正则表达式
知道这强大的玩意很久了,一直没用到就没看,趁目前学习 Java 中顺便学习之 …
初识
正则表达式是一个用于匹配字符串的模版,提供 查找、分割、提取、替换 等操作。
预定义的规则

Greedy数量词规则

其中,? 可以理解为非贪婪模式,只匹配第一次出现的地方。
功能与应用:实质是匹配
[1]. 匹配 [2]. 切割 [3]. 替换 [4]. 获取
下面重点说明下:获取
Pattern 类和 Matcher 类用于支持正则表达式,Pattern 对象(正则对象)是正则表达式编译后在内存中的表示形式,Matcher 对象(匹配器)保存执行匹配所涉及的状态,多个 Matcher 对象可以共享一个 Pattern 对象。
- 合法字符 和 特殊字符:*≥0,+≥1,0≤?≤1
- 通配符:预定义字符 和 边界匹配符;
- 方括号表达式 和 圆括号表达式:
- 数量表示符:默认 Greedy 模式
Pattern pat = Pattern.comlile("a*b");
Matcher mat = pat.matcher("b");
boolean res1 = mat.matches();
boolean res2 = Pattern.matches("a*b", "b");
// res1 = res2。 另外可以利用 String 类的 matches()方法
boolean res = 目标字符串.matches("正则表达式");
其中,Pattern 不可变类,并发线程安全;Matcher 类的实例方法 find() 和 group() 可以从目标字符串中依次取出特定子串,start() 和 end() 确定子串的起始位置。
常用正则表达式
中文:@"^[\u4e00-\u9fa5]+$"
英文:@"^[a-zA-Z]+$"
数字:@"^[0-9]+$"
邮箱:@"^[a-zA-Z0-9_+.-]+@([a-zA-Z0-9_-])+((\.\w{1,4}){1,3})$"
手机号:@"^1[3,4,5,7,8]\d{9}$"
特殊字符:键盘上可见的所有非字母数字的符号@"^((?=[\x21-\x7e]+)[^A-Za-z0-9])$"
或 枚举"[`~!@#$%^&*()+=|{}':;',\\[\\].<>/?~!@#¥%……&*()——+|{}【】‘;:”“’。,、?]"
数字字母、特殊字符等:@"^[\x21-\x7e]+$"
根据手机号判断运营商
移动 ^134[0-8]\d{7}$|^(?:13[5-9]|14[78]|15[0-27-9]|165|17[28]|170[356]|18[2-478]|198)\d{7,8}$
联通 ^(?:13[0-2]|14[56]|15[56]|16[67]|176|167|170[47-9]|17[156]|18[56])\d{7,8}|$
电信 ^(?:133|1349|149|153|162|170[0-2]|173|1740[0-5]|177|18[019]|19[0139])\d{6,8}$
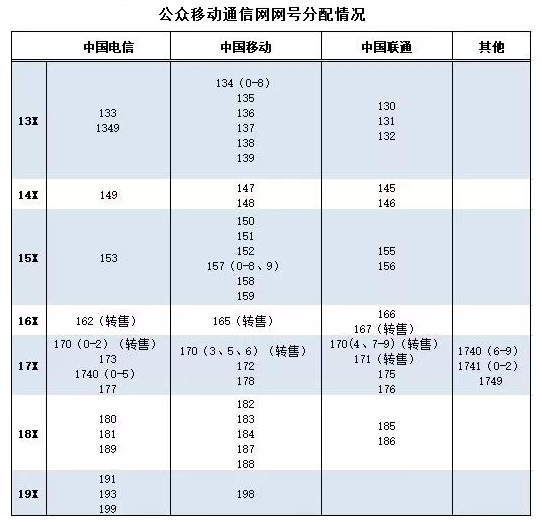
注:目前 2020.01月 版本,需及时更新
常用场景总结
// 将多个连续空格替换成一个 Regex.Replace(str, "\\s+", " ");
最近项目上遇到问题,归类相似的SQL语句,采用正则方式,相关表达式总结如下:(待优化)
// 表名 public const string REG_TabName = @"\s*(from|join)\s+([\[?#?\w+-?\]?\.?]+)"; // select...from之间的部分, 包括(select和from) public const string REG_SelectFrom1 = @"(^select.*?[\s]*from)"; //ok // select...from之间的部分, 不包括(select和from) public const string REG_SelectFrom2 = @"(?<=^select)(.*?[\s]*)(?=from)"; // 匹配select top 的数字的后面部分 public const string Reg_Top_Post = @"^(select top)\s+\(?\d+\)?\s+(.+)"; //INSERT INTO 表名称 VALUES (值1, 值2,....) //INSERT INTO table_name (列1, 列2,...) VALUES (值1, 值2,....) public const string REG_Insert = @"\s*(insert\s+into\s+([\[?#?\w+-?\]?\.?]+))"; //UPDATE 表名称 SET 列名称 = 新值 WHERE 列名称 = 某值 /// update xxx set... public const string REG_Update1 = @"\s*(update\s+([\[?#?\w+-?\]?\.?]+))"; //略有问题 // update...set之间的部分, 不包括(update和set) public const string REG_Update2 = @"(?<=^update)(.*?[\s]*)(?=set)"; //DELETE FROM 表名称 WHERE 列名称 = 值 public const string REG_Delete = @"(^delete.*?[\s]*from)"; //问题比较大
同时推荐一个SQL解析利器:Druid - SqlParser - github;待学习!
扩展
正则匹配时,可以采用 静态方法Regex.Match 或 实例方法reg.Match,但是在大量重复调用同一正则表达式时,可能会存在性能问题(时间、内存)。
Regex.CompileToAssembly
// 摘要: 将一个或多个指定的 System.Text.RegularExpressions.Regex 对象编译为命名程序集 // regexinfos:描述要编译的正则表达式的数组 // assemblyname:程序集的文件名。 public static void CompileToAssembly(RegexCompilationInfo[] regexinfos, AssemblyName assemblyname);
方法使用信息参见:Regex.CompileToAssembly,正则表达式的最佳实践
---
纵使山重水复,亦会柳暗花明
sunqh1991@163.com
欢迎关注,互相交流

