
Python NumPy学习(1)——numpy概述
一、NumPy简介
NumPy是Python语言的一个扩充程序库。支持高级大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库。Numpy内部解除了CPython的GIL(全局解释器锁),运行效率极好,是大量机器学习框架的基础库!
关于GIL请参考博客:http://www.cnblogs.com/wj-1314/p/9056555.html
NumPy的全名为Numeric Python,是一个开源的Python科学计算库,它包括:
- 一个强大的N维数组对象ndrray;
- 比较成熟的(广播)函数库;
- 用于整合C/C++和Fortran代码的工具包;
- 实用的线性代数、傅里叶变换和随机数生成函数
NumPy的优点:
- 对于同样的数值计算任务,使用NumPy要比直接编写Python代码便捷得多;
- NumPy中的数组的存储效率和输入输出性能均远远优于Python中等价的基本数据结构,且其能够提升的性能是与数组中的元素成比例的;
- NumPy的大部分代码都是用C语言写的,其底层算法在设计时就有着优异的性能,这使得NumPy比纯Python代码高效得多
当然,NumPy也有其不足之处,由于NumPy使用内存映射文件以达到最优的数据读写性能,而内存的大小限制了其对TB级大文件的处理;此外,NumPy数组的通用性不及Python提供的list容器。因此,在科学计算之外的领域,NumPy的优势也就不那么明显。
关于Python Numpy学习(2)——矩阵的用法总结请参考博文:https://www.cnblogs.com/wj-1314/p/10244807.html
关于Python Numpy学习(3)——常用函数用法请参考博文:https://www.cnblogs.com/wj-1314/p/10708813.html
二,numpy保存二进制文件(.npy/.npz)
ndarray对象可以保存到磁盘文件并从磁盘文件加载,可用的IO功能有:
- load()和save() 函数处理Numpy 二进制文件(带npy扩展名)。
- loadtxt() 和savetxt() 函数处理正常的文本文件。
Numpy为ndarray对象引入了一个简单的文件格式,这个npy文件在磁盘文件中,存储重建ndarray所需的数据,图形,dtype和其他信息,以便正确获取数组,即使该文件在具有不同架构的一台机器上。
numpy.load和numpy.save函数式以Numpy专用的二进制类型保存数据,这两个函数会自动处理元素类型和shape等信息,使用它们读写数组就方便多了,但是numpy.save输出的文件很难和其他语言编写的程序读入。
1,numpy.save
保存一个数组到一个二进制的文件中,保存格式是.npy
参数介绍:
numpy.save(file, arr, allow_pickle=True, fix_imports=True) file:文件名/文件路径 arr:要存储的数组 allow_pickle:布尔值,允许使用Python pickles保存对象数组(可选参数,默认即可) fix_imports:为了方便Pyhton2中读取Python3保存的数据(可选参数,默认即可)
举例说明:
>>> import numpy as np
#生成数据
>>> x=np.arange(10)
>>> x
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
#数据保存
>>> np.save('save_x',x)
#读取保存的数据
>>> np.load('save_x.npy')
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
2,numpy.savez
这个同样是保存数组到一个二进制的文件中,但是厉害的是,它可以保存多个数组到同一个文件中,保存格式为.npz,它们其实就是多个前面np.save的保存的npy,再通过打包(未压缩)的方式把这些文件归到一个文件上,不行你再去解压npz文件就知道自己保存的是多个npy。
参数介绍:
numpy.savez(file, *args, **kwds) file:文件名/文件路径 *args:要存储的数组,可以写多个,如果没有给数组指定Key,Numpy将默认从'arr_0','arr_1'的方式命名 kwds:(可选参数,默认即可)
举例说明:
>>> import numpy as np
#生成数据
>>> x=np.arange(10)
>>> x
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
>>> y=np.sin(x)
>>> y
array([ 0. , 0.84147098, 0.90929743, 0.14112001, -0.7568025 ,
-0.95892427, -0.2794155 , 0.6569866 , 0.98935825, 0.41211849])
#数据保存
>>> np.save('save_xy',x,y)
#读取保存的数据
>>> npzfile=np.load('save_xy.npz')
>>> npzfile #是一个对象,无法读取
<numpy.lib.npyio.NpzFile object at 0x7f63ce4c8860>
#按照组数默认的key进行访问
>>> npzfile['arr_0']
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
>>> npzfile['arr_1']
array([ 0. , 0.84147098, 0.90929743, 0.14112001, -0.7568025 ,
-0.95892427, -0.2794155 , 0.6569866 , 0.98935825, 0.41211849])
更加神奇的是,我们可以不适用Numpy给数组的key,而是自己给数组有意义的key,这样就可以不用去猜测自己加载数据是否是自己需要的。
#数据保存
>>> np.savez('newsave_xy',x=x,y=y)
#读取保存的数据
>>> npzfile=np.load('newsave_xy.npz')
#按照保存时设定组数key进行访问
>>> npzfile['x']
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
>>> npzfile['y']
array([ 0. , 0.84147098, 0.90929743, 0.14112001, -0.7568025 ,
-0.95892427, -0.2794155 , 0.6569866 , 0.98935825, 0.41211849])
在深度学习中,我们保存了训练集,验证集,测试集,还包括它们的标签,用这个方式存储起来,要加载什么有什么,文件数量大大减少,也不会到处改文件名。
3,savetxt()
以简单文本文件格式存储和获取数组数据,通过savetxt()和loadtxt()函数来完成的。
import numpy as np
a = np.array([1,2,3,4,5])
np.savetxt('out.txt',a)
b = np.loadtxt('out.txt')
print(b)
# [1. 2. 3. 4. 5.]
savetxt()和loadtxt()函数接受附加的可选参数,例如页首,页尾和分隔符。
4,csv文件转化为npy格式
下面有一个csv文件的数据,我想将其转化为npy格式,数据内容如下:
cut,flute_1,flute_2,flute_3 1,31.41635516,19.48369225,21.74806264 2,34.8927704,23.473047,24.92595987 3,38.10284657,27.17286849,27.89865916 4,41.06102301,30.59930868,30.67784802 5,43.78119133,33.76786983,33.27472071 6,46.27671037,36.69342355,35.6999933 7,48.56042098,39.39022937,37.96391852 8,50.64466037,41.87195302,40.07630017 9,52.54127629,44.15168423,42.04650728
首先,数据是有索引,序列的,所以我们读取的时候要注意,转化代码如下:
import pandas as pd
import numpy as np
file1 = 'Train_A_wear.csv'
data1 = pd.read_csv(file1,header=0,index_col=0)
np.save('train_A_wear.npy',data1.values)
data_A_wear = np.load('trainA_wear.npy')
三、数组ndarray
Numpy中定义的最重要的对象是成为ndarray的N维数组类型。它描述相同类型的元素集合。可以使用基于零的索引访问集合中的项目。
大部分的数组操作仅仅是修改元数据部分,而不改变其底层的实际数据。数组的维数称为秩,简单来说就是如果你需要获取数组中一个特定元素所需的坐标数,如a是一个2×3×4的矩阵,你索引其中的一个元素必须给定三个坐标a[x,y,z],故它的维数就是3。
我们可以直接将数组看作一种新的数据类型,就像list、tuple、dict一样,但数组中所有元素的类型必须是一致的,Python支持的数据类型有整型、浮点型以及复数型,但这些类型不足以满足科学计算的需求,因此NumPy中添加了许多其他的数据类型,如bool、inti、int64、float32、complex64等。同时,它也有许多其特有的属性和方法。
3.1 常用ndarray属性:
- dtype 描述数组元素的类型
- shape 以tuple表示的数组形状
- ndim 数组的维度
- size 数组中元素的个数
- itemsize 数组中的元素在内存所占字节数
- T 数组的转置
- flat 返回一个数组的迭代器,对flat赋值将导致整个数组的元素被覆盖
- real/imag 给出复数数组的实部/虚部
- nbytes 数组占用的存储空间
import numpy as np # 创建简单的列表 a = [1,2,3,4,5,6] # 讲列表转换为数组 b = np.array(a) # Numpy查看数组属性 print(b.size) #6 # 数组形状 print(b.shape) # (6,) # 数组维度 print(b.ndim) # 1 # 数组元素类型 print(b.dtype) # int32
import numpy as np a = np.array([1,2,3]) print(a) # [1 2 3] # 多于一个维度 a = np.array([[1, 2], [3, 4]]) print(a) # [[1 2] # [3 4]] # 最小维度 a = np.array([1, 2, 3,4,5], ndmin = 2) print(a) # [[1 2 3 4 5]] # dtype 参数 a = np.array([1, 2, 3], dtype = complex) print(a) # [1.+0.j 2.+0.j 3.+0.j]
ndarray 对象由计算机内存中的一维连续区域组成,带有将每个元素映射到内存块中某个位置的索引方案。 内存块以按行(C 风格)或按列(FORTRAN 或 MatLab 风格)的方式保存元素。
3.2 常用ndarray方法:
- reshape(…) 返回一个给定shape的数组的副本
- resize(…) 返回给定shape的数组,原数组shape发生改变
- flatten()/ravel() 返回展平数组,原数组不改变
- astype(dtype) 返回指定元素类型的数组副本
- fill() 将数组元素全部设定为一个标量值
- sum/Prod() 计算所有数组元素的和/积
- mean()/var()/std() 返回数组元素的均值/方差/标准差
- max()/min()/ptp()/median() 返回数组元素的最大值/最小值/取值范围/中位数
- argmax()/argmin() 返回最大值/最小值的索引
- sort() 对数组进行排序,axis指定排序的轴;kind指定排序算法,默认是快速排序
- view()/copy() view创造一个新的数组对象指向同一数据;copy是深复制
- tolist() 将数组完全转为列表,注意与直接使用list(array)的区别
- compress() 返回满足条件的元素构成的数组
numpy.reshape:
import numpy as np
a = np.arange(8)
print('原始数组:')
print(a)
print('\n')
b = a.reshape(4,2)
print('修改后的数组:')
print(b)
'''结果
原始数组:
[0 1 2 3 4 5 6 7]
修改后的数组:
[[0 1]
[2 3]
[4 5]
[6 7]]
'''
numpy.ndarray.flatten:
import numpy as np
a = np.arange(8).reshape(2,4)
print('原数组:')
print(a)
print('\n')
# default is column-major
print('展开的数组:')
print(a.flatten())
print('\n')
print('以 F 风格顺序展开的数组:')
print(a.flatten(order = 'F'))
'''结果:
原数组:
[[0 1 2 3]
[4 5 6 7]]
展开的数组:
[0 1 2 3 4 5 6 7]
以 F 风格顺序展开的数组:
[0 4 1 5 2 6 3 7]
'''
numpy.ravel:
import numpy as np
a = np.arange(8).reshape(2,4)
print('原数组:')
print(a)
print('\n')
print('调用 ravel 函数之后:')
print(a.ravel())
print('\n')
print('以 F 风格顺序调用 ravel 函数之后:')
print(a.ravel(order = 'F'))
'''结果:
原数组:
[[0 1 2 3]
[4 5 6 7]]
调用 ravel 函数之后:
[0 1 2 3 4 5 6 7]
以 F 风格顺序调用 ravel 函数之后:
[0 4 1 5 2 6 3 7]'''
3.3 数组的创建
numpy中使用array()函数创建数组,array的首个参数一定是一个序列,可以是元组也可以是列表。
3.3.1 一维数组的创建
可以使用numpy中的arange()函数创建一维有序数组,它是内置函数range的扩展版。
In [1]: import numpy as np In [2]: ls1 = range(10) In [3]: list(ls1) Out[3]: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] In [4]: type(ls1) Out[4]: range In [5]: ls2 = np.arange(10) In [6]: list(ls2) Out[6]: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] In [7]: type(ls2) Out[7]: numpy.ndarray
通过arange生成的序列就不是简简单单的列表类型了,而是一个一维数组。
如果一维数组不是一个规律的有序元素,而是人为的输入,就需要array()函数创建了。
In [8]: arr1 = np.array((1,20,13,28,22)) In [9]: arr1 Out[9]: array([ 1, 20, 13, 28, 22]) In [10]: type(arr1) Out[10]: numpy.ndarray
上面是由元组序列构成的一维数组。
In [11]: arr2 = np.array([1,1,2,3,5,8,13,21]) In [12]: arr2 Out[12]: array([ 1, 1, 2, 3, 5, 8, 13, 21]) In [13]: type(arr2) Out[13]: numpy.ndarray
上面是由列表序列构成的一维数组。
3.3.2 二维数组的创建
二维数组的创建,其实在就是列表套列表或元组套元组。
In [14]: arr3 = np.array(((1,1,2,3),(5,8,13,21),(34,55,89,144))) In [15]: arr3 Out[15]: array([[ 1, 1, 2, 3], [ 5, 8, 13, 21], [ 34, 55, 89, 144]])
上面使用元组套元组的方式。
In [16]: arr4 = np.array([[1,2,3,4],[5,6,7,8],[9,10,11,12]]) In [17]: arr4 Out[17]: array([[ 1, 2, 3, 4], [ 5, 6, 7, 8], [ 9, 10, 11, 12]])
上面使用列表套列表的方式。
对于高维数组在将来的数据分析中用的比较少,这里关于高维数组的创建就不赘述了,构建方法仍然是套的方式。
上面所介绍的都是人为设定的一维、二维或高维数组,numpy中也提供了几种特殊的数组,它们是:
In [18]: np.ones(3) #返回一维元素全为1的数组 Out[18]: array([ 1., 1., 1.]) In [19]: np.ones([3,4]) #返回元素全为1的3×4二维数组 Out[19]: array([[ 1., 1., 1., 1.], [ 1., 1., 1., 1.], [ 1., 1., 1., 1.]]) In [20]: np.zeros(3) #返回一维元素全为0的数组 Out[20]: array([ 0., 0., 0.]) In [21]: np.zeros([3,4]) #返回元素全为0的3×4二维数组 Out[21]: array([[ 0., 0., 0., 0.], [ 0., 0., 0., 0.], [ 0., 0., 0., 0.]]) In [22]: np.empty(3) #返回一维空数组 Out[22]: array([ 0., 0., 0.]) In [23]: np.empty([3,4]) #返回3×4二维空数组 Out[23]: array([[ 0., 0., 0., 0.], [ 0., 0., 0., 0.], [ 0., 0., 0., 0.]])
3.3.3 ones函数
返回特定大小,以1填充的新数组
>>> import numpy as np
>>> a=np.ones(3);a
array([ 1., 1., 1.])
>>> b=np.ones((3,2));b
array([[ 1., 1.],
[ 1., 1.],
[ 1., 1.]])
3.3.4 zeros函数
返回特定大小,以0填充的新数组。
官方库的解释:
def zeros(shape, dtype=None, order='C'): # real signature unknown; restored from __doc__
"""
zeros(shape, dtype=float, order='C')
Return a new array of given shape and type, filled with zeros.
Parameters
----------
shape : int or tuple of ints
Shape of the new array, e.g., ``(2, 3)`` or ``2``.
dtype : data-type, optional
The desired data-type for the array, e.g., `numpy.int8`. Default is
`numpy.float64`.
order : {'C', 'F'}, optional, default: 'C'
Whether to store multi-dimensional data in row-major
(C-style) or column-major (Fortran-style) order in
memory.
Returns
-------
out : ndarray
Array of zeros with the given shape, dtype, and order.
See Also
--------
zeros_like : Return an array of zeros with shape and type of input.
empty : Return a new uninitialized array.
ones : Return a new array setting values to one.
full : Return a new array of given shape filled with value.
Examples
--------
>>> np.zeros(5)
array([ 0., 0., 0., 0., 0.])
>>> np.zeros((5,), dtype=int)
array([0, 0, 0, 0, 0])
>>> np.zeros((2, 1))
array([[ 0.],
[ 0.]])
>>> s = (2,2)
>>> np.zeros(s)
array([[ 0., 0.],
[ 0., 0.]])
>>> np.zeros((2,), dtype=[('x', 'i4'), ('y', 'i4')]) # custom dtype
array([(0, 0), (0, 0)],
dtype=[('x', '<i4'), ('y', '<i4')])
"""
pass
numpy.zeros(shape, dtype=float, order=’C’)
参数:
shape:int或ints序列
新数组的形状,例如(2,3 )或2。
dtype:数据类型,可选
数组的所需数据类型,例如numpy.int8。默认值为 numpy.float64。
order:{'C','F'},可选
是否在存储器中以C或Fortran连续(按行或列方式)存储多维数据。
返回:
out:ndarray
具有给定形状,数据类型和顺序的零数组。
>>> c=np.zeros(3)
>>> c
array([ 0., 0., 0.])
>>> d=np.zeros((2,3));d
array([[ 0., 0., 0.],
[ 0., 0., 0.]])
#d=np.zeros(2,3)会报错,d=np.zeros(3,dtype=int)来改变默认的数据类型
3.3.5 eye&identity函数
eye()函数用于生成指定行数的单位矩阵
>>> e=np.eye(3);e
array([[ 1., 0., 0.],
[ 0., 1., 0.],
[ 0., 0., 1.]])
>>> e=np.eye(3,2);e
array([[ 1., 0.],
[ 0., 1.],
[ 0., 0.]])
>>> e=np.eye(3,1);e
array([[ 1.],
[ 0.],
[ 0.]])
>>> e=np.eye(3,3);e
array([[ 1., 0., 0.],
[ 0., 1., 0.],
[ 0., 0., 1.]])
>>> e=np.eye(3,3,1);e
array([[ 0., 1., 0.],
[ 0., 0., 1.],
[ 0., 0., 0.]])
e=np.eye(3,3,2);e
array([[ 0., 0., 1.],
[ 0., 0., 0.],
[ 0., 0., 0.]])
>>> e=np.eye(3,3,3);e
array([[ 0., 0., 0.],
[ 0., 0., 0.],
[ 0., 0., 0.]])
>>> e=np.eye(3,3,4);e
array([[ 0., 0., 0.],
[ 0., 0., 0.],
[ 0., 0., 0.]])
>>> p=np.identity(4);p
array([[ 1., 0., 0., 0.],
[ 0., 1., 0., 0.],
[ 0., 0., 1., 0.],
[ 0., 0., 0., 1.]])
>>> p=np.identity(4,3);p #会报错
>>> p=np.identity((4,3));p #会报错
3.3.6 empty函数
它创建指定形状和dtype的未初始化数组。它使用以下构造函数:
numpy.empty(shape, dtype = float, order = 'C')
注意:数组为随机值,因为他们未初始化。
import numpy as np x = np.empty([3,2], dtype = int) print(x) # [[1762 0] # [ 0 0] # [ 0 0]]
>>> a=np.empty(3);a
array([ 1.60091154e-163, 1.12069303e-258, 3.23790862e-318])
>>> a=np.empty((3,3));a
array([[ 1.57741456e-284, 1.57680914e-284, 1.56735002e-163],
[ 1.56205068e-163, 1.62511438e-163, 1.21880041e+171],
[ 1.57757869e-052, 7.34292780e+223, 4.71235856e+257]])
3.3.7 ones_like zero_like empy_like函数
>>> a=np.array([[[1,2],[1,2]],[[1,2],[1,2]],[[1,2],[1,2]]])
>>> a.shape
(3, 2, 2)
>>> b=np.ones_like(a)
>>> b
array([[[1, 1],
[1, 1]],
[[1, 1],
[1, 1]],
[[1, 1],
[1, 1]]])
>>> b=np.zeros_like(a);b
array([[[0, 0],
[0, 0]],
[[0, 0],
[0, 0]],
[[0, 0],
[0, 0]]])
>>> a=np.array([[[1,2],[1,2]],[[1,2],[1,2]],[[1,2],[1,2]]])
>>> b=np.empty_like(a);b
array([[[39125057, 40012256],
[81313824, 81313856]],
[[ 0, 0],
[ 0, 0]],
[[ 0, 0],
[ 0, 0]]])
#注意,shape和dtype均复制
3.3.8 .T函数
.T 作用于矩阵,用于求矩阵的转置
>>myMat=np.mat([[1,2,3],[4,5,6]])
>>print(myMat)
>>matrix([[1.,2.,3.]
[4.,5.,6.]])
>>print(myMat.T)
>>matrix([[1,4],
[2,5],
[3,6]])
3.3.9 tolist()函数
tolost()函数用于把一个矩阵转化为list列表
>>x=np.mat([[1,2,3],[4,5,6]]) >>print(x) >>matrix([[1,2,3],[4,,5,6]]) >>type(x) >>matrix >>x.tolist() >>[[1,2,3],[4,5,6]]
3.3.10 .I
.I用于求矩阵的逆矩阵,逆矩阵在计算中是经常要用到的,例如一个矩阵A,求A的逆矩阵B,即存在矩阵B是AB=I(I是单位)
In [3]: a=mat([[1,2,3],[4,5,6]])
In [4]: a
Out[4]:
matrix([[1, 2, 3],
[4, 5, 6]])
In [5]: a.I
Out[5]:
matrix([[-0.94444444, 0.44444444],
[-0.11111111, 0.11111111],
[ 0.72222222, -0.22222222]])
In [6]: s=a.I
In [8]: a*s
Out[8]:
matrix([[ 1.00000000e+00, 3.33066907e-16],
[ 0.00000000e+00, 1.00000000e+00]])
3.3.11 .power(x1,x2)
数组的元素分别求n次方,x2可以是数字,也可以是数组,但是x1和x2的列数要相同。
>>> x1 = range(6) >>> x1 [0, 1, 2, 3, 4, 5] >>> np.power(x1, 3) array([ 0, 1, 8, 27, 64, 125])
>>> x2 = [1.0, 2.0, 3.0, 3.0, 2.0, 1.0] >>> np.power(x1, x2) array([ 0., 1., 8., 27., 16., 5.])
>>> x2 = np.array([[1, 2, 3, 3, 2, 1], [1, 2, 3, 3, 2, 1]])
>>> x2
array([[1, 2, 3, 3, 2, 1],
[1, 2, 3, 3, 2, 1]])
>>> np.power(x1, x2)
array([[ 0, 1, 8, 27, 16, 5],
[ 0, 1, 8, 27, 16, 5]])
3.3.12 reshape() 函数
一般用法:numpy.arrange(n).reshape(a,b)
意思:依次生成n个自然数,并且以a行b列的数组形式显示。
In [1]:
np.arange(16).reshape(2,8) #生成16个自然数,以2行8列的形式显示
Out[1]:
array([[ 0, 1, 2, 3, 4, 5, 6, 7],
[ 8, 9, 10, 11, 12, 13, 14, 15]])
特殊用法:mat(or array).reshape(c,-1)
必须是矩阵格式或者数组格式,才能使用.reshape(c,-1)函数,表示将此矩阵或者数组重组,以c行d 列的形式表示(-1的作用就在此,自动计算d:d=数组或者矩阵里面所有的元素个数(c,d必须为整数,不然会报错))
In [2]: arr=np.arange(16).reshape(2,8)
out[2]:
In [3]: arr
out[3]:
array([[ 0, 1, 2, 3, 4, 5, 6, 7],
[ 8, 9, 10, 11, 12, 13, 14, 15]])
In [4]: arr.reshape(4,-1) #将arr变成4行的格式,列数自动计算的(c=4, d=16/4=4)
out[4]:
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15]])
In [5]: arr.reshape(8,-1) #将arr变成8行的格式,列数自动计算的(c=8, d=16/8=2)
out[5]:
array([[ 0, 1],
[ 2, 3],
[ 4, 5],
[ 6, 7],
[ 8, 9],
[10, 11],
[12, 13],
[14, 15]])
In [6]: arr.reshape(10,-1) #将arr变成10行的格式,列数自动计算的(c=10, d=16/10=1.6 != Int)
out[6]:
ValueError: cannot reshape array of size 16 into shape (10,newaxis)
3.3.13 np.unique()的用法
该函数是去除数组中的重复数字,并进行排序之后输出
a = [2,3,4,1,21,32,32,32,2,1]
b = [1,2,3,1,2,3]
c = [[1,2,3],[1,2,3],[2,3,4]]
resa = np.unique(a)
resb = np.unique(b)
resc = np.unique(c)
print('unique result a is :',resa)
print('unique result a is :',resb)
print('unique result a is :',resc)
'''
unique result a is : [ 1 2 3 4 21 32]
unique result a is : [1 2 3]
unique result a is : [1 2 3 4]
'''
3.3.14 np.argsort()的用法
argsort()函数返回的是数组值从小到达的索引值
One dimensional array:一维数组 >>> x = np.array([3, 1, 2]) >>> np.argsort(x) array([1, 2, 0]) Two-dimensional array:二维数组 >>> x = np.array([[0, 3], [2, 2]]) >>> x array([[0, 3], [2, 2]]) >>> np.argsort(x, axis=0) #按列排序 array([[0, 1], [1, 0]]) >>> np.argsort(x, axis=1) #按行排序 array([[0, 1], [0, 1]])
举个例子:
>>> x = np.array([3, 1, 2]) >>> np.argsort(x) #按升序排列 array([1, 2, 0]) >>> np.argsort(-x) #按降序排列 array([0, 2, 1]) >>> x[np.argsort(x)] #通过索引值排序后的数组 array([1, 2, 3]) >>> x[np.argsort(-x)] array([3, 2, 1]) 另一种方式实现按降序排序: >>> a = x[np.argsort(x)] >>> a array([1, 2, 3]) >>> a[::-1] array([3, 2, 1])
3.3.15 np.flatnonzero()
该函数输入一个矩阵,返回扁平化后矩阵中非零元素的位置(index)
下面给出一个用法,输入一个矩阵,返回了其中非零元素的位置:
>>> x = np.arange(-2, 3) >>> x array([-2, -1, 0, 1, 2]) >>> np.flatnonzero(x) array([0, 1, 3, 4]) import numpy as np d = np.array([1,2,3,4,4,3,5,3,6]) haa = np.flatnonzero(d == 3) print (haa) [2 5 7]
对向量元素的判断 d == 3,返回了一个和向量等长的由0/1组成的矩阵,然后再调用函数,返回的位置,就是对应要找的元素的位置。
# Visualize some examples from the dataset.
# We show a few examples of training images from each class.
classes = ['plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck'] #类别列表
num_classes = len(classes) #类别数目
samples_per_class = 7 # 每个类别采样个数
for y, cls in enumerate(classes): # 对列表的元素位置和元素进行循环,y表示元素位置(0,num_class),cls元素本身'plane'等
idxs = np.flatnonzero(y_train == y) #找出标签中y类的位置
idxs = np.random.choice(idxs, samples_per_class, replace=False) #从中选出我们所需的7个样本
for i, idx in enumerate(idxs): #对所选的样本的位置和样本所对应的图片在训练集中的位置进行循环
plt_idx = i * num_classes + y + 1 # 在子图中所占位置的计算
plt.subplot(samples_per_class, num_classes, plt_idx) # 说明要画的子图的编号
plt.imshow(X_train[idx].astype('uint8')) # 画图
plt.axis('off')
if i == 0:
plt.title(cls) # 写上标题,也就是类别名
plt.show() # 显示
3.3.16 np.nonzero()
nonzero函数是numpy中用于得到数组array中非零元素的目录(位置)的函数。
返回值为元组,两个值分别为两个维度,包含了相应维度上非零元素的目录值。
只有a中非零元素才会有索引值,那些零值元素没有索引值
当使用布尔数组直接作为下标对象或者元祖下标对象中有布尔数组时,都相当于用nonzero()讲布尔数组转换成一组整数数组,然后使用整数数组进行下标运算。
nonzeros(a)返回数组a中值不为零的元素的下标,它的返回值是一个长度为a.ndim(数组a的轴数)的元组,元组的每个元素都是一个整数数组,其值为非零元素的下标在对应轴上的值。例如对于一维布尔数组b1,nonzero(b1)所得到的是一个长度为1的元组,它表示b1[0]和b1[2]的值不为0(False)。
b = np.array([True,False,True,False]) b array([ True, False, True, False]) np.nonzero(b) (array([0, 2], dtype=int64),)
对于一个二维数组c,nonzeero(c)所得到的是一个长度为2的元祖,它的第0个元素是数组a中值不为0的元素的第0轴的下标,第一个元素则为第1轴的下标,因此从下面的结果可知b2[0,0]、b[0,2]和b2[1,0]的值不为0:
c = np.array([[True, False, True], [True, False, False]])
c
array([[ True, False, True],
[ True, False, False]])
np.nonzero(c)
(array([0, 0, 1], dtype=int64), array([0, 2, 0], dtype=int64))
3.3.17 np.column_stack(tup)
np.column_stack(tup)相当于np.concatenate((a1, a2, …), axis=1),对竖轴的数组进行横向的操作。
官方解释(如果传递的是一个一维数组,则会先将一维数组转化为2维数组):
Stack 1-D arrays as columns into a 2-D array.
Take a sequence of 1-D arrays and stack them as columns
to make a single 2-D array. 2-D arrays are stacked as-is,
just like with `hstack`. 1-D arrays are turned into 2-D columns
first.
Parameters
----------
tup : sequence of 1-D or 2-D arrays.
Arrays to stack. All of them must have the same first dimension.
Returns
-------
stacked : 2-D array
The array formed by stacking the given arrays.
See Also
--------
stack, hstack, vstack, concatenate
举例说明:
如果开始传入的是一维数组,首先将一维数组转化为二维数组
import numpy as np a = np.array((1, 2, 3)) b = np.array((2, 3, 4)) c = np.column_stack((a, b)) print(a) print(b) print(c) # 结果: [1 2 3] [2 3 4] [[1 2] [2 3] [3 4]]
如果一开始传入的是多维数组,则直接进行拼接操作
import numpy as np a = np.array(((1, 2, 3), (4, 3, 2))) b = np.array(((2,3,4),(2,12,2))) c = np.column_stack((a,b)) print(a) print(b) print(c) # 结果: [[1 2 3] [4 3 2]] [[ 2 3 4] [ 2 12 2]] [[ 1 2 3 2 3 4] [ 4 3 2 2 12 2]]
四,Numpy数据类型
NumPy 支持比 Python 更多种类的数值类型。 下表显示了 NumPy 中定义的不同标量数据类型。
| 序号 | 数据类型及描述 |
|---|---|
| 1. | bool_存储为一个字节的布尔值(真或假) |
| 2. | int_默认整数,相当于 C 的long,通常为int32或int64 |
| 3. | intc相当于 C 的int,通常为int32或int64 |
| 4. | intp用于索引的整数,相当于 C 的size_t,通常为int32或int64 |
| 5. | int8字节(-128 ~ 127) |
| 6. | int1616 位整数(-32768 ~ 32767) |
| 7. | int3232 位整数(-2147483648 ~ 2147483647) |
| 8. | int6464 位整数(-9223372036854775808 ~ 9223372036854775807) |
| 9. | uint88 位无符号整数(0 ~ 255) |
| 10. | uint1616 位无符号整数(0 ~ 65535) |
| 11. | uint3232 位无符号整数(0 ~ 4294967295) |
| 12. | uint6464 位无符号整数(0 ~ 18446744073709551615) |
| 13. | float_float64的简写 |
| 14. | float16半精度浮点:符号位,5 位指数,10 位尾数 |
| 15. | float32单精度浮点:符号位,8 位指数,23 位尾数 |
| 16. | float64双精度浮点:符号位,11 位指数,52 位尾数 |
| 17. | complex_complex128的简写 |
| 18. | complex64复数,由两个 32 位浮点表示(实部和虚部) |
| 19. | complex128复数,由两个 64 位浮点表示(实部和虚部) |
NumPy 数字类型是dtype(数据类型)对象的实例,每个对象具有唯一的特征。 这些类型可以是np.bool_,np.float32等。
4.1 数据类型对象(dtype)
数据类型对象描述了对应于数组的固定内存块的解释,取决于以下方面:
-
数据类型(整数、浮点或者 Python 对象)
-
数据大小
-
字节序(小端或大端)
-
在结构化类型的情况下,字段的名称,每个字段的数据类型,和每个字段占用的内存块部分。
-
如果数据类型是子序列,它的形状和数据类型。
字节顺序取决于数据类型的前缀<或>。<意味着编码是小端(最小有效字节存储在最小地址中)。>意味着编码是大端(最大有效字节存储在最小地址中)。
dtype语法构造:
numpy.dtype(object, align, copy)
参数为:
Object:被转换为数据类型的对象。 Align:如果为true,则向字段添加间隔,使其类似 C 的结构体。 Copy: 生成dtype对象的新副本,如果为flase,结果是内建数据类型对象的引用。
示例:
# 使用数组标量类型
import numpy as np
dt = np.dtype(np.int32)
print(dt)
# int32
# int8,int16,int32,int64 可替换为等价的字符串 'i1','i2','i4',以及其他。
dt = np.dtype('i4')
print(dt)
# int32
# 使用端记号
dt = np.dtype('>i4')
print(dt)
# >i4
# 首先创建结构化数据类型。
dt = np.dtype([('age',np.int8)])
print(dt)
# [('age', 'i1')]
# 现在将其应用于 ndarray 对象
dt = np.dtype([('age',np.int8)])
a = np.array([(10,),(20,),(30,)], dtype = dt)
print(a)
# [(10,) (20,) (30,)]
# 文件名称可用于访问 age 列的内容
dt = np.dtype([('age',np.int8)])
a = np.array([(10,),(20,),(30,)], dtype = dt)
print(a['age'])
# [10 20 30]
五,Numpy 切片和索引
ndarray对象的内容可以通过索引或切片来访问和修改,就像python的内置容器对象一样。
nadarray 对象中的元素遵循基于零的索引,有三种可用的索引方法类型:字段访问,基础切片和高级索引。
基本切片是Python中基本切片概念到n维的扩展,通过start,stop和step参数提供给内置函数的slice函数来构造一个Python slice对象,此slice对象被传递给数组来提取数组的一部分。
练习:
import numpy as np
a = np.arange(10)
print(a)
# [0 1 2 3 4 5 6 7 8 9]
s = slice(2,7,2)
print(s)
# slice(2, 7, 2)
print(a[s])
# [2 4 6]
b = a[2:7:2]
print(b)
# [2 4 6]
# 对单个元素进行切片
b = a[5]
print(b)
# 5
# 对始于索引的元素进行切片
print(a[2:])
# [2 3 4 5 6 7 8 9]
# 对索引之间的元素进行切片
print(a[2:5])
# [2 3 4]
# 二维数组
# 最开始的数组
import numpy as np
a = np.array([[1,2,3],[3,4,5],[4,5,6]])
print('我们的数组是:')
print(a)
print ('\n')
# 这会返回第二列元素的数组:
print ('第二列的元素是:')
print(a[...,1])
print('\n')
# 现在我们从第二行切片所有元素:
print ('第二行的元素是:')
print(a[1,...])
print( '\n')
# 现在我们从第二列向后切片所有元素:
print ('第二列及其剩余元素是:')
print(a[...,1:])
'''
我们的数组是:
[[1 2 3]
[3 4 5]
[4 5 6]]
第二列的元素是:
[2 4 5]
第二行的元素是:
[3 4 5]
第二列及其剩余元素是:
[[2 3]
[4 5]
[5 6]]'''
六,numpy中的ndarray与array的区别
答:Well, np.array is just a convenience function to create an ndarray, it is not a class itself.
(嗯,np.array只是一个便捷的函数,用来创建一个ndarray,它本身不是一个类)
You can also create an array using np.ndarray, but it is not the recommended way. From the docstring of np.ndarray:
(你也能够用np.ndarray来创建,但这不是推荐的方式。来自np.ndarray的文档:)
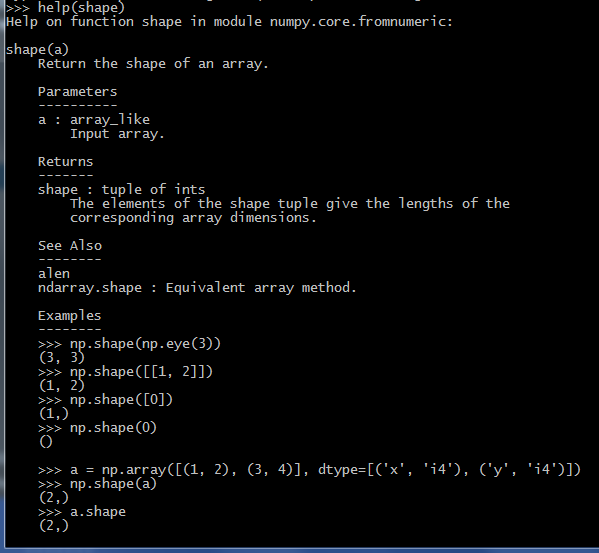
numpy函数:shape用法

 浙公网安备 33010602011771号
浙公网安备 33010602011771号