



《信息安全系统设计与实现》学习笔记10
《信息安全系统设计与实现》学习笔记10
第十二章 块设备I/O和缓冲区管理
块设备I/O缓冲区
I/O缓冲的基本原理非常简单。文件系统使用一系列I/O缓冲区作为块设备的缓存内存。当进程试图读取(dev,blk)标识的磁盘块时。它首先在缓冲区缓存中搜索分配给磁盘块的缓冲区。如果该缓冲区存在并且包含有效数据、那么它只需从缓冲区中读取数据、而无须再次从磁盘中读取数据块。如果该缓冲区不存在,它会为磁盘块分配一个缓冲区,将数据从磁盘读人缓冲区,然后从缓冲区读取数据。当某个块被读入时、该缓冲区将被保存在缓冲区缓存中,以供任意进程对同一个块的下一次读/写请求使用。同样,当进程写入磁盘块时,它首先会获取一个分配给该块的缓冲区。然后,它将数据写入缓冲区,将缓冲区标记为脏,以延迟写入,并将其释放到缓冲区缓存中。由于脏缓冲区包含有效的数据,因此可以使用它来满足对同一块的后续读/写请求,而不会引起实际磁盘I/O。脏缓冲区只有在被重新分配到不同的块时才会写人磁盘。
Unix/IO缓冲区管理算法
-
I/0缓冲区:内核中的一系列NBUF 缓冲区用作缓冲区缓存
typdef struct buf{ struct buf *next_free; //freelist pointer struct buf *next_dev; //dev_list pointer int dev, bIk; //assigned disk block; int opcode; //READ|WRITE int dirty; //buffer data modified int async; //ASYNC write flag int valid; //buffer data valid int busy; //buffer is in use int wanted; //some process needs this buffer struct semaphore lock=1; //buffer locking semaphore; value=1 struct semaphore iodone=0; //for process to wait for I/O completion; char buf[BLKSIZE]; //block data area }BUFFER; BUFFER buf[NBUF],*freelist; //NBUF buffers and free buffer list缓冲区结构体由两部分组成:用于缓冲区管理的缓冲头部分和用于数据块的数据部分。
-
设备表:每个块设备用一个设备表结构表示。
struct devtab{ u16 dev; //major device number BUFFER *dev_list; //device buffer list BUFFER *io_queue; //device I/O queue }devtab[NDEV];每个设备表都有一个dev_list,包含当前分配给该设备的I/O缓冲区,还有一个io_queue,包含设备上等待I/O操作的缓冲区。
-
缓冲区初始化:当系统启动时,所有I/O缓冲区都在空闲列表中,所有设备列表和I/O队列均为空。
-
缓冲区列表:当缓冲区分配给(dev, blk)时,它会被插入设备表的dev_list中。如果缓冲区当前正在使用,则会将其标记为BUSY(繁忙)并从空闲列表中删除。繁忙缓冲区也可能会在设备表的I/O队列中。由于一个缓冲区不能同时处于空闲状态和繁忙状态,所以可通过使用相同的next_free指针来维护设备I/O队列。当缓冲区不再繁忙时,它会被释放回空闲列表,但仍保留在dev_list中,以便可能重用。只有在重新分配时,缓冲区才可能从一个dev_list更改到另一个dev_list中。
-
Unix getblk/brelse算法
/* getblk:return a buffer=(dev,blk) for exclusive use */ BUFFER *getblk(dev,b1k){ while(1){ (1). search dev_list for a bp=(dev,blk); (2). if(bp in dev_lst){ if(bp BUSY){ set bp WANTED flag; sleep(bp); //wait for bp to be released continue; //retry the algorithm } /* bp not BUSY */ take bp out of freelist; mark bp BUSY; return bp; } (3). /* bp not in cache; try to get a free buf from freelist */ if(freelist empty){ set freelist WANTED flag; sleep(freelist); //wait for any free buffer continue; //retry the algorithm } (4). /* freelist not empty */ bp = first bp taken out of freelist; mark bp BUSY; if(bp DIRTY){ //bp is for delayed write awrite(bp); //write bp out ASYNC; continue; //from (1) but not retry } (5). reassign bp to (dev,blk); //set bp data invalid,etc. return bp; } } /** brelse:releases a buffer as FREE to freelist **/ brelse(BUFFER *bp){ if(bp WANTED) wakeup(bp); //wakeup ALL proc's sleeping on bp; if(freelist WANTED) wakeup(freelist); //wakeup ALL proc's sleeping on freelist; clear bp and freelist WANTED flags; insert bp to (tail of) freelist; }缓冲区存放在散列队列中。当缓冲区的数量很大时,散列可以减少搜索时间。当缓冲区的数量很少时,由于额外系统开销,散列实际上可能会增加执行时间。
-
Unix算法的一些具体说明
-
数据的一致性
-
缓存效果
-
临界区
-
-
Unix算法的缺点
-
效率低下
-
缓存效果不可预知
-
可能会出现饥饿
-
该算法使用只适用于单处理器系统的休眠/唤醒操作
-
新I/O缓冲区管理算法
-
假设有一个单处理器内核(一次运行一个进程)。使用计数信号量上的P/V来设计满足以下要求的新的缓冲区管理算法:
-
保证数据一致性。
-
良好的缓存效果。
-
高效率:没有重试循环,没有不必要的进程“唤醒”。
-
无死锁和饥饿。
-
P/V算法
BUFFER *getblk(dev,blk)
{
while(1){
(1). p(free);
(2). if (bp in dev_list){
(3). if (bp not BUSY){
remove from freelist;
P(bp);
return bp;
}
V(free);
(4). P(bp);
return bp;
}
(5). bp = first buffer taken out of freelist;
P(bp);
(6). if (bp dirty){
awrite(bp);
continue;
}
(7). reassign bp to (dev,blk);
return bp;
}
}
brelse (BUFFER *bp)
{
(8).if (bp queue has waiter) {V(bp); return; }
(9).if (bp dirty && freee queue has waiter){ awrite(bp); return;}
(10).enter bp into (tail of) freelist; V(bp); V(free);
}
下面将说明PV算法是正确的并满足要求:
-
缓冲区唯一性:在getblk()中,如果有空闲缓冲区,则进程不会在(1)处等待,而是会搜索dev_list。
-
无重试循环:进程重新执行while(1)循环的唯一位置是在(6)处,但这不是重试,因为进程正在不断地执行。
-
无不必要唤醒:在getblk()中,进程可以在(1)处等待空闲缓冲区,也可以在(4)处等待所需的缓冲区。在任意一种情况下,在有缓冲区之前,都不会唤醒进程重新运行。
-
缓存效果:在Unix算法中,每个释放的缓冲区都可被获取。而在新的算法中,始终保留含等待程序的缓冲区以供重用。只有缓冲区不含等待程序时,才会被释放为空闲。这样可以提高缓冲区的缓存效果。
-
无死锁和饥饿:在getblk()中,信号量锁定顺序始终是单向的,即P(free),然后是P(bp),但决不会反过来,因此不会发生死锁。如果没有空闲缓冲区,所有请求进程都将在(1)处阻塞。
实践
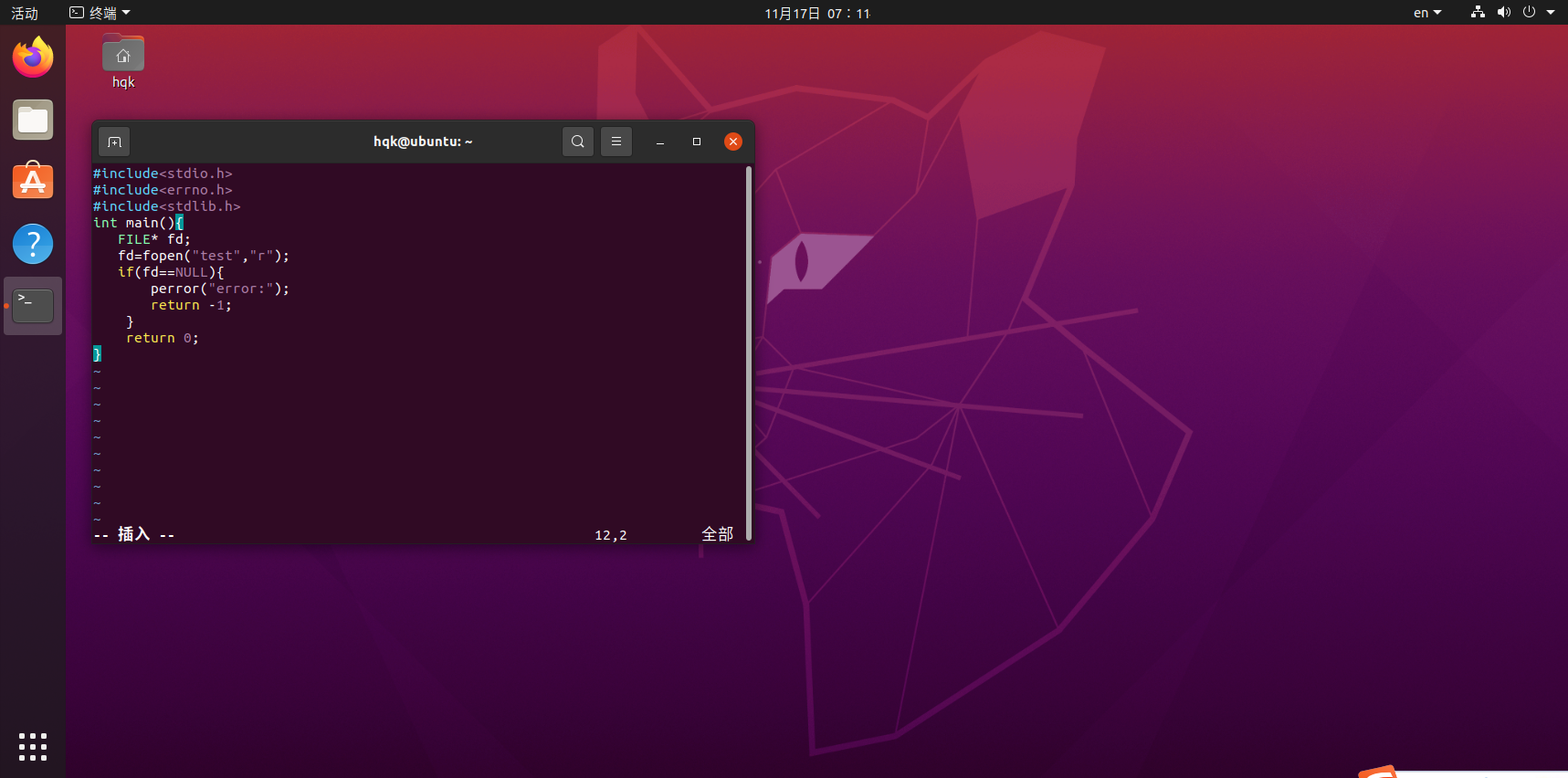
perror()函数实现
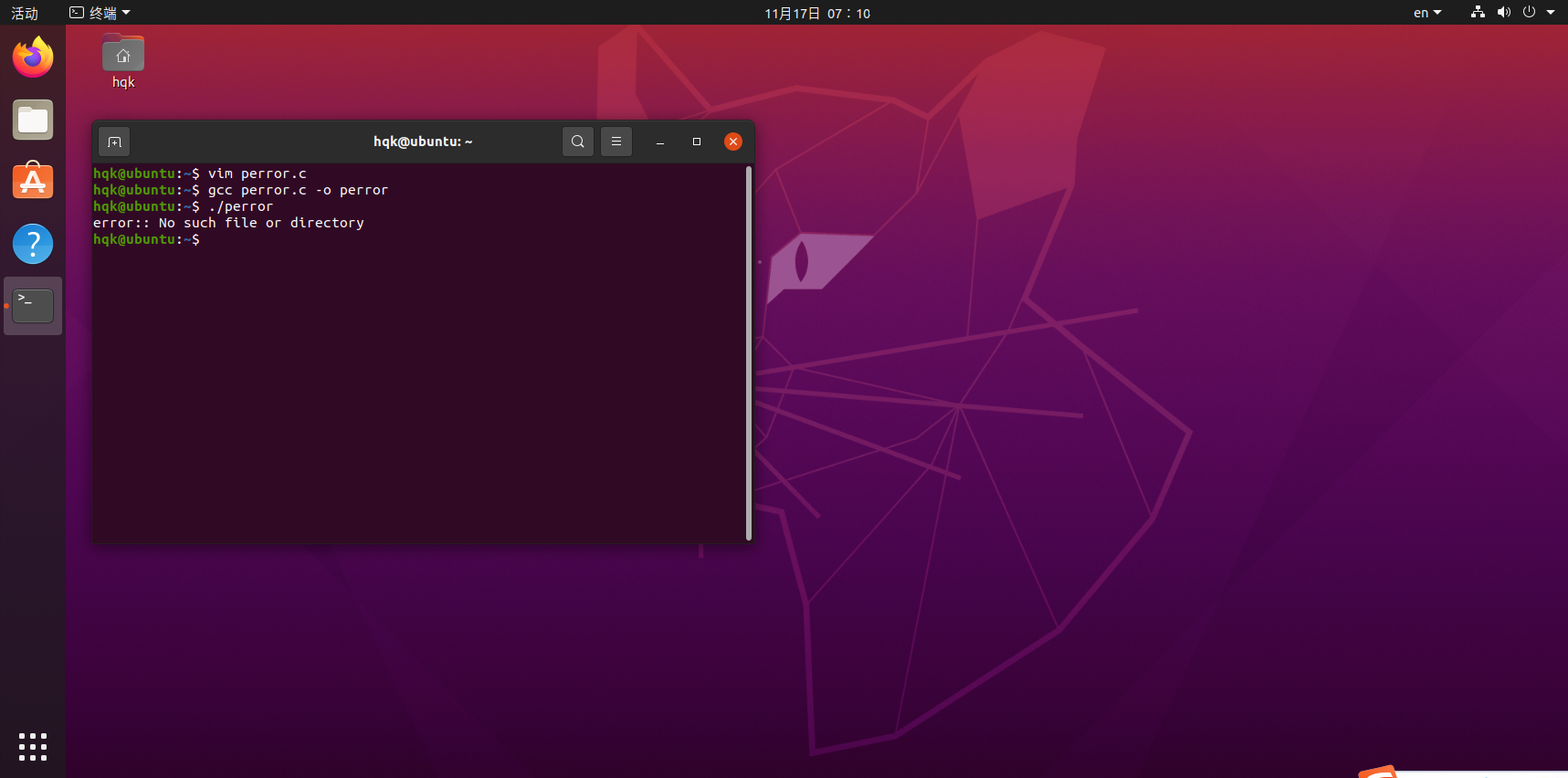
perror.c:
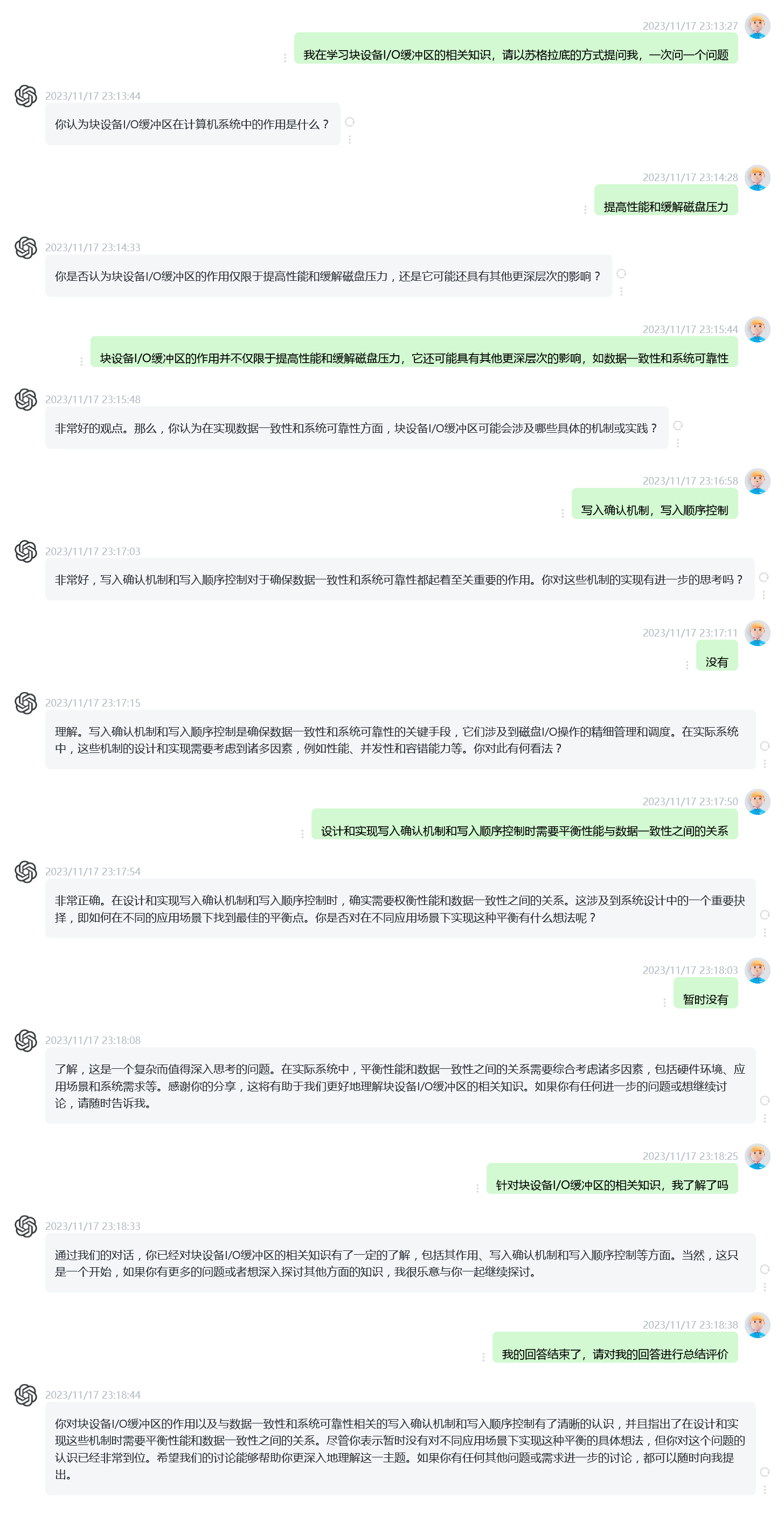
苏格拉底挑战
块设备I/O缓冲区的苏格拉底挑战
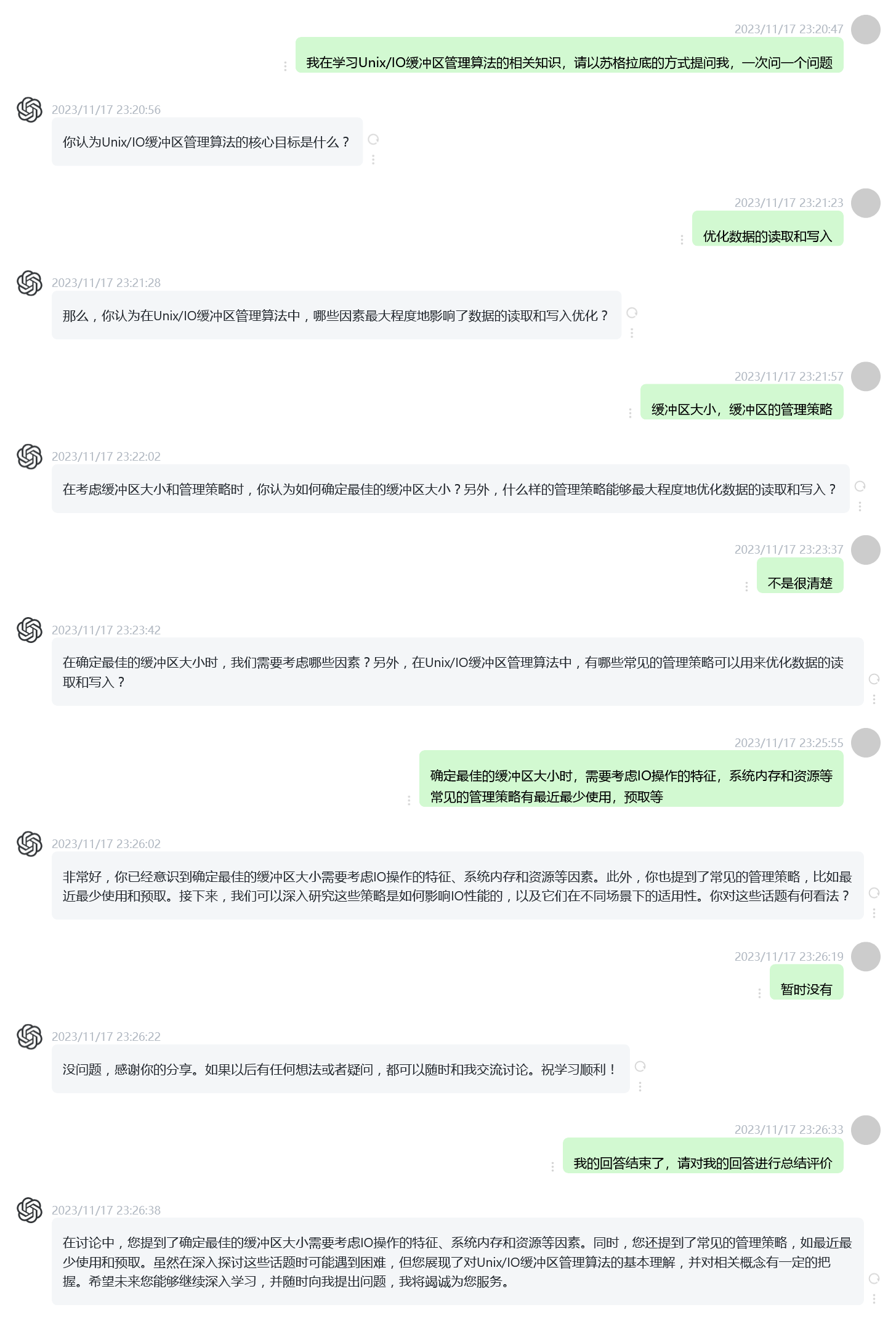
Unix/IO缓冲区管理算法的苏格拉底挑战
遇到的问题
问题:不同的IO缓冲区管理算法之间有什么区别?
解决:问gpt
gpt的回答


