
卷积神经网络学习笔记——SENet
完整代码及其数据,请移步小编的GitHub地址
传送门:请点击我
如果点击有误:https://github.com/LeBron-Jian/DeepLearningNote
这里结合网络的资料和SENet论文,捋一遍SENet,基本代码和图片都是来自网络,这里表示感谢,参考链接均在后文。下面开始。
SENet论文写的很好,有想法的可以去看一下,我这里提供翻译地址:
深度学*论文翻译解析(十六):Squeeze-and-Excitation Networks
在深度学*领域,CNN分类网络的发展对其他计算机视觉任务如目标检测和语义分割都起到至关重要的作用(检测和分割模型通常都是构建在 CNN 分类网络之上)。提到CNN分类网络,我们之前已经学*了 AlexNet,VGGNet,InceptionNet,ResNet,DenseNet等,他们的效果已经被充分验证,而且被广泛的应用在各类计算机视觉任务上。这里我们再学*一个网络(SENet),SENet 以极大的优势获得了最后一届 ImageNet 2017 竞赛 Image Classification 任务的冠军,和ResNet的出现类似,都很大程度上减少了之前模型的错误率,并且复杂度低,新增参数和计算量小。下面就来具体学*一下SENet。
1,SENet 简介
SENet的全称是Squeeze-and-Excitation Networks,中文可以翻译为压缩和激励网络。 Squeeze-and-Excitation(SE) block 并不是一个完整的网络结构,而是一个子结构,可以嵌到其他分类或检测模型中,作者采用 SENet block 和 ResNeXt结合在 ILSVRC 2017 的分类项目中拿到第一,在ImageNet数据集上将 top-5 error 降低到 2.251%,原先的最好成绩是 2.991%。
作者在文中将 SENet block 插入到现有的多种分类网络中,都取得了不错的效果。SENet的核心思想在于通过网络根据 loss 去学*特征权重,使得有效的 feature map 权重大,无效或效果小的 feature map 权重小的方式训练 模型达到更好的结果。当然,SE block 嵌入在原有的一些分类网络中不可避免地增加了一些参数和计算量,但是在效果面前还是可以接受的。
也许通过给某一层特征配备权重的想法很多人都有,那为什么只有 SENet 成功了? 个人认为主要原因在于权重具体怎么训练得到。就像有些是直接根据 feature map 的数值分布来判断;有些可能也利用了loss来指导权重的训练,不过全局信息该怎么获取和利用也是因人而已。
2,SENet的主体思路
2.1 中心思想
对于CNN网络来说,其核心计算是卷积算子,其通过卷积核从输入特征图学*到新特征图。从本质上讲,卷积是对一个局部区域进行特征融合,这包括空间上(W和H维度)以及通道间(C 维度)的特征融合,而对于卷积操作,很大一部分工作是提高感受野,即空间上融合更多特征,或者是提取多尺度空间信息,而SENet网络的创新点在于关注 channel 之间的关系,希望模型可以自动学*到不同 channel 特征的重要程度。为此,SENet 提出了 Squeeze-and-Excitation(SE)模块。
中心思想:对于每个输出 channel,预测一个常数权重,对每个 channel 加权一下,本质上,SE模块是在 channel 维度上做 attention 或者 gating 操作,这种注意力机制让模型可以更加关注信息量最大的 channel 特征,而抑制那些不重要的 channel 特征。SENet 一个很大的优点就是可以很方便地集成到现有网络中,提升网络性能,并且代价很小。
如下就是 SENet的基本结构:
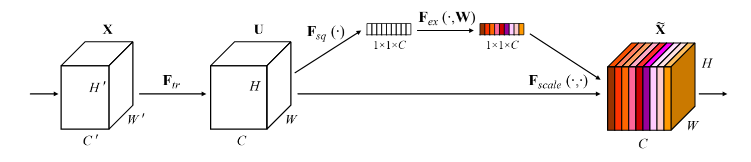
原来的任意变换,将输入 X 变为输出 U,每个通道的重要程度不同,有的通道更有用,有的通道则不太有用。
对于每一输出通道,先 global average pool,每个通道得到 1个标量,C个通道得到C个数,然后经过 FC-ReLU-FC-Sigmoid 得到 C个0~1 之间的标量,作为通道的加权,然后原来的输出通道每个通道用对应的权重进行加权(对应通道的每个元素与权重分别相乘),得到新的加权后的特征,作者称为 feature recalibration。
第一步每个通道 H*W 个数全局平均池化得到一个标量,称之为 Squeeze,然后两个 FC得到0~1之间的一个权重值,对原始的每个 H*W 的每个元素乘以对应通道的权重,得到新的 feature map ,称之为 Excitation。任意的原始网络结构,都可以通过这个 Squeeze-Excitation的方式进行 feature recalibration,采用了改方式的网络,即 SENet版本。
上面的模块很通用,也可以很容易的和现有网络集成,得到对应的 SENet版本,提升现有网络性能,SENet泛指所有的采用了上述结构地网络。另外,SENet也可以特指作者 ILSVRC 2017夺冠中采用的 SE-ResNeXt-152(64*4d)。
SENet和ResNet很相似,但比ResNet做的更多,ResNet只是增加了一个 skip connection,而SENet在相邻两层之间加入了处理,使得 channel 之间的信息交互称为可能,进一步提高了网络的准确率。

我们从最基本的卷积操作开始学*。*些年来,卷积神经网络在很多领域上都取得了巨大的突破。而卷积核作为卷积神经网络的核心,通常被看作是在局部感受野上,将空间上(Spatial)的信息和特征维度上(channel-wise)的信息进行聚合的信息聚合体。卷积神经网络由一系列卷积层,非线性层和下采样层构成,这样他们能够从全局感受野上去捕获图像的特征来进行图像的描述。
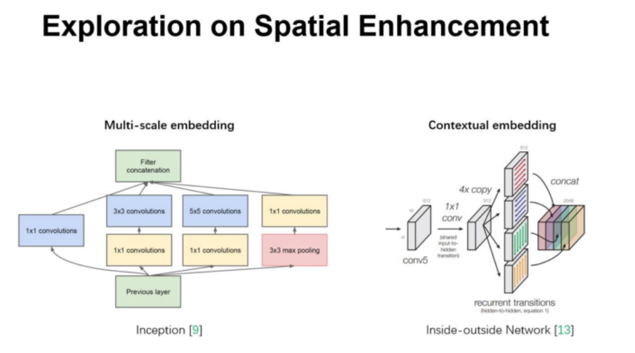
然而去学到一个性能非常强劲的网络是相当困难的,其难点来自于很多方面。最*很多工作被提出来从空间维度层面来提升网络的性能,如 Inception 结构中嵌入了多尺度信息,聚合多种不同感受野上的特征来获得性能增益;在 Inside-Outside 网络中考虑了空间中的上下文信息;还有将 Attention 机制引入到空间维度上等等。这些工作都获得了相当不错的成果。

我们可以看到,已经有很多工作在空间维度上来提升网络的性能。那么很自然的想到,网络是否可以从其他层面来考虑去提升性能,比如考虑特征通道之间的关系?我们的工作就是基于这一点并提出了 Squeeze-and-Excitation Networks(简称:SENet)。在我们提出的结构中,Squeeze和Excitation 是两个非常关键的操作,所以我们以此来命名。我们的动机是希望显式的建模特征通道之间的相互依赖关系。另外,我们并不打算引入一个新的空间维度来进行特征通道间的融合,而是采用了一种全新的“特征重标定”策略。具体来说,就是通过学*的方式来自动获取到每个特征通道的重要程度,然后依照这个重要程度去提升有用的特征并抑制对当前任务用处不大的特征。
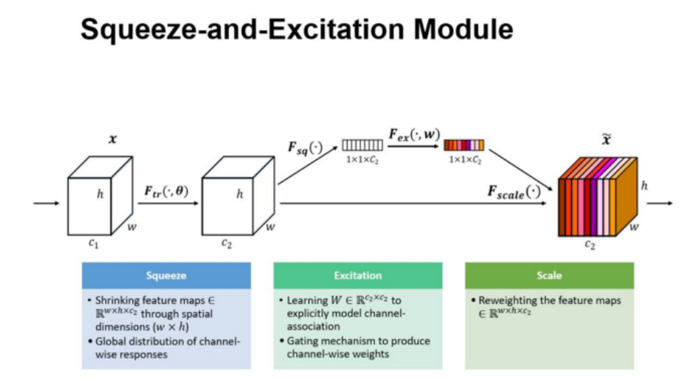
上图是我们提出的 SE 模块的示意图。给定一个输入 x,其特征通道数为c1,通过一系列卷积等一般变换后得到一个特征通道数为 c2 的特征。与传统的CNN不一样的是,接下来我们通过三个操作来重标定前面得到的特征。
2.2 SE模块
SE模块主要包含 Squeeze 和 Excitation 两个操作,可以适用于任何映射:
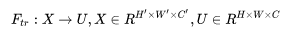 以卷积为例,卷积核为 V=[v1, v2, .... vn],其中 Vc 表示第 c 个卷积核,那么输出 u=[u1, u2,...,uc]为:
以卷积为例,卷积核为 V=[v1, v2, .... vn],其中 Vc 表示第 c 个卷积核,那么输出 u=[u1, u2,...,uc]为:
 其中 * 代表卷积操作,而 Vcs 代表一个 3D卷积核,其输入一个 channel 上的空间特征,它学*特征空间关系,但是由于对各个 channel 的卷积结果做了 sum,所以 channel 特征关系与卷积核学*到的空间关系混合在一起。而SE模块就是为了抽离这种混杂,使得模型直接学*到 channel 特征关系。
其中 * 代表卷积操作,而 Vcs 代表一个 3D卷积核,其输入一个 channel 上的空间特征,它学*特征空间关系,但是由于对各个 channel 的卷积结果做了 sum,所以 channel 特征关系与卷积核学*到的空间关系混合在一起。而SE模块就是为了抽离这种混杂,使得模型直接学*到 channel 特征关系。
2.3 Squeeze操作
首先是 Squeeze 操作,我们顺着空间维度来进行特征压缩,原始 feature map 的维度为 H*W*C,其中H是高度(height), W 是宽度(Width), C是通道数(Channel)。Squeeze做的事情是把 H*W*C 压缩为1*1*C,相当于将每个二维的特征通道(即H*W)变成一个实数(即变为一维了),实际中一般是用 global average pooling 实现的。H*W 压缩成一维后,相当于这一维度获得了之前H*W全局的视野,感受野区域更广,所以这个实数某种程度上具有全局的感受野,并且输出的维度和输入的特征通道数相匹配。它表征着在特征通道上响应的全局分布,而且使得靠*输入的层也可以获得全局的感受野,这一点在很多任务中都是非常有用的。
由于卷积只是在一个局部空间内进行操作, U 很难获得足够的信息来提取 channel 之间的关系,对于网络中前面的层这更严重,因为感受野比较小。为此SENet 提出了 Squeeze操作,将一个 channel 上整个空间特征编码为一个全局特征,采用 global average pooling 来实现(原则上也可以采用更复杂的 聚合策略):
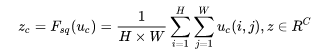
2.4 Excitation 操作
其次是 Excitation 操作,它是一个类似于循环神经网络中门的机制。通过参数 w 来为每个特征通道生成权重,其中参数 w 被学*用来显式的建模特征通道间的相关性。得到Squeeze 的 1*1*C 的表示后,加入一个 FC 全连接层(Fully Connected),对每个通道的重要性进行预测,得到不同 channel的重要性大小后再作用(激励)到之前的 feature map 的对应 channel上,再进行后续操作。
Sequeeze操作得到了全局描述特征,我们接下来需要另外一种运算来抓取 channel 之间的关系。这个操作需要满足两个准则:首先要灵活,它要可以学*到各个 channel之间的非线性关系;第二点是学*的关系不是互斥的,因为这里允许多 channel 特征,而不是 one-hot 形式。基于此,这里采用了 Sigmoid形式的 gating 机制:
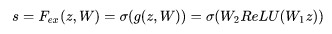
其中:
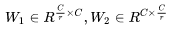
为了降低模型复杂度以及提升泛化能力,这里采用包含两个全连接层的 bottleneck结构,其中第一个 FC 层起到降维的作用,降维系数为 r 是个超参数,然后采用 ReLU激活。最后的 FC层恢复原始的维度。
最后将学*到的各个 channel的激活值(Sigmoid激活,值0~1)乘以 U 上的原始特征:
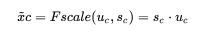
其中整个操作可以看成学*到了各个channel的权重系数,从而使得模型对各个 channel 的特征更有辨识能力,这应该也算是一种 attention机制。
最后一个是 Reweight 的操作,我们将 Excitation 的输出的权重看做是进过特征选择后的每个特征通道的重要性,然后通过乘法逐通道加权到先前的特征上,完成在通道维度上的对原始特征的重标定。
3,SE模块的应用
3.1 SE模块在 Inception 和 ResNet 上的应用
SE模块的灵活性在于它可以直接应用现有的网络结构中。这里以 Inception和ResNet为例。对于 Inception网络,没有残差网络,这里对整个Inception模块应用SE模块。对于ResNet,SE模块嵌入到残差结构中的残差学*分支中,具体如下图所示:
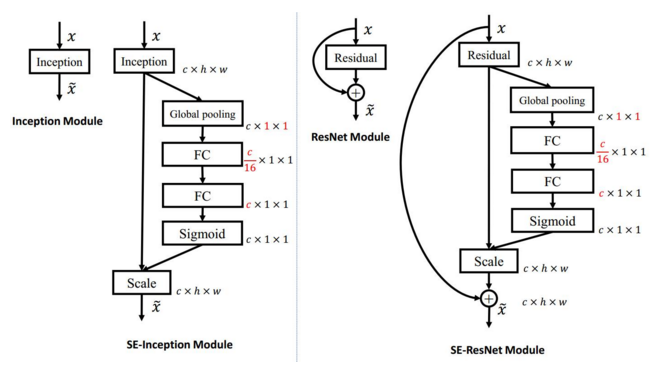
上左图是将 SE 模块嵌入到 Inception 结构的一个示例。方框旁边的维度信息代表该层的输出。
这里我们使用 global average pooling 作为 Squeeze 操作。紧接着两个 Fully Connected 层组成一个 Bottleneck 结构去建模通道间的相关性,并输出和输入特征同样数目的权重。我们首先将特征维度降低到输入的 1/16,然后经过 ReLU 激活后再通过一个 Fully Connected 层升回到原来的维度。这样做比直接用一个 Fully Connected 层的好处在于:1)具有更多的非线性,可以更好地拟合通道间复杂的相关性;2)极大地减少了参数量和计算量。然后通过一个 Sigmoid 的门获得 0~1 之间归一化的权重,最后通过一个 Scale 的操作来将归一化后的权重加权到每个通道的特殊上。
除此之外,SE模块还可以嵌入到含有 skip-connections 的模块中。上右图是将 SE嵌入到 ResNet模块中的一个例子,操作过程基本和 SE-Inception 一样,只不过是在 Addition前对分支上 Residual 的特征进行了特征重标定。如果对 Addition 后主支上的特征进行重标定,由于在主干上存在 0~1 的 scale 操作,在网络较深 BP优化时就会在靠*输入层容易出现梯度消散的情况,导致模型难以优化。
目前大多数的主流网络都是基于这两种类似的单元通过 repeat 方式叠加来构造的。由此可见,SE模块可以嵌入到现在几乎所有的网络结构中。通过在原始网络结构的 building block 单元中嵌入 SE模块,我们可以获得不同种类的 SENet。如SE-BN-Inception,SE-ResNet,SE-ReNeXt,SE-Inception-ResNet-v2等等。


从上面的介绍中可以发现,SENet构造非常简单,而且很容易被部署,不需要引入新的函数或者层。除此之外,它还在模型和计算复杂度上具有良好的特性。拿 ResNet-50 和 SE-ResNet-50 对比举例来说,SE-ResNet-50 相对于 ResNet-50有着 10% 模型参数的增长。额外的模型参数都存在于 Bottleneck 设计的两个 Fully Connected 中,由于 ResNet 结构中最后一个 stage 的特征通道数目为 2048,导致模型参数有着较大的增长,实现发现移除掉最后一个 stage 中 3个 build block 上的 SE设定,可以将 10%参数量的增长减少到 2%。此时模型的精度几乎无损失。
另外,由于在现有的 GPU 实现中,都没有对 global pooling 和较小计算量的 Fully Connected 进行优化,这导致了在 GPU 上的运行时间 SE-ResNet-50 相对于 ResNet-50 有着约 10% 的增长。尽管如此,其理论增长的额外计算量仅仅不到1%,这与其在 CPU 运行时间上的增长相匹配(~2%)。可以看出,在现有网络架构中嵌入 SE 模块而导致额外的参数和计算量的增长微乎其微。
增加了SE模块后,模型参数以及计算量都会增加,下面以SE-ResNet-50为例,对模型参数增加量为:
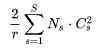
其中 r 为降维系数,S表示 stage数量,Cs 为第 s 个 stage的通道数,Ns 为第 s 个 stage的重复 block量。当 r=16时,SE-ResNet-50只增加了约 10%的参数量,但是计算量(GFLOPS)却增加不到 1%。
3.2 SE模块在ResNet网络上的模型效果
SE模块很容易嵌入到其他网络中,作者为了验证 SE模块的作用,在其他流行网络如 ResNet和VGG中引入 SE模块,测试其在 ImageNet 上的效果。

在训练中,我们使用了一些常见的数据增强方法和 Li Shen 提出的均衡数据策略。为了提高训练效率,我们使用了我们自己优化的分布式训练系统 ROCS,并采用了更大的 batch-size 和初始学*率。所有的模型都是从头开始训练的。

接下来,为了验证SENets 的有效性,我们将在 ImageNet 数据集上进行实验,并从两个方面来进行论证。一个是性能的增益 vs 网络的深度;另一个是将 SE 嵌入到现有的不同网络中进行结果对比。另外,我们也会展示在 ImageNet 竞赛中的结果。
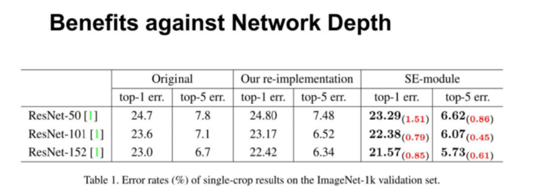
首先,我们来看一下网络的深度对SE的影响。上表分别展示了 ResNet-50,ResNet-101,ResNet-152和嵌入SE模型的结果。第一栏 Original 是原作者实现的记过,为了公平的比较,我们在ROCS 上重新进行了实验得到了 Our re-implementation 的结果(PS:我们冲实现的精度往往比原paper中要高一些)。最后一栏 SE-module 是指嵌入了 SE模块的结果,它的训练参数和第二栏 Our re-implementation 一致。括号中的红色数值是指相对于 Our re-implementation 的精度提升的幅值。
从上表可以看出,SE-ResNets 在各种深度上都远远超过其对应的没有 SE 的结构版本的精度,这说明无论网络的深度如何,SE模块都能够给网络带来性能上的增益。值得一提的是,SE-ResNet-50 可以达到和 ResNet-101 一样的精度;更甚,SE-ResNet-101 远远地超过了更深的 ResNet-152。

上图展示了 ResNet-50 和 ResNet-152 以及他们对应的嵌入 SE模块的网络在 ImageNet 上的训练过程,可以明显的看出加入了 SE 模块的网络收敛到更低的错误率上。
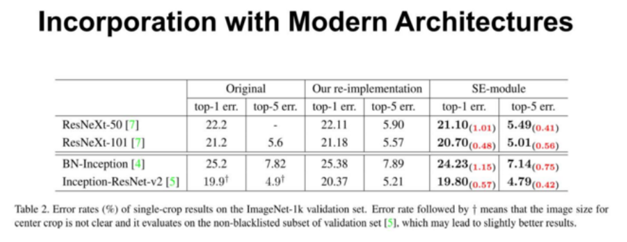
另外,为了验证 SE模块的泛化能力,我们也在除 ResNet之外的结构上进行了实验。从上表可以看出,将 SE模块嵌入到 ResNeXt,BN-Inception,Inception-ResNet-v2 上均获得了不菲的增益效果。由此看出,SE的增益效果不仅仅局限于某些特殊的网络结构,它具有很强的泛化性。

上图展示的是 SE 嵌入在 ResNeXt-50 和 Inception-ResNet-v2 的训练过程对比。
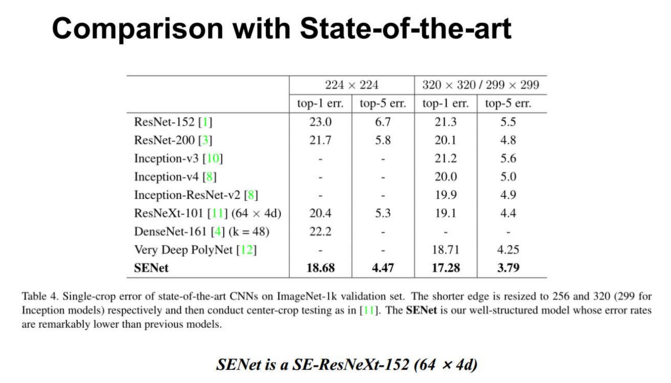
在上表中我们列出了一些最新的在 ImageNet 分类上的网络的结果。其中我们的 SENet 实质上是一个 SE-ResNeXt-152(64*4d),在ResNeXt-152 上嵌入 SE模块,并作出一些其他修改和训练优化上的小技巧,这些我们会在后面介绍。
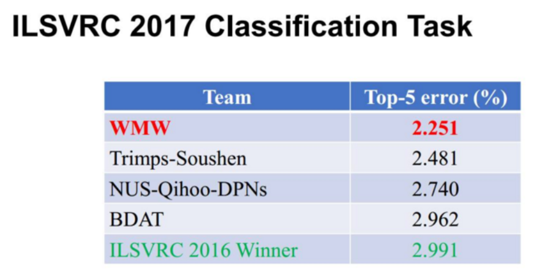
最后,在 ILSVRC 2017 竞赛中,我们的融合模型在测试集上获得了 2.251~ top-5 错误率。对比于去年第一名的结果 2.991%,我们获得了将* 25% 的精度提升。
4,总结
1,SE模块主要为了提升模型对 channel 特征的敏感性,这个模块是轻量级的,而且可以应用在现有的网络结构中,只需要增加较少的计算量就可以带来性能的提升。
2,提升很大,并且代价很小,通过对通道进行加权,强调有效信息,抑制无效信息,注意力机制,并且是一个通用的方法,应该在 Inception,Inception-ResNet, ResNeXt, ResNet 都能有所提升,适用范围很广。
3,思路很清晰简洁,实现很简单,用起来也很方便,各种试验都证明了其有效性,各种任务都可以尝试一下,效果应该不会太差。
5,Keras 实现 SENet
5.1 Keras 实现SE-Inception Net
首先,先看SE-Inception Net架构的原理图:
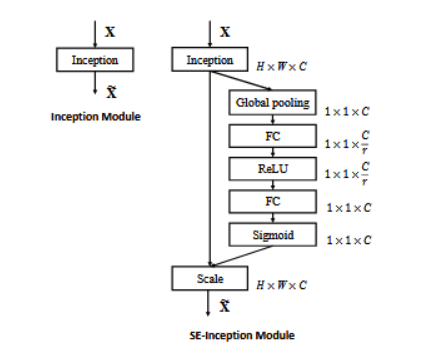
图中是将SE模块嵌入到Inception结构的一个示例。方框旁边的维度信息代表该层的输出。这里我们使用 global average pooling 作为 Squeeze 操作。紧接着两个 Fully Connected 层组成一个 Bottleneck 结构去建模通道间的相关性,并输出和输入特征同样数目的权重。
我们首先将特征维度降低到输入的 1/16,然后经过 ReLU 激活后再通过一个 Fully Connected 层升回到原来的维度。这样做比直接用一个 Fully Connected层的好处在于:
- 1,具有更多的非线性,可以更好地拟合通道间复杂的相关性
- 2,极大地减少了参数量和计算量。然后通过一个 Sigmoid的门获得 0~1 之间归一化的权重,最后通过一个 Scale的操作来将归一化后的权重加权到每个通道的特征上。
代码如下(这里 r = 16):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | def build_SE_model(nb_classes, input_shape=(256, 256, 3)): inputs_dim = Input(input_shape) x = Inception(include_top=False, weights='imagenet', input_shape=None, pooling=max)(inputs_dim) squeeze = GlobalAveragePooling2D()(x) excitation = Dense(units=2048//16)(squeeze) excitation = Activation('relu')(excitation) excitation = Dense(units=2048)(excitation) excitation = Activation('sigmoid')(excitation) excitation = Reshape((1, 1, 2048))(excitation) scale = multiply([x, excitation]) x = GlobalAveragePooling2D()(scale) dp_1 = Dropout(0.3)(x) fc2 = Dense(nb_classes)(dp_1) # 此处注意,为Sigmoid函数 fc2 = Activation('sigmoid')(fc2) model = Model(inputs=inputs_dim, outputs=fc2) return modelif __name__ == '__main__': model =build_model(nb_classes, input_shape=(im_size1, im_size2, channels)) opt = Adam(lr=2*1e-5) model.compile(optimizer=opt, loss='categorical_crossentropy', metrics=['accuracy']) model.fit() |
注意:
1,multiply([x, excitation]) 中的 x 的 shape 为(10, 10, 2048),Excitation 的 shape 为(1, 1, 2048) ,应保持他们的最后一维即 2048 相同。例如:如果用 DenseNet201,它的最后一层卷积出来的结果为(8, 8, 1920)(不包括全连接层),Excitation的 Reshape为(1, 1, 1920)。
2, fc2 = Activation('sigmoid')(fc2) ,此处注意,为Sigmoid函数。
5.2 Keras 实现SE-ResNeXt Net
下面看一下 SEResNet 架构图:

ResNeXt是 ResNet的改进版本。这里参考了网友实现的 ResNeXt,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 | from __future__ import print_functionfrom __future__ import absolute_importimport warningsimport numpy as npfrom keras.models import Modelfrom keras.layers import Inputfrom keras.layers import Lambdafrom keras.layers import Reshapefrom keras.layers import Conv2Dfrom keras.layers import Activationfrom keras.layers import AveragePooling2Dfrom keras.layers import GlobalAveragePooling2Dfrom keras.layers import BatchNormalizationfrom keras.layers import Densefrom keras.layers import Concatenate, concatenatefrom keras.layers import Add, addfrom keras.layers import Multiply, multiplyfrom keras import backend as Kclass SEResNeXt(object): def __init__(self, size=96, num_classes=10, depth=64, reduction_ratio=4, num_split=8, num_block=3): self.depth = depth # number of channels self.ratio = reduction_ratio # ratio of channel reduction in SE module self.num_split = num_split # number of splitting trees for ResNeXt (so called cardinality) self.num_block = num_block # number of residual blocks if K.image_data_format() == 'channels_first': self.channel_axis = 1 else: self.channel_axis = 3 self.model = self.build_model(Input(shape=(size,size,3)), num_classes) def conv_bn(self, x, filters, kernel_size, stride, padding='same'): ''' Combination of Conv and BN layers since these always appear together. ''' x = Conv2D(filters=filters, kernel_size=[kernel_size, kernel_size], strides=[stride, stride], padding=padding)(x) x = BatchNormalization()(x) return x def activation(self, x, func='relu'): ''' Activation layer. ''' return Activation(func)(x) def channel_zeropad(self, x): ''' Zero-padding for channle dimensions. Note that padded channles are added like (Batch, H, W, 2/x + x + 2/x). ''' shape = list(x.shape) y = K.zeros_like(x) if self.channel_axis == 3: y = y[:, :, :, :shape[self.channel_axis] // 2] else: y = y[:, :shape[self.channel_axis] // 2, :, :] return concatenate([y, x, y], self.channel_axis) def channel_zeropad_output(self, input_shape): ''' Function for setting a channel dimension for zero padding. ''' shape = list(input_shape) shape[self.channel_axis] *= 2 return tuple(shape) def initial_layer(self, inputs): ''' Initial layers includes {conv, BN, relu}. ''' x = self.conv_bn(inputs, self.depth, 3, 1) x = self.activation(x) return x def transform_layer(self, x, stride): ''' Transform layer has 2 {conv, BN, relu}. ''' x = self.conv_bn(x, self.depth, 1, 1) x = self.activation(x) x = self.conv_bn(x, self.depth, 3, stride) x = self.activation(x) return x def split_layer(self, x, stride): ''' Parallel operation of transform layers for ResNeXt structure. ''' splitted_branches = list() for i in range(self.num_split): branch = self.transform_layer(x, stride) splitted_branches.append(branch) return concatenate(splitted_branches, axis=self.channel_axis) def squeeze_excitation_layer(self, x, out_dim): ''' SE module performs inter-channel weighting. ''' squeeze = GlobalAveragePooling2D()(x) excitation = Dense(units=out_dim // self.ratio)(squeeze) excitation = self.activation(excitation) excitation = Dense(units=out_dim)(excitation) excitation = self.activation(excitation, 'sigmoid') excitation = Reshape((1,1,out_dim))(excitation) scale = multiply([x,excitation]) return scale def residual_layer(self, x, out_dim): ''' Residual block. ''' for i in range(self.num_block): input_dim = int(np.shape(x)[-1]) if input_dim * 2 == out_dim: flag = True stride = 2 else: flag = False stride = 1 subway_x = self.split_layer(x, stride) subway_x = self.conv_bn(subway_x, out_dim, 1, 1) subway_x = self.squeeze_excitation_layer(subway_x, out_dim) if flag: pad_x = AveragePooling2D(pool_size=(2,2), strides=(2,2), padding='same')(x) pad_x = Lambda(self.channel_zeropad, output_shape=self.channel_zeropad_output)(pad_x) else: pad_x = x x = self.activation(add([pad_x, subway_x])) return x def build_model(self, inputs, num_classes): ''' Build a SENet model. ''' x = self.initial_layer(inputs) x = self.residual_layer(x, out_dim=64) x = self.residual_layer(x, out_dim=128) x = self.residual_layer(x, out_dim=256) x = GlobalAveragePooling2D()(x) x = Dense(units=num_classes, activation='softmax')(x) return Model(inputs, x) |
6,SE模块的 Pytorch实现
SE模块是非常简单的,实现起来也比较容易,这里给出Pytorch版本的实现(地址:https://zhuanlan.zhihu.com/p/65459972/)。
代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | class SELayer(nn.Module): def __init__(self, channel, reduction=16): super(SELayer, self).__init__() self.avg_pool = nn.AdaptiveAvgPool2d(1) self.fc = nn.Sequential( nn.Linear(channel, channel // reduction, bias=False), nn.ReLU(inplace=True), nn.Linear(channel // reduction, channel, bias=False), nn.Sigmoid() ) def forward(self, x): b, c, _, _ = x.size() y = self.avg_pool(x).view(b, c) y = self.fc(y).view(b, c, 1, 1) return x * y.expand_as(x) |
对于SE-ResNet模型,只需要将SE模块加入到残差单元就可以:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 | class SEBottleneck(nn.Module): expansion = 4 def __init__(self, inplanes, planes, stride=1, downsample=None, reduction=16): super(SEBottleneck, self).__init__() self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False) self.bn1 = nn.BatchNorm2d(planes) self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride, padding=1, bias=False) self.bn2 = nn.BatchNorm2d(planes) self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False) self.bn3 = nn.BatchNorm2d(planes * 4) self.relu = nn.ReLU(inplace=True) self.se = SELayer(planes * 4, reduction) self.downsample = downsample self.stride = stride def forward(self, x): residual = x out = self.conv1(x) out = self.bn1(out) out = self.relu(out) out = self.conv2(out) out = self.bn2(out) out = self.relu(out) out = self.conv3(out) out = self.bn3(out) out = self.se(out) if self.downsample is not None: residual = self.downsample(x) out += residual out = self.relu(out) return out |
参考地址:https://www.sohu.com/a/161633191_465975
https://blog.csdn.net/u014380165/article/details/78006626
https://zhuanlan.zhihu.com/p/65459972/
https://blog.csdn.net/qq_38410428/article/details/87979417
https://github.com/yoheikikuta/senet-keras
https://github.com/moskomule/senet.pytorch





【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步