
深度学习论文翻译解析(一):YOLOv3: An Incremental Improvement
论文标题: YOLOv3: An Incremental Improvement
论文作者: Joseph Redmon Ali Farhadi
YOLO官网:YOLO: Real-Time Object Detection
https://pjreddie.com/darknet/yolo/
论文链接:https://pjreddie.com/media/files/papers/YOLOv3.pdf
YOLOv3论文地址:https://arxiv.org/abs/1804.02767
声明:小编翻译论文仅为学习,如有侵权请联系小编删除博文,谢谢!
小编是一个机器学习初学者,打算认真研究论文,但是英文水平有限,所以论文翻译中用到了Google,并自己逐句检查过,但还是会有显得晦涩的地方,如有语法/专业名词翻译错误,还请见谅,并欢迎及时指出。
如果需要小编其他论文翻译,请移步小编的GitHub地址
传送门:请点击我
如果点击有误:https://github.com/LeBron-Jian/DeepLearningNote
YOLO 算法的基本思想是:首先特征提取网络对输入图像提取特征,得到一定 size 的 feature map,比如 13*13,然后将输入图像分为 13*13 个 grid cell,接着如果 ground truth 中某个 object 的中心坐标落在哪个 grid cell 中,那么就由该 grid cell 来预测该 object,因为每个 grid cell 都会预期固定数量的 bounding box(YOLOv1 中是2个,YOLOv2中是5个,YOLOv3中是3个,这结果 bounding box 的初始 size 是不一样的),那么这几个 bounding box中最终是由哪一个来预测该 object?答案是:这几个 bounding box 中只有和 ground truth 的 IOU 最大的 bounding box 才是用来预测该 object 的。可以看出预测得到的输出 feature map 有两个维度是提取到的特征的维度,比如 13*13,还有一个维度(深度)是 B*(5+C) ,注意:YOLOv1中是 (B*5+C),其中B表示每个 grid cell 预测的 bounding box的数量,比如 YOLOv1 中是2个,YOLOv2中是5个,YOLOv3中是3个,C表示 bounding box的类别数(没有背景类,所以对于VOC是20个),5表示4个坐标信息和一个置信度(objectness score)。

摘要
我们为YOLO提供了一系列更新!它包含一堆小设计,可以是系统的性能得到更新;也包含一个新训练的,非常好的神经网络。虽然比上一版更大一些,但是精度也提高了。不用担心,虽然体量大了,它的速度还是有保障的。在输入320×320的图片后,YOLOv3能在22毫秒内完成处理,并取得28.2mAP的成绩。它的精度和SSD相当,但速度要快上3倍。和旧版数据相比,v3版进步明显。在Titan X环境下,YOLOv3的检测精度为57.9 AP50,用时51ms;而RetinaNet的精度只有57.5 AP50,但却需要198ms,相当于YOLOv3的3.8倍。

一,引言
有时候,一年你主要只是在玩手机,你知道吗?今年我没有做很多研究。我在Twitter上花了很多时间。玩了一下GAN。去年我留下了一点点的精力[12] [1];我设法对YOLO进行了一些改进。但是诚然,没有什么比这超级有趣的了,只是一小堆(bunch)改变使它变得更好。我也帮助了其他人的做一些研究。
其实,这就是今天我要讲的内容。我们有一篇论文快截稿了,但还缺一篇关于YOLO更新内容的文章作为引用来源,我们没写,所以以下就是我们的技术报告!
关于技术报告的好处是他们不需要介绍,你们都知道我写这个的目的,对吧。所以这段“引言”可以作为你阅读的一个指引。首先我们会告诉你YOLOv3的更新情况,其次我们会展示更新的方法以及一些失败的尝试,最后就是对这轮更新的意义的总结。

二,更新
谈到YOLOv3的更新情况,其实大多数时候我们就是直接把别人的好点子拿来用了。我们还训练了一个新的,比其他网络更好的分类网络。为了方便你理解,让我们从头开始慢慢介绍。

2.1 边界框预测
在YOLO9000后,我们的系统开始用dimension clusters固定anchor box来选定边界框。神经网络会为每个边界框预测4个坐标:tx,ty,tw,th(tx, ty, tw, th 就是模型的预测输出)。如果目标cell距离图像左上角的边距是(cx,cy),且它对应边界框的宽和高为pw,ph(pw, ph 表示预测前 bounding box的 size,bx, by, bw 和 bh 就是预测得到的 bounding box的中心的坐标和 size。),坐标的损失采用的是平方误差损失,那么网络的预测值会是:
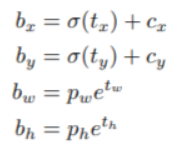
比如某一层的 feature map的大小为 13*13, 那么grid cell 就有 13*13个,第 0 行第一列的 grid cell 的坐标 cx 就是 0, cy 就是 1。

在训练期间,我们会计算方差。如果预测坐标的ground truth是t^*,那么响应的梯度就是ground truth值和预测值的差:t^*-t*。利用上述公式,我们能轻松推出这个结论。


YOLOv3用逻辑回归预测每个边界框的objectness score。如果当前预测的边界框比之前的更好地与ground truth对象重合,那它的分数就是1。如果当前的预测不是最好的,但它和ground truth对象重合到了一定阈值以上,神经网络会忽视这个预测[15]。我们使用的阈值是 0.5。与[15]不同,我们的系统只为每个ground truth对象分配一个边界框。如果先前的边界框并未分配给相应对象,那它只是检测错了对象,而不会对坐标或分类预测造成影响。
类别预测方面主要是将原来的单标签分类改进为多标签分类,因此网络结构上就将原来用于单标签多分类的 softmax 层换成用于多标签多分类的逻辑回归层。首先说明一下为什么要做这样的修改,原来分类网络中的 softmax 层都是假设一张图或一个 object 只属于一个类别,但是在一些复杂场景下,一个 object 可能属于多个类,比如你的类别中有woman和 person 两个类,这就是多标签分类,需要用逻辑回归层来对每个类别做二分类。逻辑回归层主要用到 Sigmoid函数,该函数可以将输入约束在 0~1 的范围内,因此当一张图片经过特征提取后的某一类输出经过 Sigmoid 函数约束后如果大于 0.5, 就表示属于该类。

2.2 分类预测
每个边界框都会使用多标记分类来预测框中可能包含的类。我们不用softmax,而是用单独的逻辑分类器,因为我们发现前者对于提升网络性能没什么作用。在训练过程中,我们用二元交叉熵损失来预测类别。
这个规划有助于我们把YOLO用于更复杂的领域,如开放的图像数据集。这个数据集中包含了大量重叠的标签(如女性和人)。如果我们用的是softmax,它会强加一个假设,使得每个框只包含一个类别。但通常情况下这样的做法是不妥的,相比之下,多标记的分类方法能更好的模拟数据。

2.3 跨尺度预测
YOLOv3提供3种尺寸不一的边界框。我们的系统用相似的概念提取这些尺寸的特征,以形成金字塔形网络。我们在基本特征提取器中增加了几个卷积层,并用最后的卷积层预测一个三维张量编码:边界框,框中目标和分类预测。在COCO数据集实验中,我们的神经网络分别为每种尺寸各预测了三个边界框,所以得到的张量是N ×N ×[3∗(4+ 1+ 80)],其中包含4个边界框offset、1个目标预测以及80种分类预测。

接着,我们从前两个图层中得到特征图,并对它进行2次上采样。再从网络更早的图层中获得特征图,用element-wise把高低两种分辨率的特征图连接到一起。这样做能使我们找到早期特征映射中的上采样特征和细粒度特征,并获得更有意义的语义信息。之后,我们添加几个卷积层来处理这个特征映射组合,并最终预测出一个相似的、大小是原先两倍的张量。
我们用同样的网络设计来预测边界框的最终尺寸,这个过程其实也有助于分类预测,因为我们可以从早期图像中筛选出更精细的特征。
和上一版一样,YOLOv3使用的聚类方法还是K-Means,它能用来确定边界框的先验。在实验中,我们选择了9个聚类和3个尺寸,然后在不同尺寸的边界框上均匀分割维度聚类。在COCO数据集上,这9个聚类分别是:(10×13)、(16×30)、(33×23)、(30×61)、(62×45)、(59×119)、(116 × 90)、(156 × 198)、(373 × 326)。
YOLO v3 采用多个 scale 融合的方式做预测。原来的YOLO v2 有一个层叫:passthrough layer,假设最后提取的 feature map的size 是 13*13,那么这个层的作用就是将前面一层的 26*26 的 feature map 和本层的 13*13 的 feature map 进行连接,有点像 ResNet。当时这么操作也是为了加强 YOLO 算法对小目标检测的精确度。这个思想在 YOLO V3 中得到了进一步加强,在YOLO v3中采用类似 FPN的 upsample 和 融合做法(最后融合了3个scale,其他两个scale的大小分别是 26*26 和 52*52),在多个 scale 的 feature map上做检测。

2.4 特征提取器
我们使用一个新的网络来提取特征,它融合了YOLOv2,Darknet-19以及其他新型残差网络,由连续的3x3和1x1卷积层组合而成,当然,其中也添加了一些shortcut connection,整体体量也更大。因为一共有53个卷积层,所以我们称它为……别急哦…… Darknet-53!

DarkNet-53(网络结构),一方面基本采用了全卷积(YOLO v2 中采用了 pooling 层做 feature map 的 sample,这里都换成卷积层来做了。),另一方面引入了 residual 结构(YOLO v2 中还是类似 VGG 那样直筒型的网络结构,层数太多训练起来会有梯度问题,所以DarkNet-19 也就 19 层,因此得益于 ResNet 的 Residual 结构,训练层网络难度大大降低,因此这里将网络做到 53层,精度提升比较明显)。DarkNet-53 只是特征提取层,源码中只使用 pooling 层前面的卷积层来提取特征,因此 multi-scale 的特征融合和预测支路并没有在该网络结构中体现。
预测支路采用的也是全卷积的结构,其中最后一个卷积层的卷积核个数是 255,是针对COCO数据集的 80 类:3*(80+4+1)=255,表示一个 grid cell 包含 3 个 bounding box,4表示框的 4个坐标信息, 1 表示 objectness score。模型训练方面还是采用原来 YOLO v2 的 multi-scale training。

这个新网络在性能上远超Darknet-19 ,但是在效率上同样由于ResNet-101和ResNet-152。下表是在ImageNet上的实验结果:

每个网络都使用相同的设置进行训练,输入256×256的图片,并进行单精度测试。运行环境为Titan X。我们得出的结论是Darknet-53在精度上可以与最先进的分类器相媲美,同时它的浮点运算更少,速度也更快。和ResNet-101相比,Darknet-53的速度是前者的1.5倍;而ResNet-152和它性能相似,但用时却是它的2倍以上。
Darknet-53也可以实现每秒最高的测量浮点运算。这意味着网络结构可以更好地利用GPU,使其预测效率更高,速度更快。这主要是因为ResNets的层数太多,效率不高。

2.5 训练
我们只是输入完整的图像,并没有做其他处理。实验过程中设计的多尺寸训练,大量数据增强和batch normalization等操作均符合标准。模型训练和测试的框架是Darknet神经网络。


3 我们做了什么
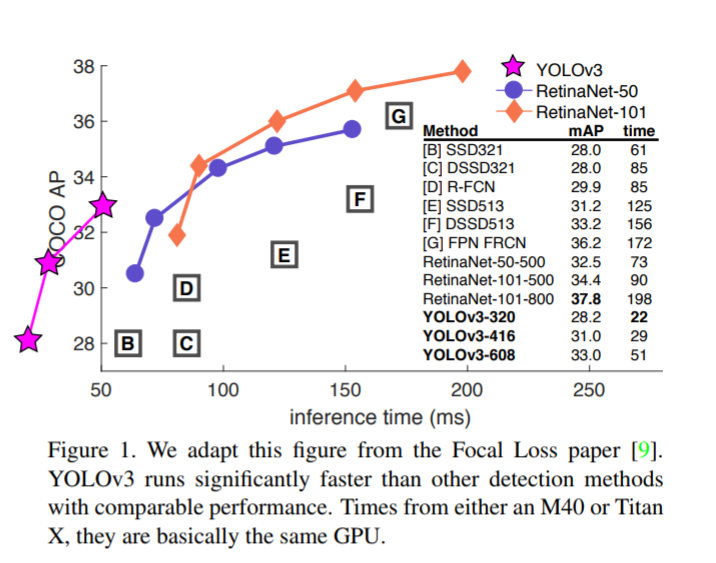
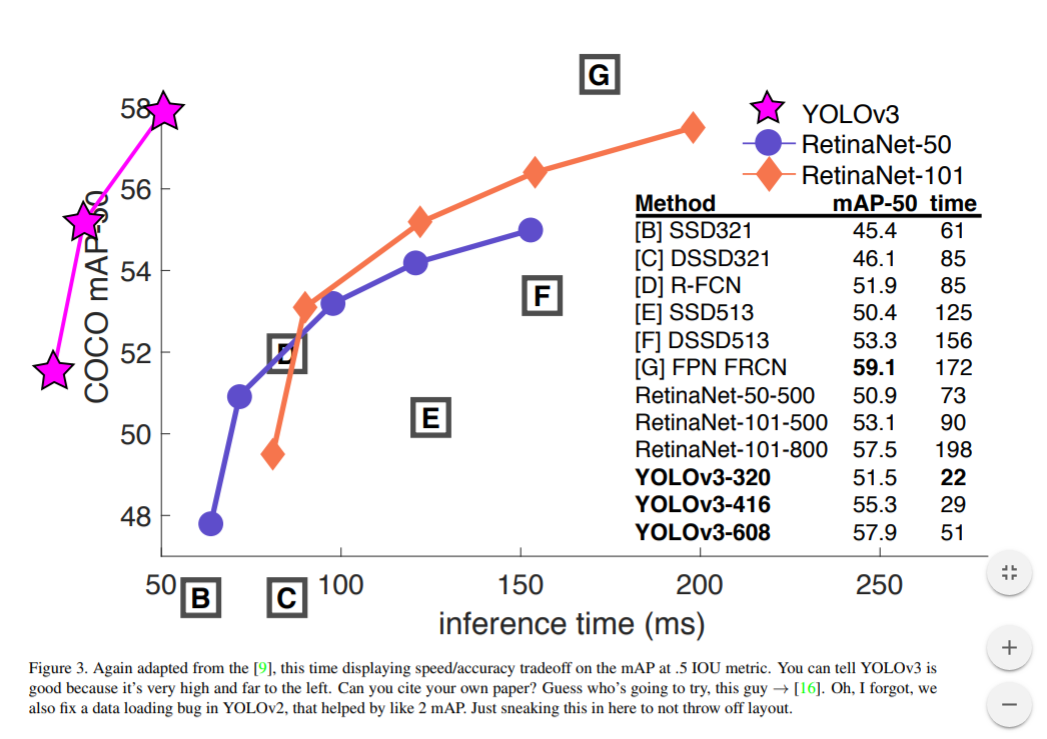
YOLOv3的表现非常好!请参见表3,就COCO奇怪的平均mAP成绩而言,它与SSD变体相当,但速度提高了3倍。尽管如此,它仍然比像RetinaNet这样的模型要差一点。
如果仔细看这个表,我们可以发现在IOU=.5(即表中的AP50)时,YOLOv3非常强大。它几乎与RetinaNet相当,并且远高于SSD变体。这就证明了它其实是一款非常灵活的检测器,擅长为检测对象生成合适的边界框。然而,随着IOU阈值增加,YOLOv3的性能开始同步下降,这时它预测的边界框就不能做到完美对齐了。
在过去,YOLO一直被用于小型对象检测。但现在我们可以预见其中的演变趋势,随着新的多尺寸预测功能上线,YOLOv3将具备更高的APS性能。但是它目前在中等尺寸或大尺寸物体上的表现还相对较差,仍需进一步的完善。
当我们基于AP50指标绘制精度和速度时(见图3),我们发现YOLOv3与其他检测系统相比具有显着优势。也就是说,它的速度正在越来越快。


4 失败的尝试
我们在研究YOLOv3时尝试了很多东西,以下是我们还记得的一些失败案例。
Anchor box坐标的偏移预测。我们尝试了常规的Anchor box预测方法,比如利用线性激活将坐标x、y的偏移程度预测为边界框宽度或高度的倍数。但我们发现这种做法降低了模型的稳定性,且效果不佳。
用线性方法预测x,y,而不是使用逻辑方法。我们尝试使用线性激活来直接预测x,y的offset,而不是逻辑激活。这降低了mAP成绩。
focal loss。我们尝试使用focal loss,但它使我们的mAP降低了2点。 对于focal loss函数试图解决的问题,YOLOv3从理论上来说已经很强大了,因为它具有单独的对象预测和条件类别预测。因此,对于大多数例子来说,类别预测没有损失?或者其他的东西?我们并不完全确定。

双IOU阈值和真值分配。在训练期间,Faster RCNN用了两个IOU阈值,如果预测的边框与.7的ground truth重合,那它是个正面的结果;如果在[.3—.7]之间,则忽略;如果和.3的ground truth重合,那它就是个负面的结果。我们尝试了这种思路,但效果并不好。
我们对现在的更新状况很满意,它看起来已经是最佳状态。有些技术可能会产生更好的结果,但我们还需要对它们做一些调整来稳定训练。


5 更新的意义
YOLOv3是一个很好的检测器,它速度快,精度又高。虽然基于.3和.95的新指标,它在COCO上的成绩不如人意,但对于旧的检测指标.5 IOU,它还是非常不错的。
所以为什么我们要改变指标呢?最初的COCO论文里只有这样一句含糊其词的话:一旦评估完成,就会生成评估指标结果。Russakovsky等人曾经有一份报告,说人类很难区分.3与.5的IOU:“训练人们用肉眼区别IOU值为0.3的边界框和0.5的边界框是一件非常困难的事”。[16]如果人类都难以区分这种差异,那这个指标有多重要?
但也许更好的一个问题是:现在我们有了这些检测器,我们能用它们来干嘛?很多从事这方面研究的人都受雇于Google和Facebook,我想至少我们知道如果这项技术发展得完善,那他们绝对不会把它用来收集你的个人信息然后卖给……等等,你把事实说出来了!!哦哦。
那么其他巨资资助计算机视觉研究的人还有军方,他们从来没有做过任何可怕的事情,比如用新技术杀死很多人……呸呸呸
我有很多希望!我希望大多数人会把计算机视觉技术用于快乐的、幸福的事情上,比如计算国家公园里斑马的数量[13],或者追踪小区附近到底有多少猫[19]。但是计算机视觉技术的应用已经步入歧途了,作为研究人员,我们有责任思考自己的工作可能带给社会的危害,并考虑怎么减轻这种危害。我们非常珍惜这个世界。
最后,不要在Twitter上@我,我已经弃坑了!!!!
参考文献:https://zhuanlan.zhihu.com/p/35023499

