2.9字符编码之文字是如何显示的
引子
通过上一节讲的二进制的知识,大家已经知道计算机只认识二进制,生活中的数字要想让计算机理解就必须转换成二进制。十进制到二进制的转换只能解决计算机理解数字的问题,那么文字要怎么让计算机理解呢?
于是我们就选择了一种曲线救国的方式,既然数字可以转换成十进制,我们只要想办法把文字转换成数字,这样文字不就可以表示成二进制了么?
可是文字应该怎么转换成数字呢?就是强制转换啊,简单粗暴呀。 我们自己强行约定了一个表,把文字和数字对应上,这张表就相当于翻译,我们可以拿着一个数字来对比对应表找到相应的文字,反之亦然。
ASCII码
这张表就是计算机显示各种文字、符号的基石呀
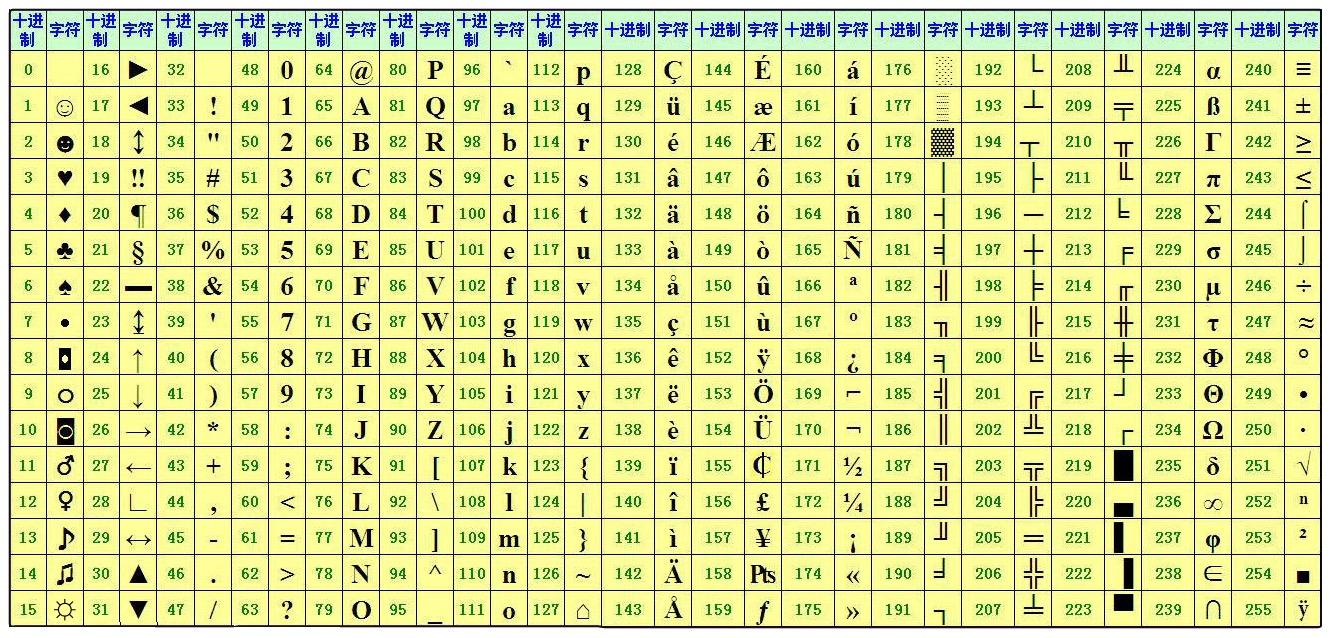
ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言。它是现今最通用的单字节编码系统,并等同于国际标准ISO/IEC 646。
由于计算机是美国人发明的,因此,最早只有127个字母被编码到计算机里,也就是大小写英文字母、数字和一些符号,这个编码表被称为ASCII编码,比如大写字母 A的编码是65,小写字母 z的编码是122。后128个称为扩展ASCII码。
那现在我们就知道了上面的字母符号和数字对应的表是早就存在的。那么根据现在有的一些十进制,我们就可以转换成二进制的编码串。
比如
一个空格对应的数字是0 翻译成二进制就是0(注意字符'0'和整数0是不同的) 一个对勾√对应的数字是251 翻译成二进制就是11111011
提问:假如我们要打印两个空格一个对勾 写作二进制就应该是 0011111011, 但是问题来了,我们怎么知道从哪儿到哪儿是一个字符呢?
论断句的重要性与必要性:
上次在网上看到个新闻,讲是个小偷在上海被捕时高喊道:“我一定要当上海贼王!”
正是由于这些字符串长的长,短的短,写在一起让我们难以分清每一个字符的起止位置,所以聪明的人类就想出了一个解决办法,既然一共就这255个字符,那最长的也不过是11111111八位,不如我们就把所有的二进制都转换成8位的,不足的用0来替换。
这样一来,刚刚的两个空格一个对勾就写作000000000000000011111011,读取的时候只要每次读8个字符就能知道每个字符的二进制值啦。
在这里,每一位0或者1所占的空间单位为bit(比特),这是计算机中最小的表示单位
每8个bit组成一个字节,这是计算机中最小的存储单位(毕竟你是没有办法存储半个字符的)orz~
bit 位,计算机中最小的表示单位 8bit = 1bytes 字节,最小的存储单位,1bytes缩写为1B 1KB=1024B 1MB=1024KB 1GB=1024MB 1TB=1024GB 1PB=1024TB 1EB=1024PB 1ZB=1024EB 1YB=1024ZB 1BB=1024YB
GB2312 & GBK
英文问题是解决了, 我们中文如何显示呢? 美国佬设计ASSCII码的时候应该是没考虑中国人有一天也能用上电脑, 所以根本没考虑中文的问题,上世界80年代,电脑进入中国,把砖家们难倒了,妈的你个一ASSCII只能存256个字符,我常用汉字就几千个,怎么玩???勒紧裤腰带还苏联贷款的时候我们都挺过来啦,这点小事难不到我们, 既然美帝的ASCII不支持中文,那我们自己搞张编码表不就行了, 于是我们设计出了GB2312编码表,长成下面的样子。一共存了6763个汉字。
这个表格比较大,像上面的一块块的文字区域有72个,这导致通过一个字节是没办法表示一个汉字的(因为一个字节最多允许256个字符变种,你现在6千多个,只能2个字节啦,2**16=65535个变种)。
有了gb2312,我们就能愉快的写中文啦。
但我们写字竟然会出现中英混杂的情况,比如“我是小猿圈,我的英文名叫Apeland.”, 这种你怎么办?这就要求你必须在gb2312里同时支持英文,但是还不能是2个字节表示一个英文字母。人家ASCII用一个字符,你用2个,那一个2mb大小的英文文档只要一改编码,就立刻变成4mb, 太坑爹,中国人你有钱也不能这么造呀。 所以中国砖家们又通过神奇手段兼容了ASSCII, 即遇到中文用2个字节,遇到英文直接用ASCII的编码。怎么做到的呢?
如何区别连在一起的2个字节是代表2个英文字母,还是一个中文汉字呢? 中国人如此聪明,决定,如果2个字节连在一起,且每个字节的第1位(也就是相当于128的那个2进制位)如果是1,就代表这是个中文,这个首位是128的字节被称为高字节。 也就是2个高字节连在一起,必然就是一个中文。 你怎么如此笃定?因为0-127已经表示了英文的绝大部分字符,128-255是ASCII的扩展表,表示的都是极特殊的字符,一般没什么用。所以中国人就直接拿来用了。
自1980年发布gb2312之后,中文一直用着没啥问题,随着个人电脑进入千家万户,有人发现,自己的名字竟然打印不出来,因为起的太生僻了。
于是1995年, 砖家们又升级了gb2312, 加入更多字符,连什么藏语、维吾尔语、日语、韩语、蒙古语什么的统统都包含进去了,国家统一亚洲的野心从这些基础工作中就可见一斑哈。 这个编码叫GBK,一直到现在,我们的windows电脑中文版本的编码就是GBK.
编码混战时代
中国人在搞自己编码的同时,世界上其它非英语国家也得用电脑呀,于是都搞出了自己的编码,你可以想得到的是,全世界有上百种语言,日本把日文编到Shift_JIS里,韩国把韩文编到Euc-kr里,
各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码。之前你从玩个日本游戏,往自己电脑上一装,就显示乱码了。
这么乱极大了阻碍了不同国家的信息传递,于是联合国出面,发誓要解决这个混乱局面。
因此,Unicode应运而生。Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了。Unicode 2-4字节 已经收录136690个字符,并还在一直不断扩张中…
Unicode标准也在不断发展,但最常用的是用两个字节表示一个字符(如果要用到非常偏僻的字符,就需要4个字节)。现代操作系统和大多数编程语言都直接支持Unicode。
Unicode有2个特点:
1.支持全球所有语言
2.可以跟各种语言的编码自由转换,也就是说,即使你gbk编码的文字 ,想转成unicode很容易。
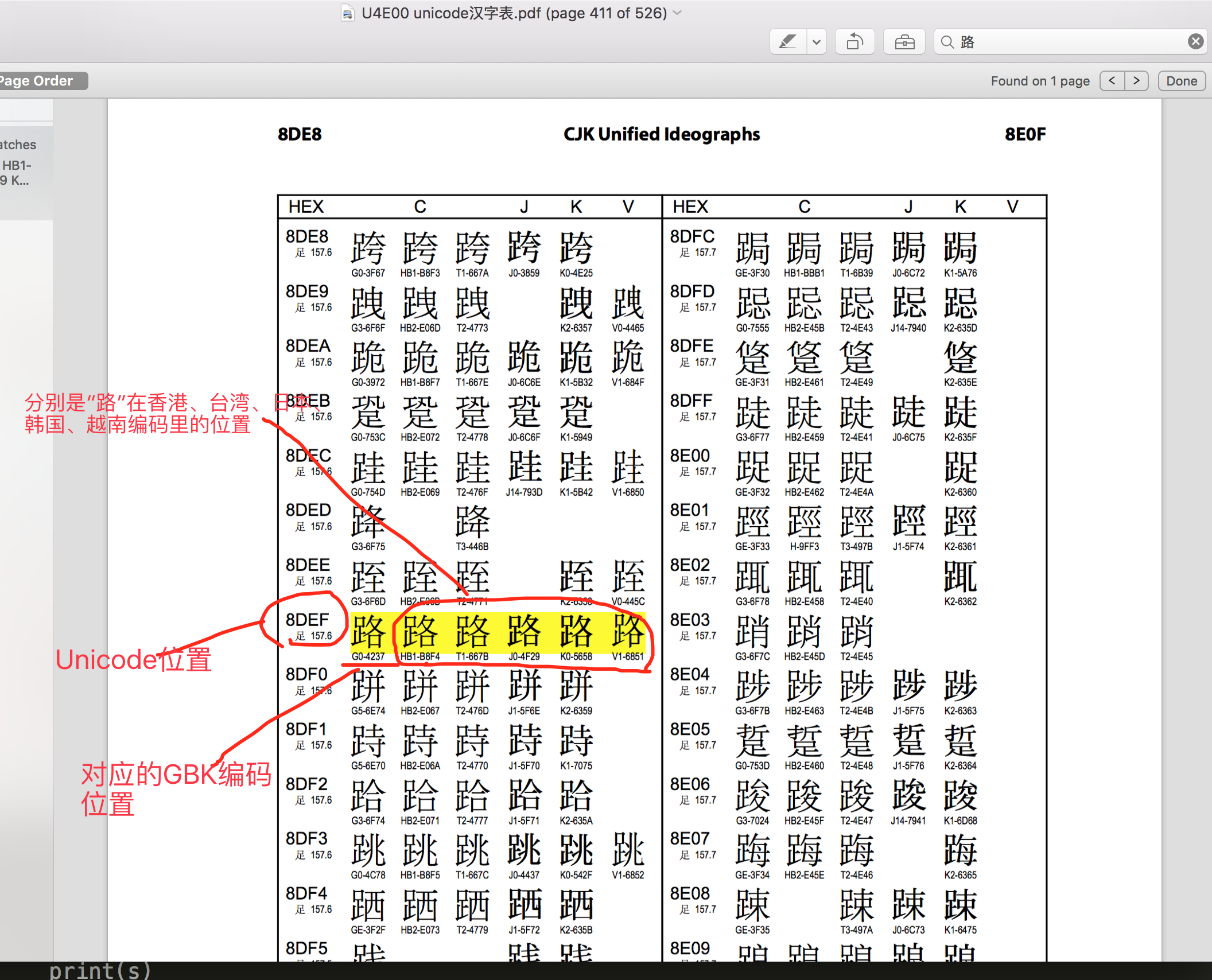
为何unicode可以跟其它语言互相转换呢? 因为有跟所有语言都有对应关系哈,这样做的好处是可以让那些已经用gbk或其它编码写好的软件容易的转成unicode编码 ,利于unicode的推广。 下图就是unicode跟中文编码的对应关系
UTF-8
新的问题又出现了:如果统一成Unicode编码,乱码问题从此消失了。但是,如果你写的文本基本上全部是英文的话,用Unicode编码比ASCII编码需要多一倍的存储空间,由于计算机的内存比较大,并且字符串在内容中表示时也不会特别大,所以内容可以使用unicode来处理,但是存储和网络传输时一般数据都会非常多,那么增加1倍将是无法容忍的!!!
为了解决存储和网络传输的问题,出现了Unicode Transformation Format,学术名UTF,即:对unicode字符进行转换,以便于在存储和网络传输时可以节省空间!
- UTF-8: 使用1、2、3、4个字节表示所有字符;优先使用1个字符、无法满足则使增加一个字节,最多4个字节。英文占1个字节、欧洲语系占2个、东亚占3个,其它及特殊字符占4个
- UTF-16: 使用2、4个字节表示所有字符;优先使用2个字节,否则使用4个字节表示。
- UTF-32: 使用4个字节表示所有字符;
总结:UTF 是为unicode编码 设计 的一种 在存储 和传输时节省空间的编码方案。
如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间:
| 字符 | ASCII | Unicode | UTF-8 |
|---|---|---|---|
| A | 01000001 | 00000000 01000001 | 01000001 |
| 中 | x | 01001110 00101101 | 11100100 10111000 10101101 |
从上面的表格还可以发现,UTF-8编码有一个额外的好处,就是ASCII编码实际上可以被看成是UTF-8编码的一部分,所以,大量只支持ASCII编码的历史遗留软件可以在UTF-8编码下继续工作。
搞清楚了ASCII、Unicode和UTF-8的关系,我们就可以总结一下现在计算机系统通用的字符编码工作方式:
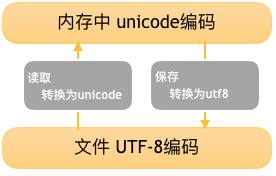
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件。
常用编码介绍一览表
| 编码 | 制定时间 | 作用 | 所占字节数 |
|---|---|---|---|
| ASCII | 1967年 | 表示英语及西欧语言 | 8bit/1bytes |
| GB2312 | 1980年 | 国家简体中文字符集,兼容ASCII | 2bytes |
| Unicode | 1991年 | 国际标准组织统一标准字符集 | 2bytes |
| GBK | 1995年 | GB2312的扩展字符集,支持繁体字,兼容GB2312 | 2bytes |
| UTF-8 | 1992年 | 不定长编码 | 1-3bytes |
Py2 Vs Py3编码
python生下来的时候 还没有unicode&utf-8, 所以龟叔选用的默认编码只能是ASCII, 一真到py2.7,用的还是ASCII, 导致Py默认只支持英文,想支持其它语言,必须单独配置。
lexs-MacBook-Pro:day2 alex$ more py2编码_ascii.py
print("小猿圈")
Alexs-MacBook-Pro:day2 alex$ python2.7 py2编码_ascii.py
File "py2编码_ascii.py", line 2
SyntaxError: Non-ASCII character '\xe5' in file py2编码_ascii.py on line 2, but no encoding declared; see http://python.org/dev/peps/pep-0263/ for details
直接写中文执行会报错的。
需在文件开头声明文件的编码才能写中文
# -*- encoding:utf-8 -*-
print("小猿圈")
再执行就不会有错了。
不过注意如果你的电脑 是windows系统 , 你的系统默认编码是GBK ,你声明的时候要声明成GBK, 不能是utf-8, 否则依然是乱码,因为gbk自然不认识utf-8.
在Py2里编码问题非常头疼,若不是彻底理解编码之间的各种关系,会经常容易出现乱码而不知所措。
到了Py3推出后,终于把默认编码改成了unicode, 同时文件存储编码变成了utf-8,意味着,不用任何声明,你就可以写各种语言文字在你的Python程序里。 从此,程序们手牵手过上了快乐的生活。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号