
深入学习Keras中Sequential模型及方法
Sequential 序贯模型
序贯模型是函数式模型的简略版,为最简单的线性、从头到尾的结构顺序,不分叉,是多个网络层的线性堆叠。
Keras实现了很多层,包括core核心层,Convolution卷积层、Pooling池化层等非常丰富有趣的网络结构。
我们可以通过将层的列表传递给Sequential的构造函数,来创建一个Sequential模型。
1 2 3 4 5 6 7 8 9 | from keras.models import Sequentialfrom keras.layers import Dense, Activationmodel = Sequential([ Dense(32, input_shape=(784,)), Activation('relu'), Dense(10), Activation('softmax'),]) |
也可以使用.add()方法将各层添加到模型中:
1 2 3 | model = Sequential()model.add(Dense(32, input_dim=784))model.add(Activation('relu')) |
指定输入数据的尺寸
模型需要知道它所期待的输入的尺寸(shape)。出于这个原因,序贯模型中的第一层(只有第一层,因为下面的层可以自动的推断尺寸)需要接收关于其输入尺寸的信息,后面的各个层则可以自动的推导出中间数据的shape,因此不需要为每个层都指定这个参数。有以下几种方法来做到这一点:
- 传递一个input_shape参数给第一层。它是一个表示尺寸的元组(一个整数或None的元组,其中None表示可能为任何正整数)。在input_shape中不包含数据的batch大小。
- 某些 2D 层,例如
Dense,支持通过参数input_dim指定输入尺寸,某些 3D 时序层支持input_dim和input_length参数。 - 如果你需要为你的输入指定一个固定的 batch 大小(这对 stateful RNNs 很有用),你可以传递一个
batch_size参数给一个层。如果你同时将batch_size=32和input_shape=(6, 8)传递给一个层,那么每一批输入的尺寸就为(32,6,8)。
因此下面的代码是等价的。
1 2 3 4 5 | model = Sequential()model.add(Dense(32, input_shape=(784,)))model = Sequential()model.add(Dense(32, input_dim=784)) |
下面三种方法也是严格等价的
1 2 3 4 5 6 7 8 9 10 | model = Sequential()model.add(LSTM(32, input_shape=(10, 64)))model = Sequential()model.add(LSTM(32, batch_input_shape=(None, 10, 64)))model = Sequential()model.add(LSTM(32, input_length=10, input_dim=64)) |
编译
在训练模型之前,我们需要配置学习过程,这是通过compile方法完成的,他接收三个参数:
- 优化器 optimizer:它可以是现有优化器的字符串标识符,如
rmsprop或adagrad,也可以是 Optimizer 类的实例。详见:optimizers。 - 损失函数 loss:模型试图最小化的目标函数。它可以是现有损失函数的字符串标识符,如
categorical_crossentropy或mse,也可以是一个目标函数。详见:losses。 - 评估标准 metrics:对于任何分类问题,你都希望将其设置为
metrics = ['accuracy']。评估标准可以是现有的标准的字符串标识符,也可以是自定义的评估标准函数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | # 多分类问题model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy'])# 二分类问题model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['accuracy'])# 均方误差回归问题model.compile(optimizer='rmsprop', loss='mse')# 自定义评估标准函数import keras.backend as Kdef mean_pred(y_true, y_pred): return K.mean(y_pred)model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['accuracy', mean_pred]) |
训练
Keras 模型在输入数据和标签的 Numpy 矩阵上进行训练。为了训练一个模型,你通常会使用 fit 函数。文档详见此处。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | # 对于具有2个类的单输入模型(二进制分类):model = Sequential()model.add(Dense(32, activation='relu', input_dim=100))model.add(Dense(1, activation='sigmoid'))model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['accuracy'])# 生成虚拟数据import numpy as npdata = np.random.random((1000, 100))labels = np.random.randint(2, size=(1000, 1))# 训练模型,以 32 个样本为一个 batch 进行迭代model.fit(data, labels, epochs=10, batch_size=32) |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | # 对于具有10个类的单输入模型(多分类分类):model = Sequential()model.add(Dense(32, activation='relu', input_dim=100))model.add(Dense(10, activation='softmax'))model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy'])# 生成虚拟数据import numpy as npdata = np.random.random((1000, 100))labels = np.random.randint(10, size=(1000, 1))# 将标签转换为分类的 one-hot 编码one_hot_labels = keras.utils.to_categorical(labels, num_classes=10)# 训练模型,以 32 个样本为一个 batch 进行迭代model.fit(data, one_hot_labels, epochs=10, batch_size=32) |
例子
这里有几个可以帮助你开始的例子!
在 examples 目录 中,你可以找到真实数据集的示例模型:
- CIFAR10 小图片分类:具有实时数据增强的卷积神经网络 (CNN)
- IMDB 电影评论情感分类:基于词序列的 LSTM
- Reuters 新闻主题分类:多层感知器 (MLP)
- MNIST 手写数字分类:MLP 和 CNN
- 基于 LSTM 的字符级文本生成
基于多层感知器 (MLP) 的 softmax 多分类:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | import kerasfrom keras.models import Sequentialfrom keras.layers import Dense, Dropout, Activationfrom keras.optimizers import SGD# 生成虚拟数据import numpy as npx_train = np.random.random((1000, 20))y_train = keras.utils.to_categorical(np.random.randint(10, size=(1000, 1)), num_classes=10)x_test = np.random.random((100, 20))y_test = keras.utils.to_categorical(np.random.randint(10, size=(100, 1)), num_classes=10)model = Sequential()# Dense(64) 是一个具有 64 个隐藏神经元的全连接层。# 在第一层必须指定所期望的输入数据尺寸:# 在这里,是一个 20 维的向量。model.add(Dense(64, activation='relu', input_dim=20))model.add(Dropout(0.5))model.add(Dense(64, activation='relu'))model.add(Dropout(0.5))model.add(Dense(10, activation='softmax'))sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)model.compile(loss='categorical_crossentropy', optimizer=sgd, metrics=['accuracy'])model.fit(x_train, y_train, epochs=20, batch_size=128)score = model.evaluate(x_test, y_test, batch_size=128) |
基于多层感知器的二分类:
思路:
输入数据:定义输入一个二维数组(x1,x2),数据通过numpy来随机产生,将输出定义为0或者1,如果x1+x2<1,则y为1,否则y为0.
隐藏层:定义两层隐藏层,隐藏层的参数为(2,3),两行三列的矩阵,输入数据通过隐藏层之后,输出的数据为(1,3),t通过矩阵之间的乘法运算可以获得输出数据。
损失函数:使用交叉熵作为神经网络的损失函数,常用的损失函数还有平方差。
优化函数:通过油画函数来使得损失函数最小化,这里采用的是Adadelta算法进行优化,常用的有梯度下降算法。
输出数据:将隐藏层的输出数据通过(3,1)的参数,输出一个一维向量,值的大小为0或者1.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 | import numpy as npfrom keras.models import Sequentialfrom keras.layers import Dense,Dropout# 生成数据,训练数据和测试数据# x_train/x_test 生成随机的浮点数,x_train为1000行20列 x_test为100行20列# 列数一定要一一对应,相当于特征个数要对应# 此处的二元分类,可以不需要one_hot编译,np.random.randint可以直接生成0 1 编码x_train = np.random.random((1000,20))y_train = np.random.randint(2,size=(1000,1))# print(x_train)# print(y_train)x_test = np.random.random((100,20))y_test = np.random.randint(2,size=(100,1))# 设计模型,通过add的方式叠起来# 注意输入时,初始网络一定要给定输入的特征维度input_dim 或者input_shape数据类型# activition激活函数既可以在Dense网络设置里,也可以单独添加model = Sequential()model.add(Dense(64,input_dim=20,activation='relu'))# Drop防止过拟合的数据处理方式model.add(Dropout(0.5))model.add(Dense(64,activation='relu'))model.add(Dropout(0.5))model.add(Dense(1,activation='sigmoid'))# 编译模型,定义损失函数,优化函数,绩效评估函数model.compile(loss='binary_crossentropy', optimizer='rmsprop', metrics=['accuracy'])# 导入数据进行训练model.fit(x_train,y_train,epochs=20,batch_size=128)# 模型评估score = model.evaluate(x_test,y_test,batch_size=128)print(score) |
类似VGG的卷积神经网络
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 | import numpy as npimport kerasfrom keras.models import Sequentialfrom keras.layers import Dense, Dropout, Flattenfrom keras.layers import Conv2D, MaxPooling2Dfrom keras.optimizers import SGD# 生成虚拟数据x_train = np.random.random((100, 100, 100, 3))y_train = keras.utils.to_categorical(np.random.randint(10, size=(100, 1)), num_classes=10)x_test = np.random.random((20, 100, 100, 3))y_test = keras.utils.to_categorical(np.random.randint(10, size=(20, 1)), num_classes=10)model = Sequential()# 输入: 3 通道 100x100 像素图像 -> (100, 100, 3) 张量。# 使用 32 个大小为 3x3 的卷积滤波器。model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(100, 100, 3)))model.add(Conv2D(32, (3, 3), activation='relu'))model.add(MaxPooling2D(pool_size=(2, 2)))model.add(Dropout(0.25))model.add(Conv2D(64, (3, 3), activation='relu'))model.add(Conv2D(64, (3, 3), activation='relu'))model.add(MaxPooling2D(pool_size=(2, 2)))model.add(Dropout(0.25))model.add(Flatten())model.add(Dense(256, activation='relu'))model.add(Dropout(0.5))model.add(Dense(10, activation='softmax'))sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)model.compile(loss='categorical_crossentropy', optimizer=sgd)model.fit(x_train, y_train, batch_size=32, epochs=10)score = model.evaluate(x_test, y_test, batch_size=32) |
基于LSTM的序列分类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | from keras.models import Sequentialfrom keras.layers import Dense, Dropoutfrom keras.layers import Embeddingfrom keras.layers import LSTMmodel = Sequential()model.add(Embedding(max_features, output_dim=256))model.add(LSTM(128))model.add(Dropout(0.5))model.add(Dense(1, activation='sigmoid'))model.compile(loss='binary_crossentropy', optimizer='rmsprop', metrics=['accuracy'])model.fit(x_train, y_train, batch_size=16, epochs=10)score = model.evaluate(x_test, y_test, batch_size=16) |
基于 1D 卷积的序列分类:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | from keras.models import Sequentialfrom keras.layers import Dense, Dropoutfrom keras.layers import Embeddingfrom keras.layers import Conv1D, GlobalAveragePooling1D, MaxPooling1Dmodel = Sequential()model.add(Conv1D(64, 3, activation='relu', input_shape=(seq_length, 100)))model.add(Conv1D(64, 3, activation='relu'))model.add(MaxPooling1D(3))model.add(Conv1D(128, 3, activation='relu'))model.add(Conv1D(128, 3, activation='relu'))model.add(GlobalAveragePooling1D())model.add(Dropout(0.5))model.add(Dense(1, activation='sigmoid'))model.compile(loss='binary_crossentropy', optimizer='rmsprop', metrics=['accuracy'])model.fit(x_train, y_train, batch_size=16, epochs=10)score = model.evaluate(x_test, y_test, batch_size=16) |
基于栈式 LSTM 的序列分类
在这个模型中,我们将 3 个 LSTM 层叠在一起,使模型能够学习更高层次的时间表示。
前两个 LSTM 返回完整的输出序列,但最后一个只返回输出序列的最后一步,从而降低了时间维度(即将输入序列转换成单个向量)。
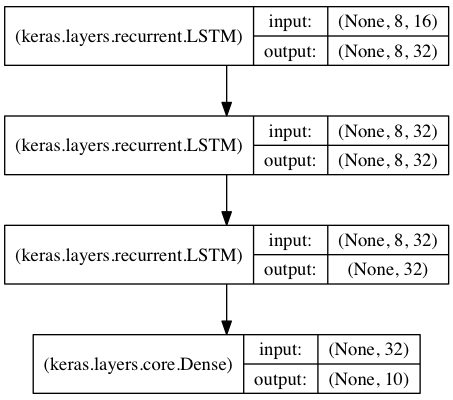
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | from keras.models import Sequentialfrom keras.layers import LSTM, Denseimport numpy as npdata_dim = 16timesteps = 8num_classes = 10# 期望输入数据尺寸: (batch_size, timesteps, data_dim)model = Sequential()model.add(LSTM(32, return_sequences=True, input_shape=(timesteps, data_dim))) # 返回维度为 32 的向量序列model.add(LSTM(32, return_sequences=True)) # 返回维度为 32 的向量序列model.add(LSTM(32)) # 返回维度为 32 的单个向量model.add(Dense(10, activation='softmax'))model.compile(loss='categorical_crossentropy', optimizer='rmsprop', metrics=['accuracy'])# 生成虚拟训练数据x_train = np.random.random((1000, timesteps, data_dim))y_train = np.random.random((1000, num_classes))# 生成虚拟验证数据x_val = np.random.random((100, timesteps, data_dim))y_val = np.random.random((100, num_classes))model.fit(x_train, y_train, batch_size=64, epochs=5, validation_data=(x_val, y_val)) |
带有状态 (stateful) 的 相同的栈式 LSTM 模型
有状态的循环神经网络模型中,在一个 batch 的样本处理完成后,其内部状态(记忆)会被记录并作为下一个 batch 的样本的初始状态。这允许处理更长的序列,同时保持计算复杂度的可控性。
你可以在 FAQ 中查找更多关于 stateful RNNs 的信息。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 | from keras.models import Sequentialfrom keras.layers import LSTM, Denseimport numpy as npdata_dim = 16timesteps = 8num_classes = 10batch_size = 32# 期望输入数据尺寸: (batch_size, timesteps, data_dim)# 请注意,我们必须提供完整的 batch_input_shape,因为网络是有状态的。# 第 k 批数据的第 i 个样本是第 k-1 批数据的第 i 个样本的后续。model = Sequential()model.add(LSTM(32, return_sequences=True, stateful=True, batch_input_shape=(batch_size, timesteps, data_dim)))model.add(LSTM(32, return_sequences=True, stateful=True))model.add(LSTM(32, stateful=True))model.add(Dense(10, activation='softmax'))model.compile(loss='categorical_crossentropy', optimizer='rmsprop', metrics=['accuracy'])# 生成虚拟训练数据x_train = np.random.random((batch_size * 10, timesteps, data_dim))y_train = np.random.random((batch_size * 10, num_classes))# 生成虚拟验证数据x_val = np.random.random((batch_size * 3, timesteps, data_dim))y_val = np.random.random((batch_size * 3, num_classes))model.fit(x_train, y_train, batch_size=batch_size, epochs=5, shuffle=False, validation_data=(x_val, y_val)) |
Sequential模型方法
1 compile
1 2 | compile(self, optimizer, loss=None, metrics=None, loss_weights=None, sample_weight_mode=None, weighted_metrics=None, target_tensors=None) |
用于配置训练模型。
1.1 参数
- optimizer: 字符串(优化器名)或者优化器对象。详见 optimizers。
- loss: 字符串(目标函数名)或目标函数。详见 losses。 如果模型具有多个输出,则可以通过传递损失函数的字典或列表,在每个输出上使用不同的损失。模型将最小化的损失值将是所有单个损失的总和。
- metrics: 在训练和测试期间的模型评估标准。通常你会使用
metrics = ['accuracy']。 要为多输出模型的不同输出指定不同的评估标准,还可以传递一个字典,如metrics = {'output_a':'accuracy'}。 - sample_weight_mode: 如果你需要执行按时间步采样权重(2D 权重),请将其设置为
temporal。 默认为None,为采样权重(1D)。如果模型有多个输出,则可以通过传递 mode 的字典或列表,以在每个输出上使用不同的sample_weight_mode。 - weighted_metrics: 在训练和测试期间,由 sample_weight 或 class_weight 评估和加权的度量标准列表。
- target_tensors: 默认情况下,Keras 将为模型的目标创建一个占位符,在训练过程中将使用目标数据。相反,如果你想使用自己的目标张量(反过来说,Keras 在训练期间不会载入这些目标张量的外部 Numpy 数据),您可以通过
target_tensors参数指定它们。它应该是单个张量(对于单输出 Sequential 模型)。 - **kwargs: 当使用 Theano/CNTK 后端时,这些参数被传入
K.function。当使用 TensorFlow 后端时,这些参数被传递到tf.Session.run。
1.2 异常
1 | ValueError: 如果 optimizer, loss, metrics 或 sample_weight_mode 这些参数不合法。 |
2 fit
1 2 3 4 | fit(self, x=None, y=None, batch_size=None, epochs=1, verbose=1, callbacks=None, validation_split=0.0, validation_data=None, shuffle=True, class_weight=None, sample_weight=None, initial_epoch=0, steps_per_epoch=None, validation_steps=None) |
以固定数量的轮次(数据集上的迭代)训练模型。
2.1 参数
- x: 训练数据的 Numpy 数组。 如果模型中的输入层被命名,你也可以传递一个字典,将输入层名称映射到 Numpy 数组。 如果从本地框架张量馈送(例如 TensorFlow 数据张量)数据,x 可以是
None(默认)。 - y: 目标(标签)数据的 Numpy 数组。 如果模型中的输出层被命名,你也可以传递一个字典,将输出层名称映射到 Numpy 数组。 如果从本地框架张量馈送(例如 TensorFlow 数据张量)数据,y 可以是
None(默认)。 - batch_size: 整数或
None。每次提度更新的样本数。如果未指定,默认为 32. - epochs: 整数。训练模型迭代轮次。一个轮次是在整个
x或y上的一轮迭代。请注意,与initial_epoch一起,epochs被理解为 「最终轮次」。模型并不是训练了epochs轮,而是到第epochs轮停止训练。 - verbose: 0, 1 或 2。日志显示模式。 0 = 安静模式, 1 = 进度条, 2 = 每轮一行。
- callbacks: 一系列的
keras.callbacks.Callback实例。一系列可以在训练时使用的回调函数。详见 callbacks。 - validation_split: 在 0 和 1 之间浮动。用作验证集的训练数据的比例。模型将分出一部分不会被训练的验证数据,并将在每一轮结束时评估这些验证数据的误差和任何其他模型指标。验证数据是混洗之前
x和y数据的最后一部分样本中。 - validation_data: 元组
(x_val,y_val)或元组(x_val,y_val,val_sample_weights),用来评估损失,以及在每轮结束时的任何模型度量指标。模型将不会在这个数据上进行训练。这个参数会覆盖validation_split。 - shuffle: 布尔值(是否在每轮迭代之前混洗数据)或者 字符串 (
batch)。batch是处理 HDF5 数据限制的特殊选项,它对一个 batch 内部的数据进行混洗。当steps_per_epoch非None时,这个参数无效。 - class_weight: 可选的字典,用来映射类索引(整数)到权重(浮点)值,用于加权损失函数(仅在训练期间)。这可能有助于告诉模型 「更多关注」来自代表性不足的类的样本。
- sample_weight: 训练样本的可选 Numpy 权重数组,用于对损失函数进行加权(仅在训练期间)。您可以传递与输入样本长度相同的平坦(1D)Numpy 数组(权重和样本之间的 1:1 映射),或者在时序数据的情况下,可以传递尺寸为
(samples, sequence_length)的 2D 数组,以对每个样本的每个时间步施加不同的权重。在这种情况下,你应该确保在compile()中指定sample_weight_mode="temporal"。 - initial_epoch: 开始训练的轮次(有助于恢复之前的训练)。
- steps_per_epoch: 在声明一个轮次完成并开始下一个轮次之前的总步数(样品批次)。使用 TensorFlow 数据张量等输入张量进行训练时,默认值
None等于数据集中样本的数量除以 batch 的大小,如果无法确定,则为 1。 - validation_steps: 只有在指定了
steps_per_epoch时才有用。停止前要验证的总步数(批次样本)。
2.2 返回
一个 History 对象。其 History.history 属性是连续 epoch 训练损失和评估值,以及验证集损失和评估值的记录(如果适用)。
2.3 异常
- RuntimeError: 如果模型从未编译。
- ValueError: 在提供的输入数据与模型期望的不匹配的情况下。
3 evaluate
1 2 | evaluate(self, x=None, y=None, batch_size=None, verbose=1, sample_weight=None, steps=None) |
在测试模式,返回误差值和评估标准值。
计算逐批次进行。
3.1 参数
- x: 输入数据,Numpy 数组或列表(如果模型有多输入)。 如果从本地框架张量馈送(例如 TensorFlow 数据张量)数据,x 可以是
None(默认)。 - y: 标签,Numpy 数组。 如果从本地框架张量馈送(例如 TensorFlow 数据张量)数据,y 可以是
None(默认)。 - batch_size: 整数。每次梯度更新的样本数。如果未指定,默认为 32。
- verbose: 日志显示模式,0 或 1。
- sample_weight: 样本权重,Numpy 数组。
- steps: 整数或
None。 声明评估结束之前的总步数(批次样本)。默认值None。
3.2 返回
标量测试误差(如果模型没有评估指标)或标量列表(如果模型计算其他指标)。 属性 model.metrics_names 将提供标量输出的显示标签。
4 predict
1 | predict(self, x, batch_size=None, verbose=0, steps=None) |
为输入样本生成输出预测。
计算逐批次进行。
4.1 参数
- x: 输入数据,Numpy 数组。
- batch_size: 整数。如未指定,默认为 32。
- verbose: 日志显示模式,0 或 1。
- steps: 声明预测结束之前的总步数(批次样本)。默认值
None。
4.2 返回
预测的 Numpy 数组。
4.3 异常
- ValueError: 如果提供的输入数据与模型的期望数据不匹配,或者有状态模型收到的数量不是批量大小的倍数。
5 train_on_batch
1 | train_on_batch(self, x, y, class_weight=None, sample_weight=None) |
一批样品的单次梯度更新。
5.1 Arguments
- x: 输入数据,Numpy 数组或列表(如果模型有多输入)。
- y: 标签,Numpy 数组。
- class_weight: 将类别映射为权重的字典,用于在训练时缩放损失函数。
- sample_weight: 样本权重,Numpy 数组。
5.2 返回
标量测试误差(如果模型没有评估指标)或标量列表(如果模型计算其他指标)。 属性 model.metrics_names 将提供标量输出的显示标签。
6 test_on_batch
1 | test_on_batch(self, x, y, sample_weight=None) |
在一批样本上评估模型。
6.1 参数
- x: 输入数据,Numpy 数组或列表(如果模型有多输入)。
- y: 标签,Numpy 数组。
- sample_weight: 样本权重,Numpy 数组。
6.2 返回
标量测试误差(如果模型没有评估指标)或标量列表(如果模型计算其他指标)。 属性 model.metrics_names 将提供标量输出的显示标签。
7 predict_on_batch
1 | predict_on_batch(self, x) |
返回一批样本的模型预测值。
7.1 参数
- x: 输入数据,Numpy 数组或列表(如果模型有多输入)。
7.2 返回
预测值的Numpy数组
8 fit_generator
1 2 3 4 | it_generator(self, generator, steps_per_epoch=None, epochs=1, verbose=1, callbacks=None, validation_data=None, validation_steps=None, class_weight=None, max_queue_size=10, workers=1, use_multiprocessing=False, shuffle=True, initial_epoch=0) |
使用 Python 生成器或 Sequence 实例逐批生成的数据,按批次训练模型。
生成器与模型并行运行,以提高效率。 例如,这可以让你在 CPU 上对图像进行实时数据增强,以在 GPU 上训练模型。
keras.utils.Sequence 的使用可以保证数据的顺序, 以及当 use_multiprocessing=True 时 ,保证每个输入在每个 epoch 只使用一次。
8.1 参数
- generator: 一个生成器或
Sequence(keras.utils.Sequence)。 生成器的输出应该为以下之一: - 一个
(inputs, targets)元组 - 一个
(inputs, targets, sample_weights)元组。 所有的数组都必须包含同样数量的样本。生成器将无限地在数据集上循环。当运行到第steps_per_epoch时,记一个 epoch 结束。 - steps_per_epoch: 在声明一个 epoch 完成并开始下一个 epoch 之前从
generator产生的总步数(批次样本)。它通常应该等于你的数据集的样本数量除以批量大小。可选参数Sequence:如果未指定,将使用len(generator)作为步数。 - epochs: 整数,数据的迭代总轮数。请注意,与 initial_epoch 一起,参数
epochs应被理解为 「最终轮数」。模型并不是训练了epochs轮,而是到第epochs轮停止训练。 - verbose: 日志显示模式。0,1 或 2。
- callbacks: 在训练时调用的一系列回调函数。
- validation_data: 它可以是以下之一:
- 验证数据的生成器或
Sequence实例 - 一个
(inputs, targets)元组 - 一个
(inputs, targets, sample_weights)元组。 - validation_steps: 仅当
validation_data是一个生成器时才可用。 每个 epoch 结束时验证集生成器产生的步数。它通常应该等于你的数据集的样本数量除以批量大小。可选参数Sequence:如果未指定,将使用len(generator)作为步数。 - class_weight: 将类别映射为权重的字典。
- max_queue_size: 生成器队列的最大尺寸。
- workers: 使用的最大进程数量。
- use_multiprocessing: 如果 True,则使用基于进程的多线程。 请注意,因为此实现依赖于多进程,所以不应将不可传递的参数传递给生成器,因为它们不能被轻易地传递给子进程。
- shuffle: 是否在每轮迭代之前打乱 batch 的顺序。只能与
Sequence(keras.utils.Sequence) 实例同用。 - initial_epoch: 开始训练的轮次(有助于恢复之前的训练)。
8.2 返回
一个 History 对象。
8.3 异常
- ValueError: 如果生成器生成的数据格式不正确。
8.4 例
1 2 3 4 5 6 7 8 9 10 11 | def generate_arrays_from_file(path): while 1: f = open(path) for line in f: # 从文件中的每一行生成输入数据和标签的 numpy 数组 x, y = process_line(line) yield (x, y) f.close()model.fit_generator(generate_arrays_from_file('/my_file.txt'), steps_per_epoch=1000, epochs=10) |
9 evaluate_generator
1 2 | evaluate_generator(self, generator, steps=None, max_queue_size=10, workers=1, use_multiprocessing=False) |
在数据生成器上评估模型。
这个生成器应该返回与 test_on_batch 所接收的同样的数据。
9.1 参数
- generator: 生成器,生成 (inputs, targets) 或 (inputs, targets, sample_weights)
- steps: 在停止之前,来自
generator的总步数 (样本批次)。 可选参数Sequence:如果未指定,将使用len(generator)作为步数。 - max_queue_size: 生成器队列的最大尺寸。
- workers: 使用的最大进程数量。
- use_multiprocessing: 如果 True,则使用基于进程的多线程。 请注意,因为此实现依赖于多进程,所以不应将不可传递的参数传递给生成器,因为它们不能被轻易地传递给子进程。
9.2 返回
标量测试误差(如果模型没有评估指标)或标量列表(如果模型计算其他指标)。 属性 model.metrics_names 将提供标量输出的显示标签。
9.3 异常
ValueError如果生成器生成的数据格式不正确
10 predict_generator
1 2 | predict_generator(self, generator, steps=None, max_queue_size=10, workers=1, use_multiprocessing=False, verbose=0) |
为来自数据生成器的输入样本生成预测。
这个生成器应该返回与 predict_on_batch 所接收的同样的数据。
10.1 参数
- generator: 返回批量输入样本的生成器。
- steps: 在停止之前,来自
generator的总步数 (样本批次)。 可选参数Sequence:如果未指定,将使用len(generator)作为步数。 - max_queue_size: 生成器队列的最大尺寸。
- workers: 使用的最大进程数量。
- use_multiprocessing: 如果 True,则使用基于进程的多线程。 请注意,因为此实现依赖于多进程,所以不应将不可传递的参数传递给生成器,因为它们不能被轻易地传递给子进程。
- verbose: 日志显示模式, 0 或 1。
10.2 返回
预测值的 Numpy 数组。
10.3 异常- ValueError: 如果生成器生成的数据格式不正确。
11 get_layer
1 | get_layer(self, name=None, index=None) |
根据名称(唯一)或索引值查找网络层。
如果同时提供了 name 和 index,则 index 将优先。
根据网络层的名称(唯一)或其索引返回该层。索引是基于水平图遍历的顺序(自下而上)。
11.1 参数
- name: 字符串,层的名字。
- index: 整数,层的索引。
11.2 返回
一个层实例。
11.3 异常
- ValueError: 如果层的名称或索引不正确。
此文是本人自己的学习笔记,参考Keras官方文档,如有侵权请联系,谢谢!






【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!
2017-09-12 python 浅析模块,包及其相关用法