

推荐系统简介
一、推荐系统的目的
- 让用户更快更好的获取到自己需要的内容
- 让内容更快更好的推送到喜欢它的用户手中
- 让网站(平台)更有效的保留用户资源
二、推荐系统的基本思想
- 利用用户和物品的特征信息,给用户推荐那些具有用户喜欢的特征的物品。
- 利用用户喜欢过的物品,给用户推荐与他喜欢过的物品相似的物品。
- 利用和用户相似的其他用户,给用户推荐那些和他们兴趣爱好相似的其他用户喜欢的物品
三、推荐系统分类
1、根据实时性分类
- 离线推荐
- 实时推荐
2、根据推荐原则分类
- 基于相似度的推荐
- 基于知识的推荐
- 基于模型的推荐
3、根据数据源分类
- 基于人口统计学的推荐
- 基于内容的推荐
- 基于协同过滤的推荐
四、推荐算法简介
1、基于人口统计学的推荐
2、基于内容的推荐:利用用户评价过的物品的内容特征
3、基于协同过滤的推荐
- 基于近邻的协同过滤
- 基于用户(User-CF)
- 基于物品(Item-CF)
- 基于模型的协同过滤
- 奇异值分解(SVD)
- 潜在语义分析(LSA)
- 支撑向量机(SVM)
5、混合推荐
实际网站的推荐系统往往都不是单纯只采用了某一种推荐机制和策略,往往是将多个方法混合在一起,从而达到更好的推荐效果。比较流行的组合方法有:
- 加权混合:用线性公式(linear formula)将几种不同的推荐按照一定权重组合起来,具体权重的值需要在测试数据集上反复实验,从而达到最好的推荐效果
- 切换混合:切换的混合方式,就是允许在不同的情况(数据量,系统运行状况,用户和物品的数目等)下,选择最为合适的推荐机制计算推荐
- 分区混合:采用多种推荐机制,并将不同的推荐结果分不同的区显示给用户
- 分层混合:采用多种推荐机制,并将一个推荐机制的结果作为另一个的输入,从而综合各个推荐机制的优缺点,得到更加准确的推荐
五、推荐系统实验方法
1、离线实验
- 通过日志系统获得用户行为数据,并按照一定格式生成一个标准的数据集
- 将数据集按照一定的规则分成训练集和测试集
- 在训练集上训练用户兴趣模型,在测试集上进行预测
- 通过事先定义的离线指标,评测算法在测试集上的预测结果
2、用户调查
用户调查需要有一些真实用户,让他们在需要测试的推荐系统上完成一些任务;我们需要记录他们的行为,并让他们回答一些问题;最后进行分析
3、在线实验
在完成离线实验和用户调查后,可以将系统上线做AB测试
AB测试:通过一定的规则将用户随机分成几组,对不同组的用户采用不同的算法,然后通过统计不同组的评测指标,比较不同算法的好坏。
六、推荐系统评测指标
1、预测准确度:是推荐系统最重要的离线评测指标
- 预测评分准确度:衡量的是算法预测的评分与用户的实际评分的贴近程度。
平均绝对误差(MAE):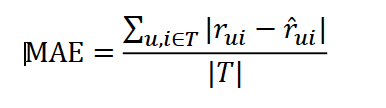
均方根误差(RMSE):![]()
- TopN推荐:给用户一个个性化的推荐列表
精确率(precision):针对预测结果而言,它表示预测为正的样本中有多少是真正的正样本。那么预测为正就有两种可能了,一种就是把正类预测为正类(TP),另一种就是把负类预测为正类(FP)
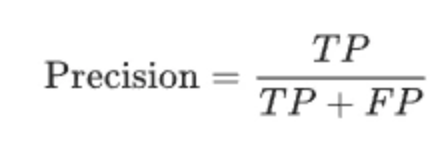
召回率(recall):针对原来的样本而言,它表示的是样本中的正例有多少被预测正确了。那也有两种可能,一种是把原来的正类预测成正类(TP),另一种就是把原来的正类预测为负类(FN)。

2、用户满意度:
- 只能通过用户调查或者在线实验获得
- 可以通过用户点击率、停留时间、转化率等指标度量用户的满意度
3、覆盖率:推荐系统推荐出来的物品占总物品的比例。
4、多样性:推荐系统需要能够覆盖用户不同兴趣的领域。
5、新颖性:向用户推荐非热门、非流行物品的能力
6、惊喜度:推荐的结果和用户的历史兴趣不相似,但让用户满意,这就是惊喜度很高
7、信任度:用户信任推荐系统,就会增加用户和推荐系统的交互
- 增加信任度的方式:
- 增加系统透明度
- 利用社交网络
8、实时性
9、健壮性:衡量推荐系统抗击作弊的能力。
10、商业目标

