
爬虫学习记录(上)
爬虫学习记录
专栏·专家说法⑱|张明楷:破坏计算机信息系统罪的认定
准备流程
-
准备工作
通过浏览器查看分析目标网页,学习编程基础规范。
-
获取数据
通过HTTP库向目标站点发起请求,请求可以包含额外的header等信息,如果服务器能正常响应,会得到一个Response,便是所要获取的页面内容。
-
解析内容
得到的内容可能是HTML、json等格式,可以用页面解析库、正则表达式等进行解析。
-
保存数据
保存形式多样,可以存为文本,也可以保存到数据库,或者保存特定格式的文件。
编码规范
-
程序第一行加入编码格式使得代码可以包含中文
#-*-coding:utf-8-*- #coding=utf-8 -
加入main函数来测试程序
if _name_=="_main_": -
使用def的函数代码块来实现单一功能或相关联功能
def add(x,y): return x+y -
添加注释来说明代码段的作用
print("hello world") # 在控制台打印hello world
web请求过程解析
基础请求
发送一次请求
访问网址 => 服务器渲染:检索数据并拼装成html => 服务器响应html文件发送回来 => 浏览器渲染html为页面

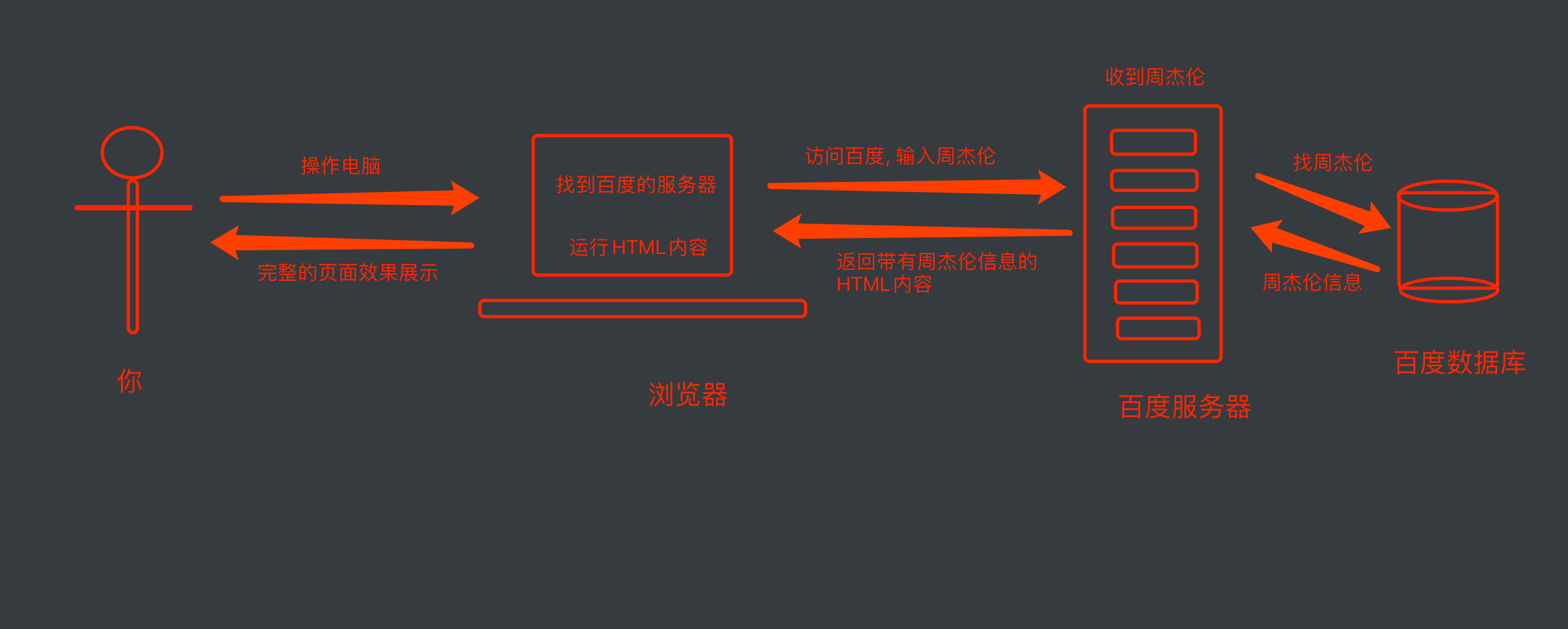
进阶请求
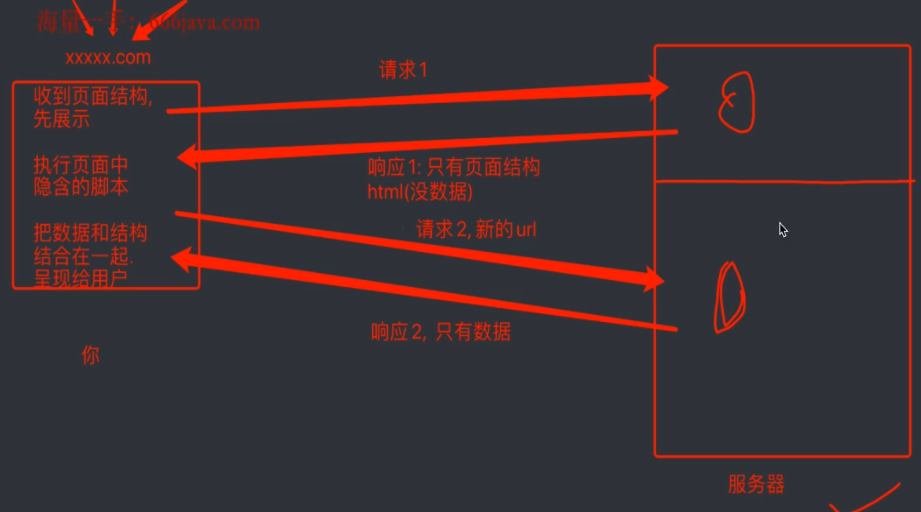
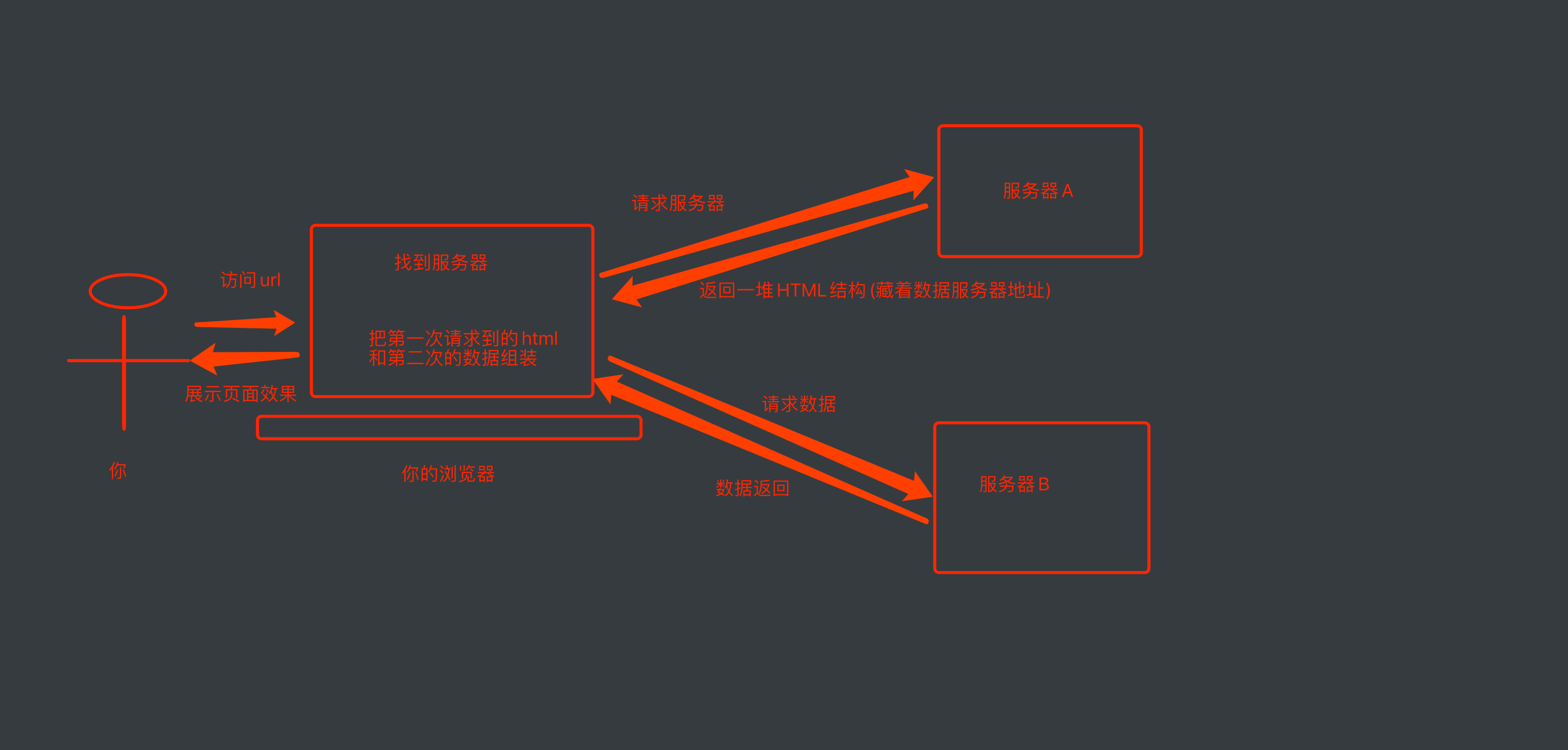
发送两次请求
- 请求页面html框架:源代码
- 请求页面数据
DevTools介绍
小箭头
寻找控件对应代码在元素中的位置
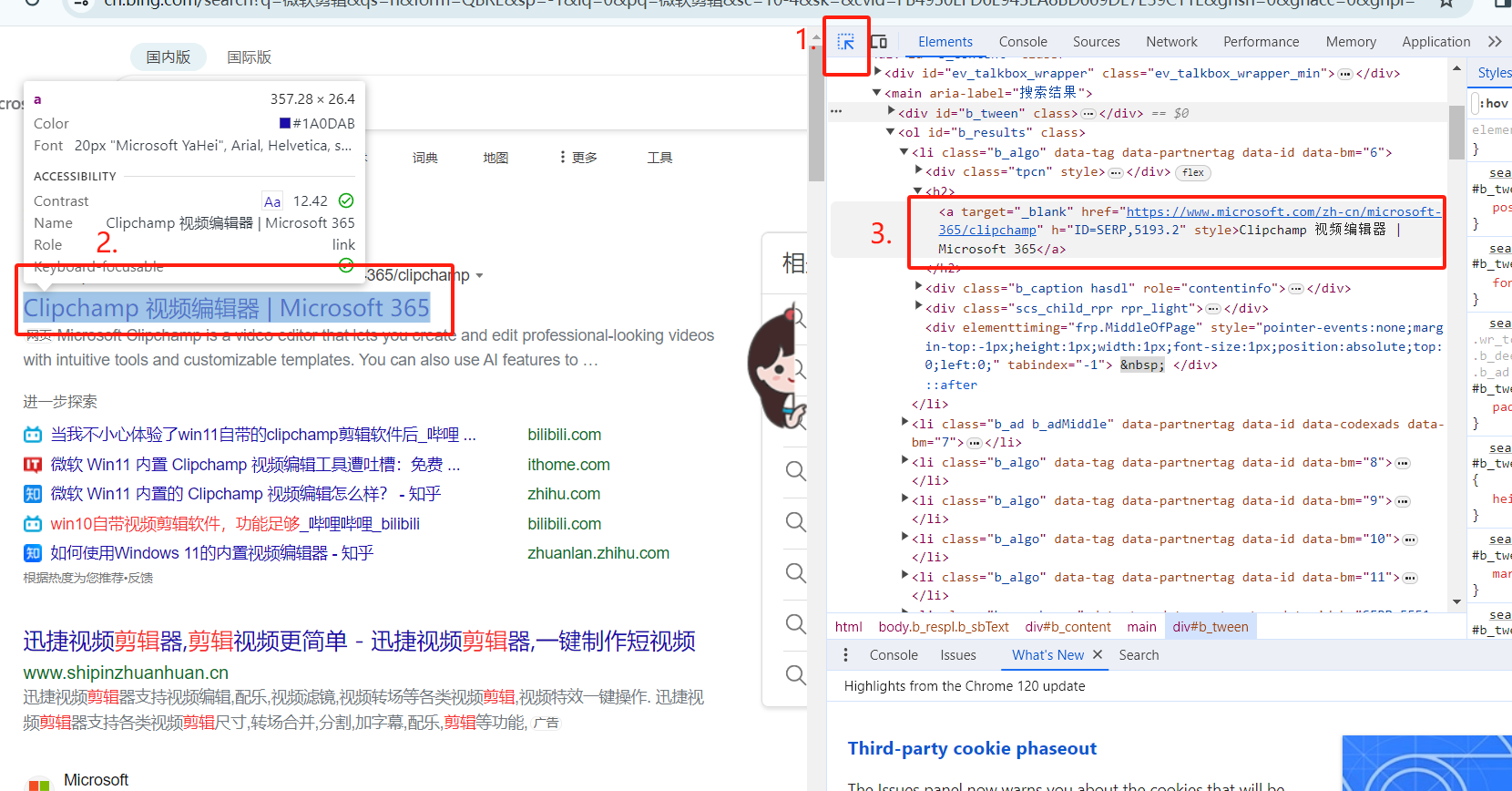
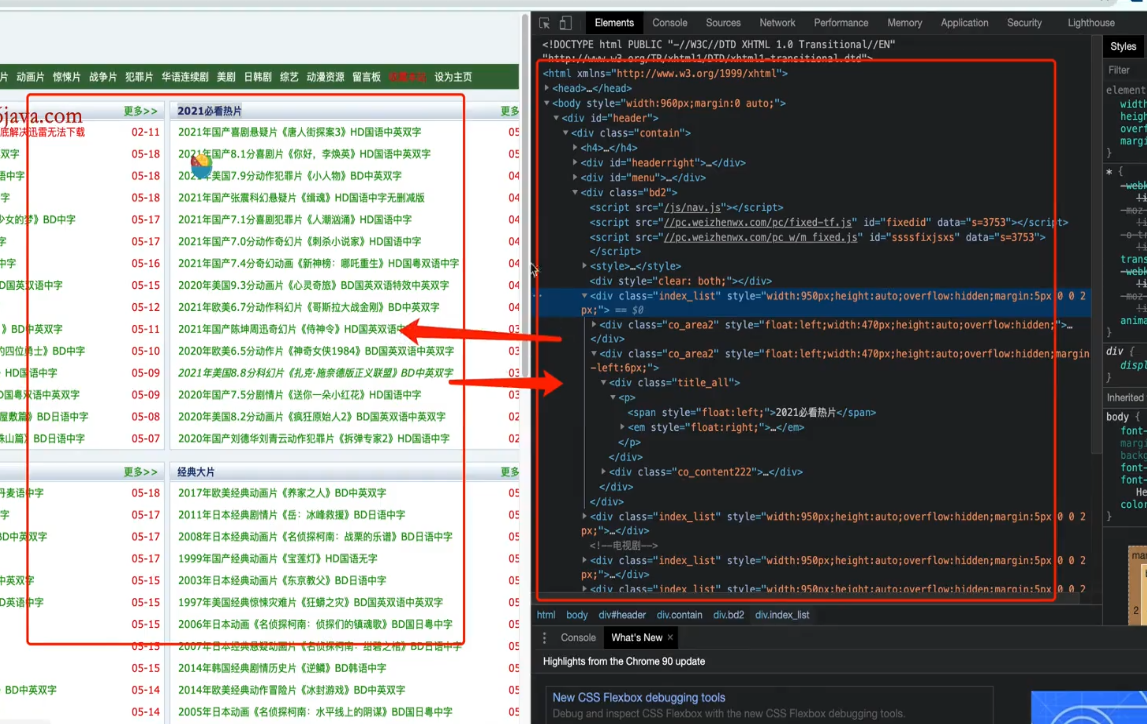
Elements
元素,实时的页面内容对比,但不等于源代码(因为此elements中有页面自带脚本实时改变网页内容)。
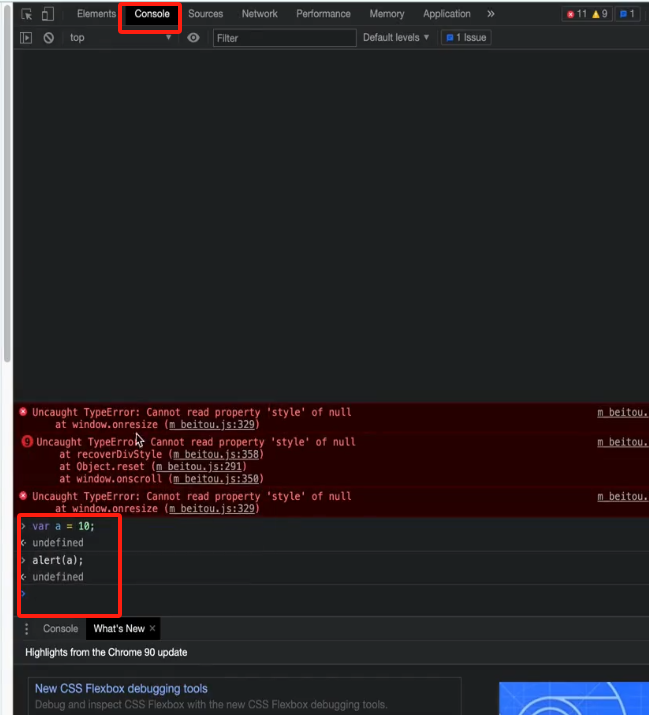
Console
控制台,可输入JavaScript代码进行调试网页。
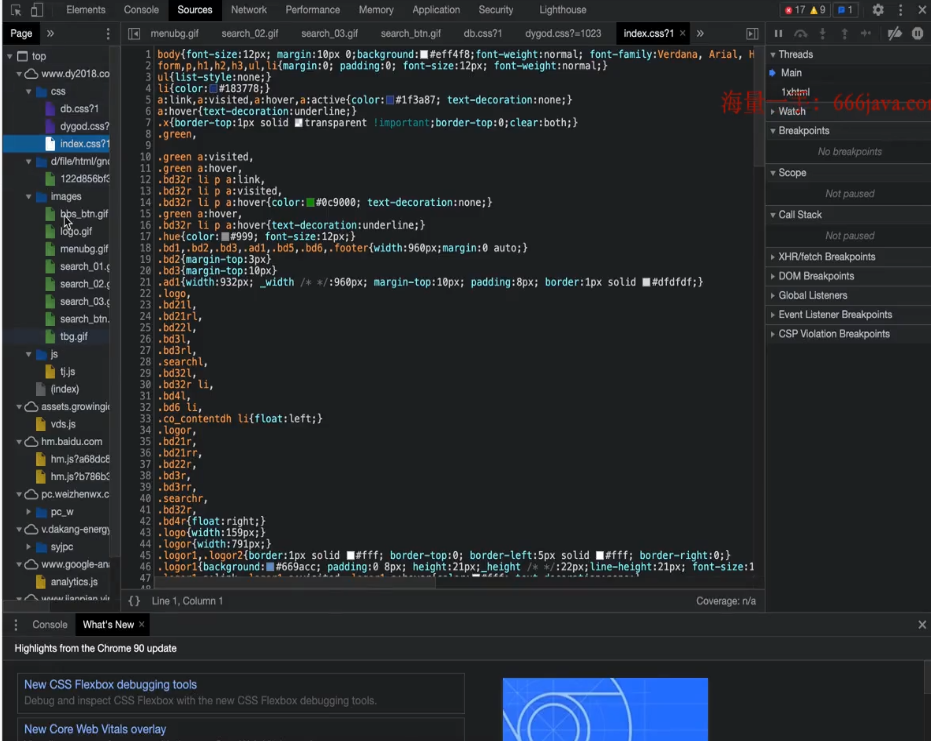
Sources
整个页面涉及到或使用到的所有的资源(包括页面源代码html框架、css样式、js脚本、其他网页)。
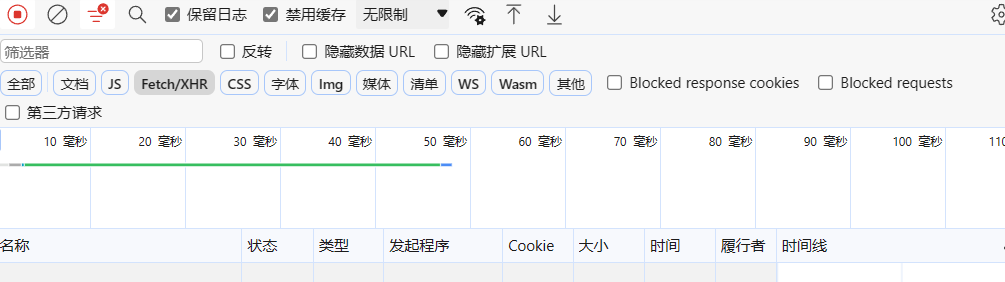
Network
体现请求的整个执行过程,包括加载静态CSS、JS、HTTP请求与响应标头和Cookie、响应状态码等等
面板组成

- 控制器:控制Network面板的外观和功能
- 过滤器:控制列表中显示的资源。【按住Ctrl并点击过滤器可以同时选择多个过滤器】
- 概览:显示资源检索时间的时间线。如果看到多条竖线堆叠在一起,则说明这些资源被同时检索
- 请求列表:默认时间排序,可选择显示列;显示所有资源请求(包括网络请求,图片资源,html、css、js文件等请求),可以根据需求筛选请求项,一般多用于网络请求的查看和分析,分析后端接口是否正确传输,获取的数据是否准确,请求头,请求参数的查看
- 概要:显示请求总数、传输数据量和加载总时间
控制器
- 红色按钮:开始/停止记录网络日志
- 清除按钮:清除网络日志
- Preserve log:保留网络日志【建议打开,便于对比分析请求】
- Disable cache:禁用缓存【建议打开,防止缓存中内容重复加载而分析不到cookies参数】
过滤器
- XHR:网络请求中的数据资源

对比翻译:
请求列表

- Name :资源名称
- Status:HTTP状态代码
- Type:请求的资源的MIME类型
- Initiator:发起请求的对象或进程。它可能有以下几种值:
- Parser(解析器):Chrome的HTML解析器发起了请求
- Redirect(重定向):HTTP重定向启动了请求
- Script(脚本): 脚本启动了请求
- Other(其他):一些其他进程或动作发起请求,例如用户点击链接跳转到页面,或在地址栏中输入网址
- Size:响应头的大小(通常是几百字节)加上响应数据,由服务器提供
- Time: 总持续时间,从请求的开始到接收响应中的最后一个字节
- Timeline:Timeline 列显示所有网络请求的视觉瀑布。点击此列的标题栏会显示其他排序字段的菜单
单个资源的详细信息

- Hearder:与资源相关的HTTP头。
- Preview:预览JSON,图片和文字资源。
- Response :HTTP响应数据(如果有)。
- Timeing:资源的请求的生命周期的明细分类。
- Cookies:某些网站为了辨别用户身份,储存在用户本地终端上的数据(通常经过加密),由用户客户端计算机暂时或永久保存的信息
- Initiator等
Headers
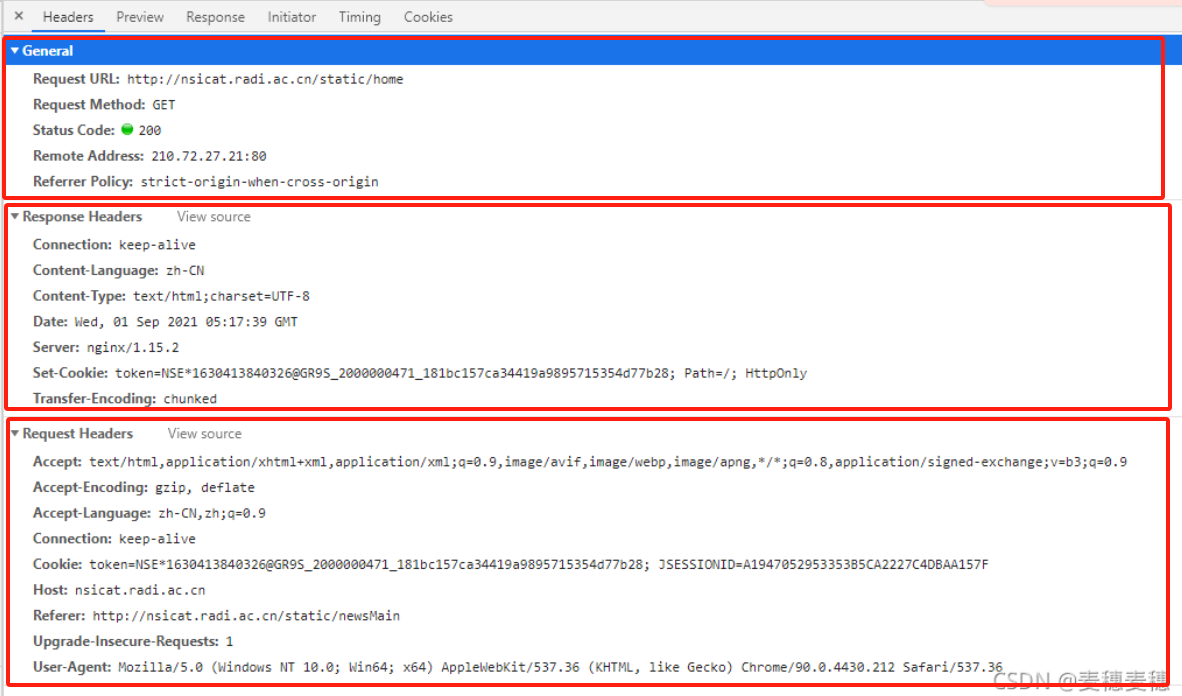
-
General
- Request URL:资源的请求url
- Request Method:请求方式 GET /POST
- Status Code:HTTP状态码(200,OK)
- Remote Address :请求地址
- Referrer Policy: 为了控制请求头中的referrer的内容(有多个属性值)
-
Response Headers
-
Connection:连接方式有两种 :keep-alive/close (保持长链接/重新建立一个请求)
-
Content-Language: 响应数据的自然语言 【例如:zh-CN】
-
Content-Type:服务器告诉浏览器它发送的数据属于什么文件类型【例如:text/html;charset=UTF-8】
-
Date:响应消息发送的GMT格式日期 【例如:Wed, 01 Sep 2021 05:17:39 GMT】
-
Server:服务器的名称 【例如:nginx/1.15.2】
-
Set-Cookie:对客户端设置cookie【例如:token=XXXX; Path=/; HttpOnly】
-
Transfer-Encoding:响应内容的传输编码格式【例如:chunked, deflate, gzip】
/* keep-alive就是浏览器和服务器 的通信连接会被持续保存,不会马上关闭,而close就会在response后马上关闭。但这里要注意一点,我们说HTTP是无状态的,跟这个是否keep-alive没有关系,不要认为keep-alive是对HTTP无状态的特性的改进。 */
-
-
Request Headers
- Accept:浏览器(或者其他基于HTTP的客户端程序)可以接收的内容类型(Content-types)
- Accept-Encoding:浏览器可以处理的编码方式,注意这里的编码方式有别于字符集,这里的编码方式通常指gzip,deflate等。【例如: Accept-Encoding: gzip, deflate】
- Accept-Language:浏览器接收的语言,其实也就是用户在什么语言地区
- Connection:告诉服务器这个user agent(通常就是浏览器)想要使用怎样的连接方式
- Cookie:浏览器向服务器发送请求时发送cookie,或者服务器向浏览器附加cookie
- Host:服务器的域名或IP地址,如果不是通用端口,还包含该端口号
- Referer:指当前请求的URL是在什么地址引用的
- Upgrade-Insecure-Requests: 请求头向服务器发送一个信号,表示客户对加密和认证响应的偏好,并且它可以成功处理
- User-Agent:通常就是用户的浏览器相关信息
HTTP协议(超文本传输协议)
HTTP(Hyper Text Transfer Protocol):⽤于从万维⽹(WWW:World Wide Web )服务器传输超⽂本到本 地浏览器的传送协议,常⻅的协议有TCP/IP. SOAP协议, HTTP协议, SMTP协议等等.....
HTTP协议把⼀条消息分为三⼤块内容. ⽆论是请求还是响应都是三块内容:
请求:
/*
请求⾏ -> 请求⽅式(get/post) 请求url地址 协议
请求头 -> 放⼀些服务器要使⽤的附加信息
请求体 -> ⼀般放⼀些请求参数
*/
响应:
/*
状态⾏ -> 协议 状态码
响应头 -> 放⼀些客户端要使⽤的⼀些附加信息,如:cookie,验证信息,解密的key
响应体 -> 服务器返回的真正客户端要⽤的内容(HTML,json)等
*/
状态码
- 200-请求成功
- 301-资源(网页等)被永久转移到其他URL;302:重定向
- 404-请求的资源(网页等)不存在
- 500-内部服务器错误
更多状态码:HTTP 状态码 | 菜鸟教程 (runoob.com)
请求头中的常见内容
- User-Agent:请求载体的身份标识(用啥发送的请求)
- Referer:防盗链(这次请求是从哪个页面来的?反爬会用到)
- cookie:本地字符串数据信息(用户登录信息,反爬的token)
响应头中的常见内容
- cookie:本地字符串数据信息(用户登录信息,反爬的token)
- 各种神奇的莫名其妙的字符串(这个需要经验了,一般都是token字样,防止各种攻击和反爬)
各类模块解析
请求模块
urllib
指定URL,获取网页数据
requests
对比urllib更简洁,更强大
基础格式
# 导入 requests 包
import requests
# 发送请求
resp = requests.get('https://www.runoob.com/')
# 返回网页内容
print(resp.text)
Cookies
获取请求头中的cookies
session.cookies.get_dict()
获取响应体中的cookies
resp.headers["cookie"]
给session加cookies
cookie = {name:value}
session.update(cookie)
响应信息
调用 requests 请求之后,会返回一个 response 对象(包含了具体的响应信息,如状态码、响应头、响应内容等)。
| 方法 | 阐述 |
|---|---|
| .status_code | 返回 http 的状态码,比如 404 和 200(200 是 OK,404 是 Not Found) |
| .text | 返回响应的内容,unicode 类型数据 |
| .json() | 返回结果的 JSON 对象 (结果需要以 JSON 格式编写的,否则会引发错误) |
| .headers | 返回响应头,字典格式 |
| .content | 返回响应的内容,以字节为单位 |
| .apparent_encoding | 返回响应内容的编码方式 |
| .encoding | 返回响应.text的编码方式 |
| .close() | 关闭与服务器的连接 |
| .reason | 响应状态的描述,比如 "Not Found" 或 "OK" |
| .request | 返回请求此响应的请求对象 |
更多响应信息:Python requests 模块 | 菜鸟教程 (runoob.com)
方法
| 方法 | 阐述 |
|---|---|
| get(url, params, args) | 发送 GET 请求到指定 url |
| post(url, data, json, args) | 发送 POST 请求到指定 url |
| request(method, url, args) | 向指定的 url 发送指定的请求方法 |
| head(url, args) | 发送 HEAD 请求到指定 url |
| patch(url, data, args) | 发送 PATCH 请求到指定 url |
| put(url, data, args) | 发送 PUT 请求到指定 url |
| delete(url, args) | 发送 DELETE 请求到指定 url |
- url: 请求 url
- params:查询参数【get请求的参数存放地点】
单个资源的详细信息->Payload->From Data->参数 - data :参数为要发送到指定 url 的字典、元组列表、字节或文件对象【post请求的参数存放地点】
单个资源的详细信息->Payload->Query String Parameters->参数 - json:参数为要发送到指定 url 的 JSON 对象
- args :为其他参数,比如 cookies、headers、verify等
SSL证书报错
有些网站可能没有购买SSL证书或SSL证书失效,进而导致爬取过程中出现SSL证书报错。
-
requests.get(url, verify=False):不验证ssl证书
-
# 去除warnning import urllib3 urllib3.disable_warnings()
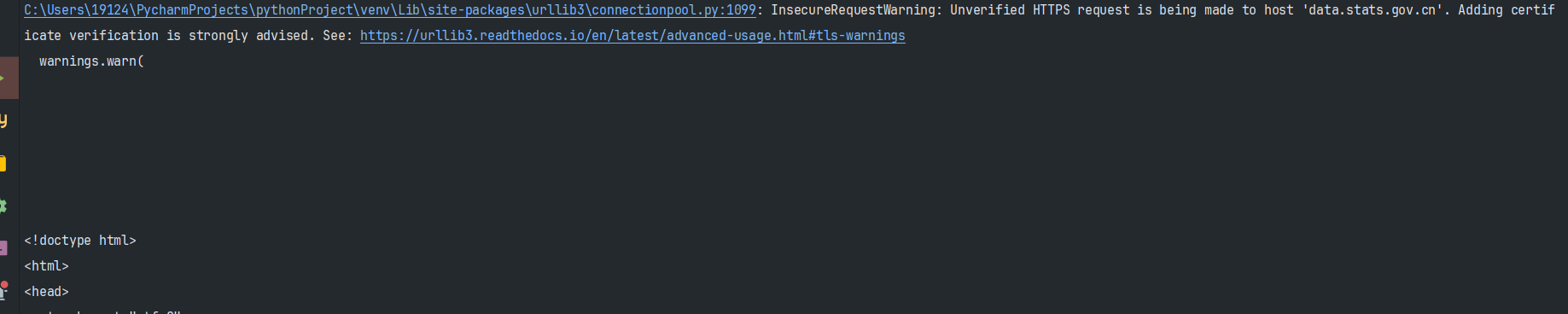

# 拿国家数据网站举例:
import requests
import urllib3
urllib3.disable_warnings()
resp = requests.get('https://data.stats.gov.cn/index.htm', verify=False)
print(resp.text)
解析模块
应用于HTML或XML文档
注意:除re模块外,其余三个模块需要学习基础html和css语法。
re
简介:正则表达式,模式匹配和搜索
- 适用于简单的
预加载
简介:
提前把正则对象加载完毕,便于重复利用,减少内存消耗
用法:
import re
obj = re.compile("\d+")
result = obj.findall("我叫周杰伦,今年32岁,我的班级是5年4班")
print(result)
result = obj.finditer("我叫周杰伦,今年32岁,我的班级是5年4班")
for item in result:
print(item.group())
函数
| 语法 | 阐述 | 例子 |
|---|---|---|
| re.findall("匹配字符"或正则,"目标语句") | 返回所有匹配项作为字符串列表。 | re.findall("a","我是一个abcdeafg") |
| re.finditer("匹配字符",""目标语句) | 返回产生 match objects 的iterator(迭代器)。 | re.finditer(r"\d+","我今年18岁,我有200000000块") |
| result=re.search("匹配字符","目标语句") | 返回匹配项中的第一项 | result=re.search(r"\d+","我叫周杰伦,今年32岁,我的班级是5年4班") |
| result=re.match("匹配字符","目标语句") | 从字符串的开头进行匹配的,类似在正则前面加上了 ^ | result=re.match(r"\d+","我叫周杰伦,今年32岁,我的班级是5年4班") |
提取分组数据
简介:
- 提取分组数据:用小括号括起来(以元组形式),可以单独起名字
- (?P<名字>正则)
- 提取数据的时候,需要.group("名字)
用法:
import re
resp = """
<div class:='西游记'><span id='10010'>中国联通</span></div>
<div class:='西游记'><span id='10086'>中国移动</span></div>
"""
obj = re.compile(r"<span id='(?P<id>\d+)'>(?P<name>.*?)</span>",re.S)
result = obj.finditer(resp)
for item in result:
id = item.group("id")
print(id)
name = item.group("name")
print(name)
注意: re.S 表示匹配换行符(\n),最好加上
bs4
简介:Beautiful Soup,创建解析树、浏览文档树,通过html文档中的标签名以及对应的属性值进行提取。
- 适用于常规解析和数据提取
导入beautifulsoup
from bs4 import BeautifulSoup
解析html
格式:BeautifulSoup(html内容, "html解析器")
page = BeautifulSoup(html, "html.parser")
查找元素
| 语法 | 阐述 | 例子 |
|---|---|---|
| page.find("标签名", attrs={"属性":"值"}) | 查找一个元素 | li = page.find("li",attrs={"id":"abc"}) |
| page.find_all("标签名", attrs={"属性":"值"}) | 查找所有元素 | li = page.find_all("li",attrs={"id":"abc"}) |
获取文本和属性
| 语法 | 阐述 | 例子 |
|---|---|---|
| .text | 获取文本 | li.text |
| .get("属性名") | 获取属性 | li.get("herf") |
xpath【XML】【直观强大】
简介:xml包含html,此模块在XML中定位节点 -> 在XML中导航和选择元素
- 适用于复杂的XML文档结构
- xml的节点= html的标签
导入xpath
from lxml import etree
# 如果pycharm报错. 可以考虑这种导入方式
# from lxml import html
# etree = html.etree
解析xml或html
et = etree.XML(xml) # xml
et = etree.HTML(html) # html
提取数据
| 方法 | 阐述 | 示例 |
|---|---|---|
| / | 表示根节点 | result = et.xpath("/book") |
| ./ | 表示当前节点 | href = li.xpath("./a") |
| /节点/子节点 | 在xpath中间的/表示的是儿子 | result = et.xpath("/book/name") |
| //节点名 | 查找所有指定节点名 | result = et.xpath("/book//nick") |
| * | 通配符. 谁都行 | result = et.xpath("/book/*/nick/text()") |
| /节点[第几项] | 查找第几项节点 | result = et.xpath("/html/body/ul/li[2]/a/text()") |
| [@属性名=值] | [ ]表示属性筛选. @属性名=值 相似于:find(Nick, attrs={"class":"jay"}) |
result = et.xpath("/book/author/nick[@class='jay']/text()") |
| /text() | 拿文本 | result = et.xpath("/book/name/text()")[0] |
| /@属性名 | 拿属性值 | result = et.xpath("/book/partner/nick/@id") |
技巧:
当页面复杂,无法搞清楚从属关系时,将源码写入html文件格式化,删删改改
pyquery【HTML】【jQuery语法】
简介:提供了类似jQuery语法的API,用于方便地操作HTML文档,可使用简洁的CSS选择器来选择和操作文档中的元素
- 适用于复杂的HTML文档结构。
导入pyquery
from pyquery import PyQuery
解析html
p = PyQuery(html)
注意:此时为pyquery对象。
查找标签
利用css选择器,看html和css的css选择器一节
| 语法 | 阐述 | 例子 |
|---|---|---|
| p("标签名") | 利用标签名找标签 | p("li a")或 p("li")("a") |
| p(".类名") | 利用类名找标签 | p("#qq a") |
| 等等... | ... | ... |
-
结果中通过数字查找:
# 例子:chexing=mt("div > dl:nth-child(1)>dd").eq(0).text() .eq(数字) 表示在已经通过css标签定位到的结果中提取第一个 dl:nth-child(1) 表示<dl>标签在其父标签中的第一个。 dt:contains(购车经销商) 表示<dt>标签包含文字:购物经销商
获取文本和属性
| 语法 | 阐述 | 例子 |
|---|---|---|
| .text() | 获取文本 | p("#qq a").text() |
| .attr("属性名") | 获取属性 | p("#qq a").attr("herf") |
动态修改标签和属性
| 语法 | 阐述 | 例子 |
|---|---|---|
| .after("""HTML代码""") | 在标签后面加html代码 | p("div.aaa").after(""" 吼吼吼 """) |
| .append("""HTML代码""") | 在标签内部加html代码 | p("div.aaa").append(""" 吼吼吼 """) |
| .attr("属性名","属性值") | 新增标签属性【前提:标签没有这个属性】 | p("div.bbb").attr("id","12306") |
| .remove() | 删除标签 | p("div.bbb").remove() |
| .remove_attr("属性名") | 删除标签属性 | p("div.bbb").remove_attr("id") |
| .attr("属性名","属性值") | 修改标签属性 | p("div.bbb").attr("class","aaa") |
存储模块
xlwt
进行excel操作
sqlite3
进行SQLite数据库操作
rich
官方文档:https://rich.readthedocs.io/en/stable/
第三方中文文档:https://geekdaxue.co/read/yumingmin@python/2UHtqpV9h_Jo9g9h
输入
# 默认输入
from rich.prompt import Prompt
name = Prompt.ask("Enter your name")
print(name)
# 指定值输入
from rich.prompt import Prompt
name = Prompt.ask("Enter your name", choices=["才哥", "可以叫我才哥", "天才"], default="可以叫我才哥")
print(name)
# 判断输入
from rich.prompt import Confirm
is_rich_great = Confirm.ask("Do you like rich?")
assert is_rich_great
输出
from rich import print
print("[red]hello[/red] [blue]world[/blue] :vampire:")
print("[italic red]Hello[/italic red] World!")
print(":smiley: :pile_of_poo: :thumbs_up: ")
# italic 斜体
# magenta 紫红色
# 加颜色:[颜色]hello[/颜色]
# 加表情::vampire:
from rich import pretty
pretty.install()
# 这样输出的格式更加漂亮
print(locals())
查看方法
# inspect(变量或常量)
inspect("asd")
inspect("asd",method="true)
自定义控制台
from rich.console import Console
console = Console()
console.print("hello world,style="bold red"") # 控制台固定格式输出
console.print("[bold red]hello world![/bold red]") # 控制台加颜色输出
console.print("Rich库有点意思啊", style="red on white") # 控制台输出-白底红字
console.log("[bold red]hello world![/bold red]") # 控制台打印日志
console.rule("[bold red]Chapter 2")
console.rule("[bold red]Chapter 2", align='left')
# 控制台打印分割线
日志
import logging
from rich.logging import RichHandler
FORMAT = "%(message)s"
logging.basicConfig(
level="NOTSET", format=FORMAT, datefmt="[%X]", handlers=[RichHandler()])
log = logging.getLogger("rich")
log.info("Hello,World!")
log.critical("Hello,World!")
log.debug("Hello,World!")
log.warning("Hello,World!")
进度条
from time import sleep
from rich.progress import track
# 只需要在循环外加上track()
for step in track(range(10)):
sleep(1)
step
# 流动进度
from time import sleep
from rich.console import Console
console = Console()
tasks = [f"task {n}" for n in range(1, 11)] # tasks为迭代器
with console.status("[bold green]正在下载...")as status:
while tasks:
task = tasks.pop(0) # 弹出一个任务
sleep(1)
console.log(f"{task} complete")
# 流动进度--协程下载文件
import asyncio
import aiohttp
from rich.progress import Progress
from rich.console import Console
async def download_file(url, session, progress):
async with session.get(url) as response:
# 获取文件总大小
total_size = int(response.headers.get('content-length', 0))
downloaded = 0
# 创建进度条
task_id = progress.add_task("[cyan]Downloading...", total=total_size)
# 保存文件内容
with open(url.split('/')[-1], 'wb') as f:
async for chunk in response.content.iter_chunked(1024):
f.write(chunk)
downloaded += len(chunk)
# 更新进度条
progress.update(task_id, advance=downloaded)
async def main():
console = Console()
urls = [
'https://example.com/file1.zip',
'https://example.com/file2.zip',
# 添加更多下载链接...
]
async with aiohttp.ClientSession() as session:
progress = Progress(console=console)
progress.start()
# 启动下载任务
download_tasks = [download_file(url, session, progress) for url in urls]
await asyncio.gather(*download_tasks)
progress.stop()
asyncio.run(main())
面板
from rich import print
from rich.panel import Panel
print(Panel("Hello, [red]World!", title="Welcome"))
表格
from rich.console import Console
from rich.table import Table
table = Table(title="Star Wars Movies")
table.add_column("Released", justify="right", style="cyan", no_wrap=True)
table.add_column("Title", style="magenta")
table.add_column("Box Office", justify="right", style="green")
table.add_row("Dec 20, 2019", "Star Wars: The Rise of Skywalker", "$952,110,690")
table.add_row("May 25, 2018", "Solo: A Star Wars Story", "$393,151,347")
table.add_row("Dec 15, 2017", "Star Wars Ep. V111: The Last Jedi", "$1,332,539,889")
table.add_row("Dec 16, 2016", "Rogue One: A Star Wars Story", "$1,332,439,889")
console = Console()
console.print(table)
语法高亮
from rich.console import Console
from rich.syntax import Syntax
my_code = '''
def iter_first_last(values: Iterable[T]) -> Iterable[Tuple[bool, bool, T]]:
"""Iterate and generate a tuple with a flag for first and last value."""
iter_values = iter(values)
try:
previous_value = next(iter_values)
except StopIteration:
return
first = True
for value in iter_values:
yield first, False, previous_value
first = False
previous_value = value
yield first, True, previous_value
'''
syntax = Syntax(my_code, "python", theme="monokai", line_numbers=True)
console = Console()
console.print(syntax)
文本格式
文本颜色样式调整
# 长文本颜色样式调整
# 将字符串0123456789中[0,6)下标的字符颜色设置为酒红色粗体。
from rich.console import Console
from rich.text import Text
console = Console()
text = Text("0123456789")
text.stylize("bold magenta", 0, 6)
console.print(text)
文本对齐
from rich import print
from rich.panel import Panel
from rich.text import Text
panel = Panel(Text("大家好,我是才哥。欢迎关注微信公众号:可以叫我才哥!", justify="center"))
print(panel)
文本高亮
from rich.console import Console
from rich.highlighter import RegexHighlighter
from rich.theme import Theme
class EmailHighlighter(RegexHighlighter):
"""Apply style to anything that looks like an email."""
base_style = "example."
highlights = [r"(?P<email>[\w-]+@([\w-]+\.)+[\w-]+)"]
theme = Theme({"example.email": "bold magenta"})
console = Console(highlighter=EmailHighlighter(), theme=theme)
console.print("Send funds to money@example.org")
markdown语法
MARKDOWN = """
# 这是一级标题
Rich 库能比较**完美**的输出markdown.
1. This is a list item
2. This is another list item
```python
from rich.console import Console
from rich.markdown import Markdown
console = Console()
md = Markdown(MARKDOWN)
console.print(md)
```

"""
from rich.console import Console
from rich.markdown import Markdown
console = Console()
md = Markdown(MARKDOWN)
console.print(md)
布局
layout布局
from rich import print
from rich.layout import Layout
layout = Layout()
layout.split_column(
Layout(name="upper",size = 10),
Layout(name="lower",size = 10)
)
layout["lower"].split_row(
Layout(name="left"), Layout(name="right"),
)
layout["right"].split(
Layout(Panel("Hello")),
Layout(Panel("World!"))
)
print(layout)
树结构
from rich.tree import Tree
from rich import print
tree = Tree("地球")
baz_tree = tree.add("亚洲")
baz_tree.add("[red]中国").add("[green]北京").add("[yellow]海淀区")
print(tree)
padding填充
from rich import print
from rich.padding import Padding
test = Padding("Hello", (2, 4), style="on blue", expand=False)
print(test)
live动态
import time
from rich.live import Live
from rich.table import Table
table = Table()
table.add_column("Row ID")
table.add_column("Description")
table.add_column("Level")
with Live(table, refresh_per_second=4): # update 4 times a second to feel fluid
for row in range(12):
time.sleep(0.4) # arbitrary delay
# update the renderable internally
table.add_row(f"{row}", f"description {row}", "[red]ERROR")
loguru
日志打印
from loguru import logger
logger.debug('This is debug information')
logger.info('This is info information')
logger.warning('This is warn information')
logger.error('This is error information')
反爬处理

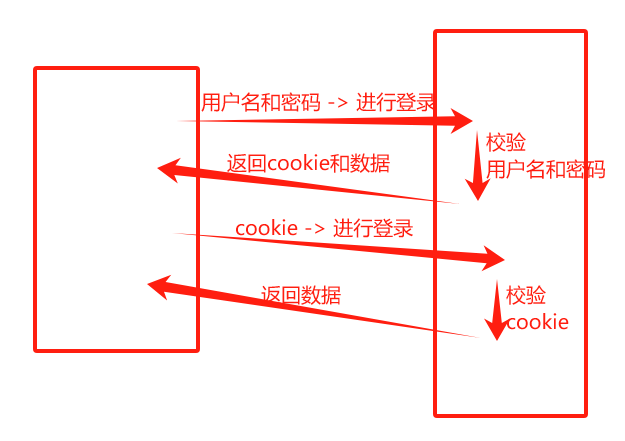
处理cookie
- Session对象
- 用于跟踪用户状态和在多个页面和HTTP请求之间共享信息。
- 可以存储cookie
- Cookie原理解析
- 设置UA
UA=user-agent=用户代理
- python程序默认的用户代理为'python-requests/requests模块版本号'【可通过 response.request.headers查看】
- 如果不设置代理,则会被检测为异常流量,进而拦截。
防盗链
Referer,用于帮助网站溯源从哪个网站访问过来,若不符合要求则返回错误
解法:在headers中设置父网站url(即Referer)
示例:笔记本 -> 梨视频视频爬取【包含防盗链】
设置代理
使用第三方服务器请求你要的网址。客户端请求->代理机器->目标网址->代理机器->客户端
解法:
import requests
def get_kuaidaili_proxy(url):
while True:
resp = requests.get(url)
if resp.json()['code'] == 0: # 预防代理返回的数据报错
for ip in resp.json()['data']['proxy_list']:
print("即将返回ip:", ip)
yield ip # 返回生成器对象
print("代理用完了,即将更新") # 预防代理用完
else:
print("获取代理IP出现异常. 重新获取!")
def spider(url, proxy_url):
while True:
try:
proxy_ip = next(get_kuaidaili_proxy(proxy_url))
proxy = {
'http': f"http://{proxy_ip}",
# 'https': f"https://{proxy_ip}" # 经测试,使用快代理的新人免费6小时IP中,使用https出现问题
}
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36"
}
resp = requests.get(url, headers=headers, proxies=proxy)
resp.encoding = "gbk"
return resp.text
except:
print("报错了,换个ip再来")
if __name__ == '__main__':
url = "要爬的链接" # 要爬的链接
proxy_url = "代理IP" # 代理IP
for i in range(2):
print(spider(url, proxy_url))
示例:笔记本->电影天堂【使用代理】
多线程与多进程
进程和线程
- 进程:运行中的程序。当执行一个程序,操作系统对自动的为这个程序准备一些必要的资源(例如,分配内存,创建一个能够执行的线程)。
- 线程:程序内可以直接被CPU调度的执行过程。CPU调度的最小单位,包含于进程之中,是进程中的实际运作单位。
使用优势:
- 多线程:任务相对统一,互相特别相似
- 多进程:多个任务相互独立,很少有交集
导入和使用
导入
from threading import Thread # 导入多线程模块
from multiprocessing import Process # 导入多进程模块
法一:
将Thread换为Process即为多进程
线程名 = Thread(target=线程调用的函数名, args=(参数)) # 参数例子: "周杰伦",
# 参数必须是元组(不可变,有序),创建含有一个元素的元组时,需要在元素后添加逗号
线程名.start()
法二【面向对象】:
面向对象:
class MyThread(Thread):
# 建立类,类可继承自模块(父类)。
def __init__(self, name):
# 类中的 init 函数称为构造函数,构造对象(实例),传入形参备用。
super().__init__()
# 类中的 init 函数称为构造函数,构造对象(实例),传入形参备用。
self.name = name
# 由于继承自模块,可以通过调用模块的构造函数来保留模块的初始化对象行为。
方法示例:
from threading import Thread
class MyThread(Thread):
def __init__(self, name):
super().__init__()
self.name = name。
def run(self): # 重写run方法
for i in range(100):
print(self.name, i)
if __name__ == '__main__':
t1 = MyThread("周杰伦")
t2 = MyThread("王力宏")
t3 = MyThread("周润发")
t1.start()
t2.start()
t3.start()
线程池与进程池
将ThreadPoolExecutor换为ProcessPoolExecutor即为进程池
from concurrent.futures import ThreadPoolExecutor # 导入线程池执行器模块
from concurrent.futures import ProcessPoolExecutor # 导入进程池执行器模块
def func(name, sequence):
for i in range(10):
return name, i, sequence
def fn(res):
print(res.result())
if __name__ == '__main__':
with ThreadPoolExecutor(10) as t: # 设定线程池执行器并行10个线程
for i in range(100): # 提交100个线程任务
# # 法一:
# t.submit(func, f"周杰伦{i}").add_done_callback(fn) # 传入多个参数时,只需要加个逗号就行
# # 回调函数,返回即执行callback函数,返回值的顺序是不确定的
# 法二:
result = t.map(func, ["周杰伦", "王力宏", "王富贵"], [2, 1, 3]) # map返回值是生成器,返回的内容和任务分发的顺序是一致的,
for r in result:
print(r)
Callback函数是多线程的还是单线程执行?
在主函数中单线程执行。
add_done_callback() 方法用于设置一个回调函数,该函数在每个线程任务完成时被调用。回调函数 verify_ip 将会在每个线程任务完成后被调用。但是,回调函数是在主线程中执行的,而不是在多线程中执行的。
当你使用 ThreadPoolExecutor 创建线程池时,任务会在多个线程中并行执行。但是,回调函数 verify_ip 是在主线程中执行的,它会在每个线程任务完成后按顺序被调用。
进程间通信:队列
为什么需要队列:
- 进程之间不共享内存,若需要传参,则需借助中间件,或mysql或redis等等。
- python的多进程模块自带队列函数(通过网卡模拟中间件)。
怎么使用队列:
-
导入进程模块的队列函数
-
from multiprocessing import Process, Queue # 第二个函数为队列
-
-
队列通信
-
q = Queue() # 定义队列函数 q.put(变量或常量) # 传入 【自我感觉传入常量没有意义】 变量 = q.get() # 传出
-
-
进程传参
-
p1 = Process(target=get_img_src, args=(q,)) # 进程1传入队列 p2 = Process(target=download_img, args=(q,)) # 进程2传入队列
-
协程
asyncio:异步。什么是异步加载:动态加载。
前景(当线程数量非常多、多任务操作、有IO阻塞耗时操作时):
- 系统线程会占用非常多的内存空间。
- 过多的线程切换会占用大量的系统时间。
- 线程阻塞会使得CPU资源利用率降低
导入协程
import asyncio
使用协程
async 用在语句之前表示可异步。只要有with,前面加上async
await 用在语句之前表示可挂起。只要是需要等待或普通语句,前面加上await
法一:
f = 函数名()
event_loop = asyncio.get_event_loop() # 创建监测人
event_loop.run_until_complete(f) # 检测任务直到任务执行完
法二:
f = 函数名()
asyncio.run(f)
wait( )和gather( )的返回值
# gather 和 wait的区别:
# 1.顺序
# gather返回值是有顺序(按照你添加任务的顺序返回的)的【在tasks之前加*来表示为位置参数】
# 2.错误信息
# return_exceptions=True, 如果有错误信息. 返回错误信息, 其他任务正常执行.
# return_exceptions=False, 如果有错误信息. 所有任务直接停止
result = await asyncio.gather(*tasks, return_exceptions=True) # return_exceptions=True
print(result)
阻塞函数代替模块
- aiohttp
- aiofiles
注意:当读取文字或图片时,要转换写法
# aiohttp, aiofiles
import asyncio
import aiohttp
import aiofiles
async def download(url):
print("开始下载", url)
file_name = url.split("/")[-1]
# 相当于requests
async with aiohttp.ClientSession() as session:
# 发送网络请求
async with session.get(url) as resp:
# await resp.text() # 转换自 resp.text
# await resp.json() # 转换自 resp.json
content = await resp.content.read() # 转换自 resp.content
# 写入文件
async with aiofiles.open(file_name, mode="wb") as f:
await f.write(content)
print("下载完成.", url)
async def main():
url_list = [
"https://i1.huishahe.com/uploads/tu/201911/9999/919ae5b037.jpeg",
"https://i1.huishahe.com/uploads/allimg/202205/9999/f89c9622d0.jpg",
"https://i1.huishahe.com/uploads/tu/201911/9999/2f9a3016dd.jpeg",
"https://i1.huishahe.com/uploads/tu/201911/9999/4e231c2fb0.jpg",
]
tasks = []
for url in url_list:
t = asyncio.create_task(download(url))
tasks.append(t)
await asyncio.wait(tasks)
if __name__ == '__main__':
asyncio.run(main())
笔记本
电影爬虫
爬虫思路分析: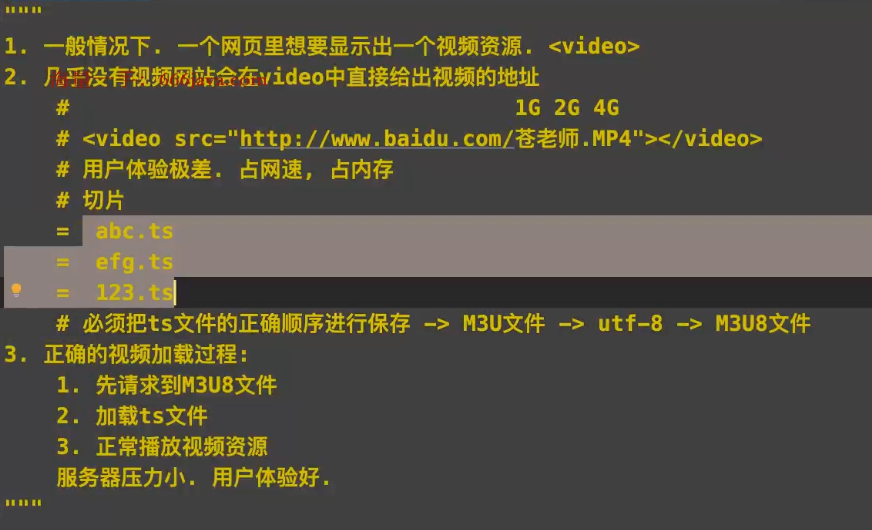

m3u8解析: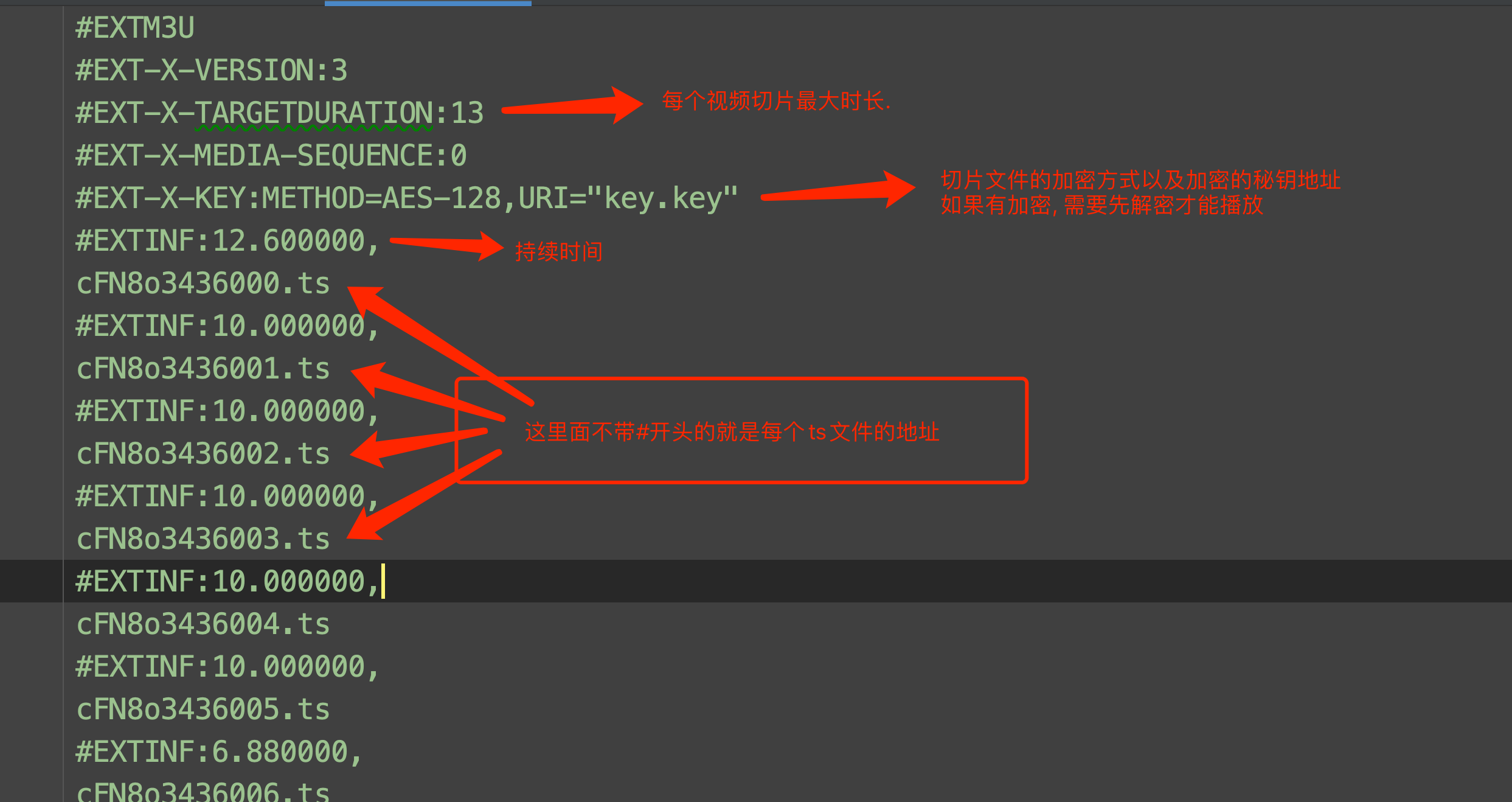
"""
ts文件的文件名过长--导致无法下载文件
ts文件的文件名过长--导致无法下载文件
"""
import aiofiles
import aiohttp
import asyncio
import os
import re
import requests
import shutil
from urllib import parse
from Crypto.Cipher import AES
from lxml import etree
from rich import print
from rich.panel import Panel
from rich.prompt import Prompt
from rich.text import Text
def move_ts(video_name):
# 获取当前工作目录
current_directory = os.getcwd()
# 定义源文件夹路径和目标文件夹路径
source_directory = os.path.join(current_directory, f"电影/{video_name}/电影_源_加密后")
destination_directory = os.path.join(current_directory, f"电影/{video_name}/电影_源_解密后")
# 获取源文件夹中的所有文件列表
files_to_move = os.listdir(source_directory)
# 遍历源文件夹中的所有文件,并移动到目标文件夹
for file_name in files_to_move:
# 构建源文件路径和目标文件路径
source_file = os.path.join(source_directory, file_name)
destination_file = os.path.join(destination_directory, file_name)
# 移动文件
shutil.move(source_file, destination_file)
print(f"Moved {file_name} to {destination_directory}")
def move_movie(video_name):
# 将电影移动到父文件夹
# 获取当前工作目录
current_directory = os.getcwd()
# 指定要移动的文件名
file_to_move = f"{video_name}.mp4"
# 构建源文件的完整路径
source_path = os.path.join(current_directory, file_to_move)
# 构建目标路径,即父目录
parent_directory = os.path.dirname(current_directory)
destination_path = os.path.join(parent_directory, file_to_move)
# 使用shutil.move()移动文件
shutil.move(source_path, destination_path)
def merge_ts(video_name):
name_list = []
with open(f"./电影/{video_name}/m3u8.txt", mode="r", encoding='utf-8') as f:
for line in f:
if line.startswith('#'):
continue
line = line.strip()
file_name = "" # 定义文件类型
if '/' not in line: # 有的电影有防盗链
file_name = line
else:
file_name = line.split('/')[-1]
name_list.append(file_name)
# print(name_list) # 所有干净的ts文件名
now_dir = os.getcwd()
os.chdir(f"./电影/{video_name}/电影_源_解密后/") # os切换到目标目录
print(f'切换目录到:{os.getcwd()}')
# 第一层合并
n = 1
temp = [] # 第一次待合并列表
for i in range(len(name_list)):
name = name_list[i]
temp.append(name)
if i != 0 and i % 100 == 0: # 每100个文件合并一次
names = " + ".join(temp)
# print(names)
os.system(f"copy /b {names} {n}.ts")
n = n + 1
temp = [] # 还原成新的待合并列表
# 第一次合并的收尾--不到100的文件
names = " + ".join(temp)
os.system(f"copy /b {names} {n}.ts")
print("第一次合并完成")
# 第二层合并
temp1 = [] # 第二次待合并列表
# 对所有第一次合并的文件进行遍历合并
for i in range(1, n + 1):
temp1.append(f'{i}.ts')
names = " + ".join(temp1)
os.system(f'copy /b {names} {video_name}.mp4')
print("第二次合并完成")
move_movie(video_name) # 将电影移动到父文件夹
# os切换回原始目录
os.chdir(now_dir)
async def des_one_ts(video_name, key, file): # AES解密
file = file.split("/")[-1]
print("正在解密", file)
aes = AES.new(key=key, IV=b"0000000000000000", mode=AES.MODE_CBC) # IV(偏移量):有的网站会在m3u8中写,mode默认这样就行
async with aiofiles.open(f"./电影/{video_name}/电影_源_加密后/{file}", mode="rb") as f1, \
aiofiles.open(f"./电影/{video_name}/电影_源_解密后/{file}", mode="wb") as f2:
content = await f1.read()
bs = aes.decrypt(content)
await f2.write(bs)
print("解密完成", file)
async def des_all_ts_file(video_name, target_m3u8_url, key):
tasks = []
with open(f"./电影/{video_name}/m3u8.txt", mode="r", encoding='utf-8') as f:
for line in f:
if line.startswith('#'):
continue
line = line.strip()
if '/' not in line: # 有的电影有防盗链
line = parse.urljoin(target_m3u8_url, line)
elif line.startswith('/'):
line = parse.urljoin(target_m3u8_url, line)
task = asyncio.create_task(des_one_ts(video_name, key, line))
tasks.append(task)
await asyncio.wait(tasks)
def get_key(video_name, target_m3u8_url):
try:
key_url = ""
obj = re.compile(r'URI="(?P<key_url>.*?)"')
with open(f"./电影/{video_name}/m3u8.txt", mode='r', encoding='utf-8') as f:
result = obj.search(f.read())
key_url = result.group('key_url')
# print(key_url)
if '/' not in key_url: # 有的电影key有防盗链
key_url = parse.urljoin(target_m3u8_url, key_url)
elif key_url.startswith('/'):
key_url = parse.urljoin(target_m3u8_url, key_url)
key_url = requests.get(key_url)
if isinstance(key_url.content, bytes):
return key_url.content
elif isinstance(key_url.text, str):
return key_url.text.encode('utf-8')
except AttributeError:
return "无加密"
async def download_one_ts(url, video_name):
# 自省
for i in range(10):
try:
file_name = url.split("/")[-1]
async with aiohttp.ClientSession() as session: # aiohttp.ClientSession()相当于会话,需要关闭,所以要用with
async with session.get(url, timeout=90) as resp:
content = await resp.content.read()
async with aiofiles.open(f"./电影/{video_name}/电影_源_加密后/{file_name}", mode="wb") as f:
await f.write(content)
print(url, "下载成功")
break
except Exception as e:
print(f"第{i + 1}次下载失败,等待{(i + 1) * 5}秒再次下载,{url},失败原因:{e}")
await asyncio.sleep((i + 1) * 5)
# if "指定的网络名不再可用" in e:
# print("[red]链接失效,请重新下载。。。[/red]")
# break
# else:
# print(f"第{i + 1}次下载失败,失败原因{e},等待{(i + 1) * 5}秒再次下载,{url}")
# await asyncio.sleep((i + 1) * 5)
async def download_all_ts(target_m3u8_url, video_name):
tasks = []
with open(f"./电影/{video_name}/m3u8.txt", mode="r", encoding='utf-8') as f:
for line in f:
if line.startswith('#'):
continue
line = line.strip()
if '/' not in line: # 有的电影有防盗链
line = parse.urljoin(target_m3u8_url, line)
elif line.startswith('/'):
line = parse.urljoin(target_m3u8_url, line)
task = asyncio.create_task(download_one_ts(line, video_name)) # 创建任务
tasks.append(task) # 装任务
await asyncio.wait(tasks) # 任务挂起-需要等待
# def m3u8_convert_download(m3u8_url, video_name):
#
# return target_m3u8_url
def main(search_name):
url = "https://www.yespb.com/sou/-------------.html" # 搜索接口
params = {
"wd": search_name,
"submit": ""
}
session = requests.session()
resp = session.get(url, params=params)
et = etree.HTML(resp.text)
href_list = et.xpath("//h4[@class='title text-overflow']/a/@href")
for i in range(len(href_list)):
href_list[i] = parse.urljoin(url, href_list[i])
title_list = et.xpath("//h4[@class='title text-overflow']/a/text()")
for i, (href, title) in enumerate(zip(href_list, title_list)):
print(f"序号:{i}\t{href}\t{title}")
video_number = int(Prompt.ask(Text("请选择要下载的电影序号", style="bold magenta")))
resp = session.get(href_list[video_number])
video_name = title_list[video_number]
if not os.path.exists('电影'): # 创建电影文件夹
os.mkdir('电影')
# 使用 os.makedirs() 创建文件夹(如果不存在)
os.makedirs(os.path.join("./电影", video_name), exist_ok=True) # exist_ok=True 如果该文件夹已经存在,不会抛出异常,也不会覆盖原有文件夹。
os.makedirs(os.path.join(f"./电影/{video_name}", "电影_源_加密后"), exist_ok=True)
os.makedirs(os.path.join(f"./电影/{video_name}", "电影_源_解密后"), exist_ok=True)
et = etree.HTML(resp.text)
# 定位所有包含资源信息的父节点
resource_fathers = et.xpath('//div[@class="stui-vodlist__head "]')
dict = {} # 创建空字典
# 遍历父节点并提取链接和相关信息
for i, resource_father in enumerate(resource_fathers):
resource_name = resource_father.xpath('./span[@class="pull-right1"]/text()')[0]
links_list = resource_father.xpath('./ul[@class="stui-content__playlist clearfix"]/li/a/@href')
for n in range(len(links_list)):
links_list[n] = parse.urljoin(url, links_list[n])
dict[resource_name] = links_list
if '迅雷已停止更新' in dict:
del dict['迅雷已停止更新']
elif '用uTorrent工具' in dict:
del dict['用uTorrent工具']
# 输出序号和资源信息
for key, value in dict.items():
print(f'{key}\t{value}')
target_href_list = dict[Prompt.ask(Text("请输入资源名称(如:乐视资源,越优先-下载越快)", style="bold magenta"))]
if len(target_href_list) > 1:
target_href = target_href_list[int(Prompt.ask(Text("下载第几个( 从0开始 )", style="bold magenta")))]
else:
target_href = target_href_list[0]
resp = session.get(target_href)
resp.encoding = "utf-8"
obj = re.compile(r'<script type="text/javascript">var player_data={.*?"url":"(?P<m3u8_url>.*?)".*?</script>', re.S)
result = obj.search(resp.text)
m3u8_url = result.group('m3u8_url').replace("\/", "/")
# 下载m3u8文件
resp = requests.get(m3u8_url)
target_m3u8_url = parse.urljoin(m3u8_url, resp.text.split()[-1]) # # target_m3u8_url 1.用来下载ts文件 2.用来下载key 3.解密ts文件
resp = requests.get(target_m3u8_url)
with open(f"./电影/{video_name}/m3u8.txt", mode="w", encoding='utf-8') as f:
f.write(resp.text)
asyncio.run(download_all_ts(target_m3u8_url, video_name)) # 异步运行-这样才有事件循环,才能轮着搜索任务状态
# 解密
key = get_key(video_name, target_m3u8_url)
if key == "无加密":
print("[red]ts文件未加密[red]")
move_ts(video_name)
else:
print(f"[red]ts文件已加密,正在解密[red]")
asyncio.run(des_all_ts_file(video_name, target_m3u8_url, key))
# 合并ts文件
merge_ts(video_name)
print("[bold magenta]下载完成。[/bold magenta]")
if __name__ == '__main__':
print(Panel.fit("[bold yellow]你好,欢迎来到平安电影下载站[/bold yellow]", title="Welcome", subtitle="https://www.cnblogs.com/wj-ive",
safe_box=True))
print(Panel.fit("[bold red]注意:[/bold red]\n[green]1.此程序为初代版本,存在诸多bug,仍需完善,若视频看不了、卡顿就换个链接试试\n2.预计下代:修复bug,下载进度条[/green]", safe_box=True))
main(Prompt.ask(Text("请输入要下载电影名", style="bold magenta")))
input("输入任意字符退出...")
笔趣阁小说爬虫
例子:[牧神记(宅猪) 最新章节 无弹窗 全文免费阅读 - 笔趣阁 (biqg.cc)](https://www.biqg.cc/book/3952/)
import requests
from urllib import parse
import aiohttp
import aiofiles
import asyncio
from lxml import etree
import os
from loguru import logger
import re
from cn2an import cn2an
def chinese_to_number(chinese):
# 使用正则表达式匹配中文数字
pattern = re.compile(r'第([\u4e00-\u9fa5]+)章 (.+)')
match = pattern.search(chinese)
if match:
chinese_number = match.group(1)
content = match.group(2)
# 使用 cn2an 将中文数字转换为阿拉伯数字
arabic_number = cn2an(chinese_number, 'smart')
return f'{arabic_number}章 {content}'
else:
return None
async def download_one(href, title0):
while 1:
try:
async with aiohttp.ClientSession() as session:
async with session.get(href) as resp:
page_source = await resp.text() # 挂起等待服务器回复页面源码
et = etree.HTML(page_source)
title = et.xpath("//h1[@class='wap_none']/text()")[0]
content = "\n".join(et.xpath("//div[@id='chaptercontent']/text()"))
# print(title0, title)
async with aiofiles.open(f"./{title0}/{chinese_to_number(title)}.txt", mode="w",
encoding="utf-8") as f:
await f.write(content)
break
except Exception as e:
logger.error(f"下载错误:再来一次,如果一直错误:找找原因:{href}", e)
logger.success(f'下载完毕--{href}----૮(˶ᵔ ᵕ ᵔ˶)ა')
async def download(href_list, title0):
tasks = []
for href in href_list:
t = asyncio.create_task(download_one(href, title0))
tasks.append(t)
await asyncio.wait(tasks)
def main(novel_url):
resp = requests.get(novel_url)
resp.encoding = "utf-8"
et = etree.HTML(resp.text) # html
title0 = et.xpath("//div[@class='info']/h1/text()")[0]
print(title0)
if not os.path.exists(title0):
os.mkdir(title0) # 创建大文件夹
href_list = et.xpath("//div[@class='listmain']/dl/dd/a/@href")
href_list1 = et.xpath("//div[@class='listmain']/dl/span[@class='dd_hide']/dd/a/@href")
n = href_list.index("javascript:dd_show()")
href_list[n:n] = href_list1
href_list.remove("javascript:dd_show()")
for i in range(len(href_list)):
href_list[i] = parse.urljoin(novel_url, href_list[i])
print(href_list)
asyncio.run(download(href_list, title0))
if __name__ == '__main__':
novel_url = input("请输入小说链接:") # https://www.biqg.cc/book/3808/
# novel_url = 'https://www.biqg.cc/book/3808/'
main(novel_url)
input("输入任意字符退出...")
美女图片下载【多进程-多线程-队列】
"""
进程 1. 访问主页面, 在主页面中拿到详情页的url.进入到详情页. 在详情页中提取到图片的下载地址
进程 2. 批量的下载图片
队列:进程之间的通信
"""
import requests
from urllib import parse # 转化
from lxml import etree
from multiprocessing import Process, Queue
from concurrent.futures import ThreadPoolExecutor
def get_img_src(q):
url = "http://www.591mm.com/mntt/6.html"
resp = requests.get(url)
resp.encoding = 'utf-8'
# print(resp.text)
tree = etree.HTML(resp.text)
href_list = tree.xpath("//div[@class='MeinvTuPianBox']/ul/li/a[1]/@href")
for href in href_list: # /mntt/hgmn/307626.html
child_url = parse.urljoin(url, href) # 拼接url地址
# print(child_url)
resp_child = requests.get(child_url)
resp_child.encoding = "utf-8"
child_tree = etree.HTML(resp_child.text)
src = child_tree.xpath("//img[@id='mouse_src']/@src")[0]
q.put(src) # 往里怼
q.put("已经传完了")
def download(url):
file_name = url.split("/")[-1]
with open("./photo/"+file_name, mode="wb") as f:
resp = requests.get(url)
f.write(resp.content) # 完成下载
def download_all(q):
# 在进程里创建线程池
with ThreadPoolExecutor(10) as t:
while 1:
src = q.get() # 往出拿
if src == "已经传完了":
break
print(src)
t.submit(download, src)
if __name__ == '__main__':
q = Queue()
p1 = Process(target=get_img_src, args=(q,))
p2 = Process(target=download_all, args=(q,))
p1.start()
p2.start()
自建免费IP代理池
- 从各个免费网站上抓取代理IP
- 验证代理IP是否可用
- 准备对外的接口【未完成】
import json
import requests
from lxml import etree
from loguru import logger
from concurrent.futures import ThreadPoolExecutor
# # 免费海外代理 ip 页
# FREE_IP_URL = 'https://www.iphaiwai.com/free'
def spider(proxy_url, page, verify_url, timeout):
global all_viable_proxies
headers1 = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36'
}
resp1 = requests.get(f"{proxy_url}{page}/", headers=headers1)
html1 = etree.HTML(resp1.text)
ip_list = html1.xpath("//td[@data-title='IP']/text()")
port_list = html1.xpath("//td[@data-title='PORT']/text()")
area_list = html1.xpath("//td[@data-title='位置']/text()")
period_of_validity_list = html1.xpath("//td[@data-title='IP时效(分钟)']/text()")
# 打包到元组,打包到列表
proxy_list = [(ip + ':' + port, area, period) for ip, port, area, period in
zip(ip_list, port_list, area_list, period_of_validity_list)]
# 2.多线程-验证代理ip-对列表的每个ip执行验证
with ThreadPoolExecutor(verify_thread_number) as t2:
# 这样写的话,会先提供线程池,然后循环为当前一次爬虫线程产生的的ip列表中的ip进行线程操作
# 若将上一句和下一句互换位置,则多次启用线程池会拖慢速度----important
for proxy in proxy_list:
t2.submit(verify, verify_url, proxy, timeout)
def verify(verify_url, proxy, timeout):
global all_viable_proxies
headers2 = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36'
}
proxy2 = {
'http': f"http://{proxy[0]}"
# 'https': f"https://{proxy[0]}"
}
try:
response = requests.get(url=verify_url, proxies=proxy2, headers=headers2, timeout=timeout)
response.encoding = 'utf-8'
if response.status_code == 200:
logger.success(f'验证成功--{proxy2}----૮(˶ᵔ ᵕ ᵔ˶)ა')
all_viable_proxies.append(proxy[0])
else:
logger.info(f'状态码错误--{proxy}--{response.status_code}')
except Exception as e:
logger.error(f'没连上--{proxy}--{e}')
def fn(i):
print(f"线程已提交:{i}")
if __name__ == '__main__':
# 抓代理url
proxy_url = "https://www.iphaiwai.com/fps-site/free/" # 快代理--海外
# proxy_url = 'https://www.kuaidaili.com/free/intr/' # 快代理--普通国内--【xpath不匹配】
# proxy_url = 'https://www.kuaidaili.com/free/inha/' # 快代理--高匿国内--【xpath不匹配】
# 验证网站
# verify_url = 'https://www.baidu.com/' # 百度
# verify_url = 'https://web.tlgrm.app/' # 电报
# verify_url = 'https://www.youtube.com/' # youtube
# verify_url = 'https://github.com/' # github
verify_url = 'http://ipinfo.io/json' # ipinfo
# 超时时间设置--秒
timeout = 20
# 设置线程数
spider_thread_number = 10
verify_thread_number = 200
# 设置全局变量保存完好代理
all_viable_proxies = []
# 1.先进去获取一共多少页
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36'
}
resp = requests.get(proxy_url, headers=headers)
html = etree.HTML(resp.text)
pages = html.xpath("//ul[@class='v3__pagination param-type-1']/li[@class='v3__pagination-item ']/@title")
all_page = pages[len(pages) - 1]
# 爬多少页代理
score_page = int(input(f"总页数:{all_page}\t一共爬多少页:"))
# 多线程分发页数,进行线程任务
print(f"爬代理线程数:{spider_thread_number}\t验证代理线程数:{verify_thread_number}")
print(f"超时时间:{timeout}")
# 2.多线程-爬链接并验证
with ThreadPoolExecutor(spider_thread_number) as t:
for page_number in range(1, score_page, 1):
t.submit(spider, proxy_url, page_number, verify_url, timeout)
# 等待全部线程执行完毕输出有效代理
print(json.dumps(all_viable_proxies))
# return json_string # 放在服务器上把这里解开
input("输入任意字符退出....")
# 调用案例
import time
import requests
def prox():
proxies = ["20.80.185.218:80", "27.79.156.72:4003", "116.203.28.43:80", "103.216.50.143:8080", "27.79.156.72:4007", "135.181.154.225:80", "103.231.78.36:80", "103.83.232.122:80", "203.243.63.16:80", "12.186.205.123:80", "27.79.175.17:4005", "41.65.224.71:1976", "216.65.13.43:80", "103.49.202.252:80", "185.191.236.162:3128", "49.249.155.3:80", "185.191.236.162:3128"]
for proxy in proxies:
yield proxy
novel_name = "牧神记"
params = {
"q": novel_name,
}
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36",
"X-Requested-With": "XMLHttpRequest"
}
session = requests.session() # 有cookie?
while 1:
try:
proxy_ip = next(prox())
proxy = {
'http': f"http://{proxy_ip}",
# 'https': f"https://{proxy_ip}" # 经测试,使用快代理的新人免费6小时IP中,使用https出现问题
}
resp = session.get("https://www.biqg.cc/user/search.html", params=params, headers=header)
i = 0
for item in resp.json():
print(f"序号:{i}\t小说名:{item['articlename']}\t作者:{item['author']}\t摘要:{item['intro']}")
i = i+1
break
number = input("请输入要爬小说的序号:")
print(resp.json()[number])
except:
print("未请求到,可能是网页限制,等20秒再来一次...")
time.sleep(20)
猪八戒爬需求接口【多线程-线程池--界面】
import tkinter as tk
from tkinter import ttk
from tkinter import messagebox
from threading import Thread
from concurrent.futures import ThreadPoolExecutor # 导入线程池执行器模块
from tkinter import filedialog
import requests
from lxml import etree
import openpyxl
def judge(list):
if list:
return list[0].replace("\n", "")
def spider(url, page, keyword):
params = {
'k': keyword,
'p': page
}
resp = requests.get(url, params=params)
et = etree.HTML(resp.text)
divs = et.xpath('//div[@class="search-result-list-task"]/div')
for div in divs:
commodity_url = judge(div.xpath('./a/@href'))
title = judge(div.xpath('./a/div[1]/div[1]/span[@class="task-names"]/text()'))
price = judge(div.xpath('./a/div[1]/div[@class="total-money"]/text()'))
mold = judge(div.xpath('./a/div[2]/span[@class="depict-refer"]/text()'))
details = judge(div.xpath('./a/div[@class="contents-text"]/text()'))
status = judge(div.xpath('./a/div[6]/div/span[@class="status-box"]/text()'))
release_time = judge(div.xpath('./a/div[6]/div/span[2]/text()'))
list = []
list.append(release_time)
list.append(status)
list.append(commodity_url)
list.append(title)
list.append(price)
list.append(details)
list.append(mold)
if list[0] is None:
continue
else:
list[0] = list[0].replace("发布", "")
print(list)
tree.insert("", "end", values=list)
def table():
print("开启爬虫")
# 标题 详情 需求类型 价格 发布时间 收费标准
keyword = entry1.get()
threads_number = int(entry2.get())
page = ""
url = "https://www.zbj.com/xq"
params = {
'k': keyword,
'p': page
}
resp = requests.get(url, params=params)
et = etree.HTML(resp.text)
all_page = et.xpath('//ul[@class="el-pager"]//text()')
print(f'一共{len(all_page)}页。')
with ThreadPoolExecutor(threads_number) as t: # 设定线程池执行器并行2个线程
for page in range(1, len(all_page) + 1, 1): # 提交len(all_page)个线程任务
t.submit(spider, url, page, keyword)
messagebox.showinfo("弹窗标题", "爬完了")
def excel():
print("获取表格数据")
# 弹出文件对话框,让用户选择保存位置和文件名
filename = filedialog.asksaveasfilename(defaultextension='.xlsx',
filetypes=[('Excel files', '*.xlsx')],
title='Save Excel file')
if filename:
workbook = openpyxl.Workbook()
sheet = workbook.active
# 获取列标题
columns = tree['columns']
for col_index, col_id in enumerate(columns, 1):
sheet.cell(row=1, column=col_index, value=col_id)
# 获取每行的数据并写入Excel
for row_index, item_id in enumerate(tree.get_children(), 2):
for col_index, col_id in enumerate(columns, 1):
cell_value = tree.item(item_id, 'values')[col_index - 1]
sheet.cell(row=row_index, column=col_index, value=cell_value)
# 保存Excel文件
workbook.save(filename)
def clear():
tree.delete(*tree.get_children())
def out_to_table():
t2 = Thread(target=table) # 创建线程
t2.start() # 启动线程
def out_to_excel():
t2 = Thread(target=excel) # 创建线程
t2.start() # 启动线程
# 设置默认输入文本
def on_entry_click(event):
if entry1.get() == "如:数据...":
entry1.delete(0, "end")
entry1.config(fg='black') # 设置文字颜色为黑色
overall_color = "lightblue"
text_color = "black"
button_color = "white"
# 创建主窗口
root = tk.Tk()
root.title("猪八戒需求采集")
# 获取屏幕宽度和高度
screen_width = root.winfo_screenwidth()
screen_height = root.winfo_screenheight()
# 计算窗口位置
x = (screen_width - 1080) // 2 # 计算窗口的x坐标
y = (screen_height - 600) // 2 # 计算窗口的y坐标
# 设置窗口大小和位置
root.geometry("1080x600+{}+{}".format(x, y))
# 设置界面背景颜色为浅蓝色
root.configure(background=overall_color)
# 创建关键字和输入框并放在同一行
search_frame = tk.Frame(root, bg=overall_color, pady=10)
search_frame.pack()
# 创建关键字
label = tk.Label(search_frame, text="输入需求关键词:", font=('SimSun', 16), bg=overall_color, fg=text_color)
label.pack(side="left", padx=10)
# 创建输入框
entry1 = tk.Entry(search_frame, font=('SimSun', 16), width=30, fg='grey') # 设置默认文字颜色为灰色
entry1.insert(0, "如:数据...") # 插入默认文字
entry1.bind("<FocusIn>", on_entry_click) # 绑定获得焦点时的事件
entry1.pack(side="left", padx=0)
# 创建线程数
label = tk.Label(search_frame, text="线程数:", font=('SimSun', 16), bg=overall_color, fg=text_color)
label.pack(side="left", padx=10)
# 创建输入框
entry2 = tk.Entry(search_frame, font=('SimSun', 16), width=30, fg='black') # 设置默认文字颜色为灰色
entry2.pack(side="left", padx=0)
# 创建搜索按钮和输出到桌面按钮并放在同一行
button_frame = tk.Frame(root, bg=overall_color)
button_frame.pack()
search_button = tk.Button(button_frame, text="开始搜索", font=('SimSun', 16), command=out_to_table)
search_button.pack(side="left", padx=10)
output_button = tk.Button(button_frame, text="输出到桌面excel", font=('SimSun', 16), command=out_to_excel)
output_button.pack(side="left", padx=10)
output_button = tk.Button(button_frame, text="clear", font=('SimSun', 16), command=clear)
output_button.pack(side="left", padx=10)
# 创建一个Frame作为列表容器
table_frame = tk.Frame(root, bg='white')
table_frame.pack(pady=20)
# 创建Treeview表格
columns = ("发布时间", "状态", "商品链接", "标题", "价格", "详情", "类型") # 定义列名
column_widths = [75, 45, 200, 250, 80, 250, 130] # 列宽
# 创建Treeview表格
tree = ttk.Treeview(table_frame, columns=columns, show="headings", height=23)
# 设置列标题和列宽
for col, width in zip(columns, column_widths):
tree.heading(col, text=col)
tree.column(col, width=width)
# 添加滚动条
scrollbar = ttk.Scrollbar(table_frame, orient="vertical", command=tree.yview)
tree.configure(yscrollcommand=scrollbar.set)
# 将Treeview和滚动条放入容器
tree.pack(side="left", fill="both", expand=True)
scrollbar.pack(side="right", fill="y")
# 启动主循环
root.mainloop()
电影天堂【使用代理】
import requests
def get_kuaidaili_proxy(url):
while True:
resp = requests.get(url)
if resp.json()['code'] == 0: # 预防代理返回的数据报错
for ip in resp.json()['data']['proxy_list']:
print("即将返回ip:", ip)
yield ip # 返回生成器对象
print("代理用完了,即将更新") # 预防代理用完
else:
print("获取代理IP出现异常. 重新获取!")
def spider(url, proxy_url):
while True:
try:
proxy_ip = next(get_kuaidaili_proxy(proxy_url))
proxy = {
'http': f"http://{proxy_ip}",
# 'https': f"https://{proxy_ip}" # 经测试,使用快代理的新人免费6小时IP中,使用https出现问题
}
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36"
}
resp = requests.get(url, headers=headers, proxies=proxy)
resp.encoding = "gbk"
return resp.text
except:
print("报错了,换个ip再来")
if __name__ == '__main__':
url = "https://www.dy2018.com/" # 要爬的链接
proxy_url = "https://dps.kdlapi.com/api/getdps/?secret_id=of33nmkfd07dlq2cyhl6&num=100&signature=68swwhszu8vjobh2mebil3ajchh4raaf&pt=1&format=json&sep=1" # 代理IP
for i in range(2):
print(spider(url, proxy_url))
梨视频视频爬取【包含防盗链】
# 1,拿到contId
# 2,拿到videoStatusi返回的json,->srcURL
# 3,srcURL里面的内容进行修整
# 4,下载视频
import requests
# 原帖子url
url = "https://www.pearvideo.com/video_1791745"
contID = url.split("_")[1]
videoStatus_url = f"https://www.pearvideo.com/videoStatus.jsp?contId={contID}&mrd=0.8583966782578469"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36',
# 防盗链:Referer,用于帮助网站溯源从哪个网站访问过来
'Referer': url
}
resp = requests.get(videoStatus_url, headers=headers).json()
systemTime = resp['systemTime']
srcUrl = resp['videoInfo']['videos']['srcUrl']
score_url = srcUrl.replace(systemTime, f"cont-{contID}")
print(score_url)
with open("./a.mp4", mode="wb") as f:
f.write(requests.get(score_url).content)
17K小说网提取个人小说数据【含登录操作-用session对象处理cookie】
法一:
通过session进行登录存储到cookie后进行提取数据
import requests
# 创建一个会话对象。
session = requests.session()
# 输入网站用户名和密码
loginName = ""
password = ""
# 1.先用session对象登录,进而获取到cookie保存在session中
url = "https://passport.17k.com/ck/user/login"
data = {
"loginName": loginName,
"password": password
}
session.post(url, data=data)
# print(resp.cookies) 查看session中的cookie
# 2. 通过session对象(登陆过一次,保存有cookie)和指定网址请求小说数据
resp = session.get('https://user.17k.com/ck/author/shelf?page=1&appKey=2406394919')
print(resp.json())
法二:
直接使用cookie进行提取数据,不建议使用,不够稳定
resp = requests.get("https://user.17k.com/ck/author/shelf?page=1&appKey=2406394919", headers={
"cookie": "GuTR-bbb5f65a-2fa2-400-0687-49840eaedadiis.channel-Qis.sss-webiuw distinctid 17700b35f65a-2fa2-400-0687-49840eaedadiis.channel-Qis.sss-webiuw distinctid 17705f65a-2fa2-400-0687-49840eaedadiis.channel-Qis.sss-webiuw distinctid 17705f65a-2fa2-400-0687-49840eaedadiis.channel-Qis.sss-webiuw distinctid 17705f65a-2fa2-400-0687-49840eaedadiis.channel-Qis.sss-webiuw distinctid 1770"
})
print(resp.text)
汽车之家-奥迪A8-口碑
目前只关注到了少数信息
import requests
def main():
params={
'pm': '3',
'seriesId': '146',
'pageIndex': '1',
'pageSize': '20',
'yearid': '0',
'ge': '0',
'seriesSummaryKey': '0',
'order': '0'
}
resp = requests.get("https://koubeiipv6.app.autohome.com.cn/pc/series/list", params=params)
list = resp.json()['result']["list"]
for item in list:
print(f'发表时间:{item["posttime"]}\t用户名:{item["username"]}\tKoubeiid:{item["Koubeiid"]}')
for i in item["scoreList"]:
print(f'{i["name"]}:{i["value"]}\t', end='')
print("\n>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>")
if __name__ == '__main__':
main()
猪八戒爬需求接口
输入要搜索的需求关键字,所有页的信息都会输出出来.
import requests
from lxml import etree
# 标题 详情 需求类型 价格 发布时间 收费标准
def judge(list):
if list:
return list[0].replace("\n", "")
keyword = "数据"
page = ""
url = "https://www.zbj.com/xq"
params = {
'k': keyword,
'p': page
}
resp = requests.get(url, params=params)
et = etree.HTML(resp.text)
all_page = et.xpath('//ul[@class="el-pager"]//text()')
print(f'一共{len(all_page)}页。')
for page in range(1, len(all_page)+1, 1):
# 巧妙的改参
resp = requests.get(url, params=params)
et = etree.HTML(resp.text)
divs = et.xpath('//div[@class="search-result-list-task"]/div')
for div in divs:
commodity_url = judge(div.xpath('./a/@href'))
title = judge(div.xpath('./a/div[1]/div[1]/span[@class="task-names"]/text()'))
price = judge(div.xpath('./a/div[1]/div[@class="total-money"]/text()'))
mold = judge(div.xpath('./a/div[2]/span[@class="depict-refer"]/text()'))
details = judge(div.xpath('./a/div[@class="contents-text"]/text()'))
status = judge(div.xpath('./a/div[6]/div/span[@class="status-box"]/text()'))
release_time = judge(div.xpath('./a/div[6]/div/span[2]/text()'))
print(f'{release_time} {status} {commodity_url}')
print(f'标题:{title} 价格:{price} 类型:{mold}')
print(f'详情:{details}')
print("\n")
print("下一页》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》")
优美图库小清新壁纸
import requests
from bs4 import BeautifulSoup
import os
os.mkdir("photo") # os模块,创建名为photo的文件夹,用来存放图片
url = "http://www.umeituku.com/bizhitupian/xiaoqingxinbizhi/"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36 Edg/120.0.0.0"
}
resp = requests.get(url, headers=headers)
resp.encoding = "utf-8"
if resp.status_code == 200:
page = BeautifulSoup(resp.text, "html.parser")
for item in page.find_all("a", attrs={"class": "TypeBigPics"}):
# print(item.get("href"))
child_resp = requests.get(item.get("href"), headers=headers)
child_resp.encoding = "utf-8"
# print(child_resp.text)
child_page = BeautifulSoup(child_resp.text, "html.parser")
img = child_page.find("div", attrs={"id": "ArticleId60"}).find("img")
img_alt = img.get("alt")
img_src = img.get("src")
print(img_alt, img_src)
img_resp = requests.get(img_src, headers=headers)
with open(f'./photo/{img_alt}.jpg', mode="wb") as f: # 以字节形式写入文件,所有mode必须是wb
f.write(img_resp.content) # 响应体中有字符串,用.text进行写入;有图片,用.content字节形式进行保存
print("图片下载完毕")
北京新发地菜市场
import requests
from bs4 import BeautifulSoup
url = "http://www.xinfadi.com.cn/getPriceData.html"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36 Edg/120.0.0.0"
}
resp = requests.get(url, headers=headers)
if resp.status_code == 200:
for item in resp.json()["list"]:
print(item)
油价
import requests
url = "https://download.jinriwenmi.com/v5/jryj.php"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36 Edg/120.0.0.0"
}
resp = requests.get(url, headers=headers)
if resp.status_code == 200:
# print(resp.json())
print(f'更新时间:{resp.json()["更新时间"]}')
print("上次油价调整:", resp.json()["油价调整最新消息"]["上次油价调整"].replace("\n", ""), "\n下次油价调整:",
resp.json()["油价调整最新消息"]["下次油价调整"].replace("\n", ""))
for item in resp.json()["各省油价"]:
if item["地区"] == "河南":
print(f'92号汽油:{item["92号汽油"]}')
print(f'98号汽油:{item["98号汽油"]}')
print(f'0号柴油:{item["0号柴油"]}')
随机笑话
import requests
url = "https://market.yizhishuwei.com/market/jokes/list"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36 Edg/120.0.0.0"
}
params = {
"key": "8c6665a0aad941ca817c5f0dca3a7582",
"count": 1
}
resp = requests.get(url, headers=headers, params=params)
if resp.status_code == 200:
for item in resp.json()["data"]:
print(item["text"])
历史上的今天
import requests
import time
url = "http://www.wudada.online/Api/ScLsDay"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36 Edg/120.0.0.0"
}
params = {
"month": time.localtime().tm_mon,
"day": time.localtime().tm_mday
}
resp = requests.get(url, headers=headers, params=params)
if resp.status_code == 200:
for item in resp.json()["data"]:
print(item["date"], item["title"])
迭代器
result=re.finditer(r"\d+","我今年18岁,我有200000000块")
for item in result:#从迭代器中拿到内容
print(item.group())#从匹配到的结果中拿到数据
正则表达式
元字符
具有特殊含义的特殊符号
常用元字符:
| 元字符 | 阐述 | ||
|---|---|---|---|
| . | 匹配除换行符以外的任意字符 ,未来在python的re模块中是一个坑 |
||
| ^ | 匹配字符串的开始 | ||
| $ | 匹配字符串的结尾 | ||
| \w | 匹配字母、数字、下划线 | \W | 匹配非字母、数字、下划线 |
| \d | 匹配数字 | \D | 匹配非数字 |
| \s | 匹配空白符 | \S | 匹配非空白符 |
| \n | 匹配一个换行符 | ||
| \t | 匹配一个制表符 | ||
| a|b | 匹配字符a或字符b | ||
| () | 匹配括号内的表达式,也表示一个组 | ||
| [...] | 匹配字符组中的字符 | [^...] | 匹配除了字符串组中字符的所有字符 |
量词:控制前面的元字符出现的次数
| 量词 | 阐述 |
|---|---|
| * | 重复 0 次或更多次 |
| + | 重复 1 次或更多次 |
| ? | 重复 0 次或 1 次 |
| 重复 n 次 | |
| 重复 n 次或更多次 | |
| 重复 n 次到 m 次 |
贪婪和惰性
| 匹配方式 | 阐述 |
|---|---|
| .* | 贪婪匹配【尽可能多的匹配】 |
| .*? | 惰性匹配【尽可能少的匹配】【回溯算法】 |
基础百度网页及写入文件【urllib】
- urllib 爬虫基础库(发送网络请求类)
- read( )
对于以可读模式(包括 r、r+、rb、rb+)打开open( )的文件,可以逐个字节(或者逐个字符)读取文件中的内容。
【如果文件是以文本模式(非二进制模式)打开的,则 read() 函数会逐个字符进行读取;反之,如果文件以二进制模式打开,则 read() 函数会逐个字节进行读取。】 - encode("utf-8") 以utf-8格式编码
decode("utf-8") 以utf-8格式解码 - charset中包含网页指定的解码格式。
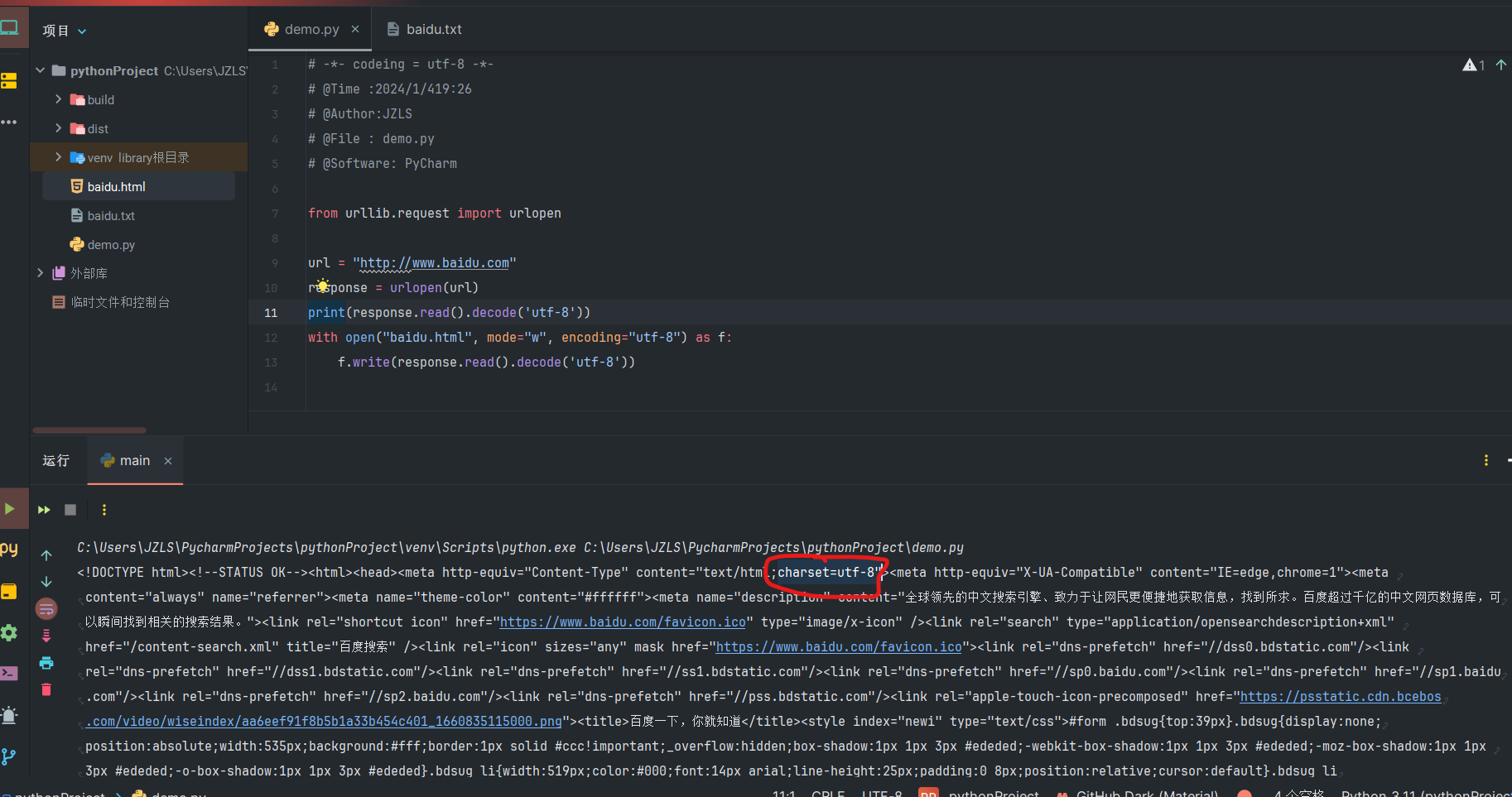
from urllib.request import urlopen
url = "http://www.baidu.com"
response = urlopen(url)
# print(response.read().decode('utf-8')) # 如果文件是以文本模式(非二进制模式)打开的,则 read() 函数会逐个字符进行读取;反之,如果文件以二进制模式打开,则 read() 函数会逐个字节进行读取。
with open("baidu.html", mode="w", encoding="utf-8") as f:
f.write(response.read().decode('utf-8'))
搜狗搜索
import requests
seekstr = input("请输入你要检索的内容:")
url = f"https://www.sogou.com/web?query={seekstr}"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
}
resp = requests.get(url=url, headers=headers)
# print(resp.request.headers)
print(resp.text)
百度翻译
import requests
url = "https://fanyi.baidu.com/sug"
data = {
"kw": input("请输入一个单词")
}
resp = requests.post(url, data=data)
print(resp.json()) # 拿到字典
豆瓣TOP250
流程:
- 拿到页面源代码
- 编写正则,提取页面数据
- 保存数据
import requests
import re
# 请求数据
number = 0
for number in range(0, 250, 25):
url = f"https://movie.douban.com/top250?start={number}&filter="
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 "
"Safari/537.36 Edg/120.0.0.0"
}
resp = requests.get(url, headers=headers)
print(resp.text)
# 解析数据
obj = re.compile(r'<div class="item">.*?<span class="title">(?P<title>.*?)</span>.*?'
r'<p class="">.*?导演: (?P<director>.*?) .*?'
r'<br>(?P<year>.*?) '
r'/ (?P<country>.*?) '
r'/ (?P<style>.*?) .*?property="v:'
r'average">(?P<stars>.*?)</span>.*?'
r'<span>(?P<number>.*?)人评价</span>.*?'
r'<span class="inq">(?P<sentence>.*?)</span>', re.S)
data = obj.finditer(resp.text)
for item in data:
print(item.group("title"), item.group("director"), item.group("year").strip(),
item.group("country"), item.group("style").strip(), item.group("stars"), item.group("number"),
item.group("sentence"))
# 写入数据
with open("./豆瓣TOP250.csv", mode="a", encoding="utf-8") as f:
f.write(f'{item.group("title")},{item.group("director")},'
f'{item.group("year").strip()},{item.group("country")},{item.group("style").strip()},'
f'{item.group("stars")},{item.group("number")},{item.group("sentence")}\n')
resp.close()
代码耗时计算
import time
start = time.time()
# 代码
print(time.time()-start)
打码
ddddocr模块
import ddddocr
ocr1 = ddddocr.DdddOcr() # 实例化
with open("图片路径", 'rb') as f:
img_bytes = f.read()
result_text = ocr1.classification(img_bytes)
print(result_text)
图鉴打码平台
打码
import base64
import json
import requests
# 一、图片文字类型(默认 3 数英混合):
# 1 : 纯数字
# 1001:纯数字2
# 2 : 纯英文
# 1002:纯英文2
# 3 : 数英混合
# 1003:数英混合2
# 4 : 闪动GIF
# 7 : 无感学习(独家)
# 11 : 计算题
# 1005: 快速计算题
# 16 : 汉字
# 32 : 通用文字识别(证件、单据)
# 66: 问答题
# 49 :recaptcha图片识别
# 二、图片旋转角度类型:
# 29 : 旋转类型
#
# 三、图片坐标点选类型:
# 19 : 1个坐标
# 20 : 3个坐标
# 21 : 3 ~ 5个坐标
# 22 : 5 ~ 8个坐标
# 27 : 1 ~ 4个坐标
# 48 : 轨迹类型
#
# 四、缺口识别
# 18 : 缺口识别(需要2张图 一张目标图一张缺口图)
# 33 : 单缺口识别(返回X轴坐标 只需要1张图)
# 五、拼图识别
# 53:拼图识别
def base64_api(uname, pwd, img, typeid):
with open(img, 'rb') as f:
base64_data = base64.b64encode(f.read())
b64 = base64_data.decode()
data = {"username": uname, "password": pwd, "typeid": typeid, "image": b64}
result = json.loads(requests.post("http://api.ttshitu.com/predict", json=data).text)
if result['success']:
return result["data"]["result"]
else:
#!!!!!!!注意:返回 人工不足等 错误情况 请加逻辑处理防止脚本卡死 继续重新 识别
return result["message"]
return ""
if __name__ == "__main__":
img_path = "C:/Users/Administrator/Desktop/file.jpg"
result = base64_api(uname='你的账号', pwd='你的密码', img=img_path, typeid=3)
print(result)
余额查询
import requests
def get_balance(uname, pwd):
params = {
'username': uname,
'password': pwd
}
resp = requests.get('http://api.ttshitu.com/queryAccountInfo.json', params=params).json()
if resp['success']:
print(f"请求成功:余额:{resp['data']['balance']} 花费掉的钱:{resp['data']['consumed']} 识别成功次数:{resp['data']['successNum']}")
else:
print(f"请求失败:{resp['message']}")
return ""
if __name__ == '__main__':
get_balance("JZLS", "20021112Aa~")
价格

细节
查看函数定义
- 鼠标移到函数上
- ctrl + 鼠标左键
易阻塞线程函数-IO操作
IO操作:即将数据写入内存或从内存输出的过程,也指应用程序和外部设备之间的数据传递,常见的外部设备包括文件、管道、网络连接。
I:就是input 、O:就是output 。
此时推荐使用协程(爬虫学习记录 -> 多线程与多进程 -> 协程)。
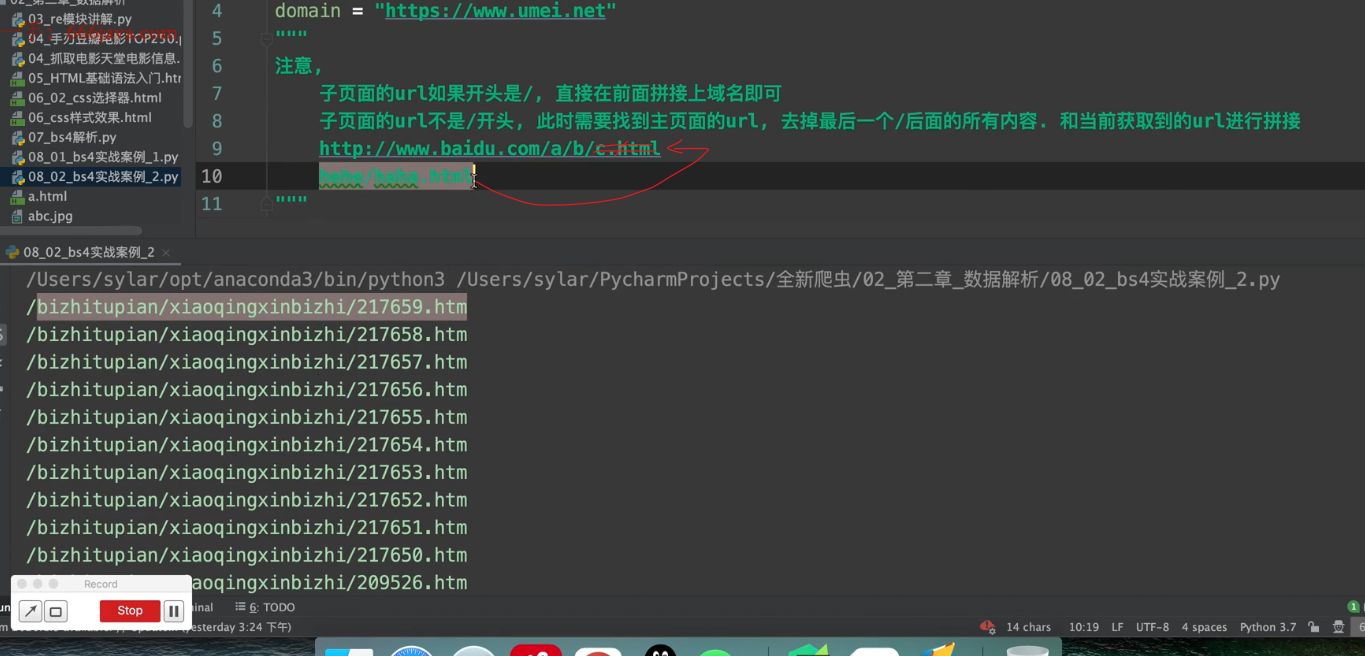
子页面url拼接方式【易错】
-
子页面的url以斜杠(/)开头:直接在前面拼接上域名
-
简洁方法:
from urllib import parse url1 = "http://www.591mm.com/mntt/6.html" url2 = "/mntt/dlmn/307677.html" url = parse.urljoin(url1, url2) print(url) # 此函数: # 若url2以 '/' 开头,则提取url1中的域名和url2进行拼接 # 若url2不以 '/' 开头,则提取url1最后一个'/'以及前面的内容并且和url2进行拼接
-
-
子页面的url不以斜杠(/)开头:需要找到主页面的urL -> 去掉最后一个斜杠(/)后面的所有内容 -> 和当前获取到的urL进行拼接
保存数据
| 响应体的格式 | 写入文件代码 | 保存格式 | 保存模式 |
|---|---|---|---|
| 字符串、json | f.write(resp.text) f.write(resp.json()["键"]) |
.txt .csv 等等 |
w |
| 图片、视频 | f.write(resp.content) | .jpg 等等 |
wb【二进制形式以字节形式保存图片】 |
各种码及解析方式
ç¾åº¦ä¸ä¸ï¼ä½ å°±ç¥é
用text属性获取了html内容出现unicode码
- 找到响应中的charset=utf-8【如果是gb2312则指定编码为gbk】
- 设置字符编码response.encoding 来匹配指定的编码
代码示例:
import requests
url = "http://www.baidu.com"
response = requests.get(url)
response.encoding = "utf-8"
print(response.text)
b'xe5xb0x8fxe7x8cxbfxe5x9cx88'
在python中,字符串必须编码成bytes后才能存到硬盘上
b开头的都代表是bytes类型,需要以utf-8编码格式来解码。
from urllib.request import urlopen
url = "http://www.baidu.com"
response = urlopen(url)
print(response.read().decode('utf-8'))
更多:[补充:bytes类型以及字符编码转换 - hanfe1 - 博客园 (cnblogs.com)](https://www.cnblogs.com/hanfe1/p/11493191.html#:~:text=b 'xe5xb0x8fxe7x8cxbfxe5x9cx88',%23b开头的都代表是bytes类型,是以16进制来显示的,2个16进制代表一个字节。 utf-8是3个字节代表一个中文,所以以上正好是9个字节)
\u5929\u6c14\u597d
unicode编码,需要以json格式解析
- response.text拿到的是文本
- response.json()拿到的是字典
import requests
url = "https://fanyi.baidu.com/sug"
hehe = {
"kw": input("请输入一个单词")
}
resp = requests.post(url, data=hehe)
# print(resp.text) # 拿到文本
print(resp.json()) # 拿到字典
注意:当相应不完全为json格式时,可用json.load(str)来转化为python对象。
