
深度学习论文翻译解析(八):Rich feature hierarchies for accurate object detection and semantic segmentation
论文标题:Rich feature hierarchies for accurate object detection and semantic segmentation
标题翻译:丰富的特征层次结构,可实现准确的目标检测和语义分割
论文作者:Ross Girshick Jeff Donahue Trevor Darrell Jitendra Mali
论文地址:http://fcv2011.ulsan.ac.kr/files/announcement/513/r-cnn-cvpr.pdf
RCNN的GitHub地址 : https://github.com/rbgirshick/rcnn
参考的RCNN翻译博客:https://blog.csdn.net/v1_vivian/article/details/78599229
声明:小编翻译论文仅为学习,如有侵权请联系小编删除博文,谢谢!
小编是一个机器学习初学者,打算认真研究论文,但是英文水平有限,所以论文翻译中用到了Google,并自己逐句检查过,但还是会有显得晦涩的地方,如有语法/专业名词翻译错误,还请见谅,并欢迎及时指出。
如果需要小编其他论文翻译,请移步小编的GitHub地址
传送门:请点击我
如果点击有误:https://github.com/LeBron-Jian/DeepLearningNote

摘要
过去几年,在权威数据集PASCAL上,物体检测的效果已经达到了一个稳定水平。效果最好的方法是融合了多种低维图像特征和高维上下文环境的复杂融合系统。在这篇论文里,我们提出了一种简单并且可扩展的检测算法,可以将 mAP在VOC2012最好结果的基础上提高30%以上——达到了53.3%。我们的方法结合了两个关键的因素:
- 1,在候选区域上自下而上使用大型卷积神经网络(CNNs),用以定位和分割物体。
- 2,当带标签的训练数据不足时,先针对辅助任务进行有监督预训练,再进行特定任务的调优,就可以产生明显的性能提升。
因为我们将区域提案与CNN结合,因此我们将我们的方法称为 R-CNN(Region proposals with CNN features):具有CNN功能的区域。完整系统的源代码可以从:http://www.cs.berkeley.edu/~rbg/rcnn 获得。
(作者也将R-CNN效果跟OverFeat 比较了一下(Overfeat是最近提出的在与我们相似的CNN特征下采样滑动窗口进行目标检测的一种方法),结果发现RCNN在200类ILSVRC2013检测数据集上的性能明显优于Overfeat。
Overfeat:是改进了AlexNet网络,并用图像缩放和滑窗方法在test数据集上测试网络;提出一种图像定位的方法;最后通过一个卷积神经网络来同时进行分类,定位和检测三个计算机视觉任务,并在 ILSVRC 2013中获得了很好的结果。

1,引言
特征问题,在过去十年,各类视觉识别任务的进展都很大程度取决于SIFT[27]和HOG[7] 的使用。但是,如果我们查看经典的视觉识别任务PASCAL VOC 对象检测的性能[13],则通常公认的是,2010~2012年进度缓慢,取得的微小进步都是通过构建一些集成系统和采用一些成功方法的变种才达到的。
SIFT和HOG是块状方向直方图(blockwise orientation historgrams),可以大致与V1(灵长类动物视觉通路的第一个皮质区域)中的复杂细胞相关联。但是我们知道识别发生在多个下游阶段(我们是先看到了一些特征,然后才意识到这是什么东西),也就是说对于视觉识别来说,更有价值的信息是层次化的,多阶段的。


Fukushima 的 “neocognitron”,一种受生物学启发用于模式识别的层次化,移动不变性模型,算是这方面最早的尝试。然而neocognitron 缺乏监督学习算法。Lecun等人的工作表明基于反向传播的随机梯度下降(SGD)对训练卷积神经网络(CNNs)非常有效,CNNs被认为是继承自 neocognitron的一类模型。
CNNs在1990年代被广泛使用,但是随着SVM的崛起而淡出研究主流。2012年,Krizhevsky等人在 ImageNet 大规模视觉识别挑战赛(ILSVRC)上的出色表现重新燃起了世界对CNNs的兴趣(AlexNet)。他们的成功在于120万的标签图像上使用了一个大型的CNN,并且对LeCun 的CNN进行了一些改造(比如ReLU和Dropout Regularization)。
这个ImageNet 的结果的重要性在ILSVRC2012 workshop上得到了热烈的讨论。提炼出来的核心问题是:ImageNet的CNN分类结果在何种程度上能够应用到 PASCAL VOC挑战的物体检测任务上?


我们通过连接图像分类和目标检测,回答了这个问题。本论文是第一个说明在PASCAL VOC的物体检测任务上CNN比基于简单类HOG特征的系统有大幅的性能提升。我们主要关注了两个问题:使用深度网络定位物体和在小规模的标注数据集上进行大型网络模型的训练。
与图像分类不同的是检测需要定位一个图像内的许多物体。一个方法是将框定位看做是回归问题。但Szegedy等人的工作说明这种策略不work(在VOC2007上他们的mAP是30.5%,而我们达到了58.5%)。另一个可替代的方法是使用滑动窗口探测器,通过这种方法使用CNNs至少已经有20年的时间了。通常用于一些特定的种类如人脸,行人等。为了获得较高的空间分辨率,这些CNNs都采用了两个卷积层和两个池化层。我们本来也考虑过使用滑动窗口的方法,但是由于网络层次更深,输入图形有非常大的感受野(195*195)和步长(32*32 ),这使得采用滑动窗口的方法充满挑战。
我们是通过操作“recognition using regions”范式,解决了CNN的定位问题。测试时,对这张图片,产生了接近2000个与类别无关的 region prorosal,对每个CNN抽取了一个固定长度的特征向量,然后借助专门针对特定类别数据的线性SVM对每个区域进行分类。我们不考虑region的大小,使用放射图像变形的方法来对每个不同形状的region proposal,对每个CNN抽取了一个固定长度的特征向量,然后借助专门针对特定类别数据的线性SVM对每个区域进行分类。我们不考虑region的大小,使用仿射图像变形的方法来对每个不同形状的region proposal产生一个固定长度的作为 CNN 输入的特征向量(也就是把不同大小的 proposal 放到同一个大小)。图1展示了我们方法的全貌并突出展示了一些实验结果。由于我们结合了 region proposals和CNNs,所以起名RCNN:regions with CNN features。
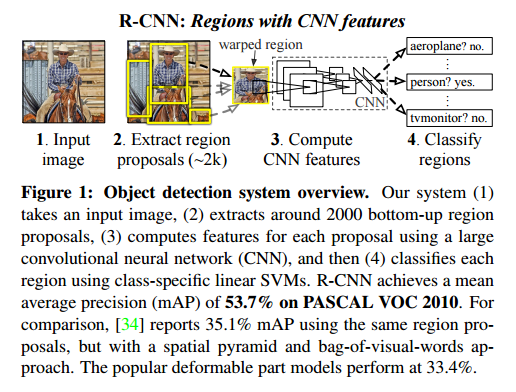


检测中面对的第二个挑战是标签数据太少,现在可获得的数据远远不够用于训练一个大型卷积网络。传统方法多是采用无监督与训练,再进行监督调优。本文的第二个核心共享是在辅助数据集(ILSVRC)上进行有监督预训练,再在小数据集上针对特定问题进行调优。这是在训练数据稀少的情况下的一个非常有效的训练大型卷积神经网络的方法。我们的实验中,针对检测的调优将mAP调高了8个百分点。调优后,我们的系统在VOC2010上达到了 54%的 mAP,远远超过高度优化的基于 HOG的可变性部件模型(deformable part model,DPM)。我们还向读者指出 Donahue等人的同期工作,[11]的研究表明,Krizhevsky 的CNN可以用作黑箱特征提取器(无需进行微调),从而在某些识别任务(包括场景分类,细粒度子分类和域自适应)上表现出出色的性能。
DPM:多尺度形变部件模型,连续获得07~09的检测冠军,2010年起作者 Felzenszwalb Pedro 被VOC授予“终身成就奖”。DPM把物体看成多个组成的部件(比如人脸的鼻子,嘴巴等),用部件间的关系来描述物体,这个特性非常符合自然界很多物体的非刚体特征。DPM可以看做是HOG+SVM的扩展,很好地继承了两者的优点,在人脸检测,行人检测等任务上取得了不错的效果,但是 DPM相对复杂,检测速度也较慢,从而也出现了很多改进的方法。
我们的系统也很高效,都是小型矩阵向量相乘和贪婪NMS这些特定类别的计算。这个计算特性源自于特征在不同类别之间的共享(对于不同类别,CNNs提取到的特征是一样的),这比之前使用的区域特征少了两个数量级的维度。
HOG-like 特征的一个优点是简单性:能够很容易明白提取到的特征是什么,那我们能可视化出CNNs提起到的特征吗?全连接层有超过5千4百万的参数值,这是关键吗?这都不是,我们将CNN切断,会发现,移除掉其中 94%的参数,精度只会下降一点点。相反,通过网络中的探测单元我们可以看到卷积层学习了一组丰富的特性。(图3)
分析我们方法的失败案例,对进一步提高很有帮助,所以我们借助 Hoiem等人的定位分析工具做实验结果的报告和分析。分析结果,我们发现主要的错误是因为 mislocalization,而是由了bounding box regression 之后,可以有效的降低这个错误。
介绍技术细节之前,我们提醒大家由于 R-CNN 是在推荐区域上进行操作,所以可以很自然地扩展到语义分割任务上。只要很小的改动,我们就在 PASCAL VOC 语义分割任务上达到了很有竞争力的结果,在 VOC2011测试集上平均语义分割精度达到了 47.9%。

2,用R-CNN进行物体检测
我们的物体检测系统包含三个模块,第一个,产生类别无关的region proposals,这些推荐定义了一个候选检测区域的集合;第二个是一个大型卷积神经网络,用于从每个区域抽取特定大小的特征向量;第三个是一个指定类别的线性SVM。本部分,将展示每个模块的设计,并介绍他们的测试阶段的用法,以及参数是如何学习的细节,最后给出在PASCAL VOC 2010~2012和 ILSVRC2013上的检测结果。

2.1 模块设计
区域推荐(region proposals)
近年来有很多研究都提出了产生类别无关区域推荐的方法。比如:objectness(物体性),selective search(选择性搜索),category-independent object proposals(类别无关物体推荐),constrained parametric min-cuts(受限参最小剪切,CPMC),multi-scal combinatorial grouping(多尺度联合分组),以及Ciresan等人的方法,将CNN用在规律空间块裁剪上以检测有丝分裂细胞,也算是一种特殊的区域推荐类型。由于RCNN对特定区域算法是不关心的,所以我们采用了选择性搜索以方便和前面的工作进行可控的比较。
特征提取(Feature extraction)
我们使用Krizhevsky等人所描述的CNN的一个Caffe实现版本对每个推荐区域抽取了一个 4096维度的特征向量把一个输入为227*227大小的图片,通过五个卷积层和两个全连接层进行前向传播,最终得到了一个 4096-D的特征向量。读者可以参考AlexNet获得更多的网络架构细节。

为了计算region proposal的特征,我们首先要对图像进行转换,使得它符合CNNs的输入(架构中的 CNNs只能接受固定大小:227*227)。这个变换有很多办法,我们使用了最简单的一种。无论候选区域是什么尺寸和宽高比,我们都把候选框变形成想要的尺寸。具体的,变形之前,我们现在候选框周围加上16的padding,再进行各向异性缩放。这种形变使得mAP提高了3到5个百分点,在补充资料中,作者对比了各向异性和各向同性缩放方法。


2.2 测试时间检测
在测试阶段,我们在测试图像上使用 selective search 抽取了2000个推荐区域(实验中,我们使用了选择性搜索的快速模式),然后编写每一个推荐区域,再通过CNN前向传播计算出特征。然后我们使用对每个类别训练出的SVM给整个特征向量中的每个类别打分。然后给出一张图像中所有的打分区域,然后使用NMS(每个类别都是独立进行的),拒绝掉一些和高分区域的IOU大于阈值的候选框。


运行时间分析
两个特性让检测变得很高效。首先,所有的CNN参数都是跨类别共享的。其次,通过CNN计算的特征向量相比其他通用方法(比如spatial pyramids with bag-of-visual-word encodings 带有视觉词袋编码的空间金字塔)相比,维度是很低的。UVA检测系统的特征比我们的要多两个数量级(360K vs 4K)。
这种共享的结果就是计算推荐区域特征的耗时可以分摊到所有类别的头上(GPU:每张图13s,CPU:每张图53s)。唯一的和具体类别有关的计算是特征向量和SVM权重和点积,以及NMS。实践中,所有的点积都可以批量化成一个单独矩阵间运算。特征矩阵的典型大小是 2000*4096,SVM权重的矩阵是 4096*N,其中N是类别的数量。
分析表明R-CNN可以扩展到上千个类别,而不需要借用近似技术(如hashing)。即使有10万个类别,矩阵乘法在现代多核CPU上只需要 10s 而已。但是这种高效不仅仅是因为使用了区域推荐和共享特征。由于较高维度的特征,UVX系统存储 100k linear predictors 需要 134G的内存,而我们只要 1.5GB,比我们高了两个数量级。
有趣的是R-CNN和最近 Dean等人使用 DPMs 和 hashing做检测的工作相比,他们用了1万个干扰类,每五分钟可以处理一张图片,在VOC 2007上的 mAP能达到 16%,我们的方法1万个检测器由于没有做近似,可以在CPU上一分钟跑完,达到了 59%的mAP。(3.2节)

2.3 训练
有监督的预训练
我们在大型辅助训练集 ILSVRC2012分类数据集(没有约束框数据)上预训练了CNN。预训练采用了Caffe的CNN库。总体来说,我们的CNN十分接近Krizhevsky等人的网络的性能,在ILSVRC2012分类验证集在top-1错误率上比他们高2.2%。差异主要来自于训练过程的简化。
特定领域的参数调优
为了让我们的CNN适应新的任务(即检测任务)和新的领域(变形后的推荐窗口)。我们只使用变形后的推荐区域对CNN参数进行SGD训练。我们替换掉了ImageNet专用的1000-way分类层,换成了一个随机初始化的21-way分类层(其中20是VOC的类别数,1代表背景)。而卷积部分都没有改变。我们对待所有的推荐区域,如果其和真实标注的框的 IoU >= 0.5 就认为是正例,否则就是负例。SGD开始的learning rate 是 0.001(是初始化预训练时的十分之一)。这使得调优得以有效进行而不会破坏初始化的成果。每轮SGD迭代,我们通一使用32个正例窗口(跨所有类别)和96个背景窗口,即每个mini-batch 的大小为 128。另外我们倾向于采样正例窗口,因为和背景相比,他们很稀少。


目标种类分类器
考虑训练一个检测汽车的二分类器。很显然,一个图像区域紧紧包裹着一辆汽车应该就是正例。同样的,没有汽车的就是背景区域,也就是负例。较为不明确的是怎么样标注那些之和汽车部分重叠的区域,我们使用IOU重叠阈值来解决这个问题,低于这个阈值的就是负例。这个阈值我们选择了 0.3,是在验证集上基于{0, 0.1,...0.5}通过网格搜索得到的。我们发现认真选择这个阈值很重要。如果设置Wie0.5,可以降低mAP 5个点,设置为0,就会降低4个点。正例就严格的是标注的框。
Tips:IOU < 0.3 被作为负例,ground-truth是正例,其余的全部丢弃。
一旦特征提取出来,并应用标签数据,我们优化了每个类的线性SVM。由于训练数据太大,难以装进内存,我们选择了标注的 hard negative mining method,高难负例挖掘算法收敛很快,实践中只需要在所有图像上经过一轮训练,mAP就可以基本停止增加了。
hard negative mining method:难负例挖掘算法,用途就是正负例样本数量不均衡,而负例分散代表性又不够的问题,hard negative 就是每次把哪些顽固的棘手的错误,再送回去继续练,练到你成绩不再提升为止,这一个过程就叫‘hard negative mining’
在补充材料中,我们讨论了为什么微调与SVM训练中正例和负例的定义不同。我们还将讨论为什么必须训练检测分类器,而不是简单地使用经过微调的CNN的最后一层(fc8)的输出。
fine-tuning阶段是由于CNN对小样本容易过拟合,需要大量训练数据,故对IOU限制宽松:IoU > 0.5 的建议框为正样本,否则为负样本;SVM这种机制是由于其适用于小样本训练,故对样本IoU限制严格:Ground Truth 为正样本,与Ground Truth 相交 IoU < 0.3 的建议框为负样本。
为什么单独训练了一个SVM而不是直接用softmax,作者提到,刚开始时只是用了ImageNet预训练了CNN,并用提取的特征训练了SVM,此时用正负样本标记方法就是前面所述的0.3,后来刚开始使用 fine-tuning时,也使用了这个方法,但是发现结果很差,于是通过调试选择0.5 这个方法,作者认为这样可以加大样本的数量,从而避免过拟合。然而,IoU大于0.5就作为正样本会导致网络定位准确度的下降,故使用了SVM做检测,全部使用ground-truth严格不作为正副本,且使用非正样本的,且IoU大于 0.3的“hard negatives”,提高了定位的准确度。


2.4 在PASCAL VOC 2010~2012上的结果
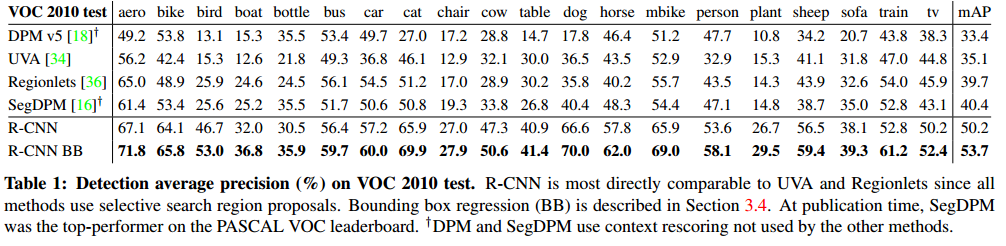
按照PASCAL VOC的最佳实践步骤,我们在VOC2007的数据集上验证了我们所有的设计思路和参数处理,我们在VOC2012上训练和优化了SVM,最终结果再VOC 2010~12的数据库,我们在评估服务器上提交了两个结果(一个是有 bunding box regression,一个没有)。
表1展示了在VOC2010的结果,我们将自己的方法同四种先进基准方法做对比,其中包括SegDPM,这种方法将DPM检测子与语义分割系统相结合并且附加的inter-detector的环境和图片检测器。更加恰当的是比较同Uijling的UVA系统比较,因为我们的方法同样基于候选框算法。对于候选框区域的分类,他们通过构建一个四层的金字塔,并且将之与SIFT模板结合,SIFT为扩展的OpponsentSIFT和RGB-SIFT描述子,每一个向量被量化为 4000-word的codebook。分类任务由一个交叉核的SVM承担,对比这种方法的多特征方法,非线性内核的SVM方法,我们在mAP达到了一个更大的提升,从 35.1%提升到53.7%,而且速度更快。我们的方法在 VOC 2011/2012测试集上达到了相似的检测效果mAP 53.3%。

3,可视化,消融和模型的错误
3.1 可视化学习的特征
直接可视化第一层 filters非常容易理解,他们主要捕获方向性边缘和对比色。难以理解的是后面的层,Zeiler and Fgrgus 提出了一种可视化的很棒的反卷积办法。我们则使用了一种简单的非参数化方法,直接展示网络学习到的东西。
这个想法是单一输出网络中一个特定单元(特征),然后把它当做一个正确类别的物体检测器来使用。方法是这样的,先计算所有抽取出来的推荐区域(大约1000万),计算每个区域所导致的对应单元的激活值,然后按激活值对这些区域进行排序,然后进行最大值抑制,最后展示分值最高的若干个区域。这个方法让被选中的单元在遇到它想激活的输入时“自己说话”。我们避免平均化是为了看到不同的视觉模式和深入观察单元计算出来的不变性。
我们可视化了第五层的池化层 pool5,是卷积网络的最后一层,feature map(卷积核和特征数的总称)的大小是 6*6*256 = 9216维。忽略边界效应,每个pool5单元拥有195*195的感受野,输入是 227*227.pool5中间的单元,几乎是一个全局视角,而边缘的单元有较小的带裁切的支持。


图3的每一行显示了对于一个 pool5 单元的最高 16个激活区域情况,这个实例来自于 VOC 2007上我们调优的CNN,这里只展示了 256个单元中的6个(附录D包含更多),我们看看这些单元都学到了什么。第二行,有一个单元看到狗和斑点的时候就会激活,第三行对应红斑点,还有人脸,当然还有一些抽象的模式,比如文字和带窗口的三角结构。这个网络似乎学到了一些类别调优相关的特征,这些特征都是形状,纹理,颜色和材质特性的分布式表示。而后续的 fc6层则对这些丰富的特征建立大量的组合来表达各种不同的事物。



3.2 消融研究(Ablation studies)
tips:Albation study 就是为了研究模型中所提出的一些结构是否有效而设计的实验。如你提出了某某结构,但是要想确定这个结构是否有利于最终的效果,那就要将去掉该结构的网络与加上该结构的网络所得到的结果进行对比,这就是 ablation study,也就是控制变量法。
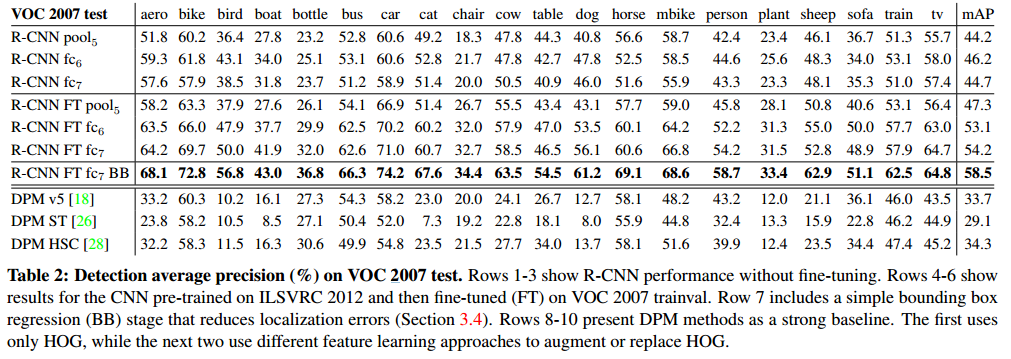
没有调优的各层性能
为了理解那一层对于检测的性能十分重要,我们分析了CNN最后三层的每一层在 VOC 2007上面的结果。Pool5在3.1 中做过简短的表述。最后两层下面来总结一下。
fc6 是一个与pool5连接的全连接层。为了计算特征,它和 pool5的 feature map(reshape成一个 9216维度的向量)做了一个 4096*9216的矩阵乘法,并添加了一个 bias 向量。中间的向量是逐个组件的半波整流(component wise half wave rectified)(RELU (x -> max(0, x)))
fc7是网络的最后一层,跟 fc6 之间通过一个 4096*4096 的矩阵相乘。也是添加了 bias 向量和应用了RELU。
我们先来看看没有调优的CNN在PASCAL 上的表现,没有调优是指所在的CNN参数就是在ILSVRC 2012上训练后的状态。分析每一层的性能显示来自于fc7的特征泛化能力不如fc6的特征。这意味着29%的CNN参数,也就是 1680万的参数可以移除掉,而且不影响mAP。更多的惊喜是即使同时移除fc6和fc7,仅仅使用pool5的特征,只使用CNN参数的6%也能有非常好的结果。可见CNN的主要表达力来自于卷积层,而不是全连接层。这个发现提醒我们也许可以在计算一个任意尺寸的图片的稠密特征图(dense feature map)时仅仅使用CNN的卷积层。这种表示可以直接在 pool5 的特征上进行滑动窗口检测的实验。

调优后的各层性能
我们现在看看调优后在VOC 2007上的结果表现。提升非常明显,mAP提升了8个百分点,达到了54.2%。fc6和fc7的提升明显优于pool5,这说明 pool5从ImageNet学习的特征通用性很强,在它之上层的大部分提升主要是在学习领域相关的非线性分类器。

对比最近的特征学习方法
相当少的特征学习方法应用于VOC数据集。我们找到的两个最近的方法都是基于固定探测模型。为了参照的需要,我们也将基于基本HOG的DFM方法的结果加入比较。
第一个DPM的特征学习方法,DPM ST将HOG中加入略图表征的概率直方图。直观的,一个略图表征概率通过一个被训练出来的分类 35*35 像素路径为一个 150 略图表征的随机森林方法计算。
第二个方法,DPM HSC,将 HOG特征替换成一个稀疏编码的直方图。为了计算HSC,在每个像素上使用一个学习到的 1007*7像素(灰度空间)原子求解稀疏编码激活,由此产生的激活以三种方式(全波和半波)整流,空间池化,L2标准化,然后进行幂运算。
所有的RCNN变种算法都要强于这三个 DPM 方法(表2,8~10行),包括两种特征学习的方法与最新版本的 DPM方法比较,我们的mAP要多大约20个百分点,61%的相对提升。略图表征与HOG相结合的方法比单纯HOG的性能高出2.5%,而HSC的方法相对于HOG提升4个百分点(当内在的与他们自己的DPM基准比较,全都是用的非公共 DPM执行,这低于开源版本)。这些方法分别达到了 29.1%和34.3%。

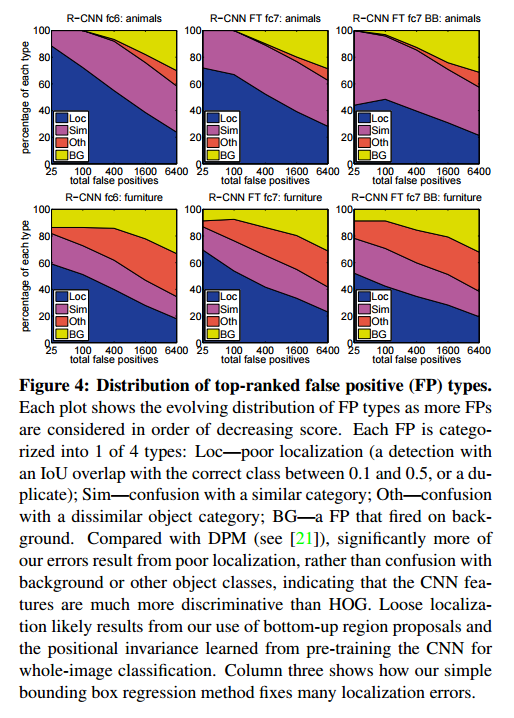
3.3 检测错误分析
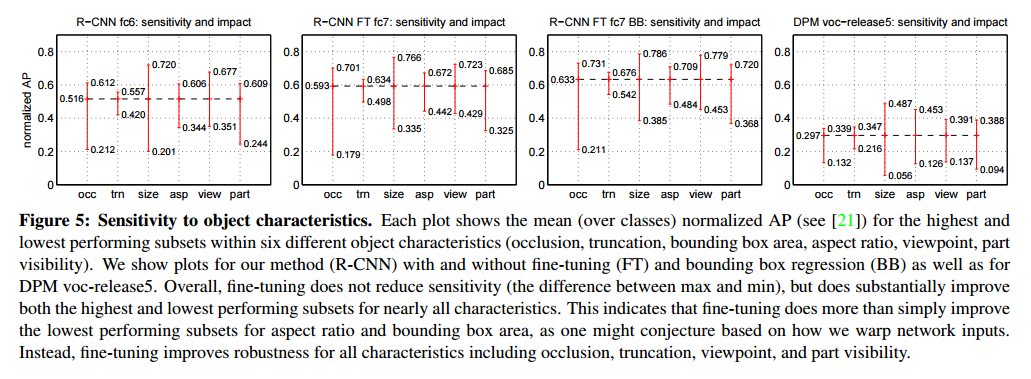
为了揭露出我们方法的错误之处,我们使用Hoiem提出的优秀的检测分析工具,来理解调参是怎么改变他们,并且观察相对于 DPM方法,我们的错误形式。这个分析方法全部的介绍超出了本文的介绍范围,我们建议读者查阅文献21来了解更加详细的介绍(例如“normalized AP”的介绍),由于这些分析是不太有关联性,所以我们放在图4和图5的题注里讨论。

3.4 Bounding box回归
基于错误分析,我们使用了一种简单的方法减少定位误差,受到 DPM[17]中使用的约束框回归训练启发,我们训练了一个线性回归模型在给定一个选择区域的 pool5特征时去预测了一个新的检测窗口。详细的细节参考附录C。表1,表2 和图4的结果说明这个简单的方法,修复了大量的错位检测,提升了3~4个百分点。


4,语义分割
区域分类是语义分割的标准技术,这使得我们很容易将R-CNN 应用到PASCAL VOC 分割任务的挑战。为了和当前主流的语义分割系统(称为O2P,second-order piiling[4])做对比,我们使用了一个开源的框架。O2P使用CPMC针对每张图片产生了150个区域推荐,并预测每个区域的品质,对于每个类别,进行支撑向量回归(support vector regression,SVR)。他们的方法很高效,主要得益于CPMC区域的品质和多特征类型的强大二阶池化(second -sencond pooling,SIFT和LBP的增强变种)。我们也注意到Farabet等人[16]将CNN用作多尺度逐像素分类器,在几个高密度场景标注数据集(不包括PASCAL)上取得了不错的成绩。
我们学习[2, 4],将Haeiharan等人提供的额外标注信息补充到PASCAL分割训练集中。设计选择和超参数都在 VOC2011验证集上进行交叉验证。最后的测试结果只执行了一次。

用于分割的CNN特征
为了计算CPMC区域上的特征,我们执行了三个策略,每个策略都先将矩形窗口变形到 227*227大小。第一个策略完全忽略区域的形状(full ignore),直接在变形后的窗口上计算 CNN特征,就和我们检测时做的一样。但是,这些特征忽略了区域的非矩形形状。两个区域也许包含相似的约束框却几乎没有重叠。因此,第二个策略(fg,foreground)只计算前景遮罩(foreground mask)的CNN特征,我们将所有的背景像素替换成平均输入,这样减去平均值后他们就会变成0。第三个策略(full+fg),简单的并联全部(full)特征和前景(fg)特征;我们的实验验证了他们的互补性。

在VOC 2011 上的结果
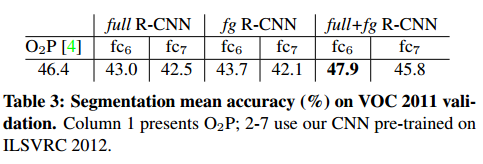
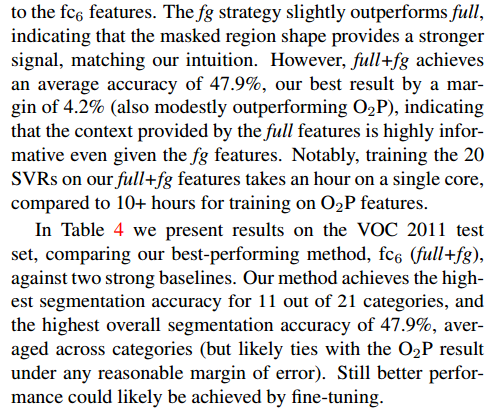
表3显示了与O2P相比较的VOC 2011验证集的结果(每个类别的计算结果见补充材料)。在每个特征计算策略中,FC6总是优于FC7,下面就针对FC6进行讨论,fg策略略优于full,表明掩蔽区域形状提供了更强的信号,匹配我们的直觉。然而,full+fg 的平均精度为 47.9%,比 fg优4.2%(也稍优于O2P),这表明即使提供了FG特征,由full特征提供的上下文也是有很多信息。值得注意的是,训练20个SVR,在我们的full+fg 特征在单核上需要1个小时,而在O2P特征则需要10个小时。
在表4中,我们给出了 VOC 2011测试集上的结果。比较我们的最佳执行方法(full + fg),对抗两个强大的 baselines。我们的方法在 21 个类别中的 11 个达到最高的分割精度,最高的总体分割精度为 47.9%,平均跨类别(但可能与O2P结果在任何合理的误差范围内)。通过微调可能会取得更好的成绩。



5,总结
最近几年,物体检测陷入停滞,表现最好的检测系统是复杂的将多低层次的图像特征与高层次的物体检测器环境与创建识别相结合。本文提出了一种简单并且可扩展的物体检测方法,达到了VOC 2012数据集相对之前最好性能的 30%的提升。
我们取得这个性能主要通过两个方面:第一是应用了自底向上的候选框训练的高容量的卷积神经网络进行定位和分割物体。另外一个是使用在标签数据匮乏的情况下训练一个大规模神经网络的方法。我们展示了在有监督的情况下使用丰富的数据集(图片分类)预训练一个网络作为辅助性的工作是很有效的,然后采用稀少数据(检测)去调优定位任务的网络。我们猜测“有监督的预训练 + 特定领域的调优” 这一范式对数据稀少的视觉问题是很有效的。
最后,我们注意到能得到这些结果,将计算机视觉中经典的工具和深度学习(自底向上的区域候选框和卷积神经网络)组合是非常重要的。而不是违背科学探索的主线,。这两个部分是自然而且必然的结合。
致谢
这项研究得到了DARPA Mind的Eye和MSEE计划的部分支持,由NSF授予IIS-0905647,IIS-1134072和IIS-1212798,MURI N000014-10-1-0933的支持,以及丰田的支持。 本研究中使用的GPU由NVIDIA Corporation慷慨捐赠。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号