。数据1对应日期2022-10-01,依次类推,15对应日期2022-10-15
我这里通过Hive内置的函数,通过拼接字符串的形式来写,最后再转换日期格式,就可以完成了。
字符串拼接:
insert overwrite table sales_sample_20170310 select concat('2022-10-',day_id),sale_nbr,buy_nbr,cnt,round from sales_sample_20170310 ;
转换格式:
create table sales_sample111 as select to_date(from_unixtime(UNIX_TIMESTAMP(day_id,'yyyy-MM-dd'))) as day_id, sale_nbr, buy_nbr, cnt, round from sales_sample_20170310;
验证:
select * from sales_sample111 limit 1000;
三、数据统计分析
在这里处理的数据100多Mb,文件很小,大约500万条数据。如果处理sql的执行时间超过15分钟,基本可以直接停止执行了,绝对是SQL写错了。检查SQL的限制字段或者分组字段重新查询。
我就有一个SQL写错了,处理出了10GB的数据,很离谱。
①统计每天各个机场的销售数量和销售金额。
-- 统计航空公司 create table sale_hangkong as select day_id,sale_nbr,sum(cnt) as cnt,sum(round) as round from sales_sample_20170310 where sale_nbr like 'C%' group by day_id, sale_nbr;
结果验证:
select * from sales_hangkong1 limit 1000;
②统计每天各个代理商的销售数量和销售金额。
create table day_sale as select day_id, sale_nbr, sum(cnt) as cnt_max, sum(round) as round_max from sales_sample111 where day_id between '2022-10-01' and '2022-10-20' group by sale_nbr,day_id;
结果验证:
select * from day_sale limit 1000;
③统计每天各个代理商的销售活跃度。
create table huoyuedu as select day_id, sale_nbr, count(*) as sale_number from sales_sample111 where day_id between '2022-10-01' and '2022-10-20' group by sale_nbr,day_id;
结果验证:
select * from huoyuedu limit 1000;
④汇总统计10月1日到10月15日之间各个代理商的销售利润。
这个最后要求的表字段较多,需要先建立买入表和卖出表进行辅助。最后通过两表连接查询做出利润表。
计算代理商买入数量金额创建买入表
--计算代理商买入数量金额 drop table mairu; create table mairu as select day, buy_nbr, sum(cnt) as cnt, sum(round) as round from sales_sample111 where buy_nbr like 'O%' group by day, buy_nbr; select * from mairu limit 1000;
计算代理商卖出数量金额创建卖出表
create table maichu as select day, sale_nbr, sum(cnt) as cnt, sum(round) as round from sales_sample111 where sale_nbr like 'O%' group by day, sale_nbr;
select * from maichu limit 1000;
计算利润建立利润表
create table lirun as select a.day as day, b.sale_nbr as nbr, a.cnt as cnt_buy, a.round as rount_buy, b.cnt as cnt_sale, b.round as round_sale, b.round-a.round as liren from mairu a join maichu b on a.buy_nbr = b.sale_nbr and a.day = b.day where a.day between '2022-10-01' and '2022-10-15';
select * from lirun limit 1000;
到这里就完成了第三阶段,第四阶段需要Sqoop安装部署,具体安装可以去bili搜索或者博客查看。
四、Sqoop数据导出
Sqoop进行数据导出的时候,虚拟机的Mysql必须提前建表。
①航空公司表导出
MySQL建表
--mysql create table sale_hangkong( day_id varchar(50) not null , sale_nbr varchar(20), cnt int , round int );
导出
bin/sqoop export \ --connect jdbc:mysql://node1:3306/testdb \ --username root \ --password hadoop \ --table sale_hangkong \ --columns day_id,sale_nbr,cnt,round \ --export-dir /user/hive/warehouse/wjb.db/sales_hangkong \ --input-fields-terminated-by "\001"
倒数第二行是自己的hive数据库文件的位置
倒数第三行是MySQL表的字段名
倒数第一行是选择数据字段的分隔符,hive默认是\001
②代理商每天销售表
MySQL建表
create table day_sale( day_id varchar(20) not null , sale_nbr varchar(20), cnt_sum int , round_sum int );
导出
bin/sqoop export \ --connect jdbc:mysql://node1:3306/testdb \ --username root \ --password hadoop \ --table day_sale \ --columns day_id,sale_nbr,cnt_sum,round_sum \ --export-dir /user/hive/warehouse/wjb.db/day_sale \ --fields-terminated-by "\001" \ --input-null-non-string '\\N'
③活跃度
MySQL建表
create table huoyuedu( day_id varchar(50) , sale_nbr varchar(20), sale_number int );
导出
bin/sqoop export \ --connect jdbc:mysql://node1:3306/testdb \ --username root \ --password hadoop \ --table huoyuedu \ --columns day_id,sale_nbr,sale_number \ --export-dir /user/hive/warehouse/wjb.db/huoyuedu \ --fields-terminated-by "\001" \ --input-null-non-string '\\N'
④利润
MySQL建表
--mysql create table lirun( day_id varchar(50) , nbr varchar(20), cnt_buy int, rount_buy int, cnt_sale int, round_sale int, lirun int );
导出
bin/sqoop export \ --connect jdbc:mysql://node1:3306/testdb \ --username root \ --password hadoop \ --table lirun \ --columns day_id,nbr,cnt_buy,rount_buy,cnt_sale,round_sale,lirun \ --export-dir /user/hive/warehouse/wjb.db/lirun \ --fields-terminated-by "\001" \ --input-null-non-string '\\N'
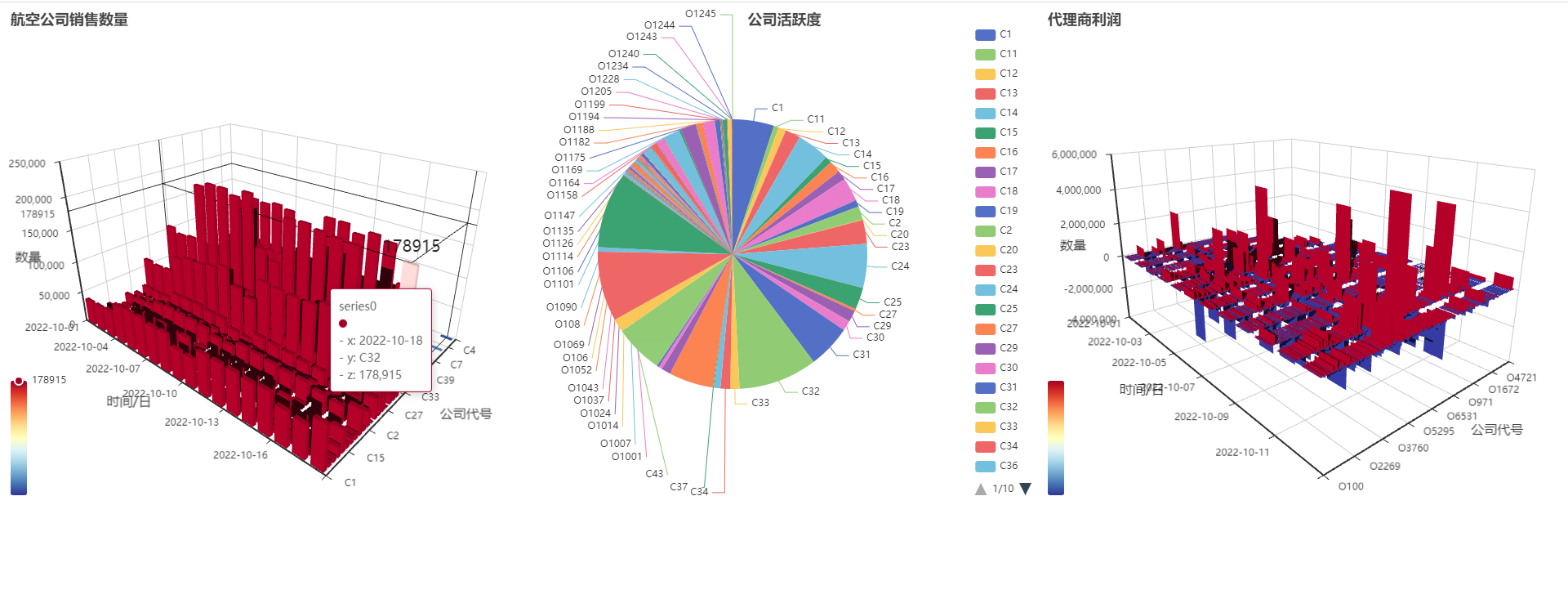
五、数据可视化
这里我是通过srpingboot+vue3做的,去Echatrts官网找实例复制。大致思路就是后端写好数据接口,前端简单处理一下直接赋值就好了。
由于代码太多冗杂不再这里展示,直接进行结果的展示。
相关源代码已开源到GitHub,可以到wjbhyn/springboot-echarts: 石铁大软工hive测试 (github.com)进行拉取


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 零经验选手,Compose 一天开发一款小游戏!
· 一起来玩mcp_server_sqlite,让AI帮你做增删改查!!