
深入学习sequoiadb巨杉数据库及python连接方式
随着公司日益复杂与多变的需求,以及迅速扩展带来的海量数据业务,我们需要在提供高效服务的同时,降低其设备与程序维护成本。算了,不吹了,说白了就是需要从巨杉数据库中抓取大量的数据,但是我现在不会,所以需要好好学习一下。顺便在此做个笔记,以备不时之需。
这里,我从了解巨杉数据库的基础,历史,性能,部署等方面开始学习。
据在网上粗略的了解,BAT等巨头内部基本都有自己的NoSQL项目,有的是基于开源项目自行研发,有的是依托MongoDB等NoSQL为基础搭建数据分析平台。而近些年迅速成长的各类公有云服务提供商,在除了SQL Server,MySQL,MariaDB等关系数据库之外,也在开始尝试部署的NoSQL(当然,这些NoSQL数据库是以MongoDB为主)。
BAT等大互联网公司,财大气粗,大都养着一群程序员基于开源数据库做改进,使之更适合他们自己的业务,因此,很少这类产品发布。
值得庆幸的是,国内也有NoSQL研发商。广州巨杉发布的的企业级NoSQL:SequoiaDB,号称在功能和研发技术方面,并不输MongoDB。SequoiaDB之前名字还是很陌生的,但是近几个年来,经常在各类大数据主题的大会,论坛等场合出现,而且在近期宣布获得千万级美元的A轮,同时在ArchSummit峰会上宣布开源,声名鹊起。
广州巨杉软件对其产品SequoiaDB的简介是:SequoiaDB(巨杉数据库)是一款分布式文档型NoSQL数据库,是业界唯一支持事务和SQL的产品。SequoiaDB既可作为Hadoop与Spark的数据源以满足实时查询和分析的混合负载,也可独立作为高性能、灵活易用的数据库被应用程序直接使用。SequoiaDB已拥有的客户包括知名IT互联网公司和世界五百强企业。
一,python环境搭建
1.1 安装和部署一个集群环境(此步骤并未执行,小编使用的都是部署好的)
进入终端,切入到存放SequoiaDB的目录,我的目录是home(~)目录。
SequoiaDB的安装包下载下来,是一个tar.gz的压缩包,需要先解压:
tar -zxvf sequoiadb-1.10-linux_x86_64-installer.tar.gz
该命令会把压缩包解压到当前目录。
执行解压出来的run包:
sudo ./sequoiadb-1.10-linux_x86_64-installer.run
此shell命令会执行SequoiadbDB的安装,如果是桌面环境,默认会以图形向导的方式安装,如果需要用字符安装向导,可以用下面的命令来执行安装:
sudo ./sequoiadb-1.10-linux_x86_64-installer.run --mode text --SMS false
我采用的是字符向导安装,依次会经过
- 语言选择,有 English 和 中文 供选择,我选择是English;
- 用户许可协议声明,如有疑问开源选择2,查看协议的具体内容;
- 确认许可,选择 y;
- 安装目录,默认是 /opt/sequoiadb;(不包括“;”)
- 创建数据库管理员账户:用户名,默认是sdbadmin;密码,默认为sdbadmin,如果你需要自己设定数据库管理员用户名和密码,可以在对应的输入提示处输入;
- 集群管理服务端口,默认是11790;
- 开机自启动,我选择的是 Y,确认开机自启动;
- OM Server安装等确认,我选择的是 y,确认安装;
最后就是继续安装确认,必须选择 Y哈,确认之后会出现一下字符:
lease wait while Setup installs SequoiaDB Server on your computer. Installing 0% ______________ 50% ______________ 100% ###########################
此时耐心等待其安装即可,当安装完成,会自动切入Shell输入状态。
再次确认一下:安装过程中,安装程序会创建一个数据库管理员的系统用户,用户数据库的管理和部署。
到此处,数据库正确安装了 :)
安装完成后,先检查数据库服务状态,在shell中执行 service sdbcm status
正确情况下,应该出现的是 sdbcmd进程号,和 sdbcm is running. 的提示:
tynia@Milky:~$ service sdbcm status 4991 sdbcm is running.
如果sdbcm服务并没有启动,可以手动执行 service sdbcm start 来启动sdbcm服务。
如果仍然失败,请检查一下安装过程是否出错。
sdbcm服务状态正确的话,就可以继续部署了。
(以上操作是参考此博客,部署的具体操作,请参考网友博客:https://www.cnblogs.com/tynia/p/sequoiadb01.html)
1.2 安装sequoiadb的驱动
我其实很不解的是为什么我下载巨杉数据库的驱动,还要我注册,输入个人信息等。算了,寄人篱下,就这样吧,下载链接地址如下 http://download.sequoiadb.com/cn/index-cat_id-2#
本人使用的编译语言是python,所以下载的是python驱动,请看下图(注意是Linux):

对于Windows,暂未推出驱动开发包,好惨,,,,,
1.3 数据库操作
数据库连接(connecting)
import pysequoiadb
from pysequoiadb import client
# connect to local db, using default args value.
host = 'loaclhost'
port = 11810
# user = '', password = ''
db = client(host,port)
# if no error occurs, connect to specified server successfully
print('Connect success')
db.disconnect()
(此教程是巨杉数据库官方文档)本例程连接到本地数据库的服务端口11810,使用的是空的用户名和密码。用户需要根据自己的实际情况配置参数。譬如,将上述代码中的 db = client() 修改为 db = client('192.168.10.188', 11810)。当数据库已经创建用户时,应该使用正确的用户及密码连接到数据库,否则连接失败。
创建集合空间和集合
以下创建了一个名字为“foo”的集合空间和一个名字为“bar”的集合,集合空间内的集合的数据页大小为16k。可根据实际情况选择不同大小的数据页。创建集合后,可对集合做增删改查等操作。
# connect to db
db = client("localhost", 11810)
# create collection space
cs_name = 'foo'
cs = db.create_collection_space(cs_name)
cl_name = 'bar'
cl = cs.create_collection(cl_name)
插入数据(insert)
# creat dict object
record = {"name":"Tom", "age":24}
oid = cl.insert ( record ) ;
record为输入参数,为要插入的数据。dict对象将会被转换成bson插入到集合中。oid 是插入该记录时,返回的bson结构的objectid。
查询(query)
import pysequoiadb
from pysequoiadb import client
from pysequoiadb.error import SDBEndOfCursor
cr = cl.query()
while True:
try:
record = cr.next()
print(record)
except SDBEndOfCursor:
break
finally:
cr.close()
查询操作需要一个游标对象存放查询的结果到本地。要获得查询的结果需要使用游标操作。本例使用了游标操作的next接口,表示从查询结果中取到一条记录。此示例中没有设置查询条件,筛选条件,排序情况,及仅使用默认索引。
索引(index)
index_name = "index_name"
idx = OrderedDict([('name', 1), ('age', -1)])
cl.create_index ( idx, index_name, False, False ) ;
集合对象collection中创建一个以“name”为升序,“age”为降序的索引。
更新(update)
rule = {"$set":{ "age":19}}
print rule
cl.update( rule )
在集合对象 ollection中更新了记录。实例中没有指定数据匹配规则,所以此示例将更新集合中所有的集合。
1.4 SQL to SequoiaDB shell to Python
SequoiaDB 的查询用 dict(bson)对象表示,下表以例子的形式显示了 SQL 语句。SequoiaDB shell 语句和 SequoiaDB Python 驱动程序语法之间的对照。
| SQL | SequoiaDB shell | Python Driver |
|---|---|---|
| insert into bar(a,b) values(1,-1) | db.foo.bar.insert({a:1,b:-1}) | cl = db.get_collection("foo.bar") obj = { "a":1, "b":-1 } cl.insert( obj ) |
| select a,b from bar | db.foo.bar.find(null,{a:"",b:""}) | cl = db.get_collection("foo.bar") selected = { "a":"","b":"" } cr = cl.query(selector = selected ) |
| select * from bar | db.foo.bar.find() | cl = db.get_collection("foo.bar") cr = cl.query () |
| select * from bar where age=20 | db.foo.bar.find({age:20}) | cl = db.get_collection("foo.bar") cond ={"age":20} cr = cl.query ( condition = cond ) |
| select * from bar where age=20 order by name | db.foo.bar.find({age:20}).sort({name:1}) | cl = db.get_collection("foo.bar") cond ={"age":20} orderBy = {"name":1} cr = cl.query (condition=cond , order_by=orderBy) |
| select * from bar where age > 20 and age < 30 | db.foo.bar.find({age:{$gt:20,$lt:30}}) | cl = db.get_collection("foo.bar") cond = {"age":{"$gt":20,"$lt":30}} cr = cl.query (condition = cond ) |
| create index testIndex on bar(name) | db.foo.bar.createIndex("testIndex",{name:1},false) | cl = db.get_collection("foo.bar") obj = { "name":1 } cl.create_index ( obj, "testIndex", False, False ) |
| select * from bar limit 20 offset 10 | db.foo.bar.find().limit(20).skip(10) | cl = db.get_collection("foo.bar") cr = cl.query (num_to_skip=10L, num_to_return=20L ) |
| select count(*) from bar where age > 20 | db.foo.bar.find({age:{$gt:20}}).count() | cl = db.get_collection("foo.bar") count = 0L condition = { "age":{"$gt":20}} count = cl.get_count (condition ) |
| update bar set a=2 where b=-1 | db.foo.bar.update({$set:{a:2}},{b:-1}) | cl = db.get_collection("foo.bar") condition = { "b":1 } rule = { "$set":{"a":2} } cl.update ( rule, condition=condition ) |
| delete from bar where a=1 | db.foo.bar.remove({a:1}) | cl = db.get_collection("foo.bar") condition = {"a":1} cl.delete ( condition=condition ) |
1.5 Python API
1 collection 类添加接口
alter,对集合的属性进行修改 enable_sharding,对集合启用分区功能 disable_sharding,对集合关闭分区功能 enable_compression,对集合启用压缩功能 disable_compression,对集合关闭压缩功能 set_attributes,对集合的属性进行修改
2 collectionspace 类添加接口
alter,对集合空间的属性进行修改 set_attributes,对集合空间的属性进行修改 set_domain,修改集合空间所属的域 remove_domain,移除集合空间所属的域
3 domain 类添加接口
add_groups,向域中添加数据组 set_groups,对域设置数据组 remove_groups,移除属于域的某些数据组 set_attributes,设置域的属性
具体请参考:http://doc.sequoiadb.com/cn/index/Public/Home/document/300/api/python/html/index.html
二:初步了解SequoiaDB数据库
(此小节说明数据的内容是参考网上博客https://blog.csdn.net/sequoiadb/article/details/12106133)
SequoiaDB作为全球第一家企业级文档式非关系型数据库,则提供了诸如此类(高可扩展 性、高可用性、高性能、易维护、低成本)的全方位平台。下面从其特点、数据模型、系统架构等三个方面来了解SequoiaDB。
2.1 SequoiaDB特点
1、当传统的关系型数据库无法做到水平扩张能力时,在SequoiaDB中会得到完美的解决,通过对数据进行垂直切片,并应用了新型的非关系型数据模型,SequoiaDB有效地降低了传统数据库分区中大量数据交换的瓶颈,进而得到线性水平扩张能力。
2、SequoiaDB能够将用户的每一份数据实时保存多份副本,有效地防止了因服务器、机房及人为等因素所造成的系统停机带来的损失,确保随时在线可用。
3、SequoiaDB为企业提供了用户友好并完善的管理、维护及监控界面,实现24×7的电话及现场技术支持,拥有完善的企业级支持。
4、SequoiaDB使用JSON数据模型,灵活有效地降低关系模型的复杂性,让数据库更加贴近应用程序,从而大大降低应用程序的开发和维护成本。
5、SequoiaDB在大规模分布式环境中提供了数据最终一致性的保障,满足用户对实时性与一致性的需求。
6、SequoiaDB通过分片机制进行读写分离,允许前端在线应用与后台数据分析完美并行互不干扰,并可结合Hadoop技术进行海量数据分析。
2.2 SequoiaDB数据模型
SequoiaDB数据库没有使用传统的关系型数据模型,而是JSON数据模型。JSON数据结构的全称为Javascript Object Notation,是一种轻量级的数据交换格式,非常易于人阅读和编写,同时也易于机器生成与解析,为纯文本格式,支持嵌套结构与数组。
2.3 JSON建构基于两种结构:
1、键值对集合。在键值对集合结构中,每一个数据元素拥有一个名称与一个数值,数值可以包含数字,字符串等常用结构,或嵌套JSON对象和数组。
2、数组。在数组中的每一个元素不包含元素名,其值可以为数字、字符串等常用结构,或者嵌套JOSN对象和数组。
其典型的嵌套式数据结构如下图所示:
{ “姓名”:“威哥”, “性别”:“男”, “住址”:“成都市”, “电话”:[ 137895×××××, 191263××××× ], “备注”:[ “IT主管”, “技术达人” ] }
2.4 SequoiaDB系统架构
SequoiaDB使用分布式架构,下图为体系结构: 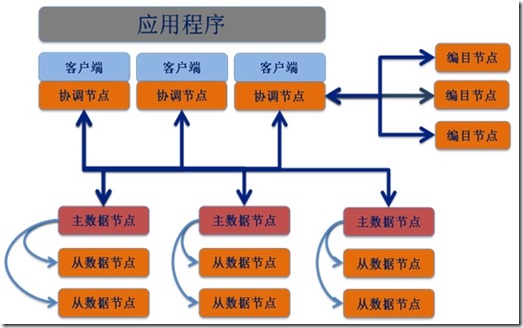
在客户端(或应用程序端),本地或(和)远程应用程序都与SequoiaDB客户机库链接。本一与远程客户机使用TCP/IP协议与协调节点进行通讯。
协调节点不保存任何用户数据,仅作为请求分发节点将用户请求分发至相应的数据节点。
编目节点保存系统的元数据信息,协调节点通过与编目节点通讯从而了解数据在数据节点中的实际分布。一个或多个编目节点可组成复制组集群。
数据节点保存用户的数据信息。一个或多个数据节点可以构成一个复制组。复制组中每个数据节点的数据保证最终一致性同步。数据复制组又叫做数据分片(Shard),不同的分片中保存的数据无重复。
每个分片中可以包含一个或多个数据节点。当存在多个数据节点时,节点间数据进行异步复制。分片中可以存在最多一个主节点与若干从节点。其中主节点可以进行读写操作,从节点进行只读操作。 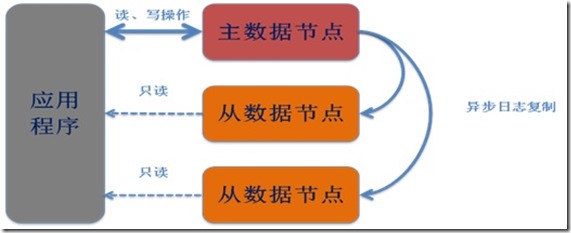
从节点离线不影响主节点的正常工作。主节点离线后会在从节点中自动选择举出新的主节点处理写请求。 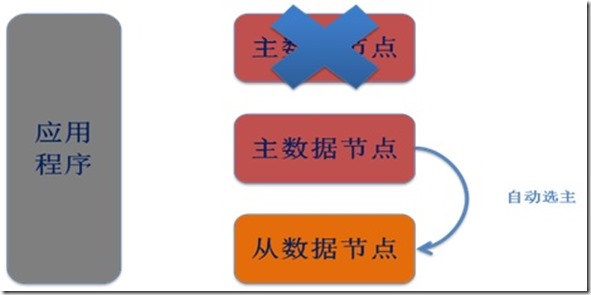
当节点恢复后,或新的节点加入分片后会理行自动同步,保障数据在同步完成时与主节点一致。 
在单个数据节点中的体系结构如下: 
在数据节点,活动由引擎可高度单元(EDU)控制。每一个节点对操作系统中的一个进程。每个EDU在节点中为一个线程。对于外部用请求其处理线程为代理线 程,对于集群内部请求则由同步代理线程处理分片内同步事件或分片代理线程处理分片间同步事件。所有对数据的写操作均会录入日志缓冲区,通过日志记录器将其 异步写入磁盘。用户数据会由代理线程直接写入文件系统缓冲池,然后由操作系统将其异步写入底层磁盘。
从以上三点可以初步了解SequoiaDB数据库,可为以后更深入学习及应用SequoiaDB数据库做为理论上的铺垫。
三: SequoiaDB数据库的一些基本概念
(此小节基础知识点是来自博客:https://blog.csdn.net/sequoiadb/article/details/12106005)
3.1 文档
SequoiaDB中的文档为JSON格式,一般又被称为记录。在数据库内部使用BSON,即二进制的方式存放JSON数据。一般情况下,一条文档由一个 或多处字段构成,每个字段分为键值与数值两个部分。需要指出的是:BSON文档可能有多个同名字段,但是,大多数SequoiaDB接口不支持重复的字段 名;SequoiaDB内部程序创建的一些文档可能含有重名的字段,但是不会向现有的用户文档添加重名的键。
3.2 集合
集合(Collection)是SequoiaDB数据库中存放文档的逻辑对象。任何一条文档必须属于一个且仅一个集合。
3.3 集合空间
集合空间(Collection Space)是数据库中存放集合的物理对象。任何一个集合必须属于一个且仅一个集合空间。每一个集合空间在数据节点均对应一个文件。
3.4 数据库服务器
SequoiaDB是文档型号非关系型数据库服务器,数据库服务器提供软件服务以便安全、高效地管理信息。数据库服务器是指安装了SequoiaDB数据 库引擎的计算机。SequoiaDB引擎为数据存取操作的基本单元,在分布式架构中,每个数据库作为一外节点存在,节点之间的数据无共享。在一台计算机 中,每一个SequoiaDB数据库引擎对应一个数据库路径,该数据库中所有的集合空间均放置在该目录中。数据库路径包含一个或多个集合空间。每个数据库 引擎可以包含最多4096个集合空间。
3.5 索引
在SequoiaDB数据库中,索引是一咱特殊的数据对象。索引本身不做为保存用户数据的容器。而是作为一种特殊的元数据,提高数据访问的效率。每一个索 引必须建立在一个集合中,一个集合最多可以拥有64个索引。索引可以被认为是将数据按照某个或多上给定的字段进行排序,从而在其中快速搜索到用户指定查询 条件的方式。在SequoiaDB中,索引使用B树结构。
3.6 事务
事务是一系列操作组成的逻辑工作单元。在同一个会话在(或连接)中,同一时刻只允许存在一个事务,也就是说当用户在一次会话中创建了一个事务,在这个事务 结束前用户不能再创建新的事务。事务作为一个完整的工作单元执行,事务中的操作要么全部执行成功要么全部执行失败。SequoiaDB事务中的操作只能是 插入数据、修改数据和删除数据,在事务过程中执行的其它操作不会纳入事务范畴,也就是说事务回滚时非事务操作不会被执行回滚。如果一个表或表空间中有数据 涉及事务操作,则该表或表空间不允许被删除。默认情况下,事务功能是关闭的。
3.7 最终一致性策略
SequoiaDB为了提升数据的可靠性和实现数据的读写分离,对于复制组间的数据采用“最终一致性”策略,在读写分离时读取的数据某一个时期内可能不是最新的,但最终是一致的。
3.8 读写分离
SequoiaDB中,所有写请求都只会发往节点,如果没有主节点则当前数据组不可处理写请求。
3.9 集群
SequoiaDB集群是指通过并联合多台数据库服务器,达到并行计算,以提升数据请求效率的方式。通过SequoiaDB集群,可以高性能的数据访问,保障数据高可用性,达到数据库的水平扩张能力。
3.10 运行模式
是指启动SequoiaDB服务时,该服务以独立模式启动还是以集群模式启动。独立模式是启动SequoiaDB的最精简模式,仅需要启动一个独立模式的 数据节点,即可进行数据服务。(一般推荐在开发环境中使用独立模式,以减少对硬件资源的需求。)集群模式是启动SequoiaDB的标准模式,至少需要三 个节点。
3.11 节点
编目节点:是一种逻辑节点,其中保存了数据库的元数据信息,而不保存其他用户数据。除了编目节点外,集群中所有其他的节点不在磁盘中保存任何全局元数据信 息。当需要访问其他节点上的数据时,除编目节点外的其他节点需要从本地缓存中寻找集合信息,如果不存在则需要从编目节点获取。编目节点与其它节点之间主要 使用编目服务端口进行通讯。 协调节点:也是一种逻辑节点,基中并不保存任何用户数据信息。协调节点作为数据请求部分的协调者,本身并不参与数据的匹配与读写操作,而仅仅是将请求分发到所需要处理的数据节点为。协调节点与其它节点之间主要使用分区服务端口进行通讯。
数据节点:仍是一种逻辑节点,其中保存用户数据信息。数据节点中高有专门的编目信息集合,因此第一次访问集合前需要向编目节点请求该集合的元数据信息。在独立模式中,数据节点为单独的服务提供者,直接与应用程序或客户端进行通讯,并且不需要访问任何编目信息。
3.12 分区组
又被称为复制组,一个复制组内可以包含一个或多个数据节点(或编目节点),节点之间的数据使用异步日志复制机制,保持最终一致。分区组中所有的节点之间使 用复制服务端口进行通讯,定期相互发送心跳信息以相互验证状态。每个分区组的节点有两种状态:主节点(可作读写操作,所有写入的数据会同步写入日志文件, 日志文件中的日志信息会异步写入从节点)和从节点(作只读操作,所有从主节点写入的数据会异步写入从节点,因此从节点与主节点之间可能存在暂时的数据不一 致,但是复制机制可以保证数据的最终一致性)。
3.13 数据分区
在SequoiaDB集群环境中,用户往往将数据存放在不同的逻辑节点与物理节点中,以达到交行计算目的。由于每一个存放数据的分区组中所有节点包含的数据完全相同,每个分区组被称作一个“分区”每个分区之间的数据互不影响,无共享状态。

