
Python机器学习笔记:常用评估模型指标的用法
在机器学习中,性能指标(Metrics)是衡量一个模型好坏的关键,通过衡量模型输出y_predict和y_true之间的某种“距离”得出的。
对学习器的泛化性能进行评估,不仅需要有效可行的试验估计方法,还需要有衡量模型泛化能力的评估价标准,这就是性能度量(performance measure)。性能度量反映了任务需求,在对比不同模型的能力时,使用不同的性能度量往往会导致不的评判结果;这意味着模型的“好坏”是相对的,什么样的模型是好的,不仅取决于算法和数据,还决定于任务需求。
性能指标往往使我们做模型时的最终目标,如准确率,召回率,敏感度等等,但是性能指标常常因为不可微分,无法作为优化的loss函数,因此采用如cross-entropy,rmse等“距离”可微函数作为优化目标,以期待在loss函数降低的时候,能够提高性能指标。而最终目标的性能指标则作为模型训练过程中,作为验证集做决定(early stoping或model selection)的主要依据,与训练结束后评估本次训练出的模型好坏的重要标准。
在使用机器学习算法的过程中,针对不同的场景需要不同的评价指标,常用的机器学习算法包括分类,回归,聚类等几大类型,在这里对常用的指标进行一个简单的总结,小编总结了前人的很多博客,知乎等,方便自己学习。当然,需要的同学们也可以看一下。
下图是不同机器学习算法的评价指标:
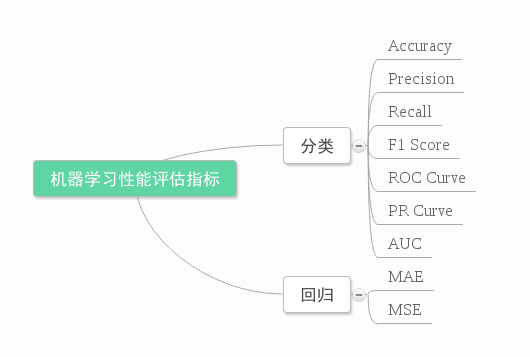
下面是机器学习算法评估指标的Sklearn方法:
# *************准确率*************
# 1,accuracy_score
# 准确率
import numpy as np
from sklearn.metrics import accuracy_score
y_pred = [0, 2, 1, 3,9,9,8,5,8]
y_true = [0, 1, 2, 3,2,6,3,5,9]
accuracy_score(y_true, y_pred)
Out[127]: 0.33333333333333331
accuracy_score(y_true, y_pred, normalize=False) # 类似海明距离,每个类别求准确后,再求微平均
Out[128]: 3
# 2, metrics
from sklearn import metrics
metrics.precision_score(y_true, y_pred, average='micro') # 微平均,精确率
Out[130]: 0.33333333333333331
metrics.precision_score(y_true, y_pred, average='macro') # 宏平均,精确率
Out[131]: 0.375
metrics.precision_score(y_true, y_pred, labels=[0, 1, 2, 3], average='macro') # 指定特定分类标签的精确率
Out[133]: 0.5
# *************召回率*************
metrics.recall_score(y_true, y_pred, average='micro')
Out[134]: 0.33333333333333331
metrics.recall_score(y_true, y_pred, average='macro')
Out[135]: 0.3125
# *************F1*************
metrics.f1_score(y_true, y_pred, average='weighted')
Out[136]: 0.37037037037037035
# *************F2*************
# 根据公式计算
from sklearn.metrics import precision_score, recall_score
def calc_f2(label, predict):
p = precision_score(label, predict)
r = recall_score(label, predict)
f2_score = 5*p*r / (4*p + r)
return f2_score
# *************混淆矩阵*************
from sklearn.metrics import confusion_matrix
confusion_matrix(y_true, y_pred)
Out[137]:
array([[1, 0, 0, ..., 0, 0, 0],
[0, 0, 1, ..., 0, 0, 0],
[0, 1, 0, ..., 0, 0, 1],
...,
[0, 0, 0, ..., 0, 0, 1],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 1, 0]])
# *************ROC*************
# 1,计算ROC值
import numpy as np
from sklearn.metrics import roc_auc_score
y_true = np.array([0, 0, 1, 1])
y_scores = np.array([0.1, 0.4, 0.35, 0.8])
roc_auc_score(y_true, y_scores)
# 2,ROC曲线
y = np.array([1, 1, 2, 2])
scores = np.array([0.1, 0.4, 0.35, 0.8])
fpr, tpr, thresholds = roc_curve(y, scores, pos_label=2)
# *************海明距离*************
from sklearn.metrics import hamming_loss
y_pred = [1, 2, 3, 4]
y_true = [2, 2, 3, 4]
hamming_loss(y_true, y_pred)
0.25
# *************Jaccard距离*************
import numpy as np
from sklearn.metrics import jaccard_similarity_score
y_pred = [0, 2, 1, 3,4]
y_true = [0, 1, 2, 3,4]
jaccard_similarity_score(y_true, y_pred)
0.5
jaccard_similarity_score(y_true, y_pred, normalize=False)
2
# *************可释方差值(Explained variance score)************
from sklearn.metrics import explained_variance_score
y_true = [3, -0.5, 2, 7]
y_pred = [2.5, 0.0, 2, 8]
explained_variance_score(y_true, y_pred)
# *************平均绝对误差(Mean absolute error)*************
from sklearn.metrics import mean_absolute_error
y_true = [3, -0.5, 2, 7]
y_pred = [2.5, 0.0, 2, 8]
mean_absolute_error(y_true, y_pred)
# *************均方误差(Mean squared error)*************
from sklearn.metrics import mean_squared_error
y_true = [3, -0.5, 2, 7]
y_pred = [2.5, 0.0, 2, 8]
mean_squared_error(y_true, y_pred)
# *************中值绝对误差(Median absolute error)*************
from sklearn.metrics import median_absolute_error
y_true = [3, -0.5, 2, 7]
y_pred = [2.5, 0.0, 2, 8]
median_absolute_error(y_true, y_pred)
# *************R方值,确定系数*************
from sklearn.metrics import r2_score
y_true = [3, -0.5, 2, 7]
y_pred = [2.5, 0.0, 2, 8]
r2_score(y_true, y_pred)
一,分类
分类是机器学习中的一类重要问题,很多重要的算法都在解决分类问题,例如决策树,支持向量机等,其中二分类问题是分类问题中的一个重要的课题。
常见的分类模型包括:逻辑回归、决策树、朴素贝叶斯、SVM、神经网络等,模型评估指标包括以下几种:
1. TPR、FPR&TNR(混淆矩阵)
在二分类问题中,即将实例分成正类(positive)或负类(negative)。对一个二分问题来说,会出现四种情况。如果一个实例是正类并且也被 预测成正类,即为真正类(True positive),如果实例是负类被预测成正类,称之为假正类(False positive)。相应地,如果实例是负类被预测成负类,称之为真负类(True negative),正类被预测成负类则为假负类(false negative)。
TP(True positive):将正类预测为正类数;
TN(True negative):将负类预测为负类数;
FP(False positive):将负类预测为正类数(误报 Type I error);
FN(False negative):将正类预测为负类数(漏报 Type II error);
在评估一个二分类模型的效果时,我们通常会用一个称为混淆矩阵(confusion matrix)的四格表来表示,即如下表所示,1代表正类,0代表负类:
| 预测1 | 预测0 | |
| 实际1 | True Positive(TP) | False Negative(FN) |
| 实际0 | False Positive(FP) | True Negative(TN) |
从列联表引入两个新名词。其一是真正类率(true positive rate ,TPR), 计算公式为
TPR = TP / (TP + FN)
刻画的是分类器所识别出的 正实例占所有正实例的比例。
另外一个是负正类率(false positive rate, FPR),计算公式为
FPR = FP / (FP + TN)
计算的是分类器错认为正类的负实例占所有负实例的比例。
还有一个真负类率(True Negative Rate,TNR),也称为specificity,计算公式为
TNR = TN /(FP + TN) = 1 - FPR
from sklearn.metrics import confusion_matrix # y_pred是预测标签 y_pred, y_true =[1,0,1,0], [0,0,1,0] confusion_matrix(y_true=y_true, y_pred=y_pred)
2,精确率Precision、召回率Recall和F1值
精确率(正确率)和召回率是广泛用于信息检索和统计学分类领域的两个度量值,用来评价结果的质量。其中精度是检索出相关文档数与检索出的文档总数的比率,衡量的是检索系统的查准率;召回率是指检索出的相关文档数和文档库中所有的相关文档数的比率,衡量的是检索系统的查全率。
一般来说,Precision就是检索出来的条目(比如:文档、网页等)有多少是准确的,Recall就是所有准确的条目有多少被检索出来了,两者的定义分别如下:
Precision = 提取出的正确信息条数 / 提取出的信息条数

Recall = 提取出的正确信息条数 / 样本中的信息条数

精准度(又称查准率)和召回率(又称查全率)是一对矛盾的度量。一般来说,查准率高时,查全率往往偏低,而查全率高时,查准率往往偏低。所以通常只有在一些简单任务中,才可能使得查准率和查全率都很高。
from sklearn.metrics import classification_report # y_pred是预测标签 y_pred, y_true =[1,0,1,0], [0,0,1,0] print(classification_report(y_true=y_true, y_pred=y_pred))
3. 综合评价指标F-measure
Precision和Recall指标有时候会出现的矛盾的情况,这样就需要综合考虑他们,最常见的方法就是在Precision和Recall的基础上提出了F1值的概念,来对Precision和Recall进行整体评价。F1的定义如下:
F1值 = 正确率 * 召回率 * 2 / (正确率 + 召回率)

F-Measure是Precision和Recall加权调和平均:
当参数α=1时,就是最常见的F1。因此,F1综合了P和R的结果,当F1较高时则能说明试验方法比较有效。

4. 应用场景:
准确率和召回率是互相影响的,理想情况下肯定是做到两者都高,但是一般情况下准确率高、召回率就低,召回率低、准确率高,当然如果两者都低,那是什么地方出问题了。当精确率和召回率都高时,F1的值也会高。在两者都要求高的情况下,可以用F1来衡量。
- 地震的预测
对于地震的预测,我们希望的是RECALL非常高,也就是说每次地震我们都希望预测出来。这个时候我们可以牺牲PRECISION。情愿发出1000次警报,把10次地震都预测正确了;也不要预测100次对了8次漏了两次。 - 嫌疑人定罪
基于不错怪一个好人的原则,对于嫌疑人的定罪我们希望是非常准确的。及时有时候放过了一些罪犯(recall低),但也是值得的。
不妨举这样一个例子:
某池塘有1400条鲤鱼,300只虾,300只鳖。现在以捕鲤鱼为目的。撒一大网,逮着了700条鲤鱼,200只虾,100只鳖。那么,这些指标分别如下:
正确率 = 700 / (700 + 200 + 100) = 70%
召回率 = 700 / 1400 = 50%
F1值 = 70% * 50% * 2 / (70% + 50%) = 58.3%
不妨看看如果把池子里的所有的鲤鱼、虾和鳖都一网打尽,这些指标又有何变化:
正确率 = 1400 / (1400 + 300 + 300) = 70%
召回率 = 1400 / 1400 = 100%
F1值 = 70% * 100% * 2 / (70% + 100%) = 82.35%
由此可见,正确率是评估捕获的成果中目标成果所占得比例;召回率,顾名思义,就是从关注领域中,召回目标类别的比例;而F值,则是综合这二者指标的评估指标,用于综合反映整体的指标。
当然希望检索结果Precision越高越好,同时Recall也越高越好,但事实上这两者在某些情况下有矛盾的。比如极端情况下,我们只搜索出了一个结果,且是准确的,那么Precision就是100%,但是Recall就很低;而如果我们把所有结果都返回,那么比如Recall是100%,但是Precision就会很低。因此在不同的场合中需要自己判断希望Precision比较高或是Recall比较高。如果是做实验研究,可以绘制Precision-Recall曲线来帮助分析。
代码补充:
from sklearn.metrics import precision_score, recall_score, f1_score
# 正确率 (提取出的正确信息条数 / 提取出的信息条数)
print('Precision: %.3f' % precision_score(y_true=y_test, y_pred=y_pred))
# 召回率 (提出出的正确信息条数 / 样本中的信息条数)
print('Recall: %.3f' % recall_score(y_true=y_test, y_pred=y_pred))
# F1-score (正确率*召回率*2 /(正确率+召回率))
print('F1: %.3f' % f1_score(y_true=y_test, y_pred=y_pred))
5. ROC曲线和AUC
AUC是一种模型分类指标,且仅仅是二分类模型的评价指标。AUC是Area Under Curve的简称,那么Curve就是ROC(Receiver Operating Characteristic),翻译为"接受者操作特性曲线"。也就是说ROC是一条曲线,AUC是一个面积值。
ROC曲线应该尽量偏离参考线,越靠近左上越好
AUC:ROC曲线下面积,参考线面积为0.5,AUC应大于0.5,且偏离越多越好
5.1 为什么引入ROC曲线?
Motivation1:在一个二分类模型中,对于所得到的连续结果,假设已确定一个阀值,比如说 0.6,大于这个值的实例划归为正类,小于这个值则划到负类中。如果减小阀值,减到0.5,固然能识别出更多的正类,也就是提高了识别出的正例占所有正例 的比类,即TPR,但同时也将更多的负实例当作了正实例,即提高了FPR。为了形象化这一变化,引入ROC,ROC曲线可以用于评价一个分类器。
Motivation2:在类不平衡的情况下,如正样本90个,负样本10个,直接把所有样本分类为正样本,得到识别率为90%。但这显然是没有意义的。单纯根据Precision和Recall来衡量算法的优劣已经不能表征这种病态问题。
绘制ROC曲线
import matplotlib.pyplot as plt
from sklearn.metrics import roc_curve, auc
# y_test:实际的标签, dataset_pred:预测的概率值。
fpr, tpr, thresholds = roc_curve(y_test, dataset_pred)
roc_auc = auc(fpr, tpr)
#画图,只需要plt.plot(fpr,tpr),变量roc_auc只是记录auc的值,通过auc()函数能计算出来
plt.plot(fpr, tpr, lw=1, label='ROC(area = %0.2f)' % (roc_auc))
plt.xlabel("FPR (False Positive Rate)")
plt.ylabel("TPR (True Positive Rate)")
plt.title("Receiver Operating Characteristic, ROC(AUC = %0.2f)"% (roc_auc))
plt.show()
5.2 什么是ROC曲线?
ROC(Receiver Operating Characteristic)翻译为"接受者操作特性曲线"。曲线由两个变量1-specificity 和 Sensitivity绘制. 1-specificity=FPR,即负正类率。Sensitivity即是真正类率,TPR(True positive rate),反映了正类覆盖程度。这个组合以1-specificity对sensitivity,即是以代价(costs)对收益(benefits)。显然收益越高,代价越低,模型的性能就越好。
此外,ROC曲线还可以用来计算“均值平均精度”(mean average precision),这是当你通过改变阈值来选择最好的结果时所得到的平均精度(PPV)。
- x 轴为假阳性率(FPR):在所有的负样本中,分类器预测错误的比例

- y 轴为真阳性率(TPR):在所有的正样本中,分类器预测正确的比例(等于Recall)
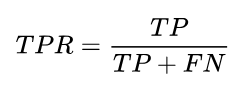
为了更好地理解ROC曲线,我们使用具体的实例来说明:
如在医学诊断中,判断有病的样本。那么尽量把有病的揪出来是主要任务,也就是第一个指标TPR,要越高越好。而把没病的样本误诊为有病的,也就是第二个指标FPR,要越低越好。
不难发现,这两个指标之间是相互制约的。如果某个医生对于有病的症状比较敏感,稍微的小症状都判断为有病,那么他的第一个指标应该会很高,但是第二个指标也就相应地变高。最极端的情况下,他把所有的样本都看做有病,那么第一个指标达到1,第二个指标也为1。
我们以FPR为横轴,TPR为纵轴,得到如下ROC空间。
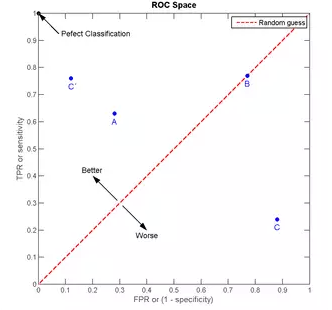
我们可以看出,左上角的点(TPR=1,FPR=0),为完美分类,也就是这个医生医术高明,诊断全对。点A(TPR>FPR),医生A的判断大体是正确的。中线上的点B(TPR=FPR),也就是医生B全都是蒙的,蒙对一半,蒙错一半;下半平面的点C(TPR<FPR),这个医生说你有病,那么你很可能没有病,医生C的话我们要反着听,为真庸医。上图中一个阈值,得到一个点。现在我们需要一个独立于阈值的评价指标来衡量这个医生的医术如何,也就是遍历所有的阈值,得到ROC曲线。
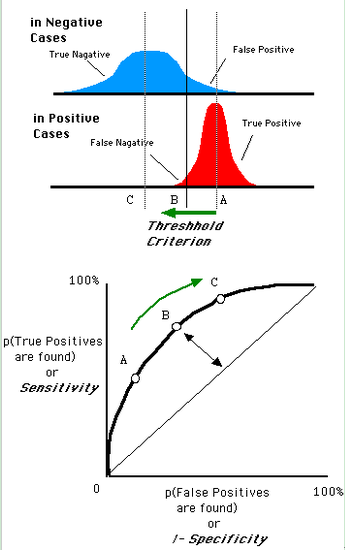
假设下图是某医生的诊断统计图,为未得病人群(上图)和得病人群(下图)的模型输出概率分布图(横坐标表示模型输出概率,纵坐标表示概率对应的人群的数量),显然未得病人群的概率值普遍低于得病人群的输出概率值(即正常人诊断出疾病的概率小于得病人群诊断出疾病的概率)。
竖线代表阈值。显然,图中给出了某个阈值对应的混淆矩阵,通过改变不同的阈值 ,得到一系列的混淆矩阵,进而得到一系列的TPR和FPR,绘制出ROC曲线。
阈值为1时,不管你什么症状,医生均未诊断出疾病(预测值都为N),此时绿色和红色区域的面积为 0,因此 ,位于左下。随着阈值的减小,红色和绿色区域增大,紫色和蓝色区域减小。阈值为 0 时,不管你什么症状,医生都诊断结果都是得病(预测值都为P),此时绿色和红色区域均占整个区域,即紫色和蓝色区域的面积为 0,此时
,位于右上。

还是一开始的那幅图,假设如下就是某个医生的诊断统计图,直线代表阈值。我们遍历所有的阈值,能够在ROC平面上得到如下的ROC曲线。
曲线距离左上角越近,证明分类器效果越好。
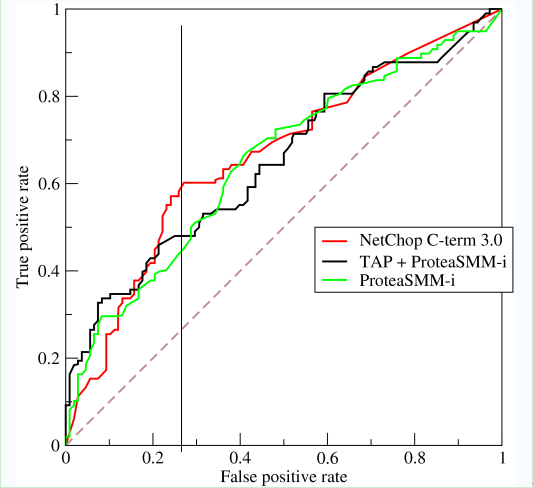
如上,是三条ROC曲线,在0.23处取一条直线。那么,在同样的低FPR=0.23的情况下,红色分类器得到更高的PTR。也就表明,ROC越往上,分类器效果越好。我们用一个标量值AUC来量化它。
5.3 什么是AUC?
AUC值为ROC曲线所覆盖的区域面积,显然,AUC越大,分类器分类效果越好。
AUC = 1,是完美分类器,采用这个预测模型时,不管设定什么阈值都能得出完美预测。绝大多数预测的场合,不存在完美分类器。
0.5 < AUC < 1,优于随机猜测。这个分类器(模型)妥善设定阈值的话,能有预测价值。
AUC = 0.5,跟随机猜测一样(例:丢铜板),模型没有预测价值。
AUC < 0.5,比随机猜测还差;但只要总是反预测而行,就优于随机猜测。
以下为ROC曲线和AUC值得实例:

AUC的物理意义:假设分类器的输出是样本属于正类的socre(置信度),则AUC的物理意义为,任取一对(正、负)样本,正样本的score大于负样本的score的概率。
AUC的物理意义正样本的预测结果大于负样本的预测结果的概率。所以AUC反应的是分类器对样本的排序能力。
另外值得注意的是,AUC对样本类别是否均衡并不敏感,这也是不均衡样本通常用AUC评价分类器性能的一个原因。
下面从一个小例子解释AUC的含义:小明一家四口,小明5岁,姐姐10岁,爸爸35岁,妈妈33岁建立一个逻辑回归分类器,来预测小明家人为成年人概率,假设分类器已经对小明的家人做过预测,得到每个人为成人的概率。
- AUC更多的是关注对计算概率的排序,关注的是概率值的相对大小,与阈值和概率值的绝对大小没有关系
例子中并不关注小明是不是成人,而关注的是,预测为成人的概率的排序。
5.4 怎样计算AUC?
第一种方法:AUC为ROC曲线下的面积,那我们直接计算面积可得。面积为一个个小的梯形面积之和。计算的精度与阈值的精度有关。
第二种方法:根据AUC的物理意义,我们计算正样本score大于负样本的score的概率。取N*M(N为正样本数,M为负样本数)个二元组,比较score,最后得到AUC。时间复杂度为O(N*M)。
第三种方法:与第二种方法相似,直接计算正样本score大于负样本的概率。我们首先把所有样本按照score排序,依次用rank表示他们,如最大score的样本,rank=n(n=N+M),其次为n-1。那么对于正样本中rank最大的样本,rank_max,有M-1个其他正样本比他score小,那么就有(rank_max-1)-(M-1)个负样本比他score小。其次为(rank_second-1)-(M-2)。最后我们得到正样本大于负样本的概率为

时间复杂度为O(N+M)。
from sklearn.metrics import roc_auc_score # y_test:实际的标签, dataset_pred:预测的概率值。 roc_auc_score(y_test, dataset_pred)
二,回归
在回归中,我们想根据连续数据来进行预测。例如,我们有包含不同人员的身高、年龄和性别的列表,并想预测他们的体重。或者,我们可能有一些房屋数据,并想预测某所住宅的价值。手头的问题在很大程度上决定着我们如何评估模型。
以下为一元变量和二元变量的线性回归示意图:

那么怎么来衡量回归模型的好坏呢?
我们首先想到的是采用残差(实际值与预测值的差值)的均值来衡量,即:
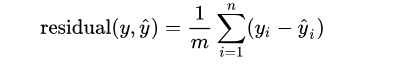
那么问题来了:使用残差的均值合理吗?
当实际值分布在拟合曲线两侧时候,对于不同样本而言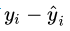 有正有负,相互抵消,因此我们想到采用预测值和真实值之间的距离来衡量。
有正有负,相互抵消,因此我们想到采用预测值和真实值之间的距离来衡量。
2.1 平均绝对误差(MAE)

既然使用了MAE,那他有什么不足?
MAE虽然较好的衡量回归模型的好坏,但是绝对值的存在导致函数不光滑,在某些点上不能求导,可以考虑将绝对值改为残差的平方,这就是均方误差。
from sklearn.metrics import mean_squared_error y_true, y_pred = [3, -0.5, 2, 7], [2.5, 0.0, 2, 8] mean_squared_error(y_true, y_pred)
2.2 平均平方误差(MSE)

那么还有没有比MSE更合理一些的指标?
MSE和方差的性质比较类似,与我们的目标变量的量纲不一致,为了保证量纲一致性,我们需要对MSE进行开方,得到RMSE。
from sklearn.metrics import mean_squared_error y_true, y_pred = [3, -0.5, 2, 7], [2.5, 0.0, 2, 8] mean_squared_error(y_true, y_pred)
2.3 均方根误差(RMSE)
RMSE虽然广为使用,但是其存在一些缺点,因为它是使用平均误差,而平均值对异常点(outliers)较敏感,如果回归器对某个点的回归值很不理性,那么它的误差则较大,从而会对RMSE的值有较大影响,即平均值是非鲁棒的。
开方之后的MSE称为RMSE,是标准差的表兄弟,如下式所示:

RMSE有没有不足的地方,有没有规范化(无量纲化的指标)?
上面的几种衡量标准的取值大小与具体的应用场景有关系,很难定义统一的规则来衡量模型的好坏。比如说利用机器学习算法预测上海的房价RMSE在2000元,我们是可以接受的,但是当四五线城市的房价RMSE为2000元,我们还可以接受吗?下面介绍的决定系数就是一个无量纲化的指标。
lr.score(test_x,test_y)#越接近1越好,负的很差 from sklearn.metrics import mean_squared_error mean_squared_error(test_y,lr.predict(test_x))#mse np.sqrt(mean_squared_error(test_y,lr.predict(test_x)))
2.4 决定系数
变量之所以有价值,就是因为变量是变化的。什么意思呢?比如说一组因变量为[0, 0, 0, 0, 0],显然该因变量的结果是一个常数0,我们也没有必要建模对该因变量进行预测。假如一组的因变量为[1, 3, 7, 10, 12],该因变量是变化的,也就是有变异,因此需要通过建立回归模型进行预测。这里的变异可以理解为一组数据的方差不为0。
决定系数又称为 score,反应因变量的全部变异能通过回归关系被自变量解释的比例。
如果结果是0,就说明模型预测不能预测因变量。
如果结果是1。就说明是函数关系。
如果结果是0-1之间的数,就是我们模型的好坏程度。
化简上面的公式 ,分子就变成了我们的均方误差MSE,下面分母就变成了方差:

以上的评估指标有没有缺陷,如果有,该如何改进呢?
以上的评估指标是基于误差的均值对进行评估的,均值对异常点(outliers)较敏感,如果样本中有一些异常值出现,会对以上指标的值有较大影响,即均值是非鲁棒的。
from sklearn.metrics import r2_score y_true, y_pred = [3, -0.5, 2, 7], [2.5, 0.0, 2, 8] r2_score(y_true, y_pred)
2.5 解决评估指标鲁棒性问题
我们通常用一下两种方法解决评估指标的鲁棒性问题:
- 剔除异常值
设定一个相对误差 ,当该值超过一定的阈值时,则认为其是一个异常点,剔除这个异常点,将异常点剔除之后。再计算平均误差来对模型进行评价。
- 使用误差的分位数来代替,
如利用中位数来代替平均数。例如 MAPE:
MAPE是一个相对误差的中位数,当然也可以使用别的分位数。
2.6 解释变异

三,聚类
常见的聚类模型有KMeans、密度聚类、层次聚类等,主要从簇内的稠密成都和簇间的离散程度来评估聚类的效果,评估指标包括:
1 . 兰德指数
兰德指数(Rand index)需要给定实际类别信息C,假设K是聚类结果,a表示在C与K中都是同类别的元素对数,b表示在C与K中都是不同类别的元素对数,则兰德指数为:

其中![]() 数据集中可以组成的总元素对数,RI取值范围为[0,1],值越大意味着聚类结果与真实情况越吻合。
数据集中可以组成的总元素对数,RI取值范围为[0,1],值越大意味着聚类结果与真实情况越吻合。
对于随机结果,RI并不能保证分数接近零。为了实现“在聚类结果随机产生的情况下,指标应该接近零”,调整兰德系数(Adjusted rand index)被提出,它具有更高的区分度:
![]()
具体计算方式参见Adjusted Rand index。
ARI取值范围为[−1,1],值越大意味着聚类结果与真实情况越吻合。从广义的角度来讲,ARI衡量的是两个数据分布的吻合程度。
2. 互信息
互信息(Mutual Information)也是用来衡量两个数据分布的吻合程度。假设UU与VV是对NN个样本标签的分配情况,则两种分布的熵(熵表示的是不确定程度)分别为:

利用基于互信息的方法来衡量聚类效果需要实际类别信息,MI与NMI取值范围为[0,1],AMI取值范围为[−1,1],它们都是值越大意味着聚类结果与真实情况越吻合。
3. 轮廓系数
3.1 轮廓系数概念
轮廓系数(Silhouette coefficient)是聚类效果好坏的一种评价方式。最早由Peter J . Rousseeuw 在1986年提出。它结合内聚度和分离度两种因素。可以用来在相同原始数据的基础上用来评价不同的算法,或者算法不同运行方式对聚类结果所产生的影响。
轮廓稀疏适用于实际类别信息未知的情况。对于单个样本,设aa是与它同类别中其他样本的平均距离,bb是与它距离最近不同类别中样本的平均距离,轮廓系数为:
![]()
对于一个样本集合,它的轮廓系数是所有样本轮廓系数的平均值。
轮廓系数取值范围是[−1,1]
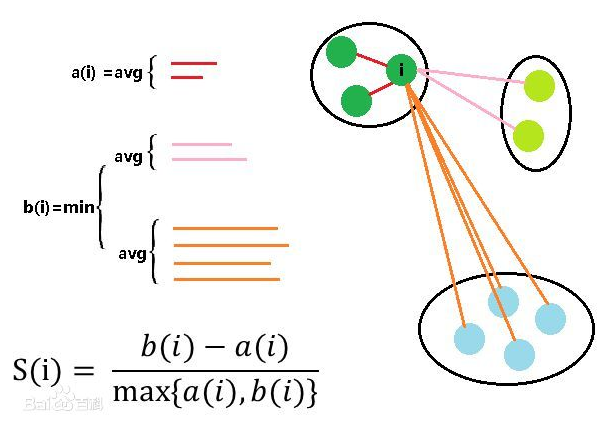
3.2 轮廓系数计算过程
假设我们已经通过一定算法啊,将待分类数据进行了聚类。常用的比如使用K-Means,将待分类数据分为了K个簇。对于簇中的每个向量。分别计算他们的轮廓系数。
对于其中的一个点 i 来说:
计算 a(i) = average(i 向量到所有它属于的簇中其他点的距离)
计算 b(i) = min(i 向量到它相邻最近的一簇内的所有点的平均距离)
那么i 向量轮廓系数就为:
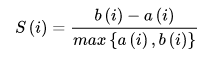
可见,轮廓系数的值是介于 [-1, 1],越趋近于1 代表内聚度和分离度都相对较近。
将所有点的轮廓系数求平均,就是该聚类结果总的轮廓系数。
a(i) :i 向量到同一簇内其他点不相似程度的平均值
b(i):i向量到其他簇的平均不相似程度的最小值
3.3 轮廓系数使用注意事项
上面说到的“距离”,指的是不相似度(区别于相似度)。“距离”值越大,代表不相似度程度越高
欧式距离就满足这个条件,而Tanimoto Measure 则用作相似度度量
当簇内只有一点时,我们定义轮廓系数 s(i) 为 0
3.4 Python实现轮廓系数的计算
我们这里使用Python实现轮廓系数,代码如下:
import pandas as pd
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
from sklearn import metrics
filename = 'data.txt'
beer = pd.read_csv(filename, sep=' ')
features = beer[['calories', 'sodium', 'alcohol', 'cost']]
scaler = StandardScaler()
features = scaler.fit_transform(features)
km1 = KMeans(n_clusters=3)
clf1 = km1.fit(features)
beer['scaled_cluster'] = clf1.labels_
sort_res = beer.sort_values('scaled_cluster')
cluster_centers1 = clf1.cluster_centers_
group_res = beer.groupby('scaled_cluster').mean()
score_scaled = metrics.silhouette_score(features, beer.scaled_cluster)
print(score_scaled)
四,信息检索
信息检索评价是对信息检索系统性能(主要满足用户信息需求的能力)进行评估,与机器学习也有较大的相关性。
总结
上面介绍了非常多的指标,实际应用中需要根据具体问题选择合适的衡量指标。那么具体工作中如何快速使用它们呢?优秀的Python机器学习开源项目Scikit-learn实现了上述绝指标的大多数,使用起来非常方便。
信息检索参考资料(还有一些未补充到):
http://wenku.baidu.com/view/1c6fb7d7b9f3f90f76c61b74.html
http://en.wikipedia.org/wiki/Precision_and_recall
http://www.cnblogs.com/eyeszjwang/articles/2368087.html
https://en.wikipedia.org/wiki/F1_score
还可以参考:
https://www.cnblogs.com/harvey888/p/6964741.html
https://baike.baidu.com/item/%E8%BD%AE%E5%BB%93%E7%B3%BB%E6%95%B0/17361607?fr=aladdin

 浙公网安备 33010602011771号
浙公网安备 33010602011771号