
浅析对人工智能,机器学习和深度学习的理解
我们对于“人工智能”这个术语都很熟悉。毕竟,它是《终结者》,《黑客帝国》和《机械姬》等美国大片电影中非常流行的关键词。但你最*或许也听说过其他术语,像“机器学*”和“深度学*”,有时这两个术语会和“人工智能”互相替换使用,前年早些时候,Google DeepMind的AlphaGo打败了韩国的围棋大师李世乭九段。在媒体描述DeepMind胜利的时候,将人工智能(AI)、机器学*(machine learning)和深度学*(deep learning)都用上了。这三者在AlphaGo击败李世乭的过程中都起了作用,但它们说的并不是一回事。那么这三个名词之间有什么区别?
我会先解释一下人工智能(AI)、机器学*(ML)和深度学*(DL),以及它们有怎样的区别。
1 三者的概念
人工智能(英语:Artificial Intelligence, AI):是指由人工制造出来的系统所表现出来的智能。通常人工智能是指通过普通电脑实现的智能。人工智能的研究可以分为几个技术问题。其分支领域主要集中在解决具体问题,其中之一是,如何使用各种不同的工具完成特定的应用程序。AI的核心问题包括推理、知识、规划、学*、交流、感知、移动和操作物体的能力等。
目前有大量的工具应用了人工智能,其中包括搜索和数学优化、逻辑推演。而基于仿生学、认知心理学,以及基于概率论和经济学的算法等等也在逐步探索当中。
机器学*(英语:Machine Learning):是人工智能的一个分支。人工智能的研究是从以“推理”为重点到以“知识”为重点,再到以“学*”为重点,一条自然、清晰的脉络。显然,机器学*是实现人工智能的一个途径,即以机器学*为手段解决人工智能中的问题。机器学*在*30多年已发展为一门多领域交叉学科,涉及概率论、统计学、逼*论、凸分析、计算复杂性理论等多门学科。机器学*理论主要是设计和分析一些让计算机可以自动“学*”的算法。机器学*算法是一类从数据中自动分析获得规律,并利用规律对未知数据进行预测的算法。因为学*算法中涉及了大量的统计学理论,机器学*与推断统计学联系尤为密切,也被称为统计学*理论。算法设计方面,机器学*理论关注可以实现的,行之有效的学*算法。很多推论问题属于无程序可循难度,所以部分的机器学*研究是开发容易处理的*似算法。
机器学*有下面几种定义:
机器学*是一门人工智能的科学,该领域的主要研究对象是人工智能,特别是
如何在经验学*中改善具体算法的性能。
机器学*是对能通过经验自动改进的计算机算法的研究。
机器学*是用数据或以往的经验,以此优化计算机程序的性能标准。
机器学*已广泛应用于数据挖掘、计算机视觉、自然语言处理、生物特征识别、搜索引擎、医学诊断、检测信用卡欺诈、证券市场分析、DNA序列测序、语音和手写识别、战略游戏和机器人等领域。
机器学*最成功的应用领域是计算机视觉,虽然也还是需要大量的手工编码来完成工作。人们需要手工编写分类器、边缘检测滤波器,以便让程序能识别物体从哪里开始,到哪里结束;写形状检测程序来判断检测对象是不是有八条边;写分类器来识别字母“ST-O-P”。使用以上这些手工编写的分类器,人们总算可以开发算法来感知图像,判断图像是不是一个停止标志牌。
深度学*(英语:Deep Learning):是机器学*拉出的分支,它试图使用包含复杂结构或由多重非线性变换构成的多个处理层对数据进行高层抽象的算法。
深度学*是机器学*中一种基于对数据进行表征学*的方法。观测值(例如一幅图像)可以使用多种方式来表示,如每个像素强度值的向量,或者更抽象地表示成一系列边、特定形状的区域等。而使用某些特定的表示方法更容易从实例中学*任务(例如,人脸识别或面部表情识别)。深度学*的好处是用非监督式或半监督式的特征学*和分层特征提取高效算法来替代手工获取特征。
统计学*:关于计算机基于数据构建概率统计模型,并运用模型对数据进行预测与分析的一门学科。
机器学*:致力于研究如何通过计算的手段,利用经验来改善系统自身的性能。
深度学*:机器学*中的神经网络算法的延伸,可以理解为包含很多个隐层的神经网络模型。
2 三者的区别
人工智能:人工智能是人类社会发展主要目标 机器学*:机器学*是实现人工智能的核心技术 深度学*:是机器学*中最热门的算法
1956年,约翰·麦卡锡成为了第一位创造了人工智能机器的人。他制造的机器具备足够高的能力,得以执行类似人类智力水平的任务,包括:做出规划、理解语言、识别对象和声音、学*并解决问题等。
对于人工智能,我们可以从广义和狭义两个层面来理解。广义层面来讲,AI应该具备人类智力的所有特征,包括上述的能力。狭义层面的人工智能则只具备部分人类智力某些方面的能力,并且能在这些领域内做的非常出众,但可能缺乏其他领域的能力。比如说,一个人工智能机器可能拥有强大的图像识别功能,但除此之外并无他用,这就是狭义层面AI的例子。
从核心上来说,机器学*是实现人工智能的一种途径。
1959年,Arthur Samuel在AI之后创造了“机器学*”这个短语,并将其定义为“在没有被明确编程的情况下就能学*的能力。”当然,你可以不使用机器学*的方式来实现人工智能,不过这需要你运用复杂的规则和决策树,再敲下几百万行的代码才行。
实际上,机器学*是一种“训练”算法的方式,目的是使机器能够向算法传送大量的数据,并允许算法进行自我调整和改进,而不是利用具有特定指令的编码软件例程来完成指定的任务。
举个例子,机器学*已经被用于计算机视觉(机器具备识别图像或视频中的对象的能力)方面,并已经有了显著的进步。你可以收集数十万甚至数百万张图片,然后让人标记它们。例如,让人标记出其中含有猫的图片。对于算法,它也能够尝试建立一个模型,可以像人一样准确地标记出含有猫的图片。一旦精度水平足够高,机器就相当于“掌握”了猫的样子。
深度学*是机器学*的众多方法之一。其他方法包括决策树学*、归纳逻辑编程、聚类、强化学*和贝叶斯网络等。
深度学*的灵感来自大脑的结构和功能,即许多神经元的互连。人工神经网络(ANN)是模拟大脑生物结构的算法。
在ANN中,存在具有离散层和与其他“神经元”连接的“神经元”。每个图层挑选出一个要学*的特征,如图像识别中的曲线/边缘。 正是这种分层赋予了“深度学*”这样的名字,深度就是通过使用多层创建的,而不是单层。
3 深度学*,给人工智能以璀璨的未来
深度学*使得机器学*能够实现众多的应用,并拓展了人工智能的领域范围。深度学*摧枯拉朽般地实现了各种任务,使得似乎所有的机器辅助功能都变为可能。无人驾驶汽车,预防性医疗保健,甚至是更好的电影推荐,都*在眼前,或者即将实现。
3.1 现在说的很火的深度学*是什么呢?
- 深度学*是机器学*中神经网络算法的延伸,只不过应用的比较广
- 深度学*在计算机视觉和自然语言处理中更厉害一些
- 有些人问到底是学*机器学*还是深度学*?其实一切的基础都是机器学*,做任何事情没有坚实的基础只会越来越迷茫,机器学*值得我们从头开始

4 如何学好机器学*?
4.1 机器学*我该怎么学?
- 机器学*本质包含了数学原理推导与实际应用技巧
- 机器学*中有很多经典算法,既然要学*,那就需要清楚一个算法是怎么来的(推导)以及该如何应用
- 机器学*中,数学非常重要,大学的数学基础即可,如果都忘了,那么就边学边查,哪里不会学哪里就OK
- 数学推导一定要会,我们不光要知其然还要知其所以然,这对于我们的应用具有很大的帮助
4.2 机器学*可以分为下面几种类别
-
监督学*从给定的训练数据集中学*出一个函数,当新的数据到来时,可以根据这个函数预测结果。监督学*的训练集要求是包括输入和输出,也可以说是特征和目标。训练数据中的目标是由人标注的。常见的监督学*算法包括回归分析和统计分类。
-
无监督学*与监督学*相比,训练集没有人为标注的结果。常见的无监督学*算法有聚类。
-
半监督学*介于监督学*与无监督学*之间。它主要考虑如何利用少量的标注样本和大量的未标注样本进行训练和分类的问题。。
-
增强学*通过观察来学*做成如何的动作。每个动作都会对环境有所影响,学*对象根据观察到的周围环境的反馈来做出判断。
在传统的机器学*领域,监督学*最大的问题是训练数据标注成本比较高,而无监督学*应用范围有限。利用少量的训练样本和大量无标注数据的半监督学*一直是机器学*的研究重点。
当前非常流行的深度学*GAN模型和半监督学*的思路有相通之处,GAN是“生成对抗网络”(Generative Adversarial Networks)的简称,包括了一个生成模型G和一个判别模型D,GAN的目标函数是关于D与G的一个零和游戏,也是一个最小-最大化问题。
GAN实际上就是生成模型和判别模型之间的一个模仿游戏。生成模型的目的,就是要尽量去模仿、建模和学*真实数据的分布规律;而判别模型则是要判别自己所得到的一个输入数据,究竟是来自于真实的数据分布还是来自于一个生成模型。通过这两个内部模型之间不断的竞争,从而提高两个模型的生成能力和判别能力。
所以我们就安心学*好机器学*就好,那么如何学*好机器学*呢,下面用几张图片展示!
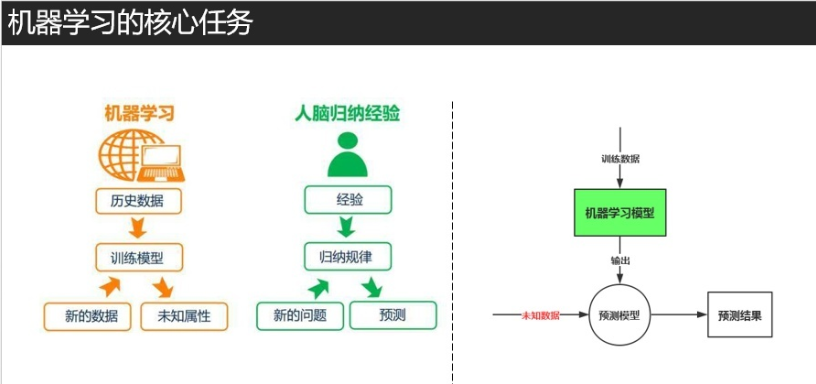
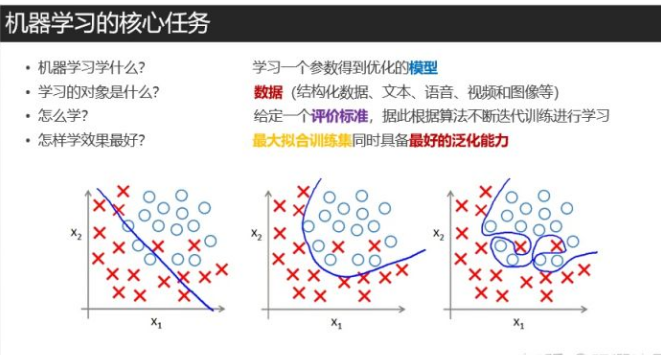

图片总结的如此清晰,我就不重复说了(此图片来此天善智能某课堂的PPT)
5 机器学*知识结构
小编从学*机器学*需要的各个方面在此阐述了要想学*机器学*,首先需要学*或者说准备什么东西,从以下四个方面说起。
5.1 数学基础
大学专业不是数学的同志们需要恶补的知识科目如下:
微积分 线性代数 矩阵论 凸优化 离散数学 概率论 统计学 随机过程

5.2 机器学*理论
机器学*的理论知识如下,其中推荐的包括算法和学*模型,还有训练的网址,全是干货哦,当然还是不全,以后小编了解到会逐渐加上的。
有监督机器学*模型和算法:分类和回归 线性回归 感知机器学* 决策树 朴素贝叶斯 人工神经网络,逻辑回归,随机森林,GBDT lightgbm xgboost....

5.3 编程与开发
编程开发使用的主要是python语言和Linux服务器,加上TensorFlow
python:numpy pandas matplotlib seaborn sklearn Linux : java c Spark Hadoop SQL excel..

5.4 英文能力
熟练地英语阅读能力
6 以下文章将会有助于你更加深入了解人工智能 、机器学* 、深度学* :
小编文中许多知识点都是参考下面的文章,大家有兴趣的可以继续了解三者的区别。
1、Artificial Intelligence, Machine Learning, and Deep Learning
2、Why Deep Learning is Radically Different from Machine Learning
6、WHY DEEP LEARNING IS SUDDENLY CHANGING YOUR LIFE
7、The Current State of Machine Intelligence 3.0
8、Here are 50 Companies Leading the AI Revolution

 浙公网安备 33010602011771号
浙公网安备 33010602011771号