
Redis学习笔记
Redis
学习方式:
-
基本的理论学习, 然后将知识融会贯通
学习路径
-
nosql 讲解
-
阿里巴巴架构眼演进
-
nosql数据模型
-
nosql 四大分类
-
CAP
-
BASE
-
Redis入门
-
Redis安装(windows & linux 服务器)
-
五大基本数据类型
-
三种特殊数据类型
-
redis配置详解
-
redis持久化
-
redis事务操作
-
redis 实现订阅发布
-
redis主从复制
-
redis 哨兵模式
-
缓存穿透及解决方案
-
缓存击穿及解决方案
-
缓存雪崩及解决方案
-
基础API以及jedis 详解
-
springboot 集成redis操作
-
redis的实践分析
Nosql 概述
为什么要用Nosql
大数据时代; 2020
一般的数据库无法进行分析处理.
- 单机MYSQL的年代!
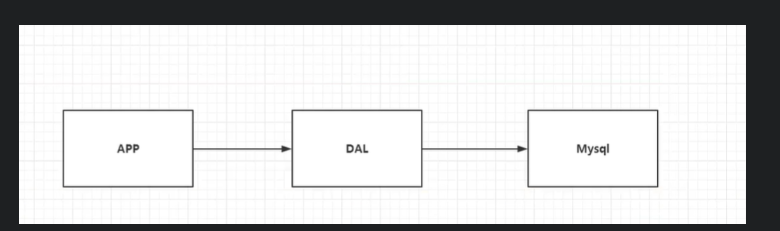
90年代, 一个基本的网站访问量一般不会太大, 单个数据库完全足够!
思考: 网站的瓶颈是什么?
- 数量如果太大, 一个机器放不下
- 数据的索引(B+ Tree), 一个机器内存放不下
- 访问量(读写混合) ,一台服务器承受不了
只要出现以上三种情况之一, 必须晋级
2.Memcached(缓存) + MYSQL + 垂直拆分(读写分离)
网站 80% 的情况都是在读, 每次都要去查询数据库的话就十分的麻烦! 希望减轻数据的压力, 可以使用缓存来保证效率!
发展过程: 优化数据结构和索引 ---> 文件缓存 (IO)---> Memcached(当时最热门的技术)
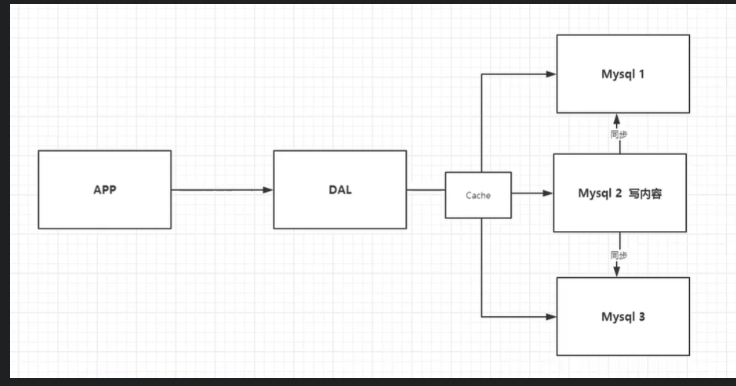
- 分库分表 + 水平拆分 + MySQL 集群
技术和业务在发展的同时, 对人的要求也越来越高
本质: 数据库(读, 写)
早些年 MyISAM: 表锁(100万条数据), 十分影响效率! 高并发下就会出现严重的锁问题
转战 Innodb: 行锁,
慢慢的就开始使用分库分表来解决写的压力!! MySQL推出了表分区, 并没有多少公司使用
MySQL的集群, 很好的满足了那个年代的所有需求
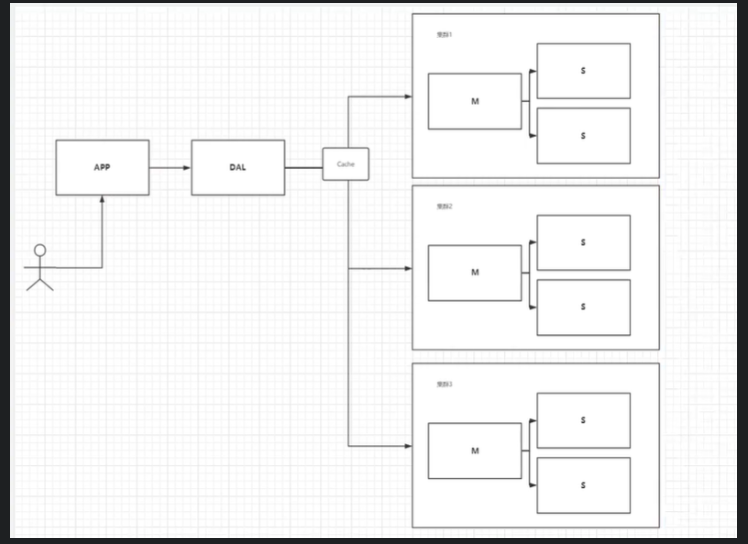
4.如今最近的年代
MySQL等关系型数据库就不够用了,数据量很多, 变化很快
图形 JSON
MySQL 有的使用它来存储一些比较大的文件, 博客, 图片, 数据库表很大, 效率就低了, 如果有一个种数据库来专门处理这种数据, MySQL压力就变得十分小(研究如何处理这些问题!) 大数据的IO压力下, 表几乎无法更改!!
目前一个基本的互联网项目!
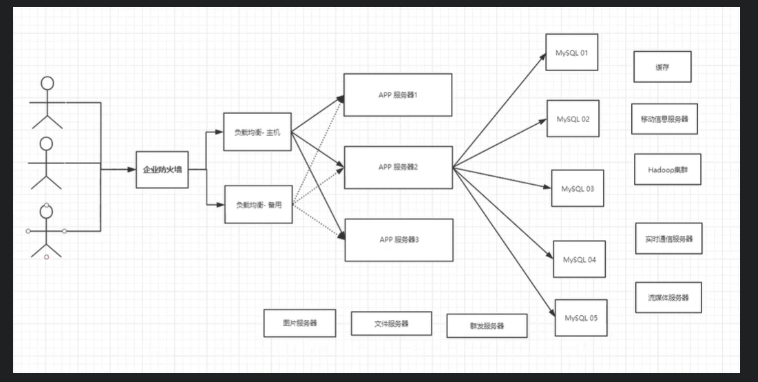
为什么要用NoSQL!
用户的个人信息, 社交网络, 地理位置, 用户自己产生的数据, 用户日志等等爆发式增长!
这时候我们就需要使用NoSQL数据库, NoSQL可以很好的处理很好的情况!
什么是NoSQL
NoSQL
NoSQL = Not Only SQL 泛指非关系型数据库,
关系型数据库: 表格, 行, 列(POI)
NoSQL特点
解耦
1.方便扩展(数据之间没有关系, 很好扩展!)
2.大数据量性能( Redis 一秒可以写8万次, 读取11万, NoSQL的缓存记录级, 是一种细粒度的缓存, 性能会比较高)
3.数据类型多样性! (不需要事先设计数据库! 随取随用, 如果是数据量十分大的表, 很多人就无法设计)
4.传统的 RDBMS和 NoSQL
传统的RDBMS
- 结构化组织
- SQL
- 数据和关系都存在单独的表中 row col
- 操作, 数据定义语言
- 基础的事务
- .....
NoSQL
- 不仅仅是数据
- 没有固定的查询语言
- 键值对存储, 列存储, 文档存储, 图形数据库(社交关系)
- 最终一致性
- CAP定理 和BASE (异地多活!) 初级架构师
- 高性能, 高可用, 高可扩展
- ......
了解 3V + 3高
大数据时代的3V: 主要是描述问题的
1.海量Volume
2.多样Variety
3.实时Velocity
大数据时代的3高: 主要是对程序的要求
- 高并发
- 高可拓
- 高性能(保证用户体验和性能!)
真正在公司中的实践, NoSQL + RDBMS 一起使用才是最强的
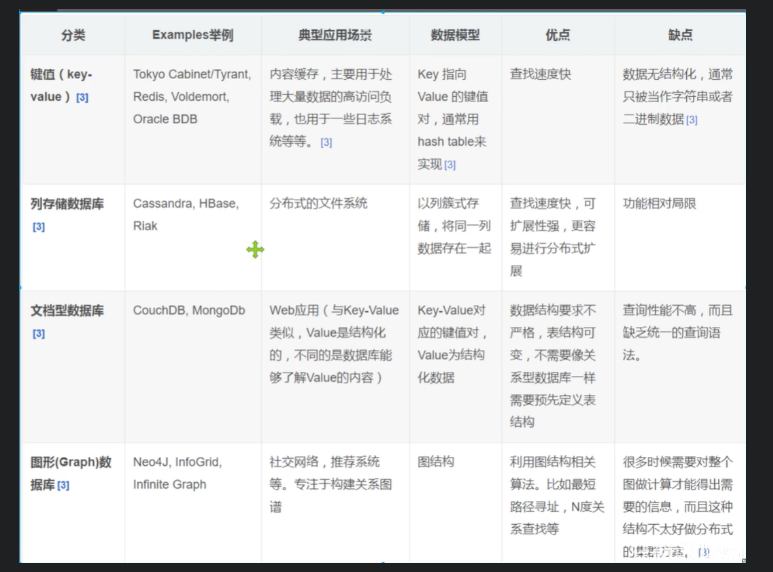
NoSQL的四大分类
KV键值对:
-
新浪: Redis
-
美团: Redis + Tair
-
阿里 、百度: Redis + Memache
文档型数据库(bson格式 和json 意义昂):
-
MongoDB(一般必须要掌握)
- MongoDB是一个基于分布式文件存储的数据库, C++编写,主要用来处理大量的文档
- MongoDB 的一个介入关系型数据库和菲关系型数据中间的产品!MongoDB的非关系型数据库中功能最丰富的, 最像关系型数据库的!
-
ConthDB
列存储数据库
- HBase
- 分布式文件系统
图型数据库
-
他不是存图形, 放的是关系, 比如: 朋友圈社交网络
-
Neo4J , InfoGrid
四者对比:
Redis
概述
Redis 是什么?
Redis(Remote Dictionary Server ),即远程字典服务!
是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。
免费和开源! 是当下最热门的NoSQL 技术之一! 也被人们称之为结构数据库!
Redis能够干嘛?
- 内存存储、持久化, 内存中是断电即失, 持久化很重要(RDB、AOF)
- 效率高, 可以用于告诉缓存
- 发布订阅系统
- 地图信息分析
- 计时器、计数器(浏览量!)
- .....
特性
- 多样的数据类型
- 持久化
- 集群
- 事务
- ....
学习中需要用到的东西
五大数据类型
Redis-Key
String
# 对象
set user:1{name:zhangsan,age:3} # 设置一个user:1 对象 值为json 字符来保存一个对象
# 这里的key是一个巧妙的设计: user:{id}:{field}
##########################
getset #先 get然后再set
127.0.0.1:6379> getset db redis #如果不存在, 则返回nil
(nil)
127.0.0.1:6379> get db
"redis"
127.0.0.1:6379> getset db mongodb # 如果存在值, 获取原来的值,并设置新的值
"redis"
127.0.0.1:6379> get db
"mongodb"
127.0.0.1:6379>
数据结构是相同的!
String类型的使用场景: value除了是我们的字符串还可以是我们的数字!
- 计数器
- 统计多单位数量 uid: 386760778:follow incr
- 粉丝数
- 对象缓存存储 !
List(列表)
基本的数据类型, 列表

在redis里面, 我们可以把list完成, 栈, 队列, 阻塞队列!
所有的list命令都是l开头的, 命令不区分大小写
#######################################################################
127.0.0.1:6379> lpush list one #lpush 将一个值或者多个值, 插入到列表的头部(左)
(integer) 3
127.0.0.1:6379> lpush list two
(integer) 4
127.0.0.1:6379> lpush list three
(integer) 5
127.0.0.1:6379> lrange list 0 -1
1) "three"
2) "two"
3) "one"
4) "two"
5) "one"
127.0.0.1:6379> lrange list 0 1
1) "three"
2) "two"
127.0.0.1:6379> rpush list five #rpush 将一个值或者多个值, 插入到列表的头部(右)
(integer) 6
127.0.0.1:6379> lrange 0 -1
(error) ERR wrong number of arguments for 'lrange' command
127.0.0.1:6379> lrange list 00 -1
1) "three"
2) "two"
3) "one"
4) "two"
5) "one"
6) "five"
#######################################################################
LPOP
RPOP
127.0.0.1:6379> lrange list 0 -1
1) "three"
2) "two"
3) "one"
4) "two"
5) "one"
6) "five"
127.0.0.1:6379> lpop list #移除list的第一个元素
"three"
127.0.0.1:6379> rpop list # 移除list的最后一个元素
"five"
127.0.0.1:6379> lrange list 0 -1
1) "two"
2) "one"
3) "two"
4) "one"
#######################################################################
Lindex
127.0.0.1:6379> lrange list 0 -1
1) "two"
2) "one"
3) "two"
4) "one"
127.0.0.1:6379> lindex list 1 # 通过下标获得list中的某一个值
"one"
127.0.0.1:6379> lindex list 0
"two"
#######################################################################
Llen
127.0.0.1:6379> lpush list one
(integer) 1
127.0.0.1:6379> lpush list two
(integer) 2
127.0.0.1:6379> lpush list three
(integer) 3
127.0.0.1:6379> llen list # 返回列表的长度
(integer) 3
#######################################################################
移除指定的值!
lrem
127.0.0.1:6379> lrange list 0 -1
1) "three"
2) "three"
3) "two"
4) "one"
127.0.0.1:6379> lrem list 1 one # 移除list集合中指定个数的value,精确匹配
(integer) 1
127.0.0.1:6379> lrange list 0 -1
1) "three"
2) "three"
3) "two"
127.0.0.1:6379> lrem list 2 three
(integer) 2
127.0.0.1:6379> lrange list 0 -1
1) "two"
#######################################################################
trim 修剪 list截断
127.0.0.1:6379> rpush mylist "hello"
(integer) 1
127.0.0.1:6379> rpush mylist "hello1"
(integer) 2
127.0.0.1:6379> rpush mylist "hello2"
(integer) 3
127.0.0.1:6379> rpush mylist "hello3"
(integer) 4
127.0.0.1:6379> ltrim mylist 1 2 # 通过下标截取指定的长度, 这个list已经被改变, 截断了只剩下截取的元素!
OK
127.0.0.1:6379> lrange mylist 0 -1
1) "hello1"
2) "hello2"
#######################################################################
rpoplpush # 移除列表的最后一个元素, 将他移动到新的列表中!
127.0.0.1:6379> rpush mylist hello
(integer) 1
127.0.0.1:6379> rpush mylist hello1
(integer) 2
127.0.0.1:6379> rpush mylist hello2
(integer) 3
127.0.0.1:6379> rpoplpush mylist mylist2 # 移除列表的最后一个元素, 将他移动到新的列表中!
"hello2"
127.0.0.1:6379> lrange mylist 0 -1 # 查看原来的列表
1) "hello"
2) "hello1"
127.0.0.1:6379>
127.0.0.1:6379> lrange mylist2 0 -1 # 查看目标列表中,确实存在值
1) "hello2"
#######################################################################
lset 将列表中指定下标的值替换为另外一个值, 更新操作
127.0.0.1:6379> exists list # 判断这个列表是否存在
127.0.0.1:6379> lpush list value
(integer) 1
127.0.0.1:6379> lrange list 0 -1
1) "value"
127.0.0.1:6379> lset list 0 key # 如果存在, 更新当前下标的值
OK
127.0.0.1:6379> lrange list 0 -1
1) "key"
127.0.0.1:6379> lset list 1 value # 如果不存在列表(或者列表下标),更新就会保存
(error) ERR index out of range
#######################################################################
linsert # 将某个具体的value插入到列表中某个元素的前面或者后面
127.0.0.1:6379> rpush mylist hello
(integer) 1
127.0.0.1:6379> rpush mylist world
(integer) 2
127.0.0.1:6379> linsert mylist before world other
(integer) 3
127.0.0.1:6379> lrange mylist 0 -1
1) "hello"
2) "other"
3) "world"
127.0.0.1:6379> linsert mylist after world new
(integer) 4
127.0.0.1:6379> lrange mylist 0 -1
1) "hello"
2) "other"
3) "world"
4) "new"
小结
- 实际上是一个链表, before Node after, left , right都可以插入值
- 如果key不存在, 创建新的链表
- 如果key存在, 新增内容
- 如果移除了所有值, 空链表也代表不存在
- 在两边插入或者改动值, 效率最高! 中间元素, 相对来说, 效率会低一点.
Set(集合)
set中的值是无序不能重复的!
#######################################################################
127.0.0.1:6379> sadd myset hello # set集合中添加元素
(integer) 1
127.0.0.1:6379> sadd myset wangjc
(integer) 1
127.0.0.1:6379> sadd myset wangjc666
(integer) 1
127.0.0.1:6379> smembers myset # 查看指定set的所有值
1) "hello"
2) "wangjc"
3) "wangjc666"
127.0.0.1:6379> sismember myset hello # 判断一个值是不是在set集合中
(integer) 1
127.0.0.1:6379> sismember myset world
(integer) 0
#######################################################################
127.0.0.1:6379> scard myset # 获取set集合中的内容元素个数!
(integer) 4
#######################################################################
rem
127.0.0.1:6379> srem myset hello # 移除set集合中的指定元素
(integer) 1
127.0.0.1:6379> scard myset
(integer) 3
127.0.0.1:6379> smembers myset
1) "wangjc"
2) "wangjc888"
3) "wangjc666"
#######################################################################
127.0.0.1:6379> smembers myset
1) "wangjc"
2) "wangjc888"
3) "wangjc666"
127.0.0.1:6379> SRANDMEMBER myset # 随机抽选出一个元素
"wangjc888"
127.0.0.1:6379> SRANDMEMBER myset
"wangjc"
127.0.0.1:6379> SRANDMEMBER myset 2 # 随机抽选出指定个数的元素
1) "wangjc666"
2) "wangjc888"
#######################################################################
删除指定的key , 随机删除key
127.0.0.1:6379> SMEMBERS myset
1) "wangjc"
2) "wangjc888"
3) "wangjc666"
127.0.0.1:6379> SPOP myset # 随机删除一些set集合中的元素!
"wangjc"
127.0.0.1:6379> SPOP myset
"wangjc666"
127.0.0.1:6379> SMEMBERS myset
1) "wangjc888"
#######################################################################
将一个指定的值, 移动到另外一个set集合中
127.0.0.1:6379> SADD myset hello
(integer) 1
127.0.0.1:6379> SADD myset world
(integer) 1
127.0.0.1:6379> SADD myset wangjc
(integer) 1
127.0.0.1:6379> SADD myset2 set2
(integer) 1
127.0.0.1:6379> SMOVE myset myset2 wangjc # 将一个指定的值, 移动到另外一个set集合中
(integer) 1
127.0.0.1:6379> SMEMBERS myset
1) "hello"
2) "world"
127.0.0.1:6379> SMEMBERS myset2
1) "set2"
2) "wangjc"
#######################################################################
数字集合类:
- 差集 sdiff
- 交集 sinter
- 并集 sunion
127.0.0.1:6379> SADD key1 a
(integer) 1
127.0.0.1:6379> SADD key1 b
(integer) 1
127.0.0.1:6379> SADD key1 c
(integer) 1
127.0.0.1:6379> SADD key2 c
(integer) 1
127.0.0.1:6379> SADD key2 d
(integer) 1
127.0.0.1:6379> SADD key2 e
(integer) 1
127.0.0.1:6379> SDIFF key1 key2 # 差集
1) "a"
2) "b"
127.0.0.1:6379> SINTER key1 key2 # 交集 共同好友可以这样实现
1) "c"
127.0.0.1:6379> SDIFF key2 key1
1) "d"
2) "e"
127.0.0.1:6379> SUNION key1 key2 # 并集
1) "a"
2) "c"
3) "b"
4) "d"
5) "e"
Hash(哈希)
Map 集合, key-Map 这个值是一个map集合! 本质和String类型没有太大区别, 还是一个简单的key-value!
set myhash field wangjc
127.0.0.1:6379> hset myhash field wangjc # set 一个具体的 key-value
(integer) 1
127.0.0.1:6379> hget myhash field # 获取一个字段值
"wangjc"
127.0.0.1:6379> HMSET myhash field hello field2 world # set 多个 key-value
OK
127.0.0.1:6379> HMGET myhash field field2 # 获取多个字段值
1) "hello"
2) "world"
127.0.0.1:6379> HGETALL myhash # 获取全部的数据
1) "field"
2) "hello"
3) "field2"
4) "world"
127.0.0.1:6379> HDEL myhash field # 删除hash 指定的key字段! 对应的value值也就消失了!
(integer) 1
127.0.0.1:6379> HGETALL myhash
1) "field2"
2) "world"
#######################################################################
127.0.0.1:6379> HMSET myhash field1 hello
OK
127.0.0.1:6379> HGETALL myhash
1) "field2"
2) "world"
3) "field1"
4) "hello"
127.0.0.1:6379> HLEN myhash # 获取hash的 字段数量
(integer) 2
#######################################################################
127.0.0.1:6379> HEXISTS myhash field1 # 判断hash中指定字段是否存在
(integer) 1
127.0.0.1:6379> HEXISTS myhash field3 # 判断hash中指定字段是否存在
(integer) 0
#######################################################################
127.0.0.1:6379> HKEYS myhash # 只获得所有field
1) "field2"
2) "field1"
127.0.0.1:6379> HVALS myhash # 只获得所有value
1) "world"
2) "hello"
#######################################################################
incr decr
127.0.0.1:6379> hset myhash field3 5
(integer) 1
127.0.0.1:6379> HINCRBY myhash field3 1 # 指定增量
(integer) 6
127.0.0.1:6379> HSETNX myhash field4 hello # 如果不存在则可以设置
(integer) 1
127.0.0.1:6379> HSETNX myhash field4 hello # 如果存在则可以设置
(integer) 0
hash 变更的数据 user name age, 尤其 是用户信息之类的, 经常变动的信息, hash更适合于对象 的存储, String更适合字符串存储!
Zset(有序集合)
在set的基础上, 增加了一个值, set k1 v1 zset k1 score v1
127.0.0.1:6379> ZADD myset 1 one # 添加一个值
(integer) 1
127.0.0.1:6379> ZADD myset 2 two
(integer) 1
127.0.0.1:6379> ZADD myset 3 three 4 four #添加多个值
(integer) 2
127.0.0.1:6379> ZRANGE myset 0 -1
1) "one"
2) "two"
3) "three"
4) "four"
#######################################################################
排序如何实现
127.0.0.1:6379> zadd salary 2500 xiaohong # 添加三个用户
(integer) 1
127.0.0.1:6379> zadd salary 5000 zhangsan
(integer) 1
127.0.0.1:6379> zadd salary 500 wangjc
(integer) 1
127.0.0.1:6379> ZRANGEBYSCORE salary -inf +inf # 显示全部用户 从小到大
1) "wangjc"
2) "xiaohong"
3) "zhangsan"
127.0.0.1:6379> ZREVRANGE salary 0 -1 # 从大到小进行排序!
1) "zhangsan"
2) "wangjc"
127.0.0.1:6379> ZRANGEBYSCORE salary -inf +inf withscores # 显示全部用户并且附带成绩 ,
1) "wangjc"
2) "500"
3) "xiaohong"
4) "2500"
5) "zhangsan"
6) "5000"
127.0.0.1:6379> ZRANGEBYSCORE salary -inf 2500 withscores # 显示工资小于2500用户的 升序
1) "wangjc"
2) "500"
3) "xiaohong"
4) "2500"
#######################################################################
移除 zset中的元素
127.0.0.1:6379> zrange salary 0 -1
1) "wangjc"
2) "xiaohong"
3) "zhangsan"
127.0.0.1:6379> zrem salary xiaohong # 移除有序集合中的元素
(integer) 1
127.0.0.1:6379> zrange salary 0 -1
1) "wangjc"
2) "zhangsan"
127.0.0.1:6379> ZCARD salary # 获取有序集合中的个数
(integer) 2
#######################################################################
127.0.0.1:6379> zadd myset 1 hello
(integer) 1
127.0.0.1:6379> zadd myset 2 world 3 wangjc
(integer) 2
127.0.0.1:6379> zcount myset 1 3 # 获取指定区间的成员数量!
(integer) 3
127.0.0.1:6379> zcount myset 1 2
(integer) 2
其余的一些API, 查官方文档!
案例思路: Zset( sorted set) 排序 , 存储班级成绩表, 工资表排序,
普通消息1 , 重要消息2 , 带权重进行判断,
排行榜应用实现, 取 Top N 测试
三种特殊数据类型
geospatial 地址位置
朋友的定位, 附近的人, 打车距离计算?
Redis的 geospatial在Redis3.2版本就推出了! 这个功能可以推算出地理位置的信息, 两地之间的距离,方圆几里的人!
可以查询一些测试数据
只有六个命令

getadd
# geoadd 添加地理位置
# 规则:两级无法直接添加, 我们一般慧下载城市数据, 直接通过java程序一次性导入
# 参数 key 值 (经度、维度、)
127.0.0.1:6379> GEOADD china:city 116.40 39.90 beijing
(integer) 1
127.0.0.1:6379> geoadd china:city 121.47 31.23 shanghai
(integer) 1
127.0.0.1:6379> GEOADD china:city 106.50 29.53 chongqing 114.05 22.52 shenzhen
(integer) 2
127.0.0.1:6379> GEOADD china:city 120.16 30.24 hangzhou 108.96 34.26 xian
(integer) 2
geopos
获得当前定位: 一定是一个坐标值!
127.0.0.1:6379> GEOPOS china:city beijing # 获取指定城市的经纬度
1) 1) "116.39999896287918"
2) "39.900000091670925"
127.0.0.1:6379> GEOPOS china:city shanghai shenzhen hangzhou
1) 1) "121.47000163793564"
2) "31.229999039757836"
2) 1) "114.04999762773514"
2) "22.520000087950386"
3) 1) "120.16000002622604"
2) "30.240000322949022"
geodist
两人之间的距离!
单位:
- m 表示单位为米。
- km 表示单位为千米。
- mi 表示单位为英里。
- ft 表示单位为英尺
127.0.0.1:6379> GEODIST china:city shanghai beijing # 查看上海 到北京的直线距离
"1067378.7564"
127.0.0.1:6379> GEODIST china:city shanghai beijing km
"1067.3788"
127.0.0.1:6379> GEODIST china:city beijing chongqing # 查看上海 到北京的直线距离
"1464070.8051"
127.0.0.1:6379> GEODIST china:city beijing chongqing km
"1464.0708"
georadius - 以给定的经纬度为中心, 找出某一半径内的元素
我附近的人, (获得所有附近的人的地址, 定位! )通过半径来查询!
获取指定数量的人
所有数据应该都输入:china:city , 才会让结果请求!
127.0.0.1:6379> GEORADIUS china:city 110 30 1000 km # 获取110 30经纬度为中心, 寻找方圆1000km内的城市
1) "chongqing"
2) "xian"
3) "shenzhen"
4) "hangzhou"
127.0.0.1:6379> GEORADIUS china:city 110 30 500 km
1) "chongqing"
2) "xian"
127.0.0.1:6379> GEORADIUS china:city 110 30 500 km withdist # 显示到中心距离的位置,
1) 1) "chongqing"
2) "341.9374"
2) 1) "xian"
2) "483.8340"
127.0.0.1:6379> GEORADIUS china:city 110 30 500 km withcoord # 显示他人的定位信息, ,
1) 1) "chongqing"
2) 1) "106.49999767541885"
2) "29.529999579006592"
2) 1) "xian"
2) 1) "108.96000176668167"
2) "34.2599996441893"
127.0.0.1:6379> GEORADIUS china:city 110 30 500 km withdist withcoord count 1 # 筛选出指定的结果!
1) 1) "chongqing"
2) "341.9374"
3) 1) "106.49999767541885"
2) "29.529999579006592"
127.0.0.1:6379> GEORADIUS china:city 110 30 500 km withdist withcoord count 2
1) 1) "chongqing"
2) "341.9374"
3) 1) "106.49999767541885"
2) "29.529999579006592"
2) 1) "xian"
2) "483.8340"
3) 1) "108.96000176668167"
2) "34.2599996441893"
GEORADIUSBYMEMBER 命令 - 找出位于指定范围内的元素,中心点是由给定的位置元素决定
# 找到位于指定元素周围的其他元素!
127.0.0.1:6379> GEORADIUSBYMEMBER china:city beijing 1000 km
1) "beijing"
2) "xian"
127.0.0.1:6379> GEORADIUSBYMEMBER china:city shanghai 400 km
1) "hangzhou"
2) "shanghai"
GEOHASH 命令 - 返回一个或多个位置元素的 Geohash 表示
该命令将返回11个字符的GeoHash字符串!
# 将二维的经纬度转为 一维的字符串, 如果两个字符串越近, 那么则距离越近!
127.0.0.1:6379> GEOHASH china:city beijing shanghai
1) "wx4fbxxfke0"
2) "wtw3sj5zbj0"
GEO底层的实现原理其实就是Zset, 可以用Zset命令来操作GEO
127.0.0.1:6379> ZRANGE china:city 0 -1 # 查看地图中全部元素
1) "chongqing"
2) "xian"
3) "shenzhen"
4) "hangzhou"
5) "shanghai"
6) "beijing"
127.0.0.1:6379> ZREM china:city beijing # 移除指定元素
(integer) 1
127.0.0.1:6379> ZRANGE china:city 0 -1
1) "chongqing"
2) "xian"
3) "shenzhen"
4) "hangzhou"
Hyperloglog
什么是基数?
A {1 , 3, 5, 7,8,7}
B{ 1, 3, 5, 7, 8 }
基数( 不重复的元素) = 5, 可以接受误差
简介
Redis2.8.9 版本就更新了Hyperloglog 数据结构!
Redis Hyperloglog基数统计的算法!
优点: 占用内存是固定的, 2∧64不同的元素的基数, 只需要消耗12kb内存! 如果从内存角度来比较的话, Hyperloglog是首选!
网页的UV(一个人访问一个网站多次, 算做一个人)
传统的方式, set保存用户的id, 然后就可以统计set中的元素数量作为标准判断!
这个方式如果保存大量的用户id, 就会比较麻烦! 我们的目的是为了计数, 而不是保存用户id;
0.81% 错误率!, 统计UV任务, 可以忽略不计!
测试使用
127.0.0.1:6379> ping
PONG
127.0.0.1:6379> PFADD mykey a b c d e f g h i j # 创建第一组元素 mykey
(integer) 1
127.0.0.1:6379> PFCOUNT mykey # 统计mykey 元素的基数数量
(integer) 10
127.0.0.1:6379> pfadd mykey2 i j z x c v b n m # 创建第二组元素 mykey2
(integer) 1
127.0.0.1:6379> PFCOUNT mykey2
(integer) 9
127.0.0.1:6379> PFMERGE mykey3 mykey mykey2 # 合并两组mykey mykey2 => mykey3并集
OK
127.0.0.1:6379> PFCOUNT mykey3 # 看并集的数量
(integer) 15
如果允许容错, 那么一定可以使用Hyperloglog!
如果不允许容错, 就使用set或者自己的数据类型即可!
BitMap
位存储
疫情感染人数: 0 1 0 1; 统计用户信息, 活跃, 不活跃 ; 登录、未登录!; 打卡, 365打卡!
BitMaps 位图, 数据结构! 都是操作二进制位来进行记录, 就只有0和1两个状态!
测试
使用bigtmap来记录周一到周日的打卡
周一: 1, 周二: 0, 周三: 0 , 周四: 1 ....
127.0.0.1:6379> setbit sign 0 1
(integer) 0
127.0.0.1:6379> setbit sign 1 0
(integer) 0
127.0.0.1:6379> setbit sign 2 0
(integer) 0
127.0.0.1:6379> setbit sign 3 1
(integer) 0
127.0.0.1:6379> setbit sign 4 1
(integer) 0
127.0.0.1:6379> setbit sgign 5 0
(integer) 0
127.0.0.1:6379> setbit sign 6 0
(integer) 0
查看某一天是否有打卡!
127.0.0.1:6379> getbit sign 3
(integer) 1
127.0.0.1:6379> getbit sign 6
(integer) 0
统计操作: 统计打卡天数
127.0.0.1:6379> bitcount sign # 统计这周的打卡记录 .就可以看到是否有全勤!
(integer) 3
事务
事务本质: 一组命令的集合! 一个事务中的所有命令都会被序列化, 在事务执行过程中, 会按照顺序执行!
一次性、顺序性、排他性!执行一些列的命令!
---- 队列 set set set 执行 -----
Redis事务没有隔离级别的概念!
所有的命令在事务中 , 并没有直接被执行, 只有在发起执行命令的时候才会执行.
Redis单条命令是保存原子性的, 但是事务不保证原子性.
redis的事务:
- 开启事务 ( multi )
- 命令入队 ( ... )
- 执行事务 ( exec )
正常执行事务!
127.0.0.1:6379> multi # 开启事务
OK
# 命令入队
127.0.0.1:6379> set k1 v1
QUEUED
127.0.0.1:6379> set k2 v2
QUEUED
127.0.0.1:6379> set k3 v3
QUEUED
127.0.0.1:6379> exec # 执行事务
1) OK
2) OK
3) OK
放弃事务
127.0.0.1:6379> multi # 开启事务
OK
127.0.0.1:6379> set k1 v1
QUEUED
127.0.0.1:6379> set k2 v2
QUEUED
127.0.0.1:6379> set k4 v4
QUEUED
127.0.0.1:6379> discard # 取消事务
OK
127.0.0.1:6379> get k4 # 事务队伍中的命令都不会被执行!
(nil)
编译型异常( 代码有问题, 命令出错!), 事务中所有的命令都不会被执行!
127.0.0.1:6379> multi
OK
127.0.0.1:6379> set k1 v1
QUEUED
127.0.0.1:6379> set k2 v2
QUEUED
127.0.0.1:6379> set k3 v3
QUEUED
127.0.0.1:6379> getset k3 # 错误的命令
(error) ERR wrong number of arguments for 'getset' command
127.0.0.1:6379> set k4 v4
QUEUED
127.0.0.1:6379> set k5 v5
QUEUED
127.0.0.1:6379> exec # 执行事务 报错!
(error) EXECABORT Transaction discarded because of previous errors.
127.0.0.1:6379> get k1 # 所有命令都不会被执行
(nil)
运行时异常( 1/0) , 如果事务中队列中存在语法性, 那么执行命令的时候, 其他命令是可以正常执行的, 错误命令抛出异常
127.0.0.1:6379> set k1 "v1"
OK
127.0.0.1:6379> multi
OK
127.0.0.1:6379> incr k1 # 执行的时候会失败
QUEUED
127.0.0.1:6379> set k2 v2
QUEUED
127.0.0.1:6379> set k3 v3
QUEUED
127.0.0.1:6379> get k3
QUEUED
127.0.0.1:6379> exec
1) (error) ERR value is not an integer or out of range # 虽然第一条命令报错了, 但是其他命令依旧正常执行成功了!
2) OK
3) OK
4) "v3"
127.0.0.1:6379> get k2
"v2"
127.0.0.1:6379> get k3
"v3"
监控! watch ( 面试常问! ! ! )
悲观锁:
- 很悲观, 什么时候都会出问题, 无论做什么都会加锁!
乐观锁:
-
很乐观, 认为什么时候都不会出问题, 所以不会上锁! 更新数据的时候, 去判断下, 在此期间, 是否有人修改过数据,
-
获取version ,
-
更新的时候比较version
Redis测监视测试
正常执行成功!
127.0.0.1:6379> set money 100
OK
127.0.0.1:6379> set out 0
OK
127.0.0.1:6379> WATCH money # 监听money对象
OK
127.0.0.1:6379> multi
OK
127.0.0.1:6379> decrby money 20
QUEUED
127.0.0.1:6379> incrby out 20
QUEUED
127.0.0.1:6379> exec # 事务正常结束, 数据期间没有发生变动, 这个时候就正常执行成功!
1) (integer) 80
2) (integer) 20
测试多线程修改值, 使用watch 可以当做redis 的 乐观锁操作, 监视失败,
127.0.0.1:6379> watch money # 监视 money
OK
127.0.0.1:6379> multi
OK
127.0.0.1:6379> decrby money 10
QUEUED
127.0.0.1:6379> incrby out 10
QUEUED
127.0.0.1:6379> exec # 执行之前, 另外一个线程, 修改了我们的值, 这个时候, 就会导致事务执行失败!
(nil)
如果需改失败, 获取最新的值就好
Jedis
什么是Jedis, 是Redis官方推荐的java连接开发工具, 使用java操作Redis中间件, 如果要使用java操作redis , 那么一定要对Jedis十分熟悉!
测试
1.导入对应 的依赖
<!--导入 jedis 的依赖-->
<dependencies>
<!-- https://mvnrepository.com/artifact/redis.clients/jedis -->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.9.0</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.62</version>
</dependency>
</dependencies>
- 编码测试:
- 连接数据库
- 操作命令
- 断开连接
package com.wangjc;
import redis.clients.jedis.Jedis;
public class TestPing {
public static void main(String[] args) {
/*1. new Jedis 对象即可*/
Jedis jedis = new Jedis("127.0.0.1",6379);
/* jedis 所有的命令就是之前学习的所有指令*/
System.out.println(jedis.ping());
}
}
输出

常用API
String
List
Set
Hash
Zset
所有的API命令,
事务
SpringBoot整合
整合测试下
说明: 在SpringBoot2.x之后, 原来使用个的jedis被替换为了 lettuce
jedis: 采用的直连, 多个线程操作的话 , 是不安全的 . 如果想要避免不安全的, 使用jedis pool连接池 更像 BIO 模式
lettuce : 采用 netty, 实例可以在多个线程中进行共享, 不存在线程不安全的情况! 可以减少线程连接池数量, 更像NIO模式
源码分析:
@Bean
@ConditionalOnMissingBean(
name = {"redisTemplate"}
) // 可以自己定义一个 redisTemplate 来替换这个默认的
public RedisTemplate<Object, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) throws UnknownHostException {
// 默认的RedisTemplate 没有过多的设置, redis对象都是需要序列化的
// 两个泛型都是Object, Object类型, 我们后使用需要强制转换<string,Object>
RedisTemplate<Object, Object> template = new RedisTemplate();
template.setConnectionFactory(redisConnectionFactory);
return template;
}
@Bean
@ConditionalOnMissingBean // 由于string 是redis中最常使用的类型, 所以说单独提出来了一个bean
public StringRedisTemplate stringRedisTemplate(RedisConnectionFactory redisConnectionFactory) throws UnknownHostException {
StringRedisTemplate template = new StringRedisTemplate();
template.setConnectionFactory(redisConnectionFactory);
return template;
}
整合测试
1.导入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
2.配置连接
# 配置redis
spring.redis.host=127.0.0.1
spring.redis.port=6379
spring.redis.database=0
3.测试
package com.wangjc;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.redis.core.RedisTemplate;
@SpringBootTest
class Redis02SpringbootApplicationTests {
@Autowired
private RedisTemplate redisTemplate;
@Test
void contextLoads() {
// redisTemplate 操作不同的数据类型, api和我们的智力高
// opsForValue() 操作字符串 类似string
// opsForList() 操作字符串 类似list
// opsForSet()
// opsForHash()
// opsForZSet()
// opsForGeo()
// opsForHyperLogLog()
// 除了基本的操作 , 我们常用的方法都可以通过 redisTemplate 操作, 比如 事务 , 和基本的crud
// 获取redis连接对象
// RedisConnection connection = redisTemplate.getConnectionFactory().getConnection();
// connection.flushAll();;
// connection.flushDb();
redisTemplate.opsForValue().set("mykey","kuangshen");
System.out.println(redisTemplate.opsForValue().get("mykey"));
}
}

