
Python机器学习笔记:SVM(3)——证明SVM
完整代码及其数据,请移步小编的GitHub
传送门:请点击我
如果点击有误:https://github.com/LeBron-Jian/MachineLearningNote
说实话,凡是涉及到要证明的东西(理论),一般都不好惹。绝大多数时候,看懂一个东西不难,但证明一个东西则需要点数学功底,进一步,证明一个东西也不是特别难,难的是从零开始发明这个东西的时候,则显得艰难(因为任何时代,大部分人的研究所得都不过是基于前人的研究成果,前人所做的是开创性的工作,而这往往是最艰难最有价值的,他们被称为真正的先驱。牛顿也曾说过,他不过是站在巨人的肩上,你,我更是如此)。
正如陈希孺院士在他的著作《数理统计学简史》的第四章,最小二乘法中所讲:在科研上诸多观念的革新和突破是有着很多的不易的,或者某个定理在某个时期由有个人点破了,现在的我们看来一切都是理所当然,但在一切没有发现之前,可能许许多多的顶级学者毕其功于一役,耗尽一生,努力了几十年最终也是无功而返。
上一节我学习了SVM的核函数内容,下面继续对SVM进行证明,具体的参考链接都在第一篇文章中,SVM四篇笔记链接为:
Python机器学习笔记:SVM(1)——SVM概述
Python机器学习笔记:SVM(2)——SVM核函数
Python机器学习笔记:SVM(3)——证明SVM
Python机器学习笔记:SVM(4)——sklearn实现
话休絮烦,要证明一个东西先要弄清楚它的根基在哪里,即构成它的基础是哪些理论。OK,以下内容基本上都是上文没有学习到的一些定理的证明,包括其背后的逻辑,来源背景等东西。
本文包括内容:
- 1,线性学习器中,主要阐述感知机算法
- 2,非线性学习器中,主要阐述 Mercer定理
- 3,损失函数
- 4,最小二乘法
- 5,SMO算法的推导
同样,在学习这些之前,我们再复习一下SVM,这里使用(http://staff.ustc.edu.cn/~ketang/PPT/PRLec5.pdf)的PPT来学习。
热身:SVM的整理
这里直接借用别人的PPT粘贴在这里,让自己再梳理一遍SVM。
热身1,Hard Margin SVM

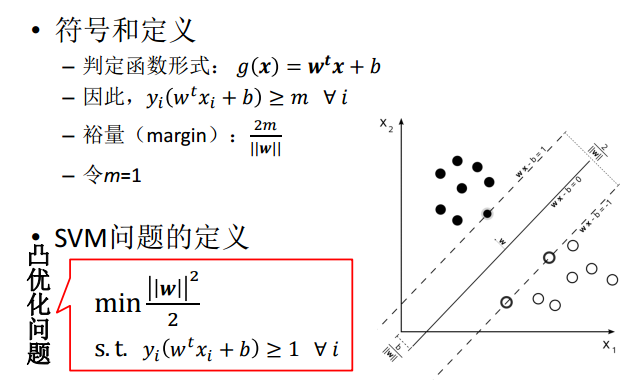




热身2,Soft Margin SVM
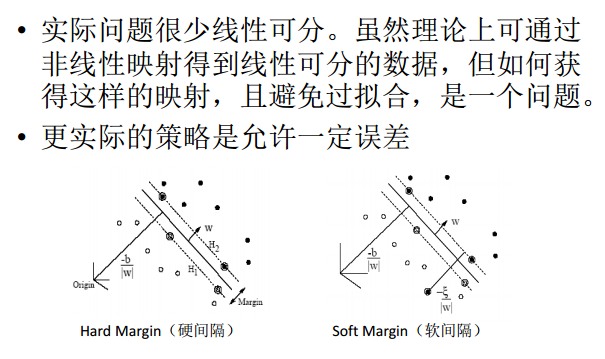


热身3,LS-SVM


1,线性学习器
1.1 感知机算法
这个感知器算法是在1956年提出的,年代久远,依然影响着当今,当然,可以肯定的是,此算法亦非最优,后续会有更详尽阐述。不过,有一点,你必须清楚,这个算法是为了干什么的:不断的训练试错以期寻找一个合适的超平面。

下面,举个例子。如下图所示,凭我们的直觉可以看出,图中红线是最优超平面,蓝线则是根据感知机算法在不断的训练中,最终,若蓝线能通过不断的训练移动到红线位置上,则代表训练成功。
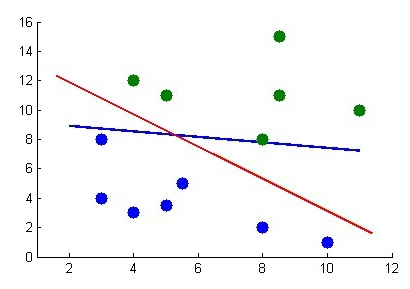
既然需要通过不断的训练以让蓝线最终成为最优分类超平面,那么到底需要训练多少次呢?
Novikoff 定理告诉我们当间隔是正的时候感知机算法会在有限次数的迭代中收敛,也就是说 Novikoff 定理证明了感知机算法的收敛性,即能得到一个界,不至于无穷循环下去。
Novikoff 定理:如果分类超平面存在,仅需要在序列 S 上迭代几次,在界为 (2R / γ)2 的错误次数下就可以找到分类超平面,算法停止。
这里的 R = max1<=i<=l||Xi|| ,γ 为扩充间隔。根据误分次数公式可知,迭代次数与对应于扩充(包括偏置)权重的训练集的间隔有关。
顺便再解释下这个所谓的扩充间隔 γ , γ 即为样本到分类间隔的距离,即从 γ 引出的最大分类间隔。之前我们推导过的内容,如下:

在给出几何间隔的定义之前,咱们首先来看下,如上图所示,对于一个点 x,令其垂直投影到超平面上的对应的为 x0,由于 w 是垂直于超平面的一个向量, γ 为样本 x 到分类间隔的距离,我们有:
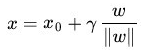
同时有一点值得注意:感知机算法虽然可以通过简单迭代对线性可分数据生成正确分类的超平面,但不是最优效果,那怎么才能得到最优效果呢,就是前面博文说的寻找最大分类间隔超平面。此外,Novikoff定理的证明请参考:http://www.cs.columbia.edu/~mcollins/courses/6998-2012/notes/perc.converge.pdf
2,非线性学习器
2.1 Mercer定理
Mercer定理:如果函数 K 是 Rn *Rn - R 上的映射(也就是从两个 n 维向量映射到实数域)。那么如果K是一个有效核函数(也称为 Mercer 核函数),那么当且仅当对于训练样例 { x(1), x(2), ... x(m)},其相应的核函数矩阵是对称半正定的。
Mercer定理表明为了证明K是有效的核函数,那么我们不用去寻找 Φ ,而只需要在训练集上求出各个 Kij,然后判断矩阵K是否是半正定(使用左上角主子式大于等于零等方法)即可。
要理解这个 Mercer定理,先要了解什么是半正定矩阵,要了解什么是半正定矩阵,先得知道什么是正定矩阵(矩阵理论博大精深,关于矩阵推荐一本书《矩阵分析与应用》),然后关于Mercer定理的证明参考:http://ftp136343.host106.web522.com/a/biancheng/matlab/2013/0120/648.html
其实,核函数在SVM的分类效果中起到了重要的作用,下面链接有个 tutorial可以看看:https://people.eecs.berkeley.edu/~bartlett/courses/281b-sp08/7.pdf
2.2 正定矩阵
在百度百科,正定矩阵的定义如下:在线性代数里,正定矩阵(positive definite materix)有时会简称为正定阵。在线性代数中,正定矩阵的性质类似于复数中的正实数。与正定矩阵相对应的线性算子是对称的正定双线性形式。
广义的定义:设 M 为 n 阶方阵,如果对任何非零向量 z,都有 zTMz > 0,其中 zT 表示 z 的转置,就称 M 为正定矩阵。
狭义的定义:一个 n 阶的实对称矩阵 M 是正定的条件是当且仅当对所有的非零实系数向量 z,都有 zTMz > 0,其中 zT 表示 z 的转置。
正定矩阵的性质:
- 1,正定矩阵的行列式恒为正
- 2,实对称矩阵 A 正定当且仅当 A 与单位矩阵合同
- 3,若 A 是正定矩阵,则 A 的逆矩阵也是正定矩阵
- 4,两个正定矩阵的和是正定矩阵
- 5,正实数域正定矩阵的乘积是正定矩阵
3,损失函数
之前提到过“支持向量机(SVM)是 90 年代中期发展起来的基于统计学习理论的一种机器学习方法,通过寻找结构化风险最小来提高学习机泛化能力,实现经验风险和置信范围的最小化,从而达到在统计样本量较少的情况下,亦能获得良好统计规律的目的。”但初次看到的人可能不了解什么是结构化风险,什么又是经验风险。要了解这两个所谓的“风险”,还得从监督学习说起。
监督学习实际上就是一个经验风险或者结构风险函数的最优化问题。风险函数度量平均意义下模型预测的好坏,模型每一次预测的好坏用损失函数来度量。它从假设空间 F 中选择模型 f 作为决策函数,对于给定的输入 X,由 f(x) 给出相应的输出 Y,这个输出的预测值 f(X)与真实值 Y 可能一致也可能不一致,用一个损失函数来度量预测错误的程度。损失函数记为 L(Y, f(X))。
常用损失函数有以下几种(摘抄于《统计学习方法》):
(1) 0-1 损失函数
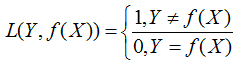
(2)平方损失函数
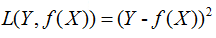
(3)绝对损失函数
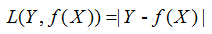
(4)对数损失函数
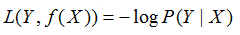
给定一个训练数据集
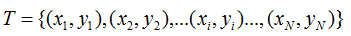
模型 f(X) 关于训练数据集的平均损失称为经验风险,如下:

关于如何选择模型,监督学习有两种策略:经验风险最小化和结构风险最小化。
经验风险最小化的策略认为,经验风险最小的模型就是最优的模型,则按照经验风险最小化求最优模型就是求解如下的最优化问题:
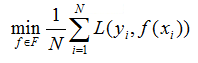
当样本容量很小时,经验风险最小化的策略容易产生过拟合的现象。结构风险最小化可以防止过拟合。结构风险是在经验风险的基础上加上表示模型复杂度的正则化项或惩罚项,结构风险定义如下:
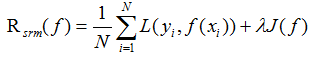
其中 J(f) 为模型的复杂度,模型 f 越复杂,J(f) 值就越大,模型越简单,J(f) 值就越小,也就是说J(f)是对复杂模型的乘法。λ>=0 是系数,用以衡量经验风险和模型复杂度。结构风险最小化的策略认为结构风险最小的模型是最优的模型,所以求最优的模型就是求解下面的最优化问题:
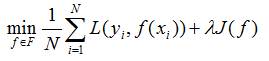
这样,简单学习问题就变成了经验风险或结构化风险函数的最优化问题。如上式最优化问题的转换。
这样一来,SVM就有第二种理解,即最优化+损失最小。如网友所言:“可以从损失函数和优化算法角度看SVM,Boosting,LR等算法,可能会有不同收获”。
关于损失函数:可以看看张潼的这篇《Statistical behavior and consistency of classification methods based on convex risk minimization》。各种算法中常用的损失函数基本都具有fisher一致性,优化这些损失函数得到的分类器可以看作是后验概率的“代理”。此外,张潼还有另外一篇论文《Statistical analysis of some multi-category large margin classification methods》,在多分类情况下margin loss的分析,这两篇对Boosting和SVM使用的损失函数分析的很透彻。
关于统计学习方法的问题,可以参考:https://people.eecs.berkeley.edu/~bartlett/courses/281b-sp08/7.pdf
4,最小二乘法
4.1 什么是最小二乘法?
下面引用《正态分布的前世今生》里的内容稍微简单阐述一下。
我们口头经常经常说:一般来说,平均来说。如平均来说,不吸烟的健康优于吸烟者,之所有要加“平均” 二字,是因为凡是皆有例外,总存在某个特别的人他吸烟但由于经常锻炼所以他的健康状况可能会优于他身边不吸烟的盆友。而最小二乘的一个最简单例子便是算术平均。
最小二乘法(又称最小平方法)是一种数学优化技术。它通过最小化误差的平方和寻找数据的最佳函数匹配。利用最小二乘法可以简便的求得未知的数据,并使得这些求得的数据与实际数据之间误差的平方和为最小。用函数表示为:
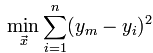
使误差(所谓误差,当然是观察值与实际真实值的差量)平方和达到最小以寻求估计值的方法,就叫做最小二乘法,用最小二乘法得到的估计,叫做最小二乘估计。当然,取平方和作为目标函数只是众多可取的方法之一。
最小二乘法的一般形式可表示为:
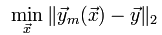
有效的最小二乘法是勒让得在1805年发表的,基本思想就是认为测量中有误差,所以所有方程的累积误差为:

我们求解出导致累积误差最小的参数即可:
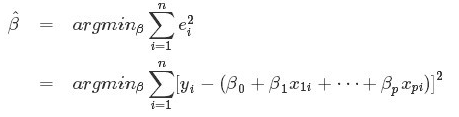
勒让得在论文中对最小二乘法的优良性做了几点说明:
- 最小二乘的误差平方和最小,并在各个方程的误差之间建立了一种平衡,从而防止某个极端误差取得支配地位。
- 计算中只需要求偏导后求解线性方程组,计算过程明确便捷
- 最小二乘可以导出算术平均值作为估计
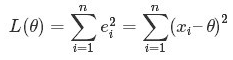
对于最后一点,从统计学的角度来看是很重要的一个性质。推理如下:假设真值为 Θ ,x1,.....xn 为 n 次测量值,每次测量的误差为 ei = xi - Θ,按最小二乘法,误差累积为:
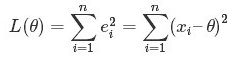
求解 Θ 使 L(Θ) 达到最小,正好是算术平均 xhat,其公式如下:
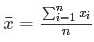
由于算术平均是一个历经考验的方法,而以上的推理说明,算术平均是最小二乘的一个特例,所以从另外一个角度说明了最小二乘方法的优良性,使我们对最小二乘法更加有信息。
最小二乘法发布之后很快得到了大家的认可接受,并迅速的在数据分析实践中被广泛使用。不过历史上又有人把最小二乘法的发明归功于高斯,这又是怎么一回事呢?高斯在 1809 年也发表了最小二乘法,并且声称自己已经使用了这个方法多年。高斯发明了小行星定位的数学方法,并在数据分析中使用最小二乘方法进行计算,准确的预测了谷神星的位置。
说了这么多,貌似与SVM没啥关系,但是别着急,请继续听,本质上说,最小二乘法即是一种参数估计方法,说到参数估计,咱们从一元线性模型说起。
4.2 最小二乘法的解法
什么是一元线性模型呢?我们引用(https://blog.csdn.net/qll125596718/article/details/8248249)的内容,先来梳理一下几个基本的概念:
- 监督学习中,如果预测的变量是离散的,我们称其为分类(如决策树,支持向量机等),如果预测的变量是连续的,我们称其为回归。
- 回归分析中,如果只包括一个自变量和一个因变量,且二者的关系可用一条直线近似表示,这种回归分析称为一元线性回归分析。
- 如果回归分析中包括两个或两个以上的自变量,且因变量和自变量之间是线性关系,则称为多元线性回归分析。
- 对于二维空间线性是一条直线;对于三维空间线性是一个平面,对于多维空间线性是一个超平面。
对于一元线性回归模型,假设从总体中获取了 n 组观察值(X1, Y1),(X2, Y2),...(Xn, Yn)。对于平面中的这 n 个点,可以使用无数条曲线来拟合。要求样本回归函数尽可能好的拟合这组值。综合起来看,这条直线处于样本数据的中心位置最合理。
选择最佳拟合曲线的标准可以确定为:使总的拟合误差(即总残差)达到最小,有以下三个标准可以选择:
- 1,用“残差和最小”确定直线位置是一个途径。但是很快发现计算“残差和” 存在相互抵消的问题。
- 2,用“残差绝对值和最小”确定直线位置也是一个途径。但绝对值的计算比较麻烦。
- 3,最小二乘法的原则是以“残差平方和最小” 确定直线位置。用最小二乘法除了计算比较方便外,得到的估计量还具有优良特性。这种方法对异常值非常敏感。
最常用的是普通最小二乘法(Ordinary Least Square, OLS ):所选择的回归模型应该使所有观察值的残差平方和达到最小,即采用平方损失函数。
我们定义样本回归模型为:
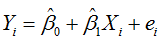
得到误差 ei (ei为样本)为:

接着,定义平方损失函数 Q:
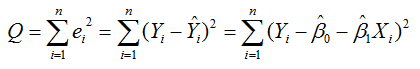
则通过Q最小确定这条直线,即确定 β0hat, β1hat, β0hat, β1hat为变量,把它们看做是 Q 的函数,就变成了一个求极值的问题,可以通过求导数得到。
求 Q 对两个待估参数的偏导数:
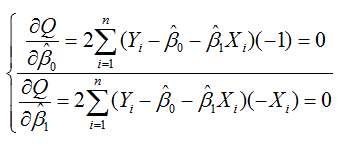
根据数学知识我们知道,函数的极值点为偏导为 0 的点,解得:

这就是最小二乘法的解法,就是求得平方损失函数的极值点。自此,我们可以看到求解最小二乘法和求解SVM是何等相似,尤其是定义损失函数,而后通过偏导求极值。
5,SMO算法
无论Hard Margin 或 Soft Margin SVM,我们均给出了SVM的对偶问题,但并没有说明对偶问题怎么求解。由于矩阵Q的规模和样本数相等,当训练样本数很大的时候,这个矩阵的规模很大,求解二次规划问题的经典算法会遇到性能问题,也就是说同时求解 n 个拉格朗日乘子涉及很多次迭代,计算开销太大,所以一般采用 Sequential Minimal Optimization(SMO)算法。
SMO算法的基本思想:每次只更新两个乘子,迭代获得最终解。
上文中,我们提到了求解对偶问题的序列最小最优化 SMO 算法,但并未提到其具体解法。首先看下最后悬而未决的问题:
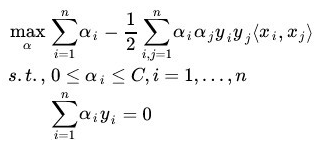
等价于求解:
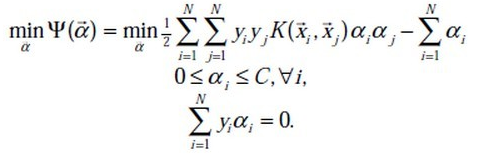
1998年,Microsoft Research 的John C. Platt 在论文《Sequential Minimal Optimization:A Fast Alogrithm for Training Support Vector Machines》中提出针对上述问题的解法:SMO算法,它很快便成为最快的二次规划优化算法,特别是针对线性SVM和数据稀疏时性能更优。这个算法的思路是每次在优化变量中挑出两个分量进行优化,而让其他分量固定,这样才能保证满足等式约束条件,这是一种分治法的思想。
接下来,我们便参考 John C.Platt 的文章(找不到了。。。)来看看 SMO的解法。
5.1 SMO算法的推导

首先我们来定义特征到结果的输出函数:
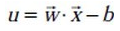
注:这个 u 与我们之前定义的 f(x) 实质上是一样的。
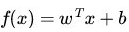
接着,重新定义下我们原始的优化问题,权当重新回顾,如下:

求导得到:
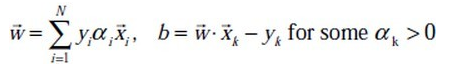
代入 u 的公式中,可得:
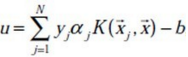
通过引入拉格朗日乘子转换为对偶问题后,得:
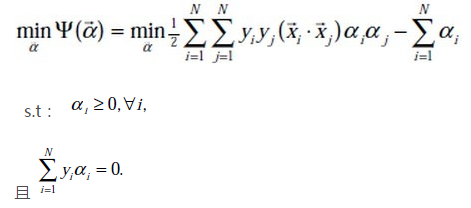
注:这里得到的 min 函数与我们之前的 max 函数实质上也是一样,因为把符号变下,即由 min 转换为 max 的问题,且 yi也与之前的 y(i) 等价,yj 亦如此。
经过加入松弛变量后,模型修改为:

从而最终我们的问题变为:
下面要解决的问题是:在 αi = { α1, α2, α3,......, αn} 上求上述目标函数的最小值。为了求解这些乘子,每次从中任意抽取两个乘子 α1 和 α2,然后固定 α1 和 α2 以外的乘子 {α3, α4,....αn},使得目标函数只是关于 α1 和 α2 的函数。这样,不断的从一堆乘子中任意抽取两个求解,不断地迭代求解子问题,最终达到求解原问题的目的。
(注意:下面均使用两个相同的表达式,是参考了两个方法,并且这两个方法均易于理解,可以说我先看第一个公式的文章,然后偶尔有次看到第二个公式的文章,发现也很好理解,所以粘贴在这里,特地说明)
我们首先给出对于这两个常量的优化问题(称为子问题)的求解方法。假设选取的两个分量为 αi, αj,其他分量都固定(即当做常数)。由于:
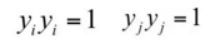
所以对偶问题的子问题的目标函数可以表达为:
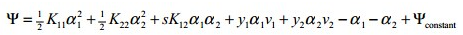
(更普及一点,可以写成下面这样)

其中C是一个常数,前面的二次项很容易计算出来,一次项要复杂一些,并且:

这里的变量 α* 为变量 a 在上一轮迭代后的值。上面的目标函数是一个两变量的二次函数,我们可以直接给出最小值的解析解(公式解)。
为了解决这个子问题,首要问题便是每次如何选取 α1 和 α2。实际上,其中一个乘子是违反 KKT条件最严重的,另外一个乘子则由另一个约束条件选取。
根据KKT条件可以得到目标函数中 αi 取值的意义:
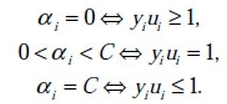
这里的 αi 还是拉格朗日乘子:
- 1,对于第一种情况,表明 αi 是正常分类,在间隔边界内部(我们知道正确分类的点 yi * f(xi) >= 0)
- 2,对于第二种情况,表明了 αi 是支持向量,在间隔边界上
- 3,对于第三种情况,表明了 αi 是在两条间隔边界之间
而最优解需要满足KKT 条件,即上述三个条件都得满足,以下几种情况出现将会出现不满足:
- 1,yiui <=1,但是 αi < C 则不是不满足的,而原本 αi = C
- 2,yiui >=1,但是 αi > C 则不是不满足的,而原本 αi = C
- 3,yiui =1,但是 αi = 0 或者 αi = C 则不是不满足的,而原本 0 < αi < C
也就是说,如果存在不满足 KKT 条件的 αi ,那么需要更新这些 αi ,这是第一个约束条件。此外,更新的同时还要受到第二个约束条件的限制,即:
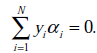
因此,如果假设选择的两个乘子 α1 和 α2 ,他们在更新之前分别是 α1old 和 α2old,更新之后分别是 α1new 和 α2new,那么更新前后的值需要满足以下等式才能保证和为 0 的约束:
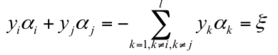
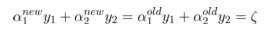
其中,ξ 是常数,(上面两个式子都一样,只不过第二个更容易理解)。
两个因子不好同时求解,所以可选求第二个乘子 α2 的解(α2new),得到 α2 的解(α2new)之后,再利用 α2 的解(α2new)表示 α1 的解(α1new).
为了求解 α2 的解(α2new),得先确定 α2new 的取值范围。假设它的上下边界分别为 H 和 L,那么有:

接下来,综合下面两个约束条件,求解 α2new 的取值范围:
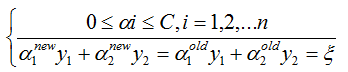
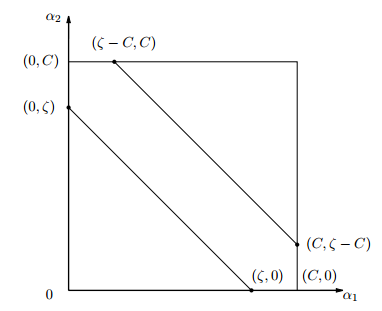
由于 yi, yj(也可以说为 y1 y2)的取值只能为 +1 或者 -1,那么当他们异号,也就是当 y1 != y2 时,根据:
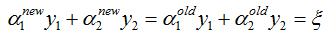
可得: α1old - α2old = ξ ( αi - αj = ξ),它确定的可行域是一条斜率为1的直线段,因为αi αj 要满足约束条件
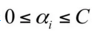
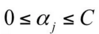
他们的可行域如下图所示:
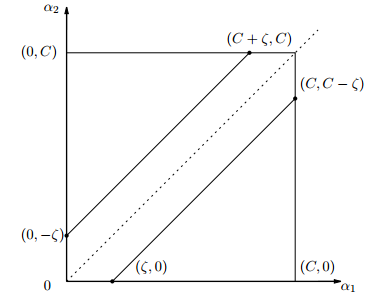

上面两条直线分别对应于 y1为 +1 和 -1 的情况。如果是上面那条直线,则 αj 的取值范围为 [-ξ, C]。如果是下面的那条直线,则为 [0,C-ξ]。
对于这两种情况 αj 的下界和上界可以统一写成如下形式:

因为 αi - αj = ξ ,所以又可以写为: L = max (0, -ξ), H = min(C, C-ξ)
下边界是直线和 x 轴交点的 x 坐标以及 0 的较大值;上边界是直线和的交点的 x 坐标和 C 的较小值。
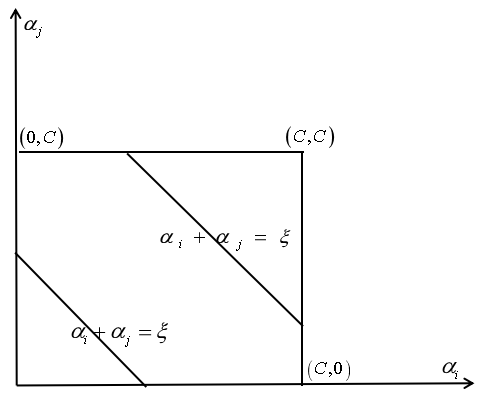
再来看第二种情况,如果 yi yj 同号,即当 y1 = y2 时,同样根据:
可得: α1old + α2old = ξ ( αi + αj = ξ ),所以有:
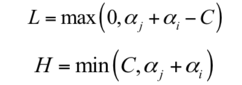
根据 αi + αj = ξ , 上式也可写为:L = max (0, ξ - C), H = min(C, ξ)
这种情况如下图所示:
如此,根据这两个变量的等式约束条件( y1 和 y2 异号或者同号),可以消掉α2old ,可得出 α2new 的上下界分别为:
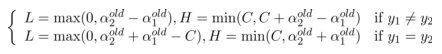
回顾下第二个约束条件:
下面我们来计算不考虑截断时的函数极值。为了避免分 -1 和 +1 两种情况,我们将上面的等式约束两边同时乘以 y1(第二种表达是乘以yi),可得:


其中 α1 可以用 α2 表示,α1 = w - s*α2,从而我们把子问题的目标函数转换为只含 α2 的问题:
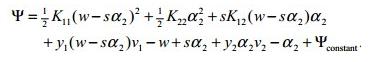
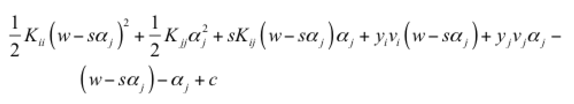
对 α2 求导(即对自变量求导),并令导数为零,可得:

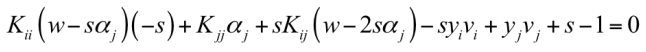
由于:
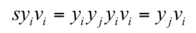
化简下:
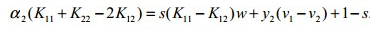

然后将: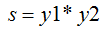
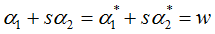
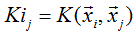
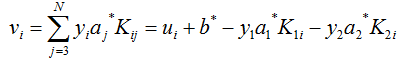
代入上式,可得:
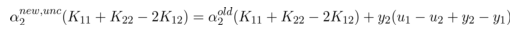
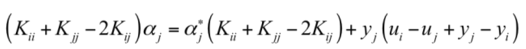
下面令(其中 Ei 表示预测值与真实值之差):
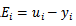
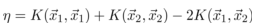
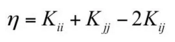
然后上式两边同时除以 η ,得到一个关于单变量 α2 的解:
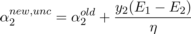
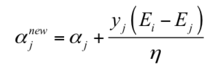
在求得 αj 之后,根据等式约束条件我们就可以求得另外一个变量的值:
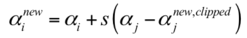
目标函数的二阶导数为 η,前面假设二阶导数 η > 0,从而保证目标函数是凸函数即开口向上的抛物线,有极小值。如果 η < 0 或者 η = 0,该怎么处理?对于线性核或正定核函数,可以证明矩阵K的任意一个上述子问题对应的二阶子矩阵半正定,因此必定有 η >= 0。无论本次迭代时的初始值是多少,通过上面的子问题求解算法得到是在可行域里的最小值,因此每次求解更新这两个变量的值之后,都能保证目标函数值小于或者等于初始值,即函数值下降。
这个解没有考虑其约束条件 0 <= α2 <= C,即是未经剪辑时的解。
然后考虑约束 0 <= α2 <= C 可得到经过剪辑后的 α2new 的解析解为:
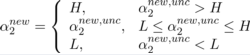
(如果用αi,αj表示,则我们求的这个二次函数的最终极值点为:)

求出了 α2new后,便可以求出α1new ,得:

这三种情况下的二次函数极小值如下图所示:
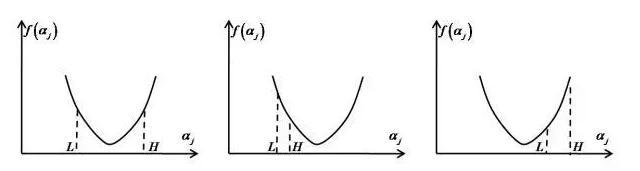
上图中第一种情况是抛物线的最小值点在 [L, H]中;第二种情况是抛物线的最小值点大于 H,被截断为H;第三种情况是小于L,被截断为L。
那么如何选择乘子 α1 和 α2呢?
- 对于 α1 ,即第一个乘子,可以通过刚刚说的那3种不满足 KKT的条件来找
- 而对于第二个乘子 α2 可以寻找满足条件: max |Ei - Ej| 的乘子
而 b 满足下述条件:
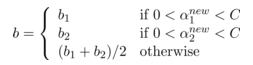
下面更新 b:

且每次更新完两个乘子的优化后,都需要再重新计算 b,及对应的 Ei值。
最后更新所有的 αi,y 和 b,这样模型就出来了,从而即可求出咱们开头提出的分类函数:
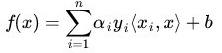
此外,这里有一篇类似的文章,大家可以参考下(https://www.cnblogs.com/jerrylead/archive/2011/03/18/1988419.html)。
5.2 SMO算法的步骤

综上,总结下SMO的主要步骤,如下:

意思是:
- 1,第一步:选取一对 αi 和 αj,选取方法使用启发式方法
- 2,第二步:固定除αi 和 αj 之外的其他参数,确定W 极值条件下的 αi 和 αj 由 αi 表示
假定在某一次迭代中,需要更新 x1,x2 对应的拉格朗日乘子 α1,α2,那么这个小规模的二次规划问题写为:
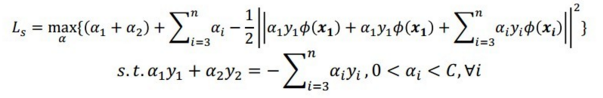
那么在每次迭代中,如何更新乘子呢?引用下面地址(http://staff.ustc.edu.cn/~ketang/PPT/PRLec5.pdf)的两张PPT说明下:

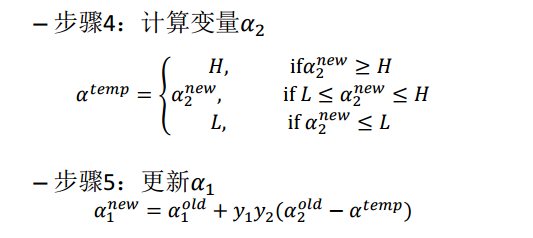
知道了如何更新乘子,那么选取哪些乘子进行更新呢?具体有以下两个步骤:
- 步骤一:先“扫描”所有乘子,把第一个违反KKT条件的作为更新对象,令为 a1
- 步骤二:在所有不违反KKT条件的乘子中,选择使 |E1 - E2|最大的 a2 进行更新,使得能最大限度增大目标函数的值(类似于梯度下降,此外 Ei = ui - yi,而 u = w*x - b ,求出来的 E 代表函数 ui 对输入 xi 的预测值与真实输出类标记 yi 之差)
最后,每次更细完两个乘子的优化后,都需要再重新计算 b,及对应的 Ei 值。

综上,SMO算法的基本思想是把 Vapnik 在 1982年提出的 Chunking方法推到极致,SMO算法每次迭代只选出两个分量 ai 和 aj 进行调整,其他分量则保持固定不变,在得到 解 ai 和 aj 之后,再用 ai 和 aj 改进其他分量。与通常的分解算法比较,尽管它可能需要更多的迭代次数,但每次迭代的计算量比较小,所以该算法表现出较好的快速收敛性,且不需要存储核函数,也没有矩阵运算。
5.3 SMO算法的实现
行文至此,我相信,SVM理解到了一定程度后,是的确能在脑海里从头到尾推导出相关公式的,最初分类函数,最大化分类间隔,max1/||w||,min1/2||w||^2,凸二次规划,拉格朗日函数,转化为对偶问题,SMO算法,都为寻找一个最优解,一个最优分类平面。一步步梳理下来,为什么这样那样,太多东西可以追究,最后实现。
至于上文中将阐述的核函数则是为了更好的处理非线性可分的情况,而松弛变量则是为了纠正或约束少量“不安分”或脱离集体不好归类的因子。
台湾的林智仁教授写了一个封装SVM算法的libsvm库,大家可以看看,此外这里还有一份libsvm的注释文档。在这篇论文《fast training of support vector machines using sequential minimal optimization》中platt给出了SMO算法的逻辑代码。
5.4 SMO算法的优缺点
优点:
- 可保证解的全局最优解,不存在陷入局部极小值的问题
- 分类器复杂度由支撑向量的个数,而非特征空间(或核函数)的维数决定,因此较少因维数灾难发生过拟合线性
缺点:
- 需要求解二次规划问题,其规模与训练模式量成正比,因此计算复杂度高,且存储开销大,不适用于需进行在线学习/训练的大规模分类问题
这篇文章主要参考:https://mp.weixin.qq.com/s/ZFWJUazMbAqeoSIkXjuG5g

 浙公网安备 33010602011771号
浙公网安备 33010602011771号