
我的Keras使用总结(3)——利用bottleneck features进行微调预训练模型VGG16
完整代码及其数据,请移步小编的GitHub地址
传送门:请点击我
如果点击有误:https://github.com/LeBron-Jian/DeepLearningNote
Keras的预训练模型地址:https://github.com/fchollet/deep-learning-models/releases
一个稍微讲究一点的办法是,利用在大规模数据集上预训练好的网络。这样的网络在多数的计算机视觉问题上都能取得不错的特征,利用这样的特征可以让我们获得更高的准确率。
1,使用预训练网络的 bottleneck 特征:一分钟达到90%的正确率
我们将使用VGG-16网络,该网络在 ImageNet数据集上进行训练,这个模型我们之前提到过了。因为 ImageNet 数据集包含多种“猫”类和多种“狗”类,这个模型已经能够学习与我们这个数据集相关的特征了。事实上,简单的记录原来网络的输出而不用 bottleneck特征就已经足够把我们的问题解决的不错了。不过我们这里讲的方法对其他的类似问题有更好的推广性,包括在ImageNet中没有出现类别的分类问题。
所以我们这里的分类,不做猫狗二分类,我做的和上一节一样的数据集,就是五分类的问题,依然对照Keras的中文文档,借鉴猫狗二分类,做我们的五分类。
VGG的博文介绍可以参考我之前的博客:
tensorflow学习笔记——VGGNet
VGG-16 的网络结构如下:
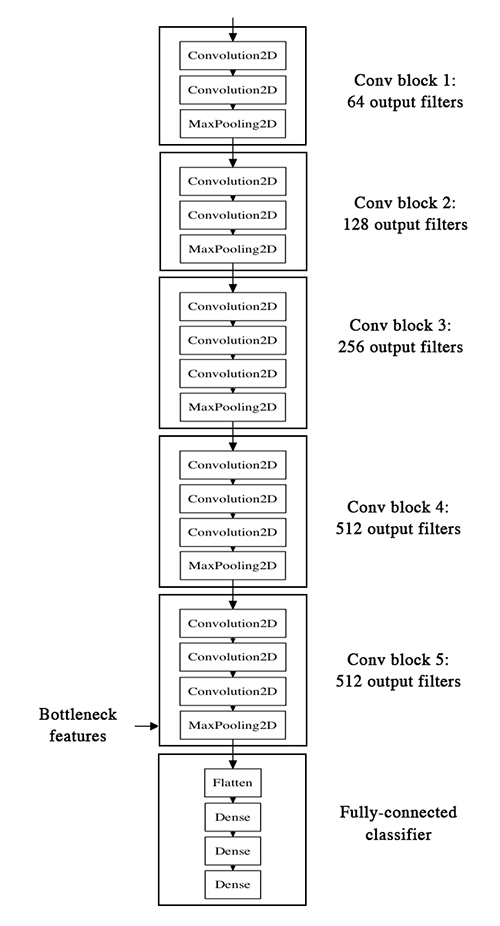
我们的方法是这样的,我们将利用网络的卷积层部分,把全连接以下的部分抛掉,然后在我们的训练集和测试集上跑一遍,将得到的输出(即“bottleneck feature”,网络在全连接之前的最后一层激活的 feature map)记录在两个 numpy array 里面。然后我们基于记录下来的特征训练一个全连接层。
我们将这些特征保存为离线形式,而不是将我们的全连接模型直接加到网络上并冻结之前的层参数进行训练的原因是处于计算效率的考虑。运行VGG网络的代价是非常高昂的,尤其是在CPU上运行,所以我们只想运行一次,这也是我们不进行数据提升的原因。
我们将不再赘述如何搭建 VGG-16 网络了。这个在Keras的example里也可以找到,这个博文里面有Keras的关于VGG的examples:
深入学习Keras中Sequential模型及方法
下面让我们看看如何记录 bottleneck特征。
generator = datagen.flow_from_directory(
'data/train',
target_size=(150, 150),
batch_size=32,
class_mode=None,
shuffle=False
)
# the predict_generator method returns the output of a model
# given a generator that yields batches of numpy data
bottleneck_feature_train = model.predict_generator(generator, 2000)
# save the output as a Numpy array
np.save(open('bottleneck_features_train.npy', 'w'), bottleneck_feature_train)
generator = datagen.flow_from_directory(
'data/validation',
target_size=(150, 150),
batch_size=32,
class_mode=None,
shuffle=False
)
bottleneck_feature_validaion = model.predict_generator(generator, 2000)
# save the output as a Numpy array
np.save(open('bottleneck_features_validation.npy', 'w'), bottleneck_feature_validaion)
记录完毕后我们可以将数据载入,用于训练我们的全连接网络:
train_data = np.load(open('bottleneck_features_train.npy'))
# the features were saved in order, so recreating the labels is easy
train_labels = np.array([0] * 1000 + [1] * 1000)
validation_data = np.load(open('bottleneck_features_validation.npy'))
validation_labels = np.array([0] * 400 + [1] * 400)
model = Sequential()
model.add(Flatten(input_shape=train_data.shape[1:]))
model.add(Dense(256, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
model.fit(train_data, train_labels, nb_epoch=50, batch_size=32,
validation_data=(validation_data, validation_labels))
model.sample_weights('bottleneck_fc_model.h5')
因为特征的size很小,模型在CPU上跑的也会很快,大概1s一个epoch,最后我们的准确率时90%~91%,这么好的结果多半归功于预训练的VGG网络帮助我们提取特征。
Keras中文文档好像有漏洞,导致内容不连贯,但是大概的代码是没有问题的,可是还是会报错,所以我这里整理一下自己的笔记。
本节主要是通过已经训练好的模型,把bottleneck特征抽取出来,然后滚到下一个“小”模型里面,也就是全连接层。
实施步骤:
- 1,把训练好的模型的权重拿来,model;
- 2,运行,提取 bottleneck feature(网络在全连接之前的最后一层激活的feature map 卷积——全连接层之间),单独拿出来,并保存;
- 3,bottleneck层数据,之后 + dense 全连接层,进行 fine-tuning;
步骤1:导入预训练权重与网络框架
原作者博客地址:https://blog.keras.io/how-convolutional-neural-networks-see-the-world.html
WEIGHTS_PATH = '/keras/animal5/vgg16_weights_tf_dim_ordering_tf_kernels.h5' WEIGHTS_PATH_NO_TOP = '/keras/animal5/vgg16_weights_tf_dim_ordering_tf_kernels_notop.h5' from keras.applications.vgg16_matt import VGG16 model = VGG16(include_top=False, weights='imagenet')
其中 WEIGHTS_PATH_NO_TOP 就是去掉了全连接层,可以用它直接提取 bottleneck的特征。
注意上面的地址,是我导入的VGG16的官网h5模型,我将源码修改了,把VGG16的官方h5下载下来运行的话,比较快。
步骤2:提取图片的bottleneck特征
需要的步骤:载入图片;灌入 pre_model的权重;得到 bottleneck feature
# 提取图片中的 bottleneck 特征
'''
步骤:1,载入图片
2,灌入 pre_model 的权重
3,得到 bottleneck feature
'''
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D
from keras.layers import Activation, Dropout, Flatten, Dense
# 载入图片 图片生成器初始化
from keras.preprocessing.image import ImageDataGenerator
import numpy as np
from keras.applications.vgg16 import VGG16
model = VGG16(include_top=False, weights='imagenet', input_shape=(150, 150, 3))
print('load model ok')
datagen = ImageDataGenerator(rescale=1./255)
# 训练集图像生成器
train_generator = datagen.flow_from_directory(
'data/mytrain',
target_size=(150, 150),
batch_size=32,
class_mode=None,
shuffle=False
)
# 验证集图像生成器
test_generator = datagen.flow_from_directory(
'data/mytest',
target_size=(150, 150),
batch_size=32,
class_mode=None,
shuffle=False
)
print('increase image ok')
# 灌入 pre_model 的权重
WEIGHTS_PATH = ''
model.load_weights('data/vgg16_weights_tf_dim_ordering_tf_kernels_notop.h5')
print('load pre model OK ')
# 得到 bottleneck feature
bottleneck_features_train = model.predict_generator(train_generator, 500)
# 核心,steps是生成器要返回数据的轮数,每个epoch含有500张图片,与model.fit(samples_per_epoch)相对
# 如果这样的话,总共有 500*32个训练样本
np.save(open('bottleneck_features_train.npy', 'w'), bottleneck_features_train)
bottleneck_features_validation = model.predict_generator(test_generator, 100)
# 与model.fit(nb_val_samples)相对,一个epoch有800张图片,验证集
np.save(open('bottleneck_features_validation.npy', 'w'), bottleneck_features_validation)
注意1:
- class_mode: 此时为预测场景,制作数据阶段,不用设置标签,因为此时是按照顺序产生;而在 train_generator 数据训练之前的数据准备,则需要设置标签。
- shuffle:此时为预测场景,制作数据集,不用打乱;但是在 model.fit 过程中需要打乱,表示是否在训练过程中每个 epoch 前随机打乱输入样本的顺序。
注意2:上面会报错:TypeError: write() argument must be str, not bytes
解决方法:
将:
np.save(open('test.npy', 'w'), block4_pool_features)
修改为:
np.save('test.npy', block4_pool_features)
注意3:在window上跑,会占满内存,根本跑不动,在linux上也会报错,比如临时内存不足等。
解决方法(同时修改batch_size,将其变小):
import tensorflow as tf import os from keras.backend.tensorflow_backend import set_session os.environ["CUDA_VISIBLE_DEVICES"] = "1,2" config = tf.ConfigProto() config.gpu_options.per_process_gpu_memory_fraction = 0.3 set_session(tf.Session(config=config))
当batch_size 设置为32,会报错:

还是内存问题,即使我设置三个GPU都没用,但是设为16就可以了。真的是。。。。。
注意4:报错:RuntimeError: can't start new thread
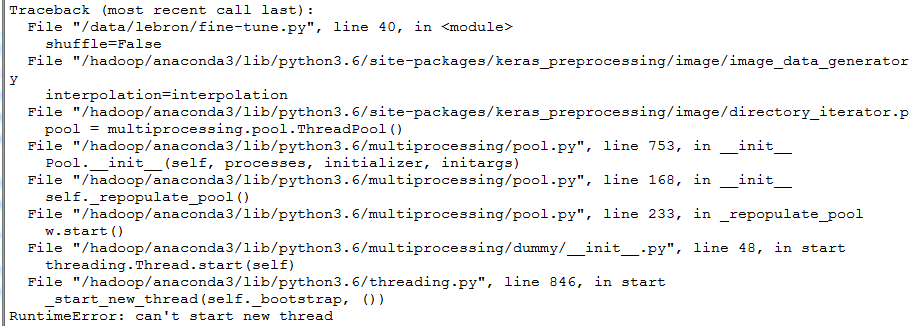
之前都没问题,今天就出问题了,记下来,真恶心。
注意5:GPU服务器笔记 报错:tensorflow.python.framework.errors_impl.InternalError: Dst tensor is not initialized.
这个网上说是GPU的内存不够了,换一个空闲的GPU就可以跑了。
注意6:terminate called after throwing an instance of 'std::system_error' what(): Resource temporarily unavailable

注意7:Segmentation fault (core dumped)问题
解释一下,注意4,5,6,7 是同一类错误,就是我的代码本身是没有任何问题的,只是我家的服务器出了问题,这个通常是指针错误引起的,而且这个错误会生成相应的 core file。
发生了core dump 之后,我们可以用 gdb 进行查看 core 文件的内容,以定位文件中引发 core dump的行:
gdb [exec file] [core file]
如:gdb ./test test.core 在进入gdb后, 用bt命令查看backtrace以检查发生程序运行到哪里,来定位core dump的文件->行。
那么什么是core?
在使用半导体作为内存的材料钱,人类是利用线圈当做内存的材料(发明者为王安),线圈就叫做 core,用线圈做的内存就叫做 core memory。如今,半导体工业蓬勃发展,已经没有人用 core memory 了,不过,在许多情况下,人们还是把记忆体叫做 core。
那么什么是 Core dump:
我们在开发(或使用)一个程序时,最怕的就是程序莫名其妙的dang掉,虽然系统没事,但我们下次仍可能遇到相同的问题,于是这时操作系统就会把程序dang掉时的内存内容 dump出来(现在通常是写在一个叫 core 的 file 里面),让我们或是 debugger作为参考,这个动作就叫做 core dump。
那么core dump时会生成何种文件?
core dump 时,会生成诸如 core. 进程号的文件
利用上面,查看问题出在哪里,发现有人将服务器上的TensorFlow锁住了,解锁就好了,又或者是方便的话可以直接重启服务器(可能大家都不会遇到后面几个问题。。请略过)。
完整代码:
#_*_coding:utf-8_*_
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D
from keras.layers import Activation, Dropout, Flatten, Dense
from keras.preprocessing.image import ImageDataGenerator
import numpy as np
from keras.applications.vgg16 import VGG16
import os
from keras.backend.tensorflow_backend import set_session
import tensorflow as tf
os.environ['CUDA_VISIBLE_DEVICES'] = '1,2,3'
config = tf.ConfigProto()
config.gpu_options.per_process_gpu_memory_fraction = 0.4
#config.gpu_options.allow_growth = True
#sess = tf.Session(config=config)
set_session(tf.Session(config=config))
model = VGG16(include_top=False, weights='imagenet', input_shape=(150, 150, 3))
print('load model ok')
datagen = ImageDataGenerator(rescale=1./255)
train_generator = datagen.flow_from_directory(
'/data/lebron/data/mytrain',
target_size=(150, 150),
batch_size=4,
class_mode=None,
shuffle=False
)
test_generator = datagen.flow_from_directory(
'/data/lebron/data/mytest',
target_size=(150, 150),
batch_size=4,
class_mode=None,
shuffle=False
)
print('increase image ok')
model.load_weights('/data/lebron/data/vgg16_weights_tf_dim_ordering_tf_kernels_notop.h5')
print('load pre model OK ')
bottleneck_features_train = model.predict_generator(train_generator, 125)
np.save('/data/lebron/bottleneck_features_train.npy', bottleneck_features_train)
bottleneck_features_validation = model.predict_generator(test_generator, 25)
np.save('/data/lebron/bottleneck_features_validation.npy', bottleneck_features_validation)
print('game over')
注意上面的修改细节,后面会继续学习,并展开叙述。
步骤3:fine-tuning “小” 网络
主要步骤:
- 1,导入 bottleneck features 数据
- 2,设置标签,并规范成 Keras默认格式
- 3,写“小网络” 的网络结构
- 4,设置参数并训练
# (1)导入bottleneck_features数据
train_data = np.load(open('bottleneck_features_train.npy'))
# the features were saved in order, so recreating the labels is easy
train_labels = np.array([0] * 100 + [1] * 100 + [2] * 100 + [3] * 100 + [4] * 96) # matt,打标签
validation_data = np.load(open('bottleneck_features_validation.npy'))
validation_labels = np.array([0] * 20 + [1] * 20 + [2] * 20 + [3] * 20 + [4] * 16) # matt,打标签
# (2)设置标签,并规范成Keras默认格式
train_labels = keras.utils.to_categorical(train_labels, 5)
validation_labels = keras.utils.to_categorical(validation_labels, 5)
# (3)写“小网络”的网络结构
model = Sequential()
#train_data.shape[1:]
model.add(Flatten(input_shape=(4,4,512)))# 4*4*512
model.add(Dense(256, activation='relu'))
model.add(Dropout(0.5))
#model.add(Dense(1, activation='sigmoid')) # 二分类
model.add(Dense(5, activation='softmax')) # matt,多分类
#model.add(Dense(1))
#model.add(Dense(5))
#model.add(Activation('softmax'))
# (4)设置参数并训练
model.compile(loss='categorical_crossentropy',
# matt,多分类,不是binary_crossentropy
optimizer='rmsprop',
metrics=['accuracy'])
model.fit(train_data, train_labels,
nb_epoch=50, batch_size=16,
validation_data=(validation_data, validation_labels))
model.save_weights('bottleneck_fc_model.h5')
结果如下:
Epoch 50/50 16/500 [..............................] - ETA: 0s - loss: 0.0704 - acc: 1.0000 48/500 [=>............................] - ETA: 0s - loss: 0.0248 - acc: 1.0000 80/500 [===>..........................] - ETA: 0s - loss: 0.0472 - acc: 0.9750 112/500 [=====>........................] - ETA: 0s - loss: 0.0397 - acc: 0.9821 144/500 [=======>......................] - ETA: 0s - loss: 0.0537 - acc: 0.9722 176/500 [=========>....................] - ETA: 0s - loss: 0.0567 - acc: 0.9716 208/500 [===========>..................] - ETA: 0s - loss: 0.0551 - acc: 0.9712 240/500 [=============>................] - ETA: 0s - loss: 0.0707 - acc: 0.9667 272/500 [===============>..............] - ETA: 0s - loss: 0.0676 - acc: 0.9706 304/500 [=================>............] - ETA: 0s - loss: 0.0620 - acc: 0.9737 336/500 [===================>..........] - ETA: 0s - loss: 0.0579 - acc: 0.9762 368/500 [=====================>........] - ETA: 0s - loss: 0.0574 - acc: 0.9783 400/500 [=======================>......] - ETA: 0s - loss: 0.0596 - acc: 0.9750 432/500 [========================>.....] - ETA: 0s - loss: 0.0595 - acc: 0.9745 464/500 [==========================>...] - ETA: 0s - loss: 0.0574 - acc: 0.9763 496/500 [============================>.] - ETA: 0s - loss: 0.0546 - acc: 0.9778 500/500 [==============================] - 1s 2ms/step - loss: 0.0563 - acc: 0.9760 - val_loss: 8.0778 - val_acc: 0.2700
准确率还是挺高的。
完整代码:
# 提取图片中的 bottleneck 特征
'''
步骤:1,载入图片
2,灌入 pre_model 的权重
3,得到 bottleneck feature
'''
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D
from keras.layers import Activation, Dropout, Flatten, Dense
# 载入图片 图片生成器初始化
from keras.preprocessing.image import ImageDataGenerator
import numpy as np
from keras.applications.vgg16 import VGG16
import keras
def save_bottleneck_features():
model = VGG16(include_top=False, weights='imagenet', input_shape=(150, 150, 3))
print('load model ok')
datagen = ImageDataGenerator(rescale=1./255)
# 训练集图像生成器
train_generator = datagen.flow_from_directory(
'data/mytrain',
target_size=(150, 150),
batch_size=16,
class_mode=None,
shuffle=False
)
# 验证集图像生成器
test_generator = datagen.flow_from_directory(
'data/mytest',
target_size=(150, 150),
batch_size=16,
class_mode=None,
shuffle=False
)
print('increase image ok')
# 灌入 pre_model 的权重
WEIGHTS_PATH = ''
model.load_weights('data/vgg16_weights_tf_dim_ordering_tf_kernels_notop.h5')
print('load pre model OK ')
# 得到 bottleneck feature
bottleneck_features_train = model.predict_generator(train_generator, 500)
# 核心,steps是生成器要返回数据的轮数,每个epoch含有500张图片,与model.fit(samples_per_epoch)相对
# 如果这样的话,总共有 500*32个训练样本
np.save('bottleneck_features_train.npy', 'w', bottleneck_features_train)
bottleneck_features_validation = model.predict_generator(test_generator, 100)
# 与model.fit(nb_val_samples)相对,一个epoch有800张图片,验证集
np.save('bottleneck_features_validation.npy', 'w', bottleneck_features_validation)
def train_fine_tune():
trainfile = 'data/model/train.npy'
testfile = 'data/model/validation.npy'
# (1) 导入 bottleneck features数据
train_data = np.load(trainfile)
print(train_data.shape) # (8000, 4, 4, 512)
# train_data = train_data.reshape(train_data.shape[0], 150, 150, 3)
# the features were saved in order, so recreating the labels is easy
train_labels = np.array(
[0]*100 + [1]*100 + [2]*100 + [3]*100 + [4]*100
)
validation_data = np.load(testfile)
print(validation_data.shape) # (1432, 4, 4, 512)
validation_labels = np.array(
[0]*20 + [1]*20 + [2]*20 + [3]*20 + [4]*20
)
# (2) 设置标签,并规范成Keras默认格式
train_labels = keras.utils.to_categorical(train_labels, 5)
validation_labels = keras.utils.to_categorical(validation_labels, 5)
print(train_labels.shape, validation_labels.shape) # (8000, 5) (1432, 5)
# (3) 写“小网络”的网络结构
model = Sequential()
# train_data.shape[1:]
model.add(Flatten(input_shape=(4, 4, 512))) #4*4*512
model.add(Dense(256, activation='relu'))
model.add(Dropout(0.5))
# model.add(Dense(1, activation='sigmoid')) # 二分类
model.add(Dense(5, activation='softmax')) # 多分类
# (4) 设置参数并训练
model.compile(loss='categorical_crossentropy', # 两分类是 binary_crossentropy
optimizer='rmsprop',
metrics=['accuracy'])
model.fit(train_data, train_labels,
nb_epoch=50, batch_size=16,
validation_data=(validation_data, validation_labels))
model.save_weights('bottleneck_fc_model.h5')
if __name__ == '__main__':
# save_bottleneck_features()
train_fine_tune()
# print('over')
注意:这里有个大问题,就是会报错:

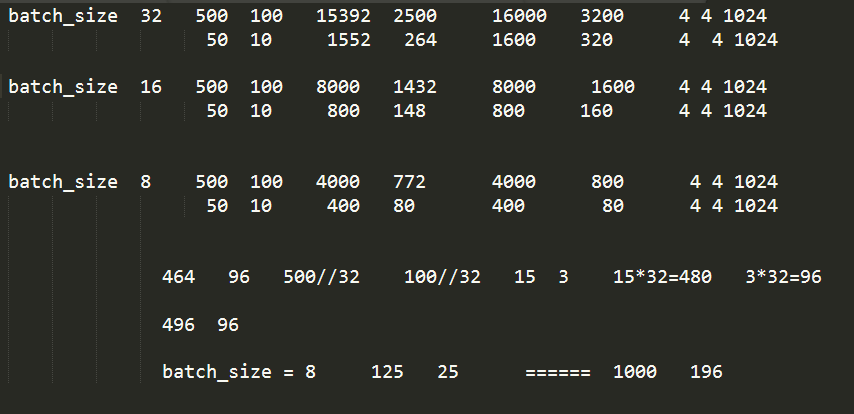
为什么呢?我们的npy文件的尺寸,我们可以查看一下:
trainfile = 'data/model/bottleneck_features_train.npy' testfile = 'data/model/bottleneck_features_validation.npy' # (1) 导入 bottleneck features数据 train_data = np.load(trainfile) print(train_data.shape) validation_data = np.load(testfile) print(validation_data.shape) (8000, 4, 4, 512) (1432, 4, 4, 512)
根本就不是 500 100
修改方法:
# 得到 bottleneck feature
bottleneck_features_train = model.predict_generator(train_generator, 500//batch_size)
bottleneck_features_validation = model.predict_generator(test_generator, 100//batch_size)
具体原因,我还不知道为什么。(具体原因找到了,往后看)
再百度,找到一篇文章:
【详解】keras + predict_generator + ImageDataGenerator.flow_from_ditectory 进行预测
其文章的大概意思呢,和我遇到的问题差不多,就是说在利用Keras进行预测分类,也就是运行下面的代码:
bottleneck_features_train = model.predict_generator(train_generator, 500)
的时候,我们从文件夹直接读取图片(直接利用flow_from_directory ),并经过ImageDataGenerator进行增强。他遇到的坑也是 flow_from_directory 的batch_size的问题,如果这个batch_size设置不对,那么预测的结果与图片不对应。
他的文章好像意思是:如果不知道batch_size 的设置,就请设置为1,如果设置为1,虽然可能会变慢,但是保证不会出错,而他设置的1,是这样的:
test_datagen = ImageDataGenerator(rescale=1./255)
test_generator = test_datagen.flow_from_directory('/predict', target_size=(height, width),
batch_size=1,class_mode='categorical', shuffle=False,)
然后生成器是这样的:
val_generator.reset() pred = model.predict_generator(val_generator, verbose=1)
综合起来,代码是这样的:
导入你的模型
导入你的参数
train_datagen = ImageDataGenerator(rescale=1./255, rotation_range=40, fill_mode='wrap')
train_generator = train_datagen.flow_from_directory('new_images', target_size=(height, width), batch_size=96)
val_datagen = ImageDataGenerator(rescale=1./255)
test_generator = test_datagen.flow_from_directory('AgriculturalDisease_validationset/predict', target_size=(height, width),batch_size=1,class_mode='categorical', shuffle=False,)
test_generator.reset()
pred = model.predict_generator(test_generator, verbose=1)
predicted_class_indices = np.argmax(pred, axis=1)
labels = (train_generator.class_indices)
label = dict((v,k) for k,v in labels.items())
# 建立代码标签与真实标签的关系
predictions = [label[i] for i in predicted_class_indices]
#建立预测结果和文件名之间的关系
filenames = test_generator.filenames
for idx in range(len(filenames )):
print('predict %d' % (int(predictions[idx])))
print('title %s' % filenames[idx])
print('')
也就是说,他在model.predict_generator(test_generator, verbose=1) 中,什么都没有设置,我们尝试一下。将预测代码改为下面:
bottleneck_features_train = model.predict_generator(train_generator, verbose=1) bottleneck_features_validation = model.predict_generator(test_generator, verbose=1)
会报错,我们将 train改回来,发现,也会报错:
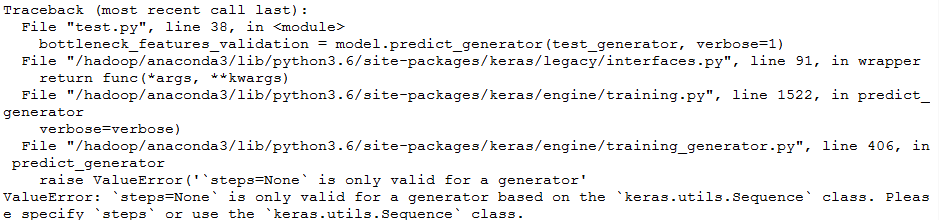
对于这个predict_generator函数,百度不了几个,我真的是难受,痛定思痛,我觉得还是查看源码比较好。
def predict_generator(self, generator,
steps=None,
max_queue_size=10,
workers=1,
use_multiprocessing=False,
verbose=0):
"""Generates predictions for the input samples from a data generator.
The generator should return the same kind of data as accepted by
`predict_on_batch`.
# Arguments
generator: Generator yielding batches of input samples
or an instance of Sequence (keras.utils.Sequence)
object in order to avoid duplicate data
when using multiprocessing.
steps: Total number of steps (batches of samples)
to yield from `generator` before stopping.
Optional for `Sequence`: if unspecified, will use
the `len(generator)` as a number of steps.
max_queue_size: Maximum size for the generator queue.
workers: Integer. Maximum number of processes to spin up
when using process based threading.
If unspecified, `workers` will default to 1. If 0, will
execute the generator on the main thread.
use_multiprocessing: If `True`, use process based threading.
Note that because
this implementation relies on multiprocessing,
you should not pass
non picklable arguments to the generator
as they can't be passed
easily to children processes.
verbose: verbosity mode, 0 or 1.
# Returns
Numpy array(s) of predictions.
# Raises
ValueError: In case the generator yields
data in an invalid format.
"""
return training_generator.predict_generator(
self, generator,
steps=steps,
max_queue_size=max_queue_size,
workers=workers,
use_multiprocessing=use_multiprocessing,
verbose=verbose)
此函数的意思是从数据生成器为输入样本生成预测。这个生成器应该返回与predict_on_batch 所接受的数据相同的数据类型,注意这个 predict_on_batch 就很有意思了,从我实践中来看,这个有意思的说法,就是 说返回值在你输入的predict_number 的基础上乘以 batch_size,这样才合理。
终于找到原因了,真的是开心哈,然后修改对应的 batch_size和predict_generator的参数,然后运行代码,执行成功。
继续找的规律,但是没有找到。
2,在预训练的网络上 fine-tune
为了进一步提高之前的结果,我们可以试着fine-tune网络的后面几层,Fine-tune以一个预训练好的网络为基础,在新的数据集上重新训练一小部分权重。
在这个实验中,fine-tune 分为三个步骤:
- 1,搭建VGG-16并载入权重
- 2,将之前定义的全连接网络加在模型的顶部,并载入权重
- 3,冻结VGG-16网络的一部分参数
- 4,模型训练
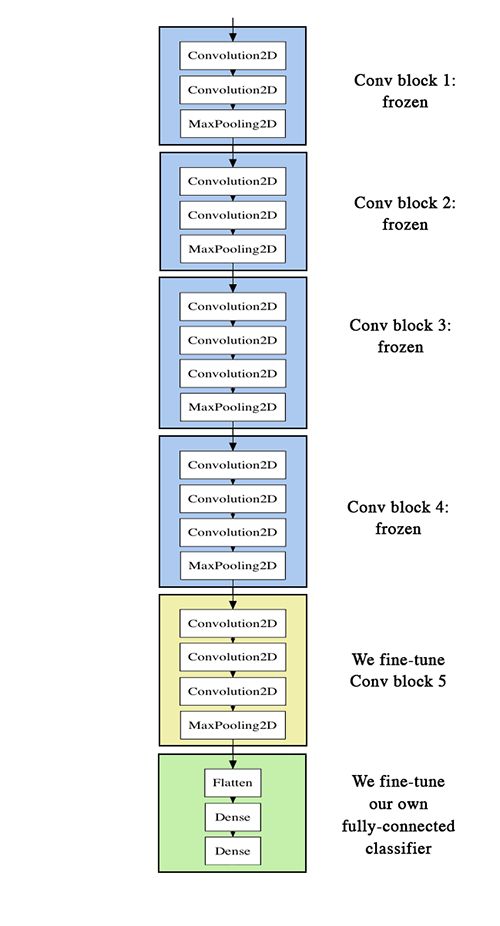
注意:
- 为了进行 fine-tune,所有的层都应该以训练好的权重为初始值,例如,你不能将随机初始的全连接放在预训练的卷积层之上,这是因为由随机权重产生的大梯度将会破坏卷积层预训练的权重。在我们的情形中,这就是为什么我们首先训练顶层分类器,然后再基于它进行 fine-tune 的原因
- 我们选择只fine-tune 最后的卷积块,而不是整个网络,这是为了防止过拟合。整个网络具有巨大的熵容量,因此具有很高的过拟合倾向。由底层卷积模块学习到的特征更加一般,更加不具有抽象性,因此我们要保持前两个卷积块(学习一般特征)不动,只 fine-tune 后面的卷积块(学习特别的特征)
- fine-tune 应该在很低的学习率下进行,通常使用 SGD 优化而不是其他自适应学习率的优化算法,比如 RMSProp,这是为了保证更新的幅度保持在较低的程度,以免毁坏预训练的特征。
2.1 下面均是Keras文档的内容
代码如下,首先在初始化好的VGG网络上添加我们预训练好的模型。
from keras.layers import Conv2D, Dense, Dropout, Flatten from keras.models import Sequential # build a classifier model to put on top of the convolution model top_model = Sequential() top_model.add(Flatten(input_shape=model.output_shape[1:])) top_model.add(Dense(256, activation='relu')) top_model.add(Dropout(0.5)) top_model.add(Dense(1, activation='sigmoid')) # note that it is neccessary to start with a fully-trained classifier # including the top classifier, in order to successfully to do fine-tuning top_model.load_weights(top_model_weights_path) # add the model on top of the convolutional base model.add(top_model)
然后将最后一个卷积块前的卷积层参数冻结:
# 然后将最后一个卷积块前的卷积层参数冻结
# set the first 25 layers (up to the last conv block)
# to non-trainable (weights will not be updated)
for layer in model.layers[: 25]:
layer.trainable = False
# compile the model with a SGD/momentum optimizer and a very slow learning rate
model.compile(loss='binary_crossentropy',
optimizer=optimizers.SGD(lr=1e-4, momentum=0.9),
metrics=['accuracy'])
然后以很低的学习率去训练:
# 然后以很低的学习率学习
# prepare data augmentation configuration
train_datagen = ImageDataGenerator(rescale=1. / 255)
train_generator = train_datagen.flow_from_directory(
validation_data_dir,
target_size=(img_height, img_width),
batch_size=32,
class_mode='binary'
)
validation_generator = test_datagen.flow_from_directory(
validation_data_dir,
target_size=(img_height, img_width),
batch_size=32,
class_mode='binary'
)
# fine-tune the model
model.fit_generator(
train_generator,
sample_per_epoch=nb_train_samples,
nb_epochs=nb_epoch,
validation_data=validation_generator,
nb_val_samples=nb_validation_samples
)
在五十个 peoch之后该方法的准确率达到 94% ,非常成功。
通过下面的方法你可以达到 95% 以上的正确率:
- 1,更加强烈的数据提升
- 2,更加强烈的dropout
- 3,使用L1和L2正则项(也成为权重衰减)
- 4,fine-tune更多的卷积块(配合更大的正则)
2.2 我的修改
中文文档是使用Sequential式那样写的,但是没有找到对的权重:top_model_weights_path,如果不正确的权重文件会报错:
ValueError: You are trying to load a weight file containing 16 layers into a model with 2 layers.
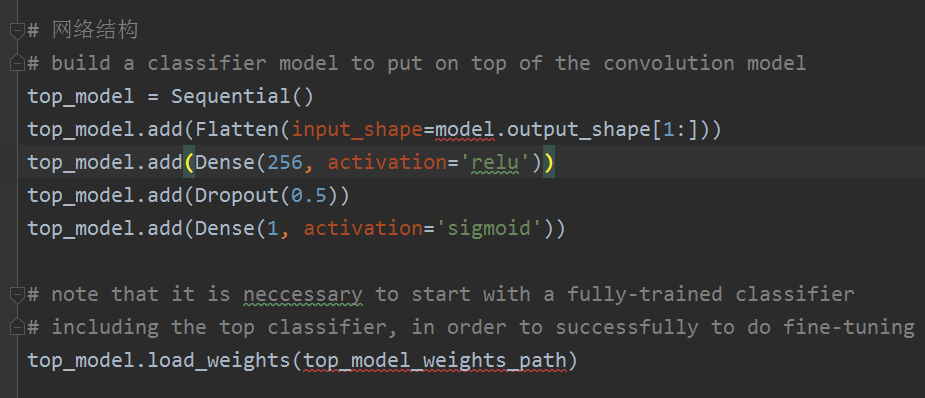
也就是说,看中文文档,我们不知道model是什么,不知道 top_model_weights_path 是哪个,
当然看原作者的代码,我们知道了这里的 model就是我们要微调的VGG model,而 top_model_weights_path 就是我们第一个训练的 h5模型,也就是 bottleneck_fc_model.h5。
from keras.applications.vgg16 import VGG16 # 载入Model 权重 + 网络 vgg_model = VGG16(weights='imagenet', include_top=False) # note that it is neccessary to start with a fully-trained classifier # including the top classifier, in order to successfully to do fine-tuning # top_model_weights_path 是上一个模型的权重 # 我们上个模型是将网络的卷积层部分,把全连接以上的部分抛掉,然后在我们自己的训练集 # 和测试集上跑一边,将得到的输出,记录下来,然后基于输出的特征,我们训练一个全连接层 top_model_weights_path = 'bottleneck_fc_model.h5' top_model.load_weights(top_model_weights_path)
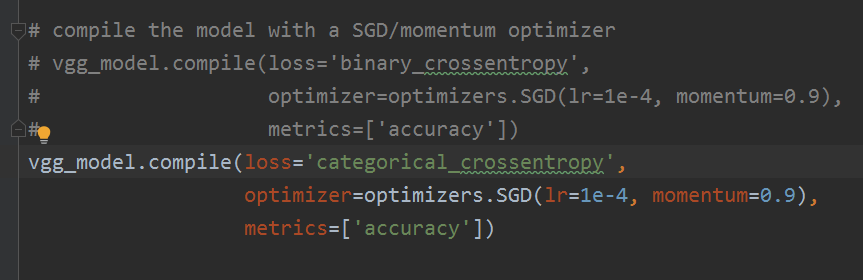
Keras的文档中做的是猫狗两分类,而我们这里做的是5分类,所以代码还是需要改,将二分类改为多分类,

编译模型的时候,如下:
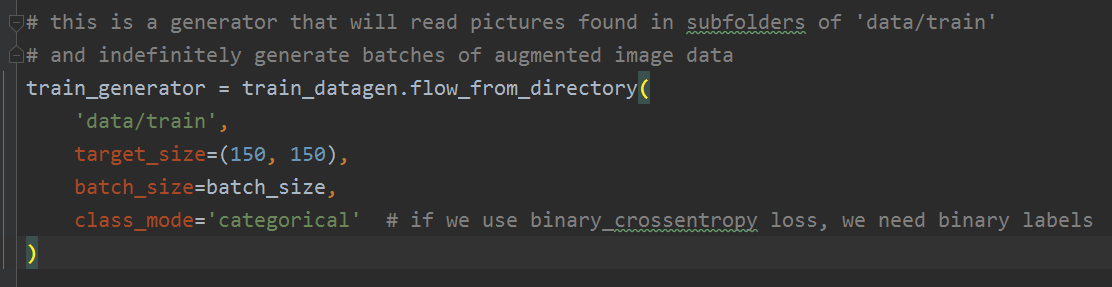
生成数据的时候,还需要修改,代码如下:
这样编译完,运行代码,会报错:
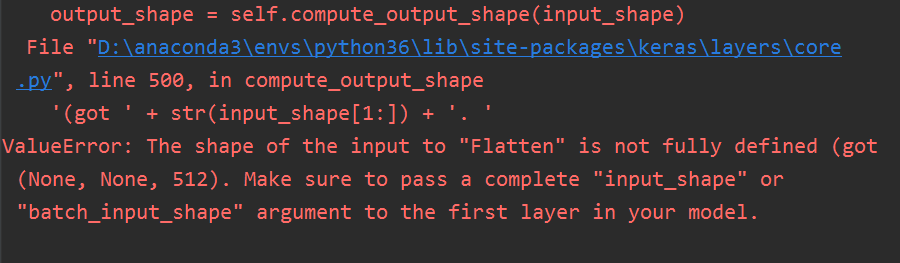
其中又遇到了Flatten() 层的问题,这是什么意思呢?网友的说法是,这一个层的意思是把 VGG16 网络结构 + 权重的model数据输出格式输入给 Flatten() 进行降维,但是 model.output 输出的格式是:(None,None,512),所以肯定会报错。
注意,这里我们这样做:
将 top_model.add(Flatten(input_shape=base_model.output_shape[1:])) 改为: vgg_model = VGG16(weights='imagenet', include_top=False, input_shape=(150, 150, 3))
这样确保了,输出的 print(vgg_model.output_shape[1:]) # (4, 4, 512)
然后会报错如下:

这是什么意思呢? 就是说VGG16原来是Model式的,而我们使用 model.add() 是 Sequential式的,所以我们不这样写,修改报错代码如下:
# add the model on top of the convolutional base
# vgg_model.add(top_model)
# 上面代码是需要将 身子 和 头 组装到一起,我们利用函数式组装即可
vgg_model = Model(inputs=base_model.input, outputs=top_model(base_model.output))
完整的代码如下:
from keras.preprocessing.image import ImageDataGenerator
from keras import optimizers
from keras.models import Sequential
from keras.layers import Dropout, Flatten, Dense
from keras.applications.vgg16 import VGG16
from keras.regularizers import l2
from keras.models import Model
def build_model():
# 构建模型
# 载入Model 权重 + 网络
base_model = VGG16(weights='imagenet', include_top=False, input_shape=(150, 150, 3))
# print(vgg_model.output_shape[1:]) # (4, 4, 512)
# 网络结构
# build a classifier model to put on top of the convolution model
top_model = Sequential()
top_model.add(Flatten(input_shape=base_model.output_shape[1:]))
# top_model.add(Dense(256, activation='relu', kernel_regularizer=l2(0.001), ))
top_model.add(Dense(256, activation='relu'))
top_model.add(Dropout(0.5))
# top_model.add(Dense(1, activation='sigmoid'))
top_model.add(Dense(5, activation='softmax'))
# note that it is neccessary to start with a fully-trained classifier
# including the top classifier, in order to successfully to do fine-tuning
# top_model_weights_path 是上一个模型的权重
# 我们上个模型是将网络的卷积层部分,把全连接以上的部分抛掉,然后在我们自己的训练集
# 和测试集上跑一边,将得到的输出,记录下来,然后基于输出的特征,我们训练一个全连接层
top_model.load_weights(top_model_weights_path)
# add the model on top of the convolutional base
# vgg_model.add(top_model)
# 上面代码是需要将 身子 和 头 组装到一起,我们利用函数式组装即可
print(base_model.input, base_model.output) # (?, 150, 150, 3) (None, 4, 4, 512)
vgg_model = Model(inputs=base_model.input, outputs=top_model(base_model.output))
# 然后将最后一个卷积块前的卷积层参数冻结
# 普通的模型需要对所有层的weights进行训练调整,但是此处我们只调整VGG16的后面几个卷积层,所以前面的卷积层要冻结起来
for layer in vgg_model.layers[: 15]: # # :25 bug 15层之前都是不需训练的
layer.trainable = False
# compile the model with a SGD/momentum optimizer
# vgg_model.compile(loss='binary_crossentropy',
# optimizer=optimizers.SGD(lr=1e-4, momentum=0.9),
# metrics=['accuracy'])
vgg_model.compile(loss='categorical_crossentropy',
optimizer=optimizers.SGD(lr=1e-4, momentum=0.9), # 使用一个非常小的lr来微调
metrics=['accuracy'])
vgg_model.summary()
return vgg_model
def generate_data():
# 然后以很低的学习率去训练
# this is the augmentation configuration we will use for training
train_datagen = ImageDataGenerator(
rescale=1. / 255, # 图片像素值为0-255,此处都乘以1/255,调整到0-1之间
shear_range=0.2, # 斜切
zoom_range=0.2, # 方法缩小范围
horizontal_flip=True # 水平翻转
)
# this is the augmentation configuration we will use for testing
test_datagen = ImageDataGenerator(rescale=1. / 255)
# this is a generator that will read pictures found in subfolders of 'data/train'
# and indefinitely generate batches of augmented image data
train_generator = train_datagen.flow_from_directory(
'data/mytrain',
target_size=(150, 150),
batch_size=batch_size,
class_mode='categorical' # if we use binary_crossentropy loss, we need binary labels
)
# this is a similar generator, for validation data
validation_generator = test_datagen.flow_from_directory(
'data/mytest',
target_size=(150, 150),
batch_size=batch_size,
class_mode='categorical'
)
# 开始用 train set 来微调模型的参数
print("start to fine-tune my model")
vgg_model.fit_generator(
train_generator,
steps_per_epoch=nb_train_samples // batch_size,
epochs=epochs,
validation_data=validation_generator,
validation_steps=nb_validation_samples // batch_size
)
# vgg_model.save_weights('vgg_try.h5')
if __name__ == '__main__':
nb_train_samples = 500
nb_validation_samples = 100
epochs = 50
batch_size = 4
top_model_weights_path = 'bottleneck_fc_model.h5'
vgg_model = build_model()
generate_data()
结果如下,效果是非常的好:
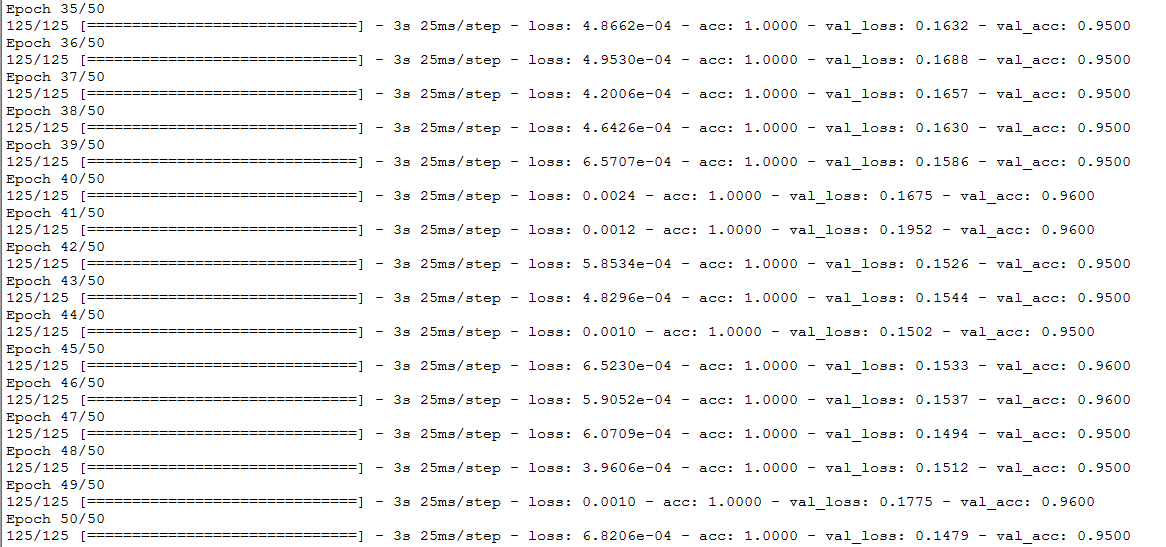
最好用服务器跑,这样快(可能说了句废话。。)。
参考文献:https://blog.csdn.net/sinat_26917383/article/details/72861152
猫狗两分类参考文献:https://blog.csdn.net/dugudaibo/article/details/78818247#commentBox
https://github.com/RayDean/DeepLearning/blob/master/FireAI_010_FineTuneMultiClass.ipynb

 浙公网安备 33010602011771号
浙公网安备 33010602011771号