
深度学习之PyTorch实战(1)——基础学习及搭建环境
如果需要小编其他论文翻译,请移步小编的GitHub地址
传送门:请点击我
如果点击有误:https://github.com/LeBron-Jian/DeepLearningNote
最近在学习PyTorch框架,买了一本《深度学习之PyTorch实战计算机视觉》,从学习开始,小编会整理学习笔记,并博客记录,希望自己好好学完这本书,最后能熟练应用此框架。
PyTorch是美国互联网巨头Facebook在深度学习框架Torch的基础上使用Python重写的一个全新的深度学习框架,它更像NumPy的替代产物,不仅继承了NumPy的众多优点,还支持GPUs计算,在计算效率上要比NumPy有更明显的优势;不仅如此,PyTorch还有许多高级功能,比如拥有丰富的API,可以快速完成深度神经网络模型的搭建和训练。所以 PyTorch一经发布,便受到了众多开发人员和科研人员的追捧和喜爱,成为AI从业者的重要工具之一。
知识储备——深度学习中的常见概念
张量Tensor
Tensorflow中数据的核心单元就是Tensor。张量包含了一个数据集合,这个数据集合就是原始值变形而来的,它可以是一个任何维度的数据。tensor的rank就是其维度。
Rank本意是矩阵的秩,不过Tensor Rank和Matrix Rank的意义不太一样,这里就还叫Rank。Tensor Rank的意义看起来更像是维度,比如Rank =1就是向量,Rank=2 就是矩阵了,Rank = 0 就是一个值。
一:PyTorch中的Tensor
首先,我们需要学会使用PyTorch中的Tensor。Tensor在PyTorch中负责存储基本数据,PyTorch针对Tensor也提供了相对丰富的函数和方法,所以PyTorch中的Tensor与NumPy的数组具有极高的相似性。Tensor是一种高层次架构,也不要明白什么是深度学习,什么是后向传播,如何对模型进行优化,什么是计算图等技术细节。更重要的是,在PyTorch中定义的Tensor数据类型可以在GPUs上进行运算,而且只需要对变量做一些简单的类型转换就能轻易实现。
1.1 Tensor的数据类型
在使用Tensor时,我们首先要掌握如何使用Tensor来定义不同数据类型的变量。和Numpy差不多,PyTorch中的Tensor也有自己的数据类型定义方式,常用的如下:
1.1.1 torch.FloatTensor
此变量用于生成数据类型为浮点型的Tensor,传递给torch.FloatTensor的参数可以是一个列表,也可以是一个维度值。
>>> import torch >>> a = torch.FloatTensor(2,3) >>> print(a) -0.1171 0.0000 -0.1171 0.0000 0.0000 0.0000 [torch.FloatTensor of size 2x3] >>> b = torch.FloatTensor([2,3,4,5]) >>> print(b) 2 3 4 5 [torch.FloatTensor of size 4]
可以看到,打印输出的两组变量数据类型都显示为浮点型,不同的是,前一组的是按照我们指定的维度随机生成的浮点型Tensor,而另外一组是按照我们给定的列表生成的浮点型Tensor。
1.1.2 torch.IntTensor
用于生成数据类型为整型的Tensor,传递给torch.IntTensor的参数可以是一个列表,也可以是一个维度值。
>>> import torch >>> a = torch.IntTensor(2,3) >>> print(a) 0 0 4 0 1 0 [torch.IntTensor of size 2x3] >>> b = torch.IntTensor([2,3,4,5]) >>> print(b) 2 3 4 5 [torch.IntTensor of size 4]
可以看到,以上生成的两组Tensor最后显示的数据类型都为整型。
1.1.3 torch.rand
用于生成数据类型为浮点型且维度指定的随机Tensor,和在Numpy中使用numpy.rand生成随机数的方法类似,随机生成的浮点数据在0~1区间均匀分布。
>>> import torch >>> a = torch.rand(2,3) >>> print(a) 0.5528 0.6995 0.5719 0.4583 0.5745 0.1114 [torch.FloatTensor of size 2x3]
1.1.4 torch.randn
用于生成数据类型为浮点型且维度指定的随机Tensor,和在Numpy中使用numpy.randn生成随机数的方法类似,随机生成的浮点数的取值满足均值为0,方差为1的正太分布。
>>> import torch >>> a = torch.randn(2,3) >>> print(a) -0.5341 1.2267 -1.0884 0.4008 -1.8140 1.6335 [torch.FloatTensor of size 2x3]
1.1.5 torch.range
用于生成数据类型为浮点型且自定义其实范围和结束范围的Tensor,所以传递给torch.range的参数有三个,分别是范围的起始值,范围的结束值和步长,其中,步长用于指定从起始值到结束值的每步的数据间隔。
>>> import torch >>> a = torch.range(2,8,1) >>> print(a) 2 3 4 5 6 7 8 [torch.FloatTensor of size 7]
1.1.6 torch.zeros
用于生成数据类型为浮点型且维度指定的Tensor,不过这个浮点型的Tensor中的元素值全部为0.
>>> import torch >>> a = torch.zeros(2,3) >>> print(a) 0 0 0 0 0 0 [torch.FloatTensor of size 2x3]
1.2 Tensor的运算
这里通常对Tensor数据类型的变量进行运算,来组合一些简单或者复杂的算法,常用的Tensor运算如下:
1.2.1 torch.abs
将参数传递到torch.abs后返回输入参数的绝对值作为输出,输出参数必须是一个Tensor数据类型的变量。
import torch
a = torch.randn(2,3)
print(a)
b = torch.abs(a)
print(b)
tensor([[-0.4098, 0.5198, 0.2362],
[ 0.1903, 0.5537, 0.2249]])
tensor([[0.4098, 0.5198, 0.2362],
[0.1903, 0.5537, 0.2249]])
Process finished with exit code 0
1.2.2 torch.add
将参数传递到torch.add后返回输入参数的求和结果作为输出,输入参数既可以全部是Tensor数据类型的变量,也可以是一个Tensor数据类型的变量,另一个是标量。
import torch
a = torch.randn(2,3)
print(a)
b = torch.randn(2,3)
print(b)
c = torch.add(a,b)
print(c)
d = torch.randn(2,3)
print(d)
e = torch.add(d,10)
print(e)
tensor([[-1.4372, -1.3911, 0.5531],
[ 1.2329, -0.1978, 1.1220]])
tensor([[-1.2755, 0.7442, 1.3189],
[-0.0558, -1.0597, -0.5731]])
tensor([[-2.7127, -0.6468, 1.8720],
[ 1.1771, -1.2575, 0.5489]])
tensor([[ 0.7636, -0.1948, 2.3720],
[ 0.8740, 0.2431, -0.1906]])
tensor([[10.7636, 9.8052, 12.3720],
[10.8740, 10.2431, 9.8094]])
Process finished with exit code 0
如上所示,无论是调用torch.add对两个Tensor数据类型的变量进行计算,还是完成Tensor数据类型的变量和标量的计算,计算方式都和NumPy中的数组的加法运算如出一辙。
1.2.3 torch.clamp
对输入参数按照自定义的范围进行裁剪,最后将参数裁剪的结果作为输出。所以输入参数一共有三个,分别是需要进行裁剪的Tensor数据类型的变量、裁剪的上边界和裁剪的下边界,具体的裁剪过程是:使用变量中的每个元素分别和裁剪的上边界及裁剪的下边界的值进行比较,如果元素的值小于裁剪的下边界的值,该元素就被重写成裁剪的下边界的值;同理,如果元素的值大于裁剪的上边界的值,该元素就被重写成裁剪的上边界的值。
import torch
a = torch.randn(2,3)
print(a)
b = torch.clamp(a,-0.1,0.1)
print(b)
tensor([[ 0.0251, 1.8832, 1.5243],
[-0.1365, 1.2307, 0.0640]])
tensor([[ 0.0251, 0.1000, 0.1000],
[-0.1000, 0.1000, 0.0640]])
Process finished with exit code 0
1.2.4 torch.div
将参数传递到torch.div后返回输入参数的求商结果作为输出,同样,参与运算的参数可以全部是Tensor数据类型的变量,也可以是Tensor数据类型的变量和标量的组合。
import torch
a = torch.randn(2,3)
print(a)
b = torch.randn(2,3)
print(b)
c = torch.div(a,b)
print(c)
d = torch.randn(2,3)
print(d)
e = torch.div(d,10)
print(e)
tensor([[-0.1323, 0.3262, -0.1542],
[-0.7933, 1.9173, 0.3522]])
tensor([[-1.3476, 1.1644, -0.8035],
[-0.4051, 1.1651, 0.4930]])
tensor([[0.0981, 0.2801, 0.1919],
[1.9582, 1.6455, 0.7143]])
tensor([[-0.2241, -0.1561, 0.8274],
[ 1.9453, 0.3524, 0.3677]])
tensor([[-0.0224, -0.0156, 0.0827],
[ 0.1945, 0.0352, 0.0368]])
Process finished with exit code 0
1.2.5 torch.mul
将参数传递到 torch.mul后返回输入参数求积的结果作为输出,参与运算的参数可以全部是Tensor数据类型的变量,也可以是Tensor数据类型的变量和标量的组合。
import torch
a = torch.randn(2,3)
print(a)
b = torch.randn(2,3)
print(b)
c = torch.mul(a,b)
print(c)
d = torch.randn(2,3)
print(d)
e = torch.mul(d,10)
print(e)
tensor([[-0.7182, 1.2282, 0.0594],
[-1.2675, 0.0491, 0.3961]])
tensor([[-0.9145, 1.0164, -1.1200],
[ 1.0187, 0.7591, -2.1201]])
tensor([[ 0.6568, 1.2483, -0.0666],
[-1.2912, 0.0373, -0.8399]])
tensor([[-1.2548, 0.2213, -1.0233],
[ 0.9986, 0.1143, -0.5950]])
tensor([[-12.5477, 2.2128, -10.2334],
[ 9.9864, 1.1433, -5.9500]])
Process finished with exit code 0
1.2.6 torch.pow
将参数传递到torch.pow后返回输入参数的求幂结果作为输出,参与运算的参数可以全部是Tensor数据类型的变量,也可以是Tensor数据类型的变量和标量的组合。
import torch
a = torch.randn(2,3)
print(a)
b = torch.pow(a,2)
print(b)
tensor([[ 0.1484, -0.5102, -0.4332],
[ 0.9905, 0.5156, 2.8043]])
tensor([[0.0220, 0.2603, 0.1877],
[0.9811, 0.2658, 7.8641]])
Process finished with exit code 0
1.2.7 torch.mm
将参数传递到 torch.mm后返回输入参数的求积结果作为输出,不过这个求积的方式和之前的torch.mul运算方式不太样,torch.mm运用矩阵之间的乘法规则进行计算,所以被传入的参数会被当作矩阵进行处理,参数的维度自然也要满足矩阵乘法的前提条件,即前一个矩阵的行数必须和后一个矩阵的列数相等,否则不能进行计算。
import torch
a = torch.randn(2,3)
print(a)
b = torch.randn(3,2)
print(b)
b = torch.mm(a,b)
print(b)
tensor([[ 1.0980, -0.8971, 0.6445],
[ 0.3750, 1.8396, -0.8509]])
tensor([[-0.4458, 1.1413],
[-0.3940, 0.9038],
[ 1.0982, 0.7131]])
tensor([[ 0.5718, 0.9020],
[-1.8263, 1.4838]])
Process finished with exit code 0
1.2.8 torch.mv
将参数传递到torch.mv后返回输入参数的求积结果作为输出,torch.mv运用矩阵与向量之间的乘法规则进行计算,被传入的参数中的第1个参数代表矩阵,第2个参数代表向量,顺序不能颠倒。
import torch
a = torch.randn(2,3)
print(a)
b = torch.randn(3)
print(b)
c = torch.mv(a,b)
print(c)
tensor([[-1.1866, 0.1514, 0.8387],
[-0.1865, -1.5696, -2.4197]])
tensor([-0.7359, 0.6183, 0.5907])
tensor([ 1.4623, -2.2623])
Process finished with exit code 0
1.3 搭建一个简易神经网络
下面通过一个实例来看看如何使用已经掌握的知识,搭建出一个基于PyTorch架构的简易神经网络模型。
搭建神经网络模型的具体代码如下,这里讲完整的代码分为几部分进行详细介绍,以便大家了解。
1.3.1 导入包
代码的开始处是相关包的导入:
import torch batch_n = 100 hidden_layer = 100 input_data = 1000 output_data = 10
我们先通过import torch 导入必要的包,然后定义4个整型变量,其中:batch_n是在一个批次中输入数据的数量,值是100,这意味着我们在一个批次中输入100个数据,同时,每个数据包含的数据特征有input_data个,因为input_data的值是1000,所以每个数据的特征就是1000个,hidden_layer用于定义经过隐藏层后保留的数据特征的个数,这里有100个,因为我们的模型只考虑一层隐藏层,所以在代码中仅仅定义了一个隐藏层的参数;output_data是输出的数据,值是10,我们可以将输出的数据看作一个分类结果值得数量,个数10表示我们最后要得到10个分类结果值。
一个批次的数据从输入到输出的完整过程是:先输入100个具有1000个特征的数据,经过隐藏层后变成100个具有100个特征的数据,再经过输出层后输出100个具有10个分类结果值的数据,在得到输出结果之后计算损失并进行后向传播,这样一次模型的训练就完成了,然后训练这个流程就可以完成指定次数的训练,并达到优化模型参数的目的。
1.3.2 初始化权重
x = torch.randn(batch_n,input_data) y = torch.randn(batch_n,output_data) w1 = torch.randn(input_data,hidden_layer) w2 = torch.randn(hidden_layer,output_data)
在以上的代码中定义的从输入层到隐藏层,从隐藏层到输出层对应的权重参数,同在之前说到的过程中使用的参数维度是一致的,由于我们现在并没有好的权重参数的初始化方法,尽管这并不是一个好主意,可以看到,在代码中定义的输入层维度为(100,1000),输出层维度为(100,10),同时,从输入层到隐藏层的权重参数维度为(1000,100),从隐藏层到输出层的权重参数维度为(100,10),这里我们可能会好奇权重参数的维度是如何定义下来的,其实,只要我们把整个过程看作矩阵连续的乘法运算,就自然能够明白了,在代码中我们的真实值y也是通过随机的方式生成的,所以一开始在使用损失函数计算损失值时得到的结果会较大。
1.3.3 定义训练次数和学习效率
在定义好输入,输出和权重参数值之后,就可以开始训练模型和优化权重参数了,在此之前,我们还需要明确训练的总次数和学习效率,代码如下:
epoch_n = 20 learning_rate = 1e-6
由于接下来会使用梯度下降的方法来优化神经网络的参数,所以必须定义后向传播的次数和梯度下降使用的学习效率。在以上代码中使用了epoch_n定义训练的次数,epoch_n的值为20,所以我们需要通过循环的方式让程序进行20次训练,来完成对初始化权重参数的优化和调整。在优化的过程中使用的学习效率learning_rate的值为1e-6,表示0.000001,接下来对模型进行正式训练并对参数进行优化。
1.1.4 梯度下降优化神经网络的参数
下面代码通过最外层的一个大循环来保证我们的模型可以进行20次训练,循环内的是神经网络模型具体的前向传播和后向传播代码。参数的优化和更新使用梯度
for epoch in range(epoch_n):
h1 = x.mm(w1) # 100*1000
h1 = h1.clamp(min=0)
y_pred = h1.mm(w2) # 100*10
# print(y_pred)
loss = (y_pred - y).pow(2).sum()
print("Epoch:{} , Loss:{:.4f}".format(epoch, loss))
gray_y_pred = 2 * (y_pred - y)
gray_w2 = h1.t().mm(gray_y_pred)
grad_h = gray_y_pred.clone()
grad_h = grad_h.mm(w2.t())
grad_h.clamp_(min=0)
grad_w1 = x.t().mm(grad_h)
w1 -= learning_rate * grad_w1
w2 -= learning_rate * gray_w2
以上代码通过最外层的一个大循环来保证我们的模型可以进行20层训练,循环内的是神经网络模型具体的前向传播和后向传播代码,参数的优化和更新使用梯度下降来完成。在这个神经网络的前向传播中,通过两个连续的矩阵乘法计算出预测结果,在计算的过程中还对矩阵乘积的结果使用clamp方法进行裁剪,将小于零的值全部重新赋值于0,这就像加上了一个ReLU激活函数的功能。
前向传播得到的预测结果通过 y_pred来表示,在得到了预测值后就可以使用预测值和真实值来计算误差值了。我们用loss来表示误差值,对误差值的计算使用了均方误差函数。之后的代码部分就是通过实现后向传播来对权重参数进行优化了,为了计算方便,我们的代码实现使用的是每个节点的链式求导结果,在通过计算之后,就能够得到每个权重参数对应的梯度分别是grad_w1和grad_w2。在得到参数的梯度值之后,按照之前定义好的学习速率对w1和w2的权重参数进行更新,在代码中每次训练时,我们都会对loss的值进行打印输出,以方便看到整个优化过程的效果,所以最后会有20个loss值被打印显示。
1.1.5 打印结果及分析
Epoch:0 , Loss:55005852.0000 Epoch:1 , Loss:131827080.0000 Epoch:2 , Loss:455499616.0000 Epoch:3 , Loss:633762304.0000 Epoch:4 , Loss:23963018.0000 Epoch:5 , Loss:10820027.0000 Epoch:6 , Loss:6080145.5000 Epoch:7 , Loss:3903527.5000 Epoch:8 , Loss:2783492.7500 Epoch:9 , Loss:2160689.0000 Epoch:10 , Loss:1788741.0000 Epoch:11 , Loss:1549332.1250 Epoch:12 , Loss:1383139.6250 Epoch:13 , Loss:1259326.3750 Epoch:14 , Loss:1161324.7500 Epoch:15 , Loss:1080014.2500 Epoch:16 , Loss:1010260.2500 Epoch:17 , Loss:949190.7500 Epoch:18 , Loss:894736.6875 Epoch:19 , Loss:845573.3750 Process finished with exit code 0
可以看出,loss值从之前的巨大误差逐渐缩减,这说明我们的模型经过二十次训练和权重参数优化之后,得到的预测的值和真实值之间的差距越来越小了。
1.1.6 完整的代码如下:
# coding:utf-8
import torch
batch_n = 100
hidden_layer = 100
input_data = 1000
output_data = 10
x = torch.randn(batch_n, input_data)
y = torch.randn(batch_n, output_data)
w1 = torch.randn(input_data, hidden_layer)
w2 = torch.randn(hidden_layer, output_data)
epoch_n = 20
learning_rate = 1e-6
for epoch in range(epoch_n):
h1 = x.mm(w1) # 100*1000
h1 = h1.clamp(min=0)
y_pred = h1.mm(w2) # 100*10
# print(y_pred)
loss = (y_pred - y).pow(2).sum()
print("Epoch:{} , Loss:{:.4f}".format(epoch, loss))
gray_y_pred = 2 * (y_pred - y)
gray_w2 = h1.t().mm(gray_y_pred)
grad_h = gray_y_pred.clone()
grad_h = grad_h.mm(w2.t())
grad_h.clamp_(min=0)
grad_w1 = x.t().mm(grad_h)
w1 -= learning_rate * grad_w1
w2 -= learning_rate * gray_w2
二:自动梯度
我们在上面基于PyTorch深度学习框架搭建了一个简易神经网络模型,并通过在代码中使用前向传播和后向传播实现了对这个模型的训练和对权重参数的额优化,不过该模型在结构上很简单,而且神经网络的代码也不复杂。我们在实践中搭建的网络模型都是层次更深的神经网络模型,即深度神经网络模型,结构会有所变化,代码也会更复杂。对于深度的神经网络模型的前向传播使用简单的代码就能实现,但是很难实现涉及该模型中后向传播梯度计算部分的代码,其中最困难的就是对模型计算逻辑的梳理。
在PyTorch中提供了一种非常方便的方法,可以帮助我们实现对模型中后向传播梯度的自动计算,避免了“重复造轮子”,这就是接下来要学习的torch.autograd包,通过torch.autograd包,可以使模型参数自动计算在优化过程中需要用到的梯度值,在很大程度上帮助降低了实现后向传播代码的复杂度。
2.1 torch.autograd和Variable
torch.autograd包的主要功能是完成神经网络后向传播中的链式求导,手动实现链式求导的代码会给我们造成很大的困扰,而torch.autograd包中丰富的类减少了这些不必要的麻烦。
实现自动梯度功能的过程大概分为以下几步:
1 通过输入的Tensor数据类型的变量在神经网络的前向传播过程中生成一张计算图 2 根据这个计算图和输出结果准确计算出每个参数需要更新的梯度 3 通过完成后向传播完成对参数梯度的更新
在实践中完成自动梯度需要用到torch.autograd包中的Variable类对我们定义的Tensor数据类型变量进行封装,在封装后,计算图中的各个节点就是一个variable 对象,这样才能应用自动梯度的功能。autograd package是PyTorch中所有神经网络的核心。先了解一些基本知识,然后开始训练第一个神经网络。autograd package提供了Tensors上所有运算的自动求导功能。它是一个按运行定义(define-by-run)的框架,这意味着反向传播是依据代码运行情况而定义的,并且每一个单次迭代都可能不相同。
autograd.Variable 是这个package的中心类。它打包了一个Tensor,并且支持几乎所有运算。一旦你完成了你的计算,可以调用.backward(),所有梯度就可以自动计算。
你可以使用.data属性来访问原始tensor。相对于变量的梯度值可以被积累到.grad中。
这里还有一个类对于自动梯度的执行是很重要的:Function(函数)
变量和函数是相互关联的,并且建立一个非循环图。每一个变量有一个.grad_fn属性,它可以引用一个创建了变量的函数(除了那些用户创建的变量——他们的grad_fn是空的)。
如果想要计算导数,可以调用Variable上的.backward()。如果变量是标量(只有一个元素),你不需要为backward()确定任何参数。但是,如果它有多个元素,你需要确定grad_output参数(这是一个具有匹配形状的tensor)。
如果已经按照如上的方式完成了相关操作,则在选中了计算图中的某个节点时,这个节点必定是一个Variable对象,用X表示我们选中的节点,那么X.data代表Tensor数据类型 的变量,X.grad也是一个Variable对象,不过他代表的是X的梯度,在想访问梯度值的时候需要X.grad.data
下面通过一个自动剃度的实例来看看如何使用torch.autograd.Variable类和torch.autograd包,我们同样搭建一个二层结构的神经网络模型,这有利于我们之前搭建的简易神经网络模型的训练和优化过程进行对比,重新实现。
2.1.1 导入包
代码的开始处是相关包的导入,但是在代码中增加一行,from torch.autograd import Variable,之前定义的不变:
import torch from torch.autograd import Variable # 批量输入的数据量 batch_n = 100 # 通过隐藏层后输出的特征数 hidden_layer = 100 # 输入数据的特征个数 input_data = 1000 # 最后输出的分类结果数 output_data = 10
其中:batch_n是在一个批次中输入数据的数量,值是100,这意味着我们在一个批次中输入100个数据,同时,每个数据包含的数据特征有input_data个,因为input_data的值是1000,所以每个数据的特征就是1000个,hidden_layer用于定义经过隐藏层后保留的数据特征的个数,这里有100个,因为我们的模型只考虑一层隐藏层,所以在代码中仅仅定义了一个隐藏层的参数;output_data是输出的数据,值是10,我们可以将输出的数据看作一个分类结果值得数量,个数10表示我们最后要得到10个分类结果值。
2.1.2 初始化权重
x = Variable(torch.randn(batch_n , input_data) , requires_grad = False) y = Variable(torch.randn(batch_n , output_data) , requires_grad = False) w1 = Variable(torch.randn(input_data,hidden_layer),requires_grad = True) w2 = Variable(torch.randn(hidden_layer,output_data),requires_grad = True)
“Variable(torch.randn(batch_n, input_data), requires_grad = False)”这段代码就是之前讲到的用 Variable类对 Tensor数据类型变量进行封装的操作。在以上代码中还使用了一个requires_grad参数,这个参数的赋值类型是布尔型,如果requires_grad的值是False,那么表示该变量在进行自动梯度计算的过程中不会保留梯度值。我们将输入的数据x和输出的数据y的requires_grad参数均设置为False,这是因为这两个变量并不是我们的模型需要优化的参数,而两个权重w1和w2的requires_grad参数的值为True
2.1.3 定义训练次数和学习效率
在定义好输入,输出和权重参数值之后,就可以开始训练模型和优化权重参数了,在此之前,我们还需要明确训练的总次数和学习效率,代码如下:
epoch_n = 20 learning_rate = 1e-6
和之前一样,在以上代码中使用了epoch_n定义训练的次数,epoch_n的值为20,所以我们需要通过循环的方式让程序进行20次训练,来完成对初始化权重参数的优化和调整。在优化的过程中使用的学习效率learning_rate的值为1e-6,表示0.000001,接下来对模型进行正式训练并对参数进行优化。
2.1.4 新的模型训练和参数优化
下面代码通过最外层的一个大循环来保证我们的模型可以进行20次训练,循环内的是神经网络模型具体的前向传播和后向传播代码。参数的优化和更新使用梯度
for epoch in range(epoch_n):
y_pred = x.mm(w1).clamp(min= 0 ).mm(w2)
loss = (y_pred - y).pow(2).sum()
print("Epoch:{} , Loss:{:.4f}".format(epoch, loss.data))
loss.backward()
w1.data -= learning_rate * w1.grad.data
w2.data -= learning_rate * w2.grad.data
w1.grad.data.zero_()
w2.grad.data.zero_()
和之前的代码相比,当前的代码更简洁了,之前代码中的后向传播计算部分变成了新代码中的 loss.backward(),这个函数的功能在于让模型根据计算图自动计算每个节点的梯度值并根据需求进行保留,有了这一步,我们的权重参数 w1.data和 w2.data就可以直接使用在自动梯度过程中求得的梯度值w1.data.grad和w2.data.grad,并结合学习速率来对现有的参数进行更新、优化了。在代码的最后还要将本次计算得到的各个参数节点的梯度值通过grad.data.zero_()全部置零,如果不置零,则计算的梯度值会被一直累加,这样就会影响到后续的计算。同样,在整个模型的训练和优化过程中,每个循环都加入了打印loss值的操作,所以最后会得到20个loss值的打印输出。
2.1.5 打印结果及分析
Epoch:0 , Loss:51193236.0000 Epoch:1 , Loss:118550784.0000 Epoch:2 , Loss:451814400.0000 Epoch:3 , Loss:715576704.0000 Epoch:4 , Loss:21757992.0000 Epoch:5 , Loss:11608872.0000 Epoch:6 , Loss:7414747.5000 Epoch:7 , Loss:5172238.5000 Epoch:8 , Loss:3814624.2500 Epoch:9 , Loss:2930500.2500 Epoch:10 , Loss:2325424.0000 Epoch:11 , Loss:1895581.7500 Epoch:12 , Loss:1581226.2500 Epoch:13 , Loss:1345434.7500 Epoch:14 , Loss:1164679.7500 Epoch:15 , Loss:1023319.6875 Epoch:16 , Loss:910640.1875 Epoch:17 , Loss:819365.0625 Epoch:18 , Loss:743999.4375 Epoch:19 , Loss:680776.3750 Process finished with exit code 0
可以看出,对参数的优化在顺利进行,因为loss值也越来越低。
2.2 自定义传播函数
其实除了可以采用自动梯度方法,我们还可以通过构建一个继承了torch.nn.Module的新类,来完成对前向传播函数和后向传播函数的重写。在这个新类中,我们使用forward作为前向传播函数的关键字,使用backward作为后向传播函数的关键字。下面介绍如何使用自定义传播函数的方法,来调整之前具备自动梯度功能的简易神经网络模型。整个代码的开始部分如下:
#_*_coding:utf-8_*_ import torch from torch.autograd import Variable # 批量输入的数据量 batch_n = 100 # 通过隐藏层后输出的特征数 hidden_layer = 100 # 输入数据的特征个数 input_data = 1000 # 最后输出的分类结果数 output_data = 10
和之前的代码一样,在代码的开始部分同样是导入必要的包、类,并定义需要用到的4 个变量。下面看看新的代码部分是如何定义我们的前向传播 forward 函数和后向传播backward函数的:
class Model(torch.nn.Module):
def __init__(self):
super(Model,self).__init__()
def forward(self,input,w1,w2):
x = torch.mm(input,w1)
x = torch.clamp(x,min=0)
x = torch.mm(x,w2)
return x
def backward(self):
pass
以上代码展示了一个比较常用的Python类的构造方式:首先通过class Model(torch.nn.Module)完成了类继承的操作,之后分别是类的初始化,以及forward函数和backward函数。forward函数实现了模型的前向传播中的矩阵运算,backward实现了模型的后向传播中的自动梯度计算,后向传播如果没有特别的需求,则在一般情况下不用进行调整。在定义好类之后,我们就可以对其进行调用了,代码如下:
model = Model()
这一系列操作相当于完成了对简易神经网络的搭建,然后就只剩下对模型进行训练和对参数进行优化的部分了,代码如下:
#_*_coding:utf-8_*_
import torch
from torch.autograd import Variable
# 批量输入的数据量
batch_n = 100
# 通过隐藏层后输出的特征数
hidden_layer = 100
# 输入数据的特征个数
input_data = 1000
# 最后输出的分类结果数
output_data = 10
x = Variable(torch.randn(batch_n , input_data) , requires_grad = False)
y = Variable(torch.randn(batch_n , output_data) , requires_grad = False)
w1 = Variable(torch.randn(input_data,hidden_layer),requires_grad = True)
w2 = Variable(torch.randn(hidden_layer,output_data),requires_grad = True)
# 训练次数设置为20
epoch_n = 20
# 将学习效率设置为0.000001
learning_rate = 1e-6
for epoch in range(epoch_n):
# y_pred = x.mm(w1).clamp(min= 0 ).mm(w2)
y_pred = model(x, w1, w2)
loss = (y_pred - y).pow(2).sum()
print("Epoch:{} , Loss:{:.4f}".format(epoch, loss.data[0]))
loss.backward()
w1.data -= learning_rate * w1.grad.data
w2.data -= learning_rate * w2.grad.data
w1.grad.data.zero_()
w2.grad.data.zero_()
这里,变量的赋值、训练次数和学习速率的定义,以及模型训练和参数优化使用的代码,和在 6.2.1节中使用的代码没有太大的差异,不同的是,我们的模型通过“y_pred =model(x, w1, w2)”来完成对模型预测值的输出,并且整个训练部分的代码被简化了。在20次训练后,20个loss值的打印输出如下:
Epoch:0 , Loss:39938204.0000 Epoch:1 , Loss:49318664.0000 Epoch:2 , Loss:147433040.0000 Epoch:3 , Loss:447003584.0000 Epoch:4 , Loss:418029088.0000 Epoch:5 , Loss:4521120.5000 Epoch:6 , Loss:3043527.5000 Epoch:7 , Loss:2294490.0000 Epoch:8 , Loss:1862741.6250 Epoch:9 , Loss:1583754.6250 Epoch:10 , Loss:1384331.2500 Epoch:11 , Loss:1230558.5000 Epoch:12 , Loss:1105670.1250 Epoch:13 , Loss:1000757.3750 Epoch:14 , Loss:910758.0625 Epoch:15 , Loss:832631.0625 Epoch:16 , Loss:764006.6250 Epoch:17 , Loss:703198.6875 Epoch:18 , Loss:649156.8125 Epoch:19 , Loss:600928.8750 Process finished with exit code 0
三:windows上安装pytorch
3.1 在线安装
PyTorch官网:https://pytorch.org/
3.1.1,进入官网
安装该库就要到官网上去找安装方法,打开官网页面如下:

3.1.2 点击Get Started
在官网页面向下划,滑到Get Started页面如下所示,run this command后面对应的命令即安装命令,右侧区域为电脑系统以及CUDA版本的选择,通过选择你电脑的配置来决定run this command后面对应的安装命令。
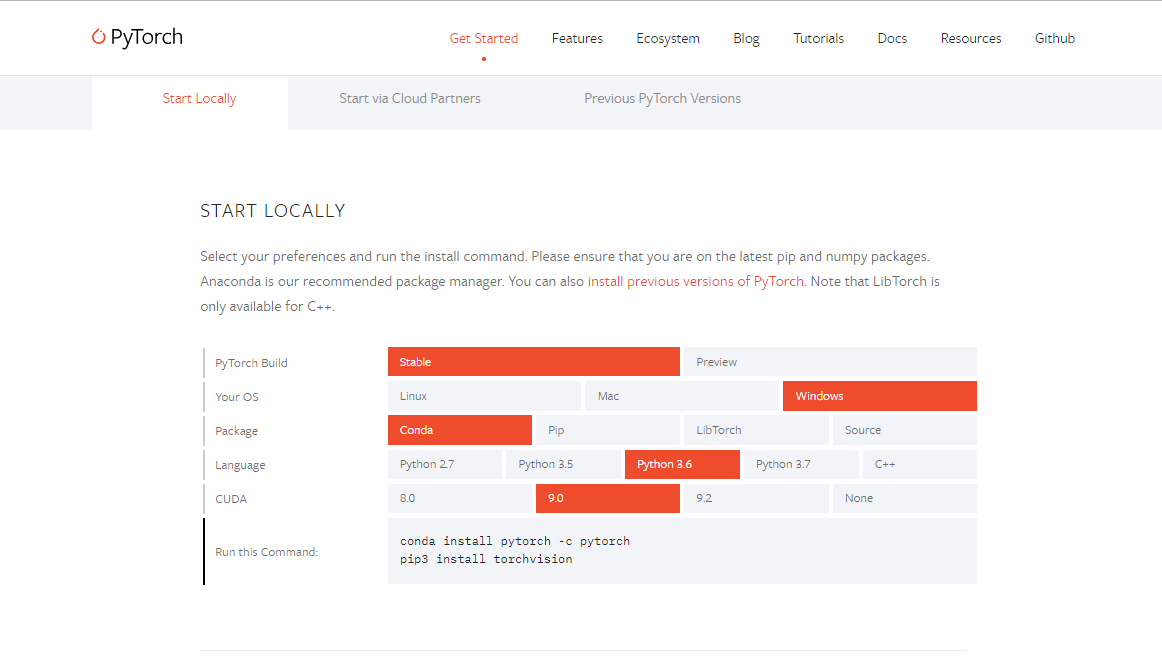
3.1.3 按照自己Windows的配置进行点击
下图是我的电脑的配置,我选择的是Windows系统,此处要根据你的选择,之后选择你的命令方式,我是使用pip命令的,Python的环境选择,根据的python环境配置来选择。
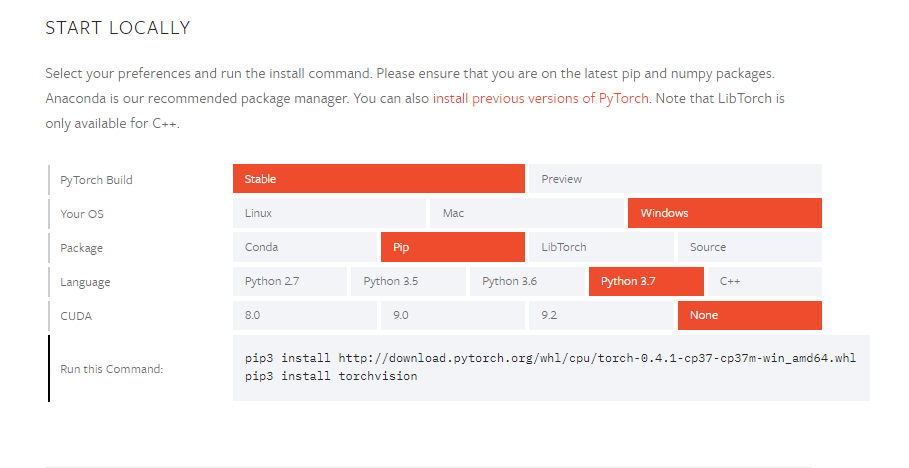
3.1.4 进入pip
打开命令窗口,输入如下代码,然后回车,如下图所示开始安装
(记得认真看自己的python版本和型号,要是32位的,就无法安装,这是坑!!)
pip3 install http://download.pytorch.org/whl/cpu/torch-0.4.1-cp37-cp37m-win_amd64.whl pip3 install torchvision
安装好如下(由于是国外网站,所以下载速度比较慢):

3.1.5 安装torchvision
pip install torchvision
3.2 离线安装
本来我想着:如果需要直接迁移环境,可以这样做,直接去自己安装好的环境包里面,找到torch和torchvision文件夹,比如我的:
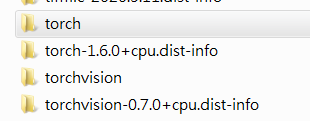
复制文件夹,放到自己需要迁移的文件夹里,即可。不过这里需要强调的是torch所需要的依赖太多了。所以单纯的迁移环境会出问题。报错如下:
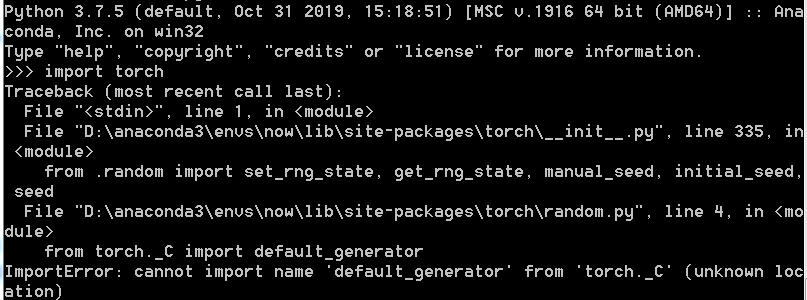
所以需要本本分分的先把依赖环境安装,一步一步的走。
3.2.1 进入官网,查看whl
进入https://download.pytorch.org/whl/torch_stable.html 页面,查看自己对应的版本,离线安装:

3.2.2 首先需要安装需要的基础包
比如我的包是:

如果直接pip install,必然会出问题。所以这里我总结一下自己踩过的坑。
首先,torch需要安装的依赖如下:
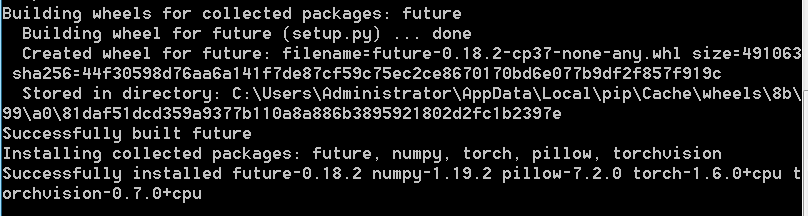
所以我们需要安装版本大于 0.18的 future,版本大于1.19的 numpy和版本大于 7.2的 pillow。
同时,这里再做一个尝试,我将这三个包文件和torch,torchvision包一起放入site-packages中,看效果如何:
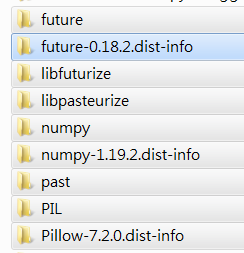
效果如下:
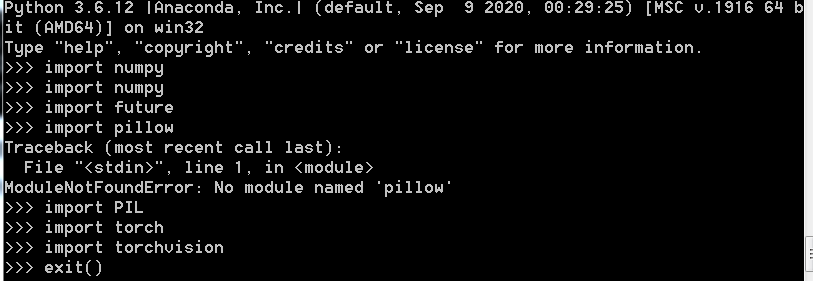
成功。
所以,我们只需要下载对应版本的 whl然后安装即可。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号