
深入学习python解析并读取PDF文件内容的方法
这篇文章主要学习了python解析并读取PDF文件内容的方法,包括对学习库的应用,python2.7和python3.6中python解析PDF文件内容库的更新,包括对pdfminer库的详细解释和应用。主要参考了一些已有的博客内容,代码。
主要思路是首先利用一个做项目的形式,描述所做的问题,运行环境,和需要安装的库,然后写代码,此代码是在python2.7中运行,小编也写出在python3.6中运行的代码,并详细解释python2.7和python3.6中python库的一些不同之处,最后详细的解释了代码的意思,和库的思路,最终的目的就让我们理解,并学会应用python解析并读取PDF文件内容的方法。
一,问题描述
利用python读取PDF文本内容
二,运行环境
python 3.6
三, 需要安装的库
pip install pdfminer
对pdfminer的简单介绍,官网介绍如下:
PDFMiner is a tool for extracting information from PDF documents. Unlike other PDF-related tools, it focuses entirely on getting and analyzing text data. PDFMiner allows to obtain the exact location of texts in a page, as well as other information such as fonts or lines. It includes a PDF converter that can transform PDF files into other text formats (such as HTML). It has an extensible PDF parser that can be used for other purposes instead of text analysis.
翻译是这样的:
PDFMiner是一个从PDF文档中提取信息的工具。与其他pdf相关的 工具不同,它完全专注于获取和分析文本数据。PDFMiner允许获取 页面中文本的确切位置,以及其他信息,比如字体或行。它包括一 个PDF转换器,可以将PDF文件转换成其他文本格式(如HTML)。 它有一个可扩展的PDF解析器,可以用于其他目的而不是文本分析。
四,实现源代码(其中代码1和代码2都是python2.7实现的)
python2中相关库的安装
python各种库下载地址:
https://www.lfd.uci.edu/~gohlke/pythonlibs/
找到pdfminer,下载,然后上传到服务器上,直接安装即可。
但是由于Python2和python3版本之间的不兼容,所以对应不同的版本,我们这里需要使用不同的特定环境。
其中的Pdfminer版本是pdfminer 20140328(对于python2.x的测试没有任何问题)
#_*_coding:utf-8_*_
from pdfminer.pdfparser import PDFParser
from pdfminer.pdfdocument import PDFDocument
from pdfminer.pdfpage import PDFPage
from pdfminer.pdfdevice import PDFDevice
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.converter import PDFPageAggregator
from pdfminer.layout import LTTextBoxHorizontal,LAParams
from pdfminer.pdfpage import PDFTextExtractionNotAllowed
def parse(Path,Save_name):
parser = PDFParser(Path)
document = PDFDocument(parser)
if not document.is_extractable:
raise PDFTextExtractionNotAllowed
else:
rsrcmgr = PDFResourceManager()
laparams = LAParams()
device = PDFPageAggregator(rsrcmgr,laparams=laparams)
interpreter = PDFPageInterpreter(rsrcmgr,device)
for page in PDFPage.create_pages(document):
interpreter.process_page(page)
layout = device.get_result()
for x in layout:
if(isinstance(x,LTTextBoxHorizontal)):
with open('%s'%(Save_name),'a') as f:
results = x.get_text().encode('utf-8')
f.write(results +"\n")
if __name__ == '__main__':
Path = open('word1-words.pdf','rb')
parse(Path,'1.txt')
五,python3.6中如何改进python2.7实现的代码
问题一,reload的改进
import sys reload(sys) sys.setdefaultencoding(‘utf-8’)
以上是python2的写法,但是在python3中这个需要已经不存在了,这么做也不会什么实际意义。
在Python2.x中由于str和byte之间没有明显区别,经常要依赖于defaultencoding来做转换。
在python3中有了明确的str和byte类型区别,从一种类型转换成另一种类型要显式指定encoding。
但是仍然可以使用这个方法代替
import importlib,sys importlib.reload(sys)
问题二,pdfminer模块的安装
在python2.7中可以直接安装
pip install pdfminer
在python3.6中就需要安装
pip install pdfminer3k
六 python3.6的源代码
import pyocr
import importlib
import sys
import time
importlib.reload(sys)
time1 = time.time()
# print("初始时间为:",time1)
import os.path
from pdfminer.pdfparser import PDFParser,PDFDocument
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.converter import PDFPageAggregator
from pdfminer.layout import LTTextBoxHorizontal,LAParams
from pdfminer.pdfinterp import PDFTextExtractionNotAllowed
text_path = r'words-words.pdf'
# text_path = r'photo-words.pdf'
def parse():
'''解析PDF文本,并保存到TXT文件中'''
fp = open(text_path,'rb')
#用文件对象创建一个PDF文档分析器
parser = PDFParser(fp)
#创建一个PDF文档
doc = PDFDocument()
#连接分析器,与文档对象
parser.set_document(doc)
doc.set_parser(parser)
#提供初始化密码,如果没有密码,就创建一个空的字符串
doc.initialize()
#检测文档是否提供txt转换,不提供就忽略
if not doc.is_extractable:
raise PDFTextExtractionNotAllowed
else:
#创建PDF,资源管理器,来共享资源
rsrcmgr = PDFResourceManager()
#创建一个PDF设备对象
laparams = LAParams()
device = PDFPageAggregator(rsrcmgr,laparams=laparams)
#创建一个PDF解释其对象
interpreter = PDFPageInterpreter(rsrcmgr,device)
#循环遍历列表,每次处理一个page内容
# doc.get_pages() 获取page列表
for page in doc.get_pages():
interpreter.process_page(page)
#接受该页面的LTPage对象
layout = device.get_result()
# 这里layout是一个LTPage对象 里面存放着 这个page解析出的各种对象
# 一般包括LTTextBox, LTFigure, LTImage, LTTextBoxHorizontal 等等
# 想要获取文本就获得对象的text属性,
for x in layout:
if(isinstance(x,LTTextBoxHorizontal)):
with open(r'2.txt','a') as f:
results = x.get_text()
print(results)
f.write(results +"\n")
if __name__ == '__main__':
parse()
time2 = time.time()
print("总共消耗时间为:",time2-time1)
七 python读取PDF文档代码分析
PDF格式不是规范格式. 尽管它被叫做"PDF文档", 但并不像word或者html文档。PDF的表现更像一张图片。PDF更像是在一张纸的各个准确的位置上把内容都摆放出来。大部分情况下,没有逻辑结构,比如句子或段落,并且不能自适应页面大小的调整。PDFMiner尝试通过猜测它们的布局来重建它们的结构,但是不保证一定能工作。我知道这样很难看,但是,PDF确实不够规范。
下面这个图片是使用流程说明,我们将其分解来看
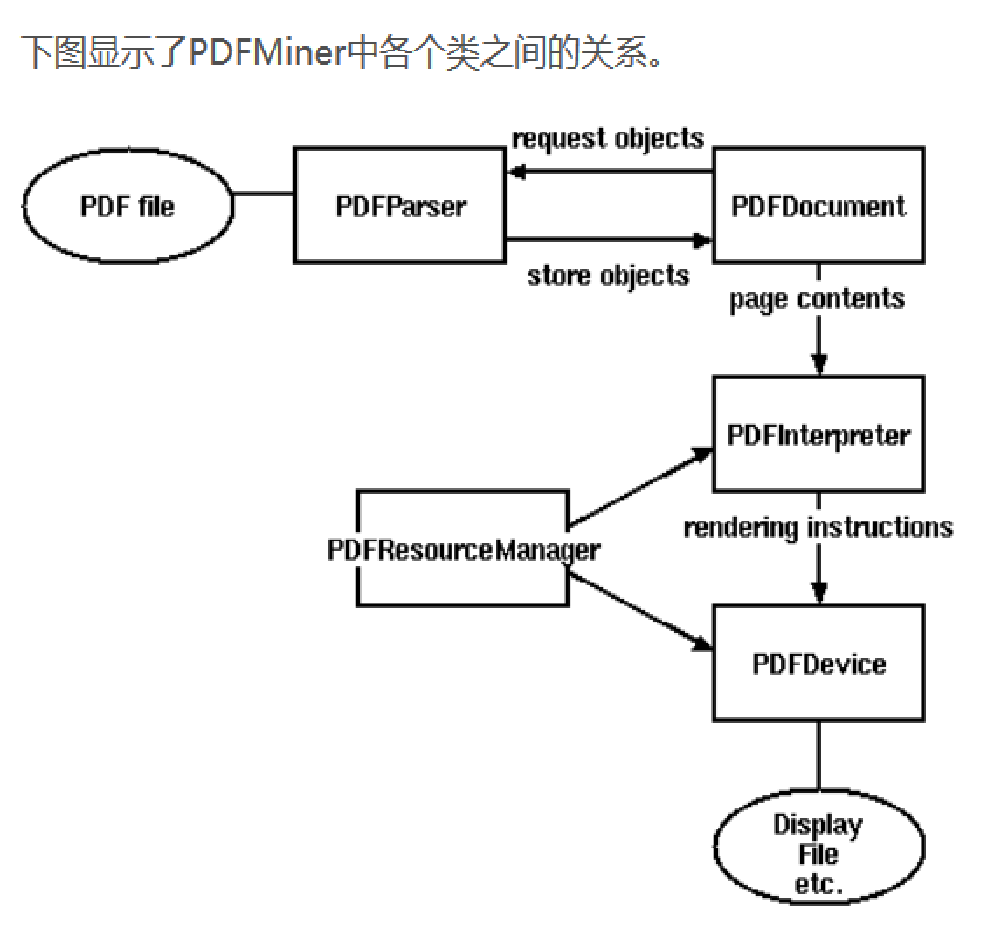
由于PDF文件有如此大和复杂的结构,完整解析PDF文件很费时费力。 好吧,大多数PDF工作中,很多模块是不需要加进来的。因此 PDFMiner 采用了一个懒惰分析的策略,就是只分析所需要的部分。解析时候,至少 需要2个核心类,PDFParser 和 PDFDocument。这两个模块配合其他 模块来使用。 PDFParser 从文件中获取数据 PDFDocument 存储文档数据结构到内存中 PDFPageInterpreter 解析page内容 PDFDevice 把解析到的内容转化为你需要的东西 PDFResourceManager存储共享资源,例如字体或图片
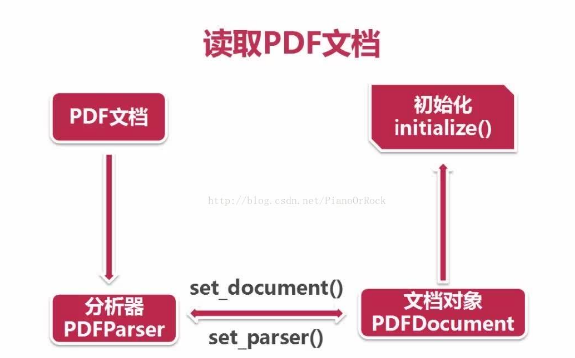
首先使用 open 方法或者 urlopen 打开本场文档或者网络文档(一般会这么做因为考虑到文档太大,对网络服务器负担也很大)生成文档对象,以下的方法之中的网络链接已经存在了。
# 获取文档对象
pdf0 = open('sampleFORtest.pdf','rb')
# pdf1 = urlopen('http://www.tencent.com/20160321.pdf')
然后创建 文档解析器 和 PDF文档对象 并将他们相互关联
# 创建一个与文档关联的解析器 parser = PDFParser(pdf0) # 创建一个PDF文档对象 doc = PDFDocument() # 连接两者 parser.set_document(doc) doc.set_parser(parser)
对 PDF文档对象 进行初始化,如果文档本身进行了加密,则需要在加入 password 参数
# 文档初始化
doc.initialize('')
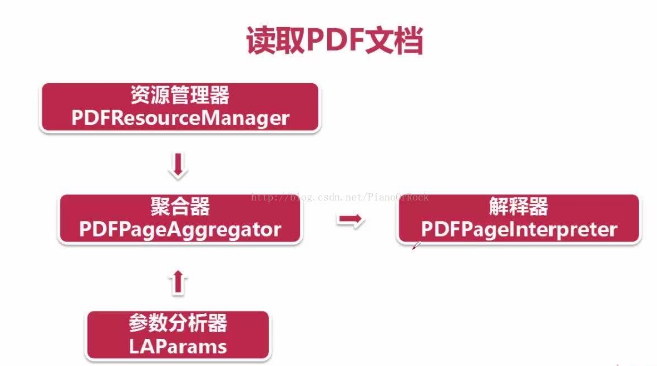
先创建 PDF资源管理器 和 参数分析器
# 创建PDF资源管理器 resources = PDFResourceManager() # 创建参数分析器 laparam = LAParams()
再创建一个 聚合器 ,并接收 PDF资源管理器 参数分析器 作为参数
# 创建一个聚合器,并接收资源管理器,参数分析器作为参数 device = PDFPageAggregator(resources,laparams=laparam)
最后创建一个 页面解释器 ,将 PDF资源管理器 和 聚合器 作为参数
# 创建一个页面解释器 interpreter = PDFPageInterpreter(resources,device)
这样 页面解释器 就具有对PDF文档进行编码,解释成Python能够识别的格式
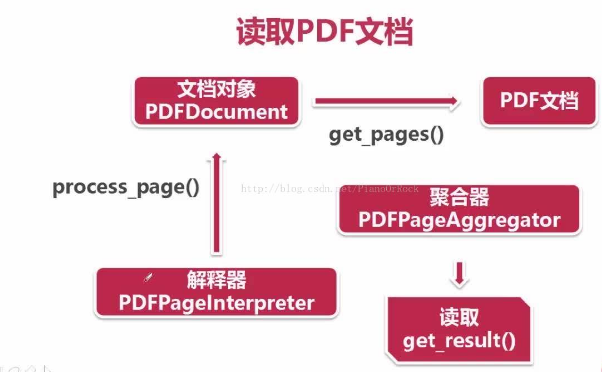
最后呢,使用 PDF文档对象 的 get_pages()方法 从PDF文档中读取出页面集合,接着使用 页面解释器 对页面集合逐一读取,再调用 聚合器 的 get_result()方法 将页面逐一放置到 layout 之中,最后商用 layout 的 get_text()方法 获取每一页的 text。
for page in doc.get_pages():
# 使用页面解释器读取页面
interpreter.process_page(page)
# 使用聚合器读取页面页面内容
layout = device.get_result()
for out in layout:
if hasattr(out,'get_text'): # 因为文档中不只有text文本
print(out.get_text())
需要注意的是在PDF文档中不只有 text 还可能有图片等等,为了确保不出错先判断对象是否具有 get_text()方法
八,结果分析
如果PDF文件中仅仅是文字,那么会完全解析出来,读出文字,存在一个TXT文档里面,但是要是出现了图片等东西,则不会读取到东西。
本文做了三个实验,分别是PDF文档里面只存在文字,只存在图片,存在文字和图片。
结果显示:
| 只存在文字的PDF | 此程序会全部读取出文字 |
| 只存在图片的PDF | 此程序不会读取出任何东西 |
| 存在图片和文字 | 此程序只会读出文字,不会识别图片 |
所以说,图片的文字识别,不能只单纯的使用pdfminer这个库,还需要图片处理等相关技术。
九,PDF解析模块-PDFMiner开发手册
PDF格式不是规范格式. 尽管它被叫做"PDF文档", 但并不像word或者html文档。PDF的表现更像一张图片。PDF更像是在一张纸的各个准确的位置上把内容都摆放出来。大部分情况下,没有逻辑结构,比如句子或段落,并且不能自适应页面大小的调整。PDFMiner尝试通过猜测它们的布局来重建它们的结构,但是不保证一定能工作。我知道这样很难看,但是,PDF确实不够规范。
更多关于PDF内部结构的技术详情,请见《如何手工提取PDF内容》。
http://www.youtube.com/watch?v=k34wRxaxA_c
http://www.youtube.com/watch?v=_A1M4OdNsiQ
http://www.youtube.com/watch?v=sfV_7cWPgZE
由于PDF文件有如此大和复杂的结构,完整解析PDF文件很费时费力。好吧,大多数PDF工作中,很多模块是不需要加进来的。因此 PDFMiner 采用了一个懒惰分析的策略,就是只分析所需要的部分。解析时候,至少需要2个核心类,PDFParser 和 PDFDocument。这两个模块配合其他模块来使用。
PDFParser 从文件中获取数据
PDFDocument 存储文档数据结构到内存中
PDFPageInterpreter 解析page内容
PDFDevice 把解析到的内容转化为你需要的东西
PDFResourceManager存储共享资源,例如字体或图片
布局分析把pdf文档中每一页返回为一个 LTPage 对象. 该对象包含该页面中的子对象,格式化为树形结构。
下图显示了这些对象之间的关系。
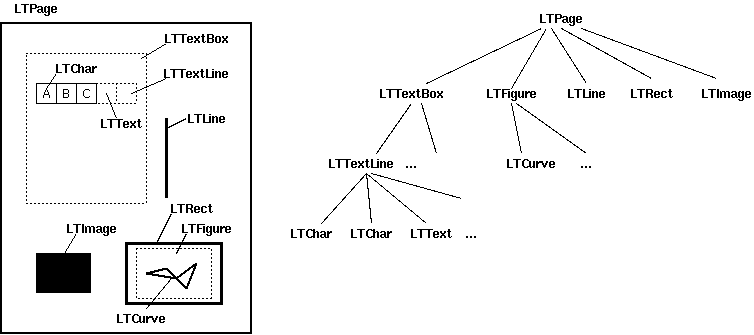
LTPage
代表一个完整的页面。可以包含子对象,例如LTTextBox,LTFigure,LTImage,LTRect,LTCurve和LTLine.
LTTextBox
它包含 LTTextLine 对象的列表
代表一组被包含在矩形区域中的文本
需要注意的是,该box是根据几何学分析得到的,并不一定准确地表现为该文本的逻辑范围
get_text()方法可以返回文本内容
LTTextLine
包含一个LTChar对象的列表,表现为单行文本
字符表现为一行或一列,取决于文本书写方式
get_text()方法返回文本内容
LTChar / LTAnno
代表一个在文本中的真实的字母,作为一个unicode字符串
LTChar 对象有真实的分隔符
LTAnno 对象没有,是虚拟分隔符,按照两个字符之间的关系,布局分析器插入虚拟分隔符
LTFigure
代表一个被PDF Form对象使用的区域
pdf form适用于目前的图表(present figures)或者页面中植入的另一个pdf文档图片。LTFigure对象可以递归
LTImage
代表一个图形对象。可以是JPEG或者其他格式,但PDFMiner目前没有花太多精力在图形对象上。
LTLine
代表一根直线。用来分割文本或图表(figures)。
LTRect
代表一个矩形。
用来框住别的图片或者图表。
LTCurve
代表一个贝塞尔曲线。
也可以从下面URL获得更多完整的示例。
http://denis.papathanasiou.org/?p=343

 浙公网安备 33010602011771号
浙公网安备 33010602011771号