
python 面向对象终极进阶之开发流程
好了,你现在会了面向对象的各种语法了, 但是你会发现很多同学都是学会了面向对象的语法,却依然写不出面向对象的程序,原因是什么呢?原因就是因为你还没掌握一门面向对象设计利器, 此刻有经验的人可能会想到瀑布模型、螺旋模型、迭代开发、敏捷、RUP等一堆软件工程相关的软件开发流程,但对于大部分人来说这些流程仅仅只是项目管理上的流程.
本节我们就来了解下,作为一名程序员基于面向对象开发程序的开发流程:
需求模型->领域模型->设计模型->实现模型
一,需求模型
1. 需求VS功能
需求:客户想要的效果,对客户有价值的事情
功能:系统为了实现客户的价值而提供的能力/功能
举例:
汽车:驾驶是需求,刹车、加速、转弯是功能
打印机:打印是需求,进纸、设定、与电脑连接等是功能
pos机:买单是需求,商品扫描、金额汇总、收银等是功能
2. 需求的重要性
1/3的项目失败或陷入困境是因为需求原因导致的 garbage in,garbage out 垃圾上了生产饼干的流水线,最后产出的是像拉吉一样的饼干
修复需求错误的问题成本极高
1 编码阶段修复发现一个错误耗费人类是1个单位 2 测试阶段修复需求错误的成本是5-10倍 3 维护阶段(产品上线后),修复需求错误成本是20倍 ps:在需求阶段修复错误,成本只需要0.1-0.2即可 结论:需求错了,几乎要把软件项目重做一遍
3. 需求分析的目的
1 记录员,记录客户的需求 2 分析员,和客户一起分析,完善需求 3 引导员,能够引导客户的需求
4. 需求分析的方法
需求分析518方法,简称我要发,具体就是5w1h8c
5w + 1h属于功能属性 8c属于质量属性
5w:
when:用户想在什么时间用,例如半夜备份的任务,很明显我们得知该需求需要自动化执行 where:用户想在什么地方用,例如垃圾桶室内和室外的区别,同样的事物放到不同地方用肯定不一样 who:用户想让谁来用,不仅是人,也可以是一个系统 what:用户想要我们程序的输出结果是什么,如图片,文档,系统 why:问一问用户为什么要这么做,(你不问,他基本不说),包括客户所有觉得不爽的事情 ps:why是核心
1h:how
8c:8个constraint约束
性能performance
性能是系统提供相应服务的效率。主要包括响应时间、吞吐量
性能是很多系统架构设计的关键约束条件之一
例如,同样一个web网站,虽然都是提供信息给用户流量,设计一个日访问量1w的网站与
日访问量10亿的网站,二者的设计截然不同
成本cost
成本指为了实现系统而需要付出的代价
成本也是很多系统架构设计的关键约束之一
例如客户只愿意花100w,而我们却设计了一个耗费1000w的系统
时间time
指客户要求什么时候交付
可靠性reliability
指系统长时间正确运行的能力,银行、证券、电信这些公司,对宕机时间要求很严格
安全security
指对信息安全的保护能力,涉及到钱、身份证、社会保险号等需求对这个要求很高
合规性compliance
指满足各种行业标准、法律法规、规范等,例如3C、SOX、3GPP,ITUT
技术性technology
有的客户可能要求我们采用某种技术
例如客户现在都是windows服务器,要求我们基于windows平台开发
兼容性compatibility
指我们的产品与客户其他已有的产品或系统的兼容能力,要知道现在很少有产品是孤立运行的,
特别是在大企业、大公司中,多个系统都是相互交互、互相配合的。新的系统必须能够和已有
的系统配合,否则将无法运行
5,需求模型之用例的写法
5.1 写用例的技巧
三段法:NEA 1 正常处理(normal):分析正常流程 2 异常处理(exception):分析每一步异常情况和对应的处理 3 替代处理(alternative):分析每一步是否有其他替代方法,以及如何做
5.2用例的书写格式
#1. 用例名称 一般情况下,用例名称即需求名称 #2. 场景 场景即用例发生的环境,正好对应5w中的:when,where,who #3. 用例描述 描述详细的用例内容,对应5w中的what和how 即用户应该怎样做,以及每个步骤中的输出,但不要求每个步骤都有一定的输出,可以有也可以没有,也可以有多个 #4. 用例价值 描述用例对应的客户价值,对应5w中的why #5. 约束和限制 即真个需求流程中相关的约束和限制条件,对应518方法中的8C
5.3 用例编写案例
#用例名
答题系统
#场景:
when:8.10开始
where:西安
who:linux学院,网络客户
#用例描述:
linux学院提供50道题
每个客户无需输入任何个人信息就可以参与答题,随机选择20道题,给客户回答,每道题5分,
3.答题结束后,输入手机号,提交,算总分
60分参与抽奖,<60分赠送基础视频
#用户价值:
答题有奖,答题提交时输入自己的手机号获取成绩,获得潜在客户的联系方式,为后期将客户转成学员做准备
#约束:
暂无
二,领域模型
需求分析阶段不区分面向对象还是面向过程
领域模型是完成从需求分析到面向对象设计的一座桥梁
领域模型定义:
领域模型是对领域内的概念或现实世界中对象的可视化表示, 又称为观念模型,领域对象模型,分析对象模型 它专注于分析问题领域本身,发掘重要的业务领域概念,并建立业务领域概念之间的关系
领域模型主要两个作用:
1 发掘重要的业务领域概念 2 建立业务领域概念之间的关系
归纳领域建模的方法:
1 从用例中找名词(找完后需要删除不是领域对象的名词,具体删除什么, 与不同领域有关,没有统一标准,靠经验) 2 加属性(有些属性并没有在用例中明确给出,靠行业经验自己添加) 3 连关系(画UML图)
三,设计模型
面向对象类设计的具体步骤
第一步:领域类映射(不是全盘拷贝)
类筛选:并不是每个领域类都会出现在软件中
名称映射:对应
属性映射:对应,照搬
提炼方法:领域类中并没有方法,在用例中找动词
第二步:应用设计原则和设计模式
第三步:拆分辅助类(领域类可以在实现阶段拆分为几个类)
四,实现模型
选取一种支持面向对象的语言实现我们的设计,比如c++,java,python
五,答题系统案例
第一步,需求分析(写用例)
#用例名
答题系统
#场景:
when:8.10开始
where:西安
who:linux学院,网络客户
#用例描述:
linux学院提供50道题
每个客户无需输入任何个人信息就可以参与答题,随机选择20道题,给客户回答,每道题5分,
3.答题结束后,输入手机号,提交,算总分
60分参与抽奖,<60分赠送基础视频
#用户价值:
答题有奖,答题提交时输入自己的手机号获取成绩,获得潜在客户的联系方式,为后期将客户转成学员做准备
#约束:
暂无
第二步:领域模型(找名词,加属性,连关系===》出图
2.1 找名词:
找名词: linux学院,题,客户,得分,奖,视频 #筛选:去掉与领域无关的名词。视频应该算作一种奖品 linux学院,题,客户,得分,奖
2.2 加属性:
#加属性 加属性 名词 属性 备注 linux学院 NA 对于答题系统来说,并不需要linux学院的属性,因此在领域模型中,linux学院是没有属性的 题 题目编号,题目类型,题目描述,答题选项,正确答案,分数 客户 客户编号,姓名,性别,年龄,手机号 答题记录 记录编号,客户编号,题目编号列表,总分数,时间 通过答题记录就可以知道用户是谁,以及用户答过的题目 奖品 奖品编号,奖品名字
2.3 连关系:
#连关系:画图
1:答题记录是客户与题的关系类,而客户与奖品之间可以建一个关系类,这样以后单查关系类就可以知道谁得了什么奖品
2:找动词:
创建题目
随机选择题目
答题
提交
算总分
抽奖
2.4 出图
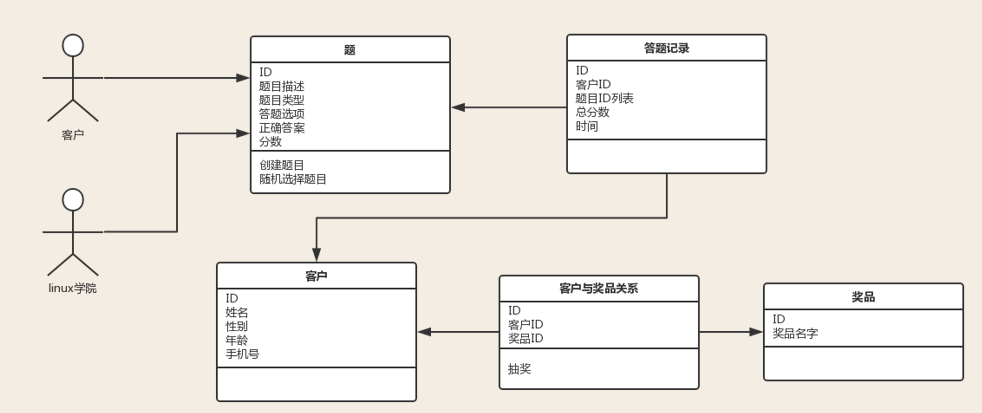
第三步:设计模型
第四步:实现模型
链接: https://pan.baidu.com/s/1jHYFKWI 密码: wimc
六,UML图
主要模型
在UML系统开发中有三个主要的模型:
UML图功能模型
从用户的角度展示系统的功能,包括用例图。
UML图对象模型
采用对象、属性、操作、关联等概念展示系统的结构和基础,包括类图、对象图、包图。
UML图动态模型
展现系统的内部行为。 包括序列图、活动图、状态图。
图的功能
综述
UML是数据库设计过程中,在E-R图(实体-联系图)的设计后的进一步建模。
要了解一下UML设计中有的图例及基本作用。首先对UML中的各个图的功用做一个简单介绍:
用例图
描述角色以及角色与用例之间的连接关系。说明的是谁要使用系统,以及他们使用
该系统可以做些什么。一个用例图包含了多个模型元素,如系统、参与者和用例,
并且显示了这些元素之间的各种关系,如泛化、关联和依赖。
类图
类图是描述系统中的类,以及各个类之间的关系的静态视图。能够让我们在正确编写
代码以前对系统有一个全面的认识。类图是一种模型类型,确切的说,是一种静态模型
类型。类图表示类、接口和它们之间的协作关系。
对象图
与类图极为相似,它是类图的实例,对象图显示类的多个对象实例,而不是实际的类。
它描述的不是类之间的关系,而是对象之间的关系。
包图
包图用于描述系统的分层结构,由包或类组成,表示包与包之间的关系。
活动图
描述用例要求所要进行的活动,以及活动间的约束关系,有利于识别并行活动。
能够演示出系统中哪些地方存在功能,以及这些功能和系统中其他组件的功能如何
共同满足前面使用用例图建模的商务需求。
状态图
描述类的对象所有可能的状态,以及事件发生时状态的转移条件。可以捕获对象、
子系统和系统的生命周期。他们可以告知一个对象可以拥有的状态,并且事件(如消息
的接收、时间的流逝、错误、条件变为真等)会怎么随着时间的推移来影响这些状态。
一个状态图应该连接到所有具有清晰的可标识状态和复杂行为的类;该图可以确定类
的行为,以及该行为如何根据当前的状态变化,也可以展示哪些事件将会改变类的对
象的状态。状态图是对类图的补充。
序列图(顺序图)
序列图是用来显示你的参与者如何以一系列顺序的步骤与系统的对象交互的模型。
顺序图可以用来展示对象之间是如何进行交互的。顺序图将显示的重点放在消息序列上,
即强调消息是如何在对象之间被发送和接收的。
协作图
和序列图相似,显示对象间的动态合作关系。可以看成是类图和顺序图的交集,协作图建
模对象或者角色,以及它们彼此之间是如何通信的。如果强调时间和顺序,则使用序列图;
如果强调上下级关系,则选择协作图;这两种图合称为交互图。
构件图(组件图)
描述代码构件的物理结构以及各种构建之间的依赖关系。用来建模软件的组件及其相互之间
的关系,这些图由构件标记符和构件之间的关系构成。在组件图中,构件是软件单个组成部分,
它可以是一个文件,产品、可执行文件和脚本等。
部署图(配置图)
是用来建模系统的物理部署。例如计算机和设备,以及它们之间是如何连接的。部署图的使
用者是开发人员、系统集成人员和测试人员。部署图用于表示一组物理结点的集合及结点间的
相互关系,从而建立了系统物理层面的模型。
一:这十种模型图各有侧重
1:用例图侧重描述用户需求,
2:类图侧重描述系统具体实现;
二:描述的方面都不相同
1:类图描述的是系统的结构,
2:序列图描述的是系统的行为;
三:抽象的层次也不同
1:构件图描述系统的模块结构,抽象层次较高,
2:类图是描述具体模块的结构,抽象层次一般,
3:对象图描述了具体的模块实现,抽象层次较低。
在有的文献书籍中,将这九种模型图分为三大类:
结构分类、动态行为和模型管理:
1:结构分类包括用例图、类图、对象图、构件图和部署图,
2:动态行为包括状态图、活动图、顺序图和协作图,
3:模型管理则包含类图。
类图中通过加号(+)来表示 public 通过减号(-)表示 private 通过井号(#)表示 protected
七,作业练习
详细请看:http://www.cnblogs.com/wj-1314/p/8707772.html
八,面向对象原则:高内聚,低耦合
软件设计中通常用耦合度和内聚度作为衡量模块独立程度的标准,划分模块的一个准则就是高内聚低耦合。
这是软件工程中的概念,是判断设计好坏的标准,主要是面向OO的设计,主要是看类的内聚性是否高,耦合度是否低。
每一个类完成特定的独立的功能,这就是高内聚,耦合就是类之间的互相调用关系,如果耦合很强,互相牵扯调用很多,那么会牵一发而动全身,不利于维护和扩展。
类之间的设置应该要低耦合,但是每个类要高内聚,耦合就是类之间相互依赖的尺度,如果每个对象都有引用其他所有的对象,那么就有高耦合,这是不合乎要求的,因为在两个对象之间,潜在性地流动了太多的信息,低耦合是合乎要求的:它意味着对象彼此之间更独立的工作,低耦合最小化了修改一个类而导致也要修改其他类的“连锁反应”。内聚是一个类中变量与方法连接强度的尺度.高内聚是值得要的,因为它意味着类可以更好地执行一项工作.低内聚是不好的,因为它表明类中的元素之间很少相关.成分之间相互有关联的模块是合乎要求的.每个方法也应该高内聚.大多数的方法只执行一个功能.不要在方法中添加’额外’的指令,这样会导致方法执行更多的函数.
什么是耦合
耦合性也称块间联系。指软件系统结构中各模块间相互联系紧密程度的一种度量。模块之间联系越紧密,其耦合性就越强,模块的独立性则越差。模块间耦合高低取决于模块间接口的复杂性、调用的方式及传递的信息。
耦合度就是某模块(类)与其它模块(类)之间的关联、感知和依赖的程度,是衡量代码独立性的一个指标,也是软件工程设计及编码质量评价的一个标准。耦合的强度依赖于以下几个因素:
- (1)一个模块对另一个模块的调用;
- (2)一个模块向另一个模块传递的数据量;
- (3)一个模块施加到另一个模块的控制的多少;
- (4)模块之间接口的复杂程度。
耦合分类
耦合按从强到弱的顺序可分为以下几种类型:
a)非直接耦合:两模块间没有直接关系,之间的联系完全是通过主模块的控制和调用来实现的
b)数据耦合:指两个模块之间有调用关系,传递的是简单的数据值,相当于高级语言的值传递;
c)标记耦合:指两个模块之间传递的是数据结构,如高级语言中的数组名、记录名、文件名等这些名字即标记,其实传递的是这个数据结构的地址;
d)控制耦合:一指一个模块调用另一个模块时,传递的是控制变量(如开关、标志等),被调模块通过该控制变量的值有选择地执行块内某一功能;
e)外部耦合:一组模块都访问同一全局简单变量而不是同一全局数据结构,而且不是通过参数传递该全局变量的信息
f)公共耦合:一组模块都访问同一个公共数
据环境。该公共数据环境可以是全局数据结构、共享的通信区、内存的公共覆盖区等。
g)内容耦合:这是最高程度的耦合,也是最差的耦合。当一个模块直接使用另一个模块的内部数据,或通过非正常入口而转入另一个模块内部。
为什么要低耦合(解耦合)
在面向对象编程中,对象自身是内聚的,是保管好自己的数据,完成好自己的操作的,而对外界呈现出自己的状态和行为。但是,没有绝对的自力更生,对外开放也是必要的!一个对象,往往需要跟其他对象打交道,既包括获知其他对象的状态,也包括仰赖其他对象的行为,而一旦这样的事情发生时,我们便称该对象依赖于另一对象。只要两个对象之间存在一方依赖一方的关系,那么我们就称这两个对象之间存在耦合。 比如妈妈和baby,妈妈要随时关注baby的睡、醒、困、哭、尿等等状态,baby则要仰赖妈妈的喂奶、哄睡、换纸尿裤等行为,从程序的意义上说,二者互相依赖,因此也存在耦合。首先要说,耦合是必要的。
耦合的程度就是耦合度,也就是双方依赖的程度。上文所说的妈妈和baby就是强耦合。而你跟快递小哥之间则是弱耦合。一般来说耦合度过高并不是一件好事。就拿作为IT精英的你来说吧,上级随时敦促你的工作进度,新手频繁地需要你指导问题,隔三差五还需要参加酒局饭局,然后还要天天看领导的脸色、关注老婆的心情,然后你还要关注代码中的bug 、bug、bug,和需求的变化、变化、变化,都够焦头烂额了,还猝不及防的要关注眼睛、颈椎、前列腺和头发的状态,然后你再炒个股,这些加起来大概就是个强耦合了。从某种意义上来说,耦合天生就与自由为敌,无论是其他对象依赖于你,还是你依赖其他对象。比如有人嗜烟、酗酒,你有多依赖它们就有多不自由;比如有人家里生了七八个娃,还有年迈的父母、岳父母,他们有多依赖你,你就有多不自由。所以老子这样讲:“五音令人耳聋,五色令人目盲,驰骋狩猎令人心发狂,难得之货令人行妨。”卢梭也是不无悲凉的说“人生而自由,却又无往而不在枷锁中”。因此,要想自由,就必须要降低耦合,而这个过程就叫做解耦和。
耦合度很高的情况下,维护代码时修改一个地方会牵连到很多地方,如果修改时没有理清这些耦合关系,那么带来的后果
可能会是灾难性的,特别是对于需求变化较多以及多人协作开发维护的项目,修改一个地方会引起本来已经运行稳定的模块错误,严重时会导致恶性循环,问题永远改不完,开发和测试都在各种问题之间奔波劳累,最后导致项目延期,用户满意度降低,成本也增加了,这对用户和开发商影响都是很恶劣的,各种风险也就不言而喻了。
如何降低耦合(解耦合)
- 少使用类的继承,多用接口隐藏实现的细节。 Java面向对象编程引入接口除了支持多态外, 隐藏实现细节也是其中一个目的。
- 模块的功能化分尽可能的单一,道理也很简单,功能单一的模块供其它模块调用的机会就少。(其实这是高内聚的一种说法,高内聚低耦合一般同时出现,为了限制篇幅,我们将在以后的版期中讨论)。
- 遵循一个定义只在一个地方出现。
- 少使用全局变量。
- 类属性和方法的声明少用public,多用private关键字,
- 多用设计模式,比如采用MVC的设计模式就可以降低界面与业务逻辑的耦合度。
- 尽量不用“硬编码”的方式写程序,同时也尽量避免直接用SQL语句操作数据库。
- 最后当然就是避免直接操作或调用其它模块或类(内容耦合);如果模块间必须存在耦合,原则上尽量使用数据耦合,少用控制耦合,
- 限制公共耦合的范围,避免使用内容耦合。
什么是内聚
内聚,通俗的来讲,就是自己的东西自己保管,自己的事情自己做。每个模块尽可能独立完成自己的功能,不依赖于模块外部的代码。
对象是什么?对象就是保管好自己的东西,做好自己的事情的程序模块——这就是内聚!当然,对象的内聚只是内聚的一个层次,在不同的尺度下其实都有内聚的要求,比如方法也要讲内聚,架构也要讲内聚。
内聚: 内聚性又称块内联系。指模块的功能强度的度量,即一个模块内部各个元素彼此结合的紧密程度的度量。若一个模块内各元素(语名之间、程序段之间)联系的越紧密,则它的内聚性就越高。
高内聚:类与类之间的关系而定,高,意思是他们之间的关系要简单,明了,不要有很强的关系,不然,运行起来就会出问题。一个类的运行影响到其他的类。由于高内聚具备鲁棒性,可靠性,可重用性,可读性等优点,模块设计推荐采用高内聚。
内聚度是指内部各元素之间联系的紧密程度,模块的内聚种类通常可分为7种,按其内聚度从低
到高的次序依此为:偶然内聚、逻辑内聚、瞬时内聚、过程内聚、通信内聚、顺序内聚、功能内聚。
- 1 偶然内聚: 指一个模块内的各处理元素之间没有任何联系。
- 2 逻辑内聚: 指模块内执行几个逻辑上相似的功能,通过参数确定该模块完成哪一个功能。
- 3 时间内聚: 把需要同时执行的动作组合在一起形成的模块为时间内聚模块。
- 4 通信内聚: 指模块内所有处理元素都在同一个数据结构上操作(有时称之为信息内聚),或者指各处理使用相同的输入数据或者产生相同的输出数据。
- 5 顺序内聚: 指一个模块中各个处理元素都密切相关于同一功能且必须顺序执行,前一功能元素输出就是下一功能元素的输入。
- 6 功能内聚: 这是最强的内聚,指模块内所有元素共同完成一个功能,缺一不可。与其他模块的耦合是最弱的。

