

MySQL-索引简介
一、索引是什么?
索引是本质是一种数据结构,索引的目的在于提高查询效率。【排好序的快速查找的数据结构】
每个节点包含索引键值和一个指向对应数据记录物理地址的指针。
索引往往以索引文件的形式存储在磁盘。
二、索引的优缺点:
优势:
提高数据检索的效率,降低数据库的IO成本
通过索引列对数据进行排序,降低数据排序的成本,降低CPU的消耗
缺点:
索引提高了查询效率,但是同时会降低更新表的速度(MySQL不仅要更新数据,还要保存索引文件每次更新添加了索引列的字段)
三、MySQL索引分类
单值索引
唯一索引
复合索引:一个索引
基本语法:
创建索引:create index <索引的名字> on table_name (列的列表) 修改表索引: alter table table_name add index [索引的名字] (列的列表); 删除索引:drop index <索引的名字> on table_name 查看索引:show index from table_name;
四、MySQL索引结构
BTree索引
Hash索引
full-text全文索引
R-Tree索引
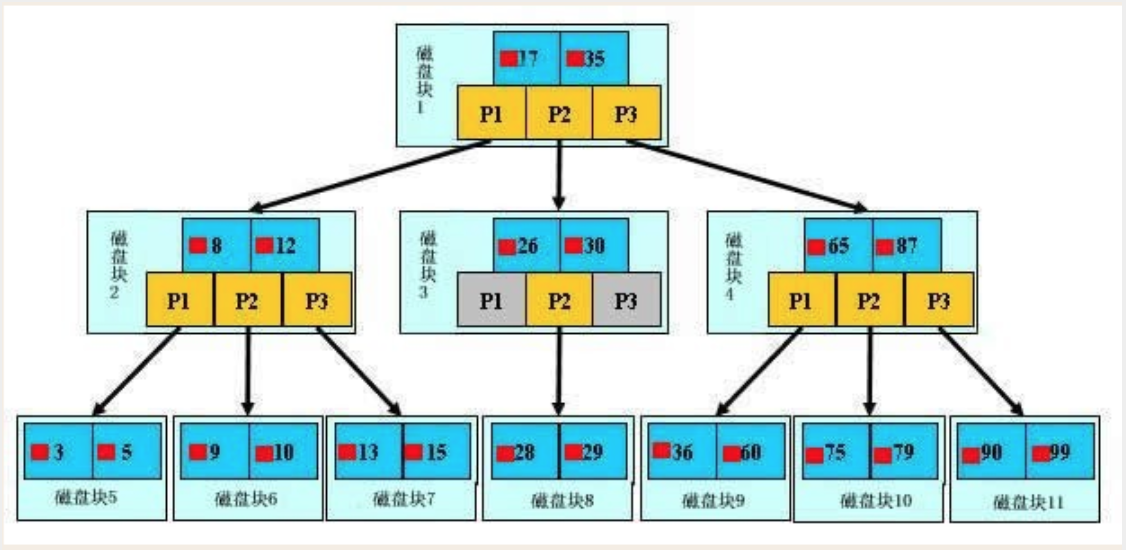
一颗B+树,浅蓝色的块我们称之为一个磁盘块,可以看到每个磁盘块包含几个数据项(深蓝色所示)和指针(黄色所示)
真实的数据存在于叶子节点即3、5、9、10、13、15、28、29、36、60、75、79、90、99。
非叶子节点只不存储真实的数据,只存储指引搜索方向的数据项。
- B+树查找过程
如果要查找数据项29,首先会把磁盘块1由磁盘加载到内存,此时发生一次IO,在内存中用二分查找确定29在17和35之间,锁定磁盘块1的P2指针。
通过磁盘块1的P2指针的磁盘地址把磁盘块3由磁盘加载到内存,发生第二次IO,29在26和30之间,锁定磁盘块3的P2指针。
通过磁盘块3的P2指针的磁盘地址把磁盘块8由磁盘加载到内存,发生第三次IO,同时内存中做二分查找找到29,结束查询,总计三次IO。
真实的情况是,3层的b+树可以表示上百万的数据,如果上百万的数据查找只需要三次IO,性能提高将是巨大的。
如果没有索引,每个数据项都要发生一次IO,那么总共需要百万次的IO,显然成本非常非常高。
五、什么情况下需要创建索引
六、explain分析

1、id:查询中执行select子句或操作表的顺序
id相同:执行顺序由上到下
id不同:如果是子查询,id的序号会递增,id越大优先级越高,越先被执行
id相同、不同同时存在:,id越大优先级越高,越先被执行
2、select_type:主要是用于区别普通查询、联合查询、子查询等的复杂查询
SIMPLE:简单SELECT,不使用UNION或子查询等
PRIMARY:查询中若包含任何复杂的子部分,最外层的select被标记为PRIMARY
SUBQUERY:在select或where列表中包含子查询
DERIVED
UNION
UNION RESULT:
3、table:这一行的数据是关于哪个表的
4、type:
从最好到最差依次是:system>const>eq_ref>ref>range>index>ALL【一般来说至少达到range或ref级别】
system:表只有一行记录(等于系统表)
const:
eq_ref
ref
range
index:Full Index Scan,index与ALL区别为index类型只遍历索引树
ALL:Full Table Scan, MySQL将遍历全表以找到匹配的行
5、possible_keys
6、key
7、key_len
8、ref
9、rows
10、extra:包含不适合在其他列中显示但十分重要的额外信息
Using filesort:MySQL中无法利用索引完成的排序操作称为“文件排序”
Using temporary:MySQL需要使用临时表来存储结果集,常见于排序 order by和分组查询group by
Using index
五、提高Order By的速度
- 当query的字段大小总和小于max_length_for_sort_data,而且排序字段不是TEXT|BLOB类型时,使用单路排序。否则使用多路排序
- 两种算法的数据都有可能超出sort_buffer_size的容量,超出之后,会创建tmp文件进行合并排序,导致多次IO。
- 尝试提高sort_buffer_size
- 尝试提高max_length_for_sort_data,如果设置太高,数据总容量超出sort_buffer_size的概率增大,会导致高磁盘IO和低的处理器使用率。

