Hive建库建表
这里我使用的是DataGrip可视化工具。
第一次跟视频操作主要熟悉并记录一下流程。
先在虚拟机node3上创建一个数据库wjb
0: jdbc:hive2://node1:10000> create database wjb;
在数据库里创建表格,使用DataGrip工具
--1、创建一张表,将射手结构化数据文件在Hive中映射成功
-- 表名
-- 字段 名称 类型 顺序
-- 字段之间分隔符指定
create table wjb.t_archer(
id int comment "id编号",
name string comment "英雄名称",
hp_max int comment "最大生命",
mp_max int comment "最大法力",
attack_max int comment "最高物攻",
defense_max int comment "最大物防",
attack_range string comment "攻击范围",
role_main string comment "主要定位",
role_assist string comment "次要定位"
)
row format delimited
fields terminated by "\t"; --字段之间的分隔符
创建完成后需要先把Windows的txt文件移动到虚拟机,我使用FinalShell进行拖动到指定文件夹,并上传到HDFS文件系统。
#在node机器上进行操作
cd ~
cd hivedata/
#把文件从课程资料中首先上传到node1 linux系统上
#执行命令把文件上传到HDFS表所对应的目录下
hadoop fs -put team_ace_player.txt
/user/hive/warehouse/itheima.db/t_team_ace_playe
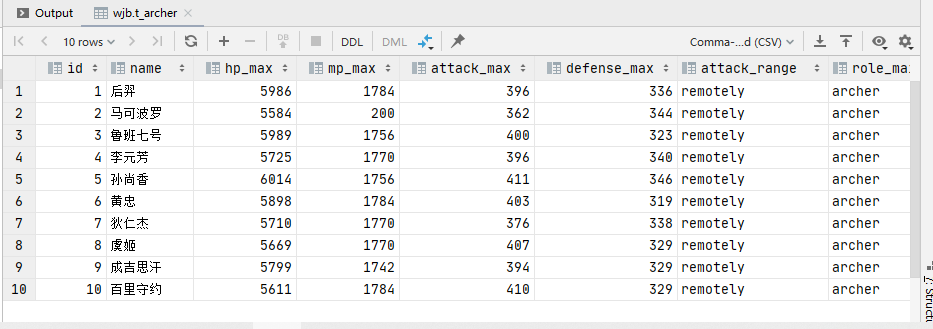
最后查询一下表格
select * from wjb.t_archer
到这里就完成了。
