
Python机器学习笔记:SVM(2)——SVM核函数
完整代码及其数据,请移步小编的GitHub
传送门:请点击我
如果点击有误:https://github.com/LeBron-Jian/MachineLearningNote
上一节我学习了完整的SVM过程,下面继续对核函数进行详细学习,具体的参考链接都在上一篇文章中,SVM四篇笔记链接为:
Python机器学习笔记:SVM(1)——SVM概述
Python机器学习笔记:SVM(2)——SVM核函数
Python机器学习笔记:SVM(3)——证明SVM
Python机器学习笔记:SVM(4)——sklearn实现
热身实例
我在上一节有完整的学习了SVM算法,为了不让自己这么快就忘了,这里先学习一个实例,回顾一下,并引出核函数的概念。
数据是这样的:有三个点,其中正例 x1(3, 3),x2(4,3),负例 x3(1,1)
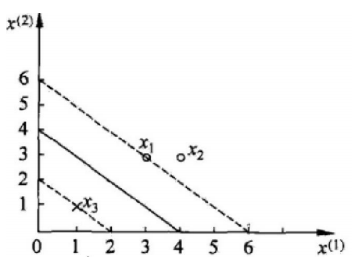
求解:

约束条件为:
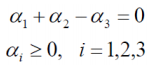
这个约束条件是通过这个得到的(为什么这里强调一下呢,因为我们这个例子本身说的就是SVM的求解过程):
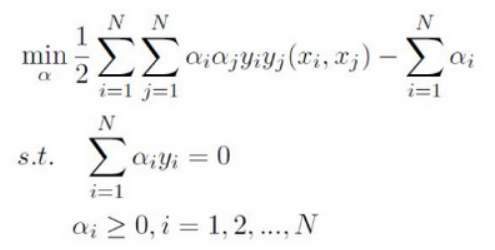
我们可以知道 y1 = +1, y2 = +1 , y3 = -1,同时,代入 α ,则得到:
α1 + α2 - α3=0
下面通过SVM求解实例。
我们将数据代入原式中:
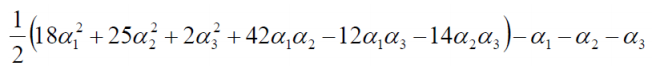
由于 α1 + α2 = α3 化简可得:

然后分别对 α1 和 α2 求偏导,偏导等于 0 可得: α1 = 1.5 α2 = -1 ,但是我们发现这两个解并不满足约束条件 αi >= 0,i=1,2,3,所以解应该在边界上(正常情况下,我们需要对上式求偏导,进而算出 w,b)。
首先令 α1 = 0,得出 α2 = -2/13 ,α3 = -2/13 (不满足约束)
再令 α2 = 0,得出 α1 = 0.25 ,α3 = 0.25 (满足约束)
所以最小值在(0.25, 0,0.25)处取得。
我们将 α 的结果代入求解:
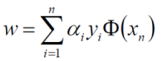
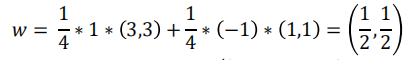
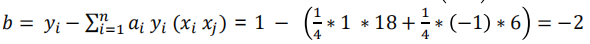
所以我们代入 w b ,求得最终的平面方程为:

热身完毕,下面学习核函数,为了方便理解我们下面要说的核函数,我在知乎找了一个简单易懂的故事,让我们了解支持向量机,更是明白支持向量机的核函数是个什么鬼,下面看故事。
1,故事分析:支持向量机(SVM)是什么?
下面故事来源于此(这是源作者链接):点击我即可
在很久以前的情人节,有一个大侠要去救他的爱人,但是魔鬼和他玩了一个游戏。
魔鬼在桌面上似乎有规律放了两种颜色的球,说:“你用一根棍分开他们?要求:尽量在放更多球之后,仍然使用”

于是大侠这样做,干得不错吧:
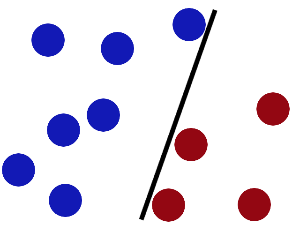
然后魔鬼又在桌上放了更多的球,似乎有一个球站错了阵营。
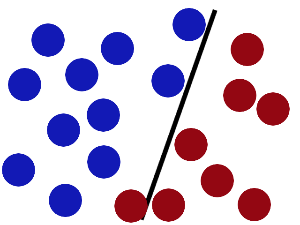
SVM就是试图把棍放在最佳位置,好让在棍的两边有尽可能大的间隙。
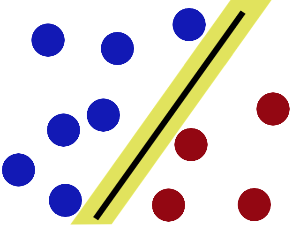
现在即使魔鬼放了更多的球,棍仍然是一个好的分界线。

然后,在SVM工具箱中有另一个更加重要的trick 。魔鬼看到大侠已经学会了一个trick,于是魔鬼给了大侠一个新的挑战。

现在,大侠没有棍可以很好地帮他分开这两种球了,现在怎么办,当然像所有武侠片中一样大侠桌子一拍,球飞到空中。然后凭借着大侠的轻功,大侠抓起一张纸,插到了两种球的中间。

现在,从魔鬼的角度看这些球,这些球好像是被一条曲线分开了。
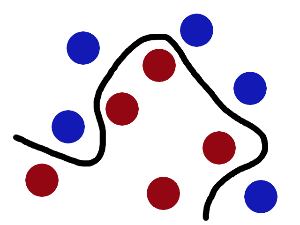
在之后,无聊的大人们,把这些球叫做 「data」,把棍子 叫做 「classifier」, 最大间隙trick 叫做「optimization」, 拍桌子叫做「kernelling」, 那张纸叫做「hyperplane」。
所以说,Support Vector Machine,一个普通的SVM就是一条直线罢了,用来完美划分linearly separable的两类。但是这又不是一条普通的直线,这是无数条可以分类的直线当中最完美的,因为它恰好在两个类的中间,距离两个类的点都一样远。而所谓的Support vector就是这些离分界线最近的点,如果去掉这些点,直线多半是要改变位置的。如果是高维的点,SVM的分界线就是平面或者超平面。其实没有差,都是一刀切两块,我们这里统一叫做直线。
再理解一下,当一个分类问题,数据是线性可分的,也就是用一根棍就可以将两种小球分开的时候,我们只要将棍的位置放在让小球距离棍的距离最大化的位置即可。寻找这个最大间隔的过程,就叫做最优化。但是,显示往往是残酷的,一般的数据是线性不可分的。也就是找不到一个棍将两种小球很好的分类,这时候我们就需要像大侠一样,将小球排起,用一张纸代替小棍将两种小球进行分类,想让数据飞起,我们需要的东西就是核函数(kernel),用于切分小球的纸,就是超平面。
2,核函数的概念
上面故事说明了SVM可以处理线性可分的情况,也可以处理非线性可分的情况。而处理非线性可分的情况是选择了核函数(kernel),通过将数据映射到高位空间,来解决在原始空间中线性不可分的问题。
我们希望样本在特征空间中线性可分,因此特征空间的好坏对支持向量机的性能至关重要,但是在不知道特征映射的情况下,我们是不知道什么样的核函数是适合的,而核函数也只是隐式的定义了特征空间,所以,核函数的选择对于一个支持向量机而言就显得至关重要,若选择了一个不合适的核函数,则数据将映射到不合适的样本空间,从而支持向量机的性能将大大折扣。
所以构造出一个具有良好性能的SVM,核函数的选择是关键。而核函数的选择包含两部分工作:一是核函数类型的选择,二是确定核函数类型后相关参数的选择。
我们知道,核函数的精妙之处在于不用真的对特征向量做核映射,而是直接对特征向量的内积进行变换,而这种变换却等价于先对特征向量做核映射然后做内积。
SVM主要是在用对偶理论求解一个二次凸优化问题,其中对偶问题如下:
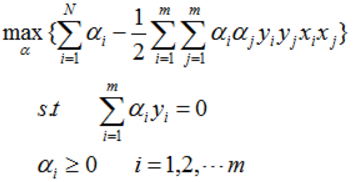
求得最终结果:
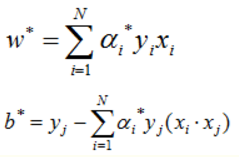
当然这是线性可分的情况,那么如果问题本身是线性不可分的情况呢?那就是先扩维后再计算。具体来说,在线性不可分的情况下,支持向量机首先在低维空间中完成计算,然后通过核函数将输入空间映射到高维特征空间,最终在高维特征空间中构造出最优分离超平面,从而把平面上本身不好分的非线性数据分开。如下图所示,一堆数据在二维空间中无法划分,从而映射到三维空间中划分:

而在我们遇到核函数之前,如果用原始的方法,那么在用线性学习器学习一个非线性关系,需要选择一个非线性特征集,并且将数据写成新的表达形式,这等价于应用一个固定的非线性映射,将数据映射到特征空间,在特征空间中使用线性学习器。因此,考虑的假设集是这种类型的函数:
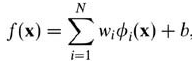
这里 Φ :X -> F 是从输入空间到某个特征空间的映射,这意味着建立非线性学习器分为两步:
- 1,使用一个非线性映射将数据变换到一个特征空间 F
- 2,在特征空间使用线性学习器分类
而由于对偶形式就是线性学习器的一个重要性质,这意味着假设可以表达为训练点的线性组合,因此决策规则可以用测试点和训练点的内积来表示:
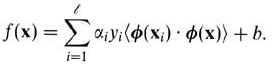
为向量加上核映射后,要求解的最优化问题变为:
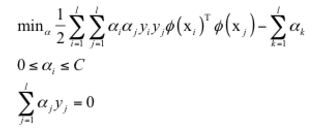
根据核函数满足的等式条件,它等价于下面的问题:
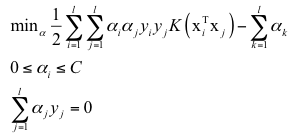
其线性不可分情况的对偶形式如下:
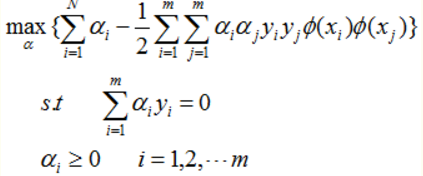
其中 Φ(xi) 表示原来的样本扩维后的坐标。
最后得到的分类判别函数为:
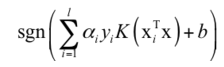
和不用核映射相比,只是求解的目标函数,最后的判定函数对特征向量的内积做了核函数变换。如果K是一个非线性函数,上面的决策函数则是非线性函数,此时SVM是非线性模型。当训练样本很多,支持向量的个数很大的时候,预测时的速度是一个问题,因此很多时候我们会使用线性支持向量机。
3,举例说明核函数的巧妙之处
下面先从一个小例子来阐述问题。假设我们有两个数据, x = (x1, x2, x3) y = (y1, y2, y3)。此时在3D空间已经不能对其进行线性划分了,那么我们通过一个函数将数据映射到更高维的空间,比如9维的话,那么 f(x) = (x1x1, x1x2, x1x3, x2x1, x2x2, x2x3, x3x1, x3x2, x3x3),由于需要计算内积,所以在新的数据在 9 维空间,需要计算 <f(x), f(y)> 的内积,需要花费 O(n^2)。
再具体点,令 x = (1, 2, 3), y = (4, 5, 6),那么 f(x) = (1, 2, 3, 2, 4, 6, 3, 6, 9),f(y) = (16, 20, 24, 20, 25, 36, 24, 30, 36)
此时: <f(x), f(y)> = 16 + 40 + 72 +40 +100 + 180 + 72 +180 +324 = 1024
对于3D空间这两个数据,似乎还能计算,但是如果将维数扩大到一个非常大数的时候,计算起来可就不是这么一点点问题了。
然而,我们发现 K(x, y) = (<x, y>)^2 ,代入上式: K(x, y) = (4 + 10 + 18)^2 = 32^2 = 1024
也就是说 : K(x, y) = (<x, y>)^2 = <f(x), f(y)> 。
但是 K(x, y) 计算起来却比 <f(x), f(y)> 简单的多,也就是说只要用 K(x, y)来计算,效果与 <f(x), f(y)> 是一样的,但是计算效率却大幅度提高了,如 K(x, y) 是 O(n),而 <f(x), f(y)> 是 O(n^2),所以使用核函数的好处就是,可以在一个低维空间去完成一个高纬度(或者无限维度)样本内积的计算,比如上面例子中 K(x, y)的3D空间对比 <f(x), f(y)> 的9D空间。
下面再举个例子来证明一下上面的问题,为了简单起见,假设所有样本点都是二维点,其值分别为(x, y),分类函数为:
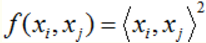
它对应的映射方式为:

可以验证:任意两个扩维后的样本点在3维空间的内积等于原样本点在二维空间的函数输出:
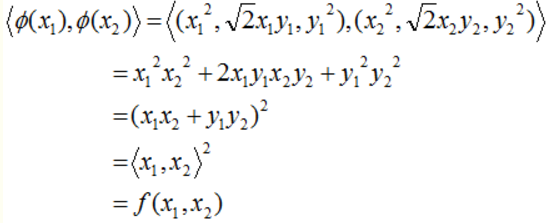
有了这个核函数,以后的高维内积都可以转换为低维的函数运算了,这里也就是说只需要计算低维的内积,然后再平方。明显问题得到解决且复杂度降低极大。总而言之:核函数它本质上隐含了从低维到高维的映射,从而避免直接计算高维的内积。
当然上述例子是多项式核函数的一个特例,其实核函数的种类还有很多,后文会一一介绍。
4,核函数的计算原理
通过上面的例子,我们大概可以知道核函数的巧妙应用了,下面学习一下核函数的计算原理。
如果有一种方法可以在特征空间中直接计算内积 <Φ(xi , Φ(x)> ,就像在原始输入点的函数中一样,就有可能将两个步骤融合到一起建立一个非线性的学习器,这样直接计算的方法称为核函数方法。
设 x 是输入空间(欧式空间或者离散集合),H为特征空间(希尔伯特空间),如果存在一个从 x 到 H 的映射:
![]()
核是一个函数 K,对于所有 x, z ∈ χ, 则满足:

则称Κ(x,z)为核函数,φ(x)为映射函数,φ(x)∙φ(z)为x,z映射到特征空间上的内积。
参考网友的理解:任意两个样本点在扩维后的空间的内积,如果等于这两个样本点在原来空间经过一个函数后的输出,那么这个函数就叫核函数。
由于映射函数十分复杂难以计算,在实际中,通常都是使用核函数来求解内积,计算复杂度并没有增加,映射函数仅仅作为一种逻辑映射,表征着输入空间到特征空间的映射关系。至于为什么需要映射后的特征而不是最初的特征来参与计算,为了更好地拟合是其中一个原因,另外的一个重要原因是样例可能存在线性不可分的情况,而将特征映射到高维空间后,往往就可分了。
下面将核函数形式化定义。如果原始特征内积是 <X , Z>,映射 <Φ(xi • Φ(x)>,那么定义核函数(Kernel)为:
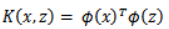
到这里,我们可以得出结论,如果要实现该节开头的效果,只需要计算 Φ(x) ,然后计算 Φ(x)TΦ(x)即可,然而这种计算方式是非常低效的。比如最初的特征是n维的,我们将其映射到 n2 维,然后再计算,这样需要O(n2 ) 的时间,那么我们能不能想办法减少计算时间呢?
先说结论,当然是可以的,毕竟我们上面例子,活生生的说明了一个将需要 O(n2 ) 的时间 转换为 需要O(n ) 的时间。
先看一个例子,假设x和z都是n维度的,
![]()
展开后,得到:
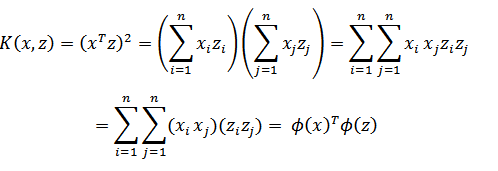
这个时候发现我们可以只计算原始特征 x 和 z 内积的平方(时间复杂度为O(n)),就等价于计算映射后特征的内积。也就是说我们不需要花O(n2 ) 的时间了。
现在看一下映射函数(n = 3),根据上面的公式,得到:

也就是说核函数 Κ(x,z) = (xTz)2 只能选择这样的 φ 作为映射函数时才能够等价于映射后特征的内积。
再看另外一个核函数,高斯核函数:

这时,如果 x 和 z 很相近 (||x - z || 约等于 0),那么核函数值为1,如果 x 和 z 相差很大(||x - z || >> 0),那么核函数值约等于0.由于这个函数类似于高斯分布,因此称为高斯核函数,也叫做径向基函数(Radial Basis Function 简称为RBF)。它能够把原始特征映射到无穷维。
下面有张图说明在低维线性不可分时,映射到高维后就可分了,使用高斯核函数。
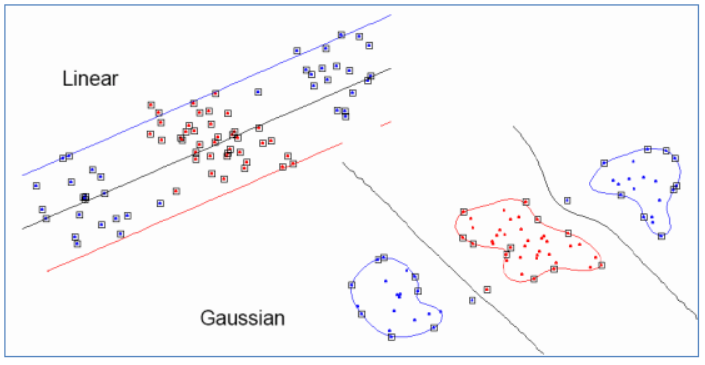
注意,使用核函数后,怎么分类新来的样本呢?线性的时候我们使用SVM学习出w和b,新来样本x的话,我们使用 wTx + b 来判断,如果值大于等于1,那么是正类,小于等于是负类。在两者之间,认为无法确定。如果使用了核函数后,wTx + b 就变成了 wTΦ(x) + b,是否先要找到 Φ(x) ,然后再预测?答案肯定不是了,找 Φ(x) 很麻烦,回想我们之前说过的。
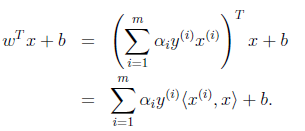
只需将 <(x(i) , x> 替换成 (x(i) , x),然后值的判断同上。
4.1 核函数有效性的判定
问题:给定一个函数K,我们能否使用K来替代计算 Φ(x)TΦ(x),也就说,是否能够找出一个 Φ,使得对于所有的x和z,都有 K(x, z) = Φ(x)TΦ(x),即比如给出了 K(x, z) = (xTz)2,是否能够认为K是一个有效的核函数。
下面来解决这个问题,给定m个训练样本(x(1),x(2), ....,x(m)),每一个x(i) 对应一个特征向量。那么,我们可以将任意两个 x(i) 和 x(j) 带入K中,计算得到Kij = K(x(i), x(j))。i 可以从1到m,j 可以从1到m,这样可以计算出m*m的核函数矩阵(Kernel Matrix)。为了方便,我们将核函数矩阵和 K(x, z) 都使用 K 来表示。如果假设 K 是有效地核函数,那么根据核函数定义:
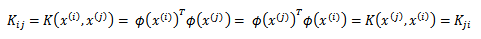
可见,矩阵K应该是个对称阵。让我们得出一个更强的结论,首先使用符号ΦK(x)来表示映射函数 Φ(x) 的第 k 维属性值。那么对于任意向量 z,得:
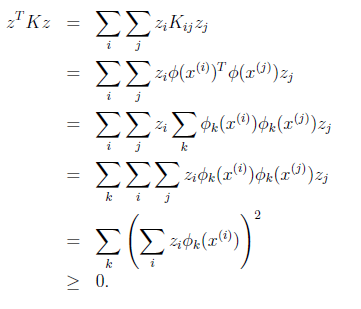
最后一步和前面计算 K(x, z) = (xTz)2 时类似。从这个公式我们可以看出,如果K是个有效的核函数(即 K(x, z) 和 Φ(x)TΦ(z)等价),那么,在训练集上得到的核函数矩阵K应该是半正定的(K>=0)。这样我们得到一个核函数的必要条件:K是有效的核函数 ==> 核函数矩阵K是对称半正定的。
Mercer定理表明为了证明K是有效的核函数,那么我们不用去寻找 Φ ,而只需要在训练集上求出各个 Kij,然后判断矩阵K是否是半正定(使用左上角主子式大于等于零等方法)即可。
5,核函数:如何处理非线性数据
来看个核函数的例子。如下图所示的两类数据,分别分布为两个圆圈的形状,这样的数据本身就是线性不可分的,此时我们该如何把这两类数据分开呢?
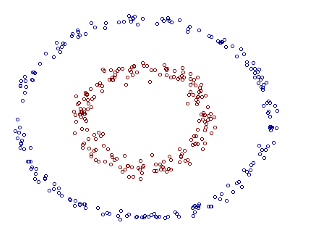
事实上,上图所示的这个数据集,是用两个半径不同的圆圈加上了少量的噪音生成得到的,所以,一个理想的分界应该是“圆圈” 而不是“一条线”(超平面)。如果用 X1 和 X2 来表示这个二维平面的两个坐标的话,我们知道一条二次曲线(圆圈是二次曲线的一种特殊情况)的方程可以写作这样的形式:
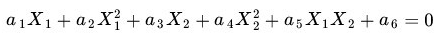
注意上面的形式,如果我们构造另外一个五维的空间,其中五个坐标的值分别为:
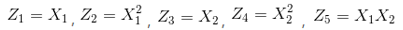
那么显然,上面的方程在新的坐标系下可以写做:
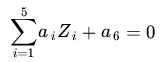
关于新的坐标 Z,这正是一个 hyper plane 的方程!也就是说,如果我们做一个映射:
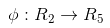
将X按照上面的规则映射为 Z,那么在新的空间中原来的数据将变成线性可分的,从而使用之前我们推导的线性分类算法就可以进行处理了。这正是Kernel方法处理非线性问题的基本思想。
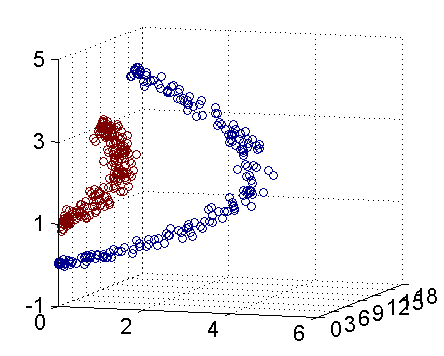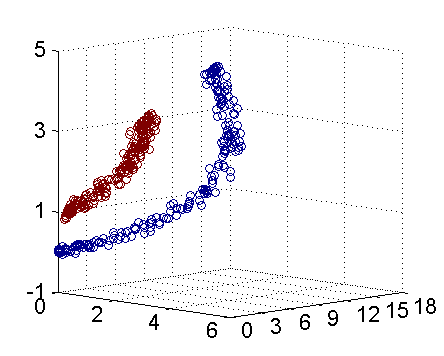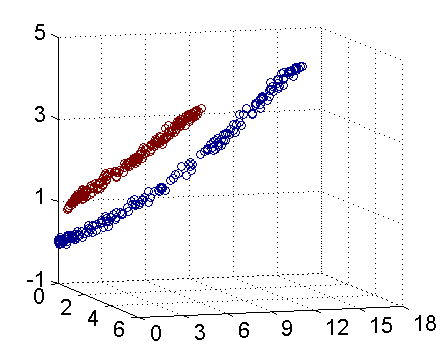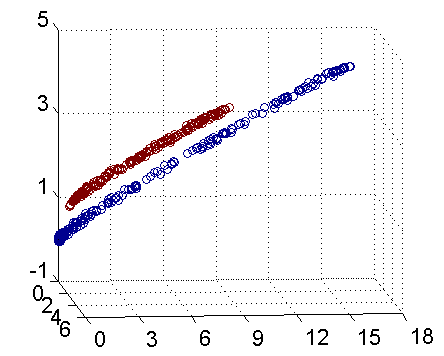
再进一步描述 Kernel 的细节之前,不妨再来看看上述例子在映射过后的直观形态。当然,我们无法将五维空间画出来,不过由于我这里生成数据的时候用了特殊的情形,所以这里的超平面实际的方程是这个样子的(圆心在X2轴上的一 个正圆):

因此我只需要把它映射到下面这样一个三维空间中即可:

下图即是映射之后的结果,将坐标轴经过适当的旋转,就可以很明显的看出,数据是可以通过一个平面来分开的
核函数相当于把原来的分类函数:
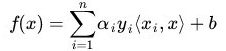
映射成:
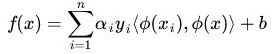
而其中的 α 可以通过求解如下 dual 问题而得到的:

这样一来问题就解决了吗?似乎是的:拿到非线性数据,就找一个映射(Φ(•),然后一股脑把原来的数据映射到新空间中,再做线性SVM即可。不过事实上问题好像没有这么简单)。
细想一下,刚才的方法是不是有问题:
在最初的例子里,我们对一个二维空间做映射,选择的新空间是原始空间的所有一阶和二阶的组合,得到了五个维度;
如果原始空间是三维(一阶,二阶和三阶的组合),那么我们会得到:3(一次)+3(二次交叉)+3(平方)+3(立方)+1(x1 * x2 * x3) + 2*3(交叉,一个一次一个二次,类似 x1*x2^2)=19 维的新空间,这个数目是呈指数级爆炸性增长的,从而势必这给 Φ(•) 的计算带来非常大的困难,而且如果遇到无穷维的情况,就根本无从计算了。
这个时候,可能就需要Kernel出马了。
不妨还是从最开始的简单例子触发,设两个向量为:
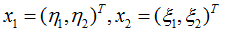
而 Φ(•) 即是前面说的五维空间的映射,因此映射过后的内积为:
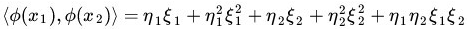
(公式说明:上面的这两个推导过程中,所说的前面的五维空间的映射,这里说的便是前面的映射方式,回顾下之前的映射规则,再看看那个长的推导式,其实就是计算x1,x2各自的内积,然后相乘相加即可,第二个推导则是直接平方,去掉括号,也很容易推出来)
另外,我们又注意到:
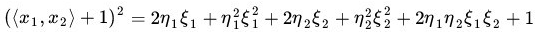
二者有很多相似的地方,实际上,我们只要把某几个维度线性缩放一下,然后再加上一个常数维度,具体来说,上面这个式子的计算结果实际上和映射
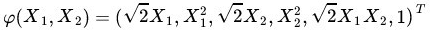
之后的内积 <Φ(xi • Φ(x)> 的结果是相等的,那么区别在什么地方呢?
- 1,一个是映射到高维空间中,然后再根据内积的公式进行计算
- 2,另一个则直接在原来的低维空间中进行计算,而不需要显式地写出映射后的结果
(公式说明:上面之中,最后的两个式子,第一个算式,是带内积的完全平方式,可以拆开,然后,再通过凑一个得到,第二个算式,也是根据第一个算式凑出来的)
回想刚才提到的映射的维度爆炸,在前一种方法已经无法计算的情况下,后一种方法却依旧能从容处理,甚至是无穷维度的情况也没有问题。
我们把这里的计算两个向量在隐式映射过后的空间中的内积的函数叫做核函数(kernel Function),例如,在刚才的例子中,我们的核函数为:

核函数能简化映射空间中的内积运算——刚好“碰巧”的是,在我们的SVM里需要计算的地方数据向量总是以内积的形式出现的。对比刚才我们上面写出来的式子,现在我们的分类函数为:

其中 α 由如下 dual 问题计算而得:

这样一来计算的问题就算解决了,避免了直接在高维空间中进行计算,而结果却是等价的!当然,因为我们这里的例子非常简单,所以可以手工构造出对应于 Φ(•) 的核函数出来,如果对于任意一个映射,想要构造出对应的核函数就非常困难了。
6,核函数的本质
下面概况一下核函数的意思:
- 1,实际上,我们会经常遇到线性不可分的样例,此时,我们的常用做法是把样例特征映射到高位空间中去(比如之前有个例子,映射到高维空间后,相关特征便被分开了,也就达到了分类的目的)
- 2,进一步,如果凡是遇到线性不可分的样例,一律映射到高维空间,那么这个维度大小是会高到可怕的(甚至是无穷维),所以核函数就隆重出场了,核函数的价值在于它虽然也是将特征进行从低维到高维的转换,但核函数绝就绝在它事先在低维上进行计算,而将实质上的分类效果表现在了高维上,也就是上文所说的避免了直接在高维空间中的复杂计算。
下面引用这个例子距离下核函数解决非线性问题的直观效果。
假设现在你是一个农场主,圈养了一批羊群,但为了预防狼群袭击羊群,你需要搭建一个篱笆来把羊群圈起来。但是篱笆应该建在哪里呢?你很可能需要依据羊群和狼群的位置搭建一个“分类器”,比如下图这几种不同的分类器,我们可以看到SVM完成了一个很完美的解决方案。
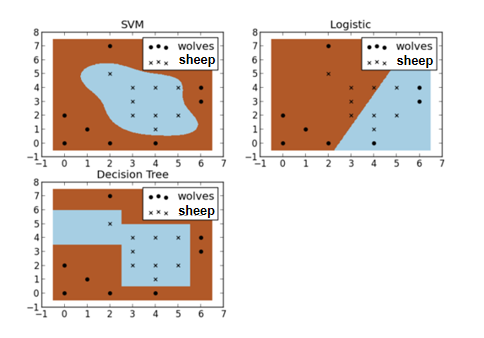
这个例子侧面简单说明了SVM使用非线性分类器的优势,而逻辑模式以及决策树模式都是使用了直线方法。
7,几种常见的核函数
核函数有严格的数学要求,所以设计一个核函数是非常困难的,科学家们经过很多很多尝试也就只尝试出来几个核函数,所以我们就不要在这方面下无用功了,直接拿这常见的几个核函数使用就OK。
下面来分别学习一下这几个常见的核函数。
7.1 线性核(Linear Kernel )
基本原理:实际上就是原始空间中的内积

这个核存在的主要目的是使得“映射后空间中的问题” 和 “映射前空间中的问题” 两者在形式上统一起来了(意思是说:我们有的时候,写代码或者写公式的时候,只要写个模板或者通用表达式,然后再代入不同的核,便可以了。于此,便在形式上统一了起来,不用再找一个线性的和一个非线性的)
线性核,主要用于线性可分的情况,我们可以看到特征空间到输入空间的维度是一样的。在原始空间中寻找最优线性分类器,具有参数少速度快的优势。对于线性可分数据,其分类效果很理想。因此我们通常首先尝试用线性核函数来做分类,看看效果如何,如果不行再换别的。
优点:
- 方案首选,奥多姆剃刀定理
- 简单,可以快速解决一个QP问题
- 可解释性强:可以轻易知道哪些feature是重要的
限制:
- 只能解决线性可分问题
7.2 多项式核(Polynomial Kernel)
基本原理:依靠升维使得原本线性不可分的数据线性可分。

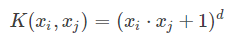
多项式核函数可以实现将低维的输入空间映射到高维的特征空间。多项式核适合于正交归一化(向量正交且模为1)数据,属于全局核函数,允许相距很远的数据点对核函数的值有影响。参数d越大,映射的维度越高,计算量就会越大。
优点:
- 可解决非线性问题
- 可通过主观设置Q来实现总结的预判
缺点:
- 多项式核函数的参数多,当多项式的阶数d比较高的是,由于学习复杂性也会过高,易出现“过拟合”现象,核矩阵的元素值将趋于无穷大或者无穷小,计算复杂度会大道无法计算。
7.3 高斯核(Gaussian Kernel)/ 径向基核函数(Radial Basis Function)
径向基核函数是SVM中常用的一个核函数。径向基函数是一个采用向量作为自变量的函数,能够基于向量距离运算输出一个标量。
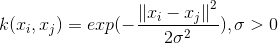
也可以写成如下格式:
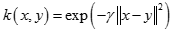
径向基函数是指取值仅仅依赖于特定点距离的实值函数,也就是:

任意一个满足上式特性的函数 Φ 都叫径向量函数,标准的一般使用欧氏距离,尽管其他距离函数也是可以的。所以另外两个比较常用的核函数,幂指数核,拉普拉斯核也属于径向基核函数。此外不太常用的径向基核还有ANOVA核,二次有理核,多元二次核,逆多元二次核。
高斯径向基函数是一种局部性强的核函数,其可以将一个样本映射到一个更高维的空间内,该核函数是应用最广的一个,无论大样本还是小样本都有比较好的性能,而且其相对于多项式核函数参数要少,因此大多数情况下在不知道用什么样的核函数的时候优先使用高斯核函数。
径向基核函数属于局部核函数,当数据点距离中心点变远时,取值会变小。高斯径向基核对数据中存在的噪声有着较好的抗干扰能力,由于其很强的局部性,其参数决定了函数作用范围,随着参数 σ 的增大而减弱。
优点:
- 可以映射到无线维
- 决策边界更为多样
- 只有一个参数,相比多项式核容易选择
缺点:
- 可解释性差(无限多维的转换,无法算出W)
- 计算速度比较慢(当解决一个对偶问题)
- 容易过拟合(参数选不好时容易overfitting)
上述所讲的径向核函数表达式:
幂指数核(Exponential Kernel)
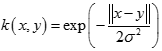
拉普拉斯核(LaplacIan Kernel)
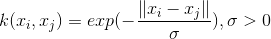
ANOVA 核(ANOVA Kernel)
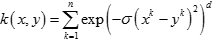
二次有理核(Rational Quadratic Kernel)
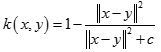
多元二次核(Multiquadric Kernel)
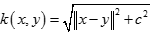
逆多元二次核(Inverse Multiquadric Kernel)
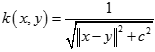
7.4 Sigmoid核
Sigmoid核函数来源于神经网络,被广泛用于深度学习和机器学习中
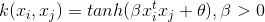
采用Sigmoid函数作为核函数时,支持向量机实现的就是一种多层感知器神经网络,应用SVM方法,隐含层节点数目(它确定神经网络的结构),隐含层节点对输入节点的权重都是在设计(训练)的过程中自动确定的。而且支持向量机的理论基础决定了它最终求得的是全局最优值而不是局部最优值,也保证了它对未知样本的良好泛化能力而不会出现过学习线性。
8,核函数的选择
8.1,先验知识
利用专家的先验知识预先选定核函数
8.2,交叉验证
采取Cross-Validation方法,即在进行核函数选取时,分别试用不同的核函数,归纳误差最小的核函数就是最好的核函数。如针对傅里叶核,RBF核,结合信号处理问题中的函数回归问题,通过仿真实验,对比分析了在相同数据条件下,采用傅里叶核的SVM要比采用RBF核的SVM误差小很多。
8.3,混合核函数
采用由Smits等人提出的混合核函数方法,该方法较之前两者是目前选取核函数的主流方法,也是关于如何构建核函数的又一开创性的工作,将不同的核函数结合起来后有更好的特性,这是混合核函数方法的基本思想。
8.4,经验
当样本特征很多时,特征的维度很高,这是往往样本线性可分,可考虑用线性核函数的SVM或者LR(如何不考虑核函数,LR和SVM都是线性分类算法,也就是说他们的分类决策面都是线性的)
当样本的数量很多,但特征较少时,可以手动添加一些特征,使样本线性可分,再考虑用线性核函数的SVM或者LR
当样本特征维度不高时,样本数量也不多时,考虑使用高斯核函数(RBF核函数的一种,指数核函数和拉普拉斯核函数也属于RBF核函数)
8.5,吴恩达给出的选择核函数的方法
如果特征的数量大道和样本数量差不多,则选用LR或者线性核的SVM
如果特征的数量小,样本的数量正常,则选用SVM+ 高斯核函数
如果特征的数量小,而样本的数量很大,则需要手工添加一些特征从而变成第一种情况
8.6 核函数选择的例子
这里简单说一下核函数与其他参数的作用(后面会详细学习关于使用Sklearn学习SVM):
- kernel='linear' 时,C越大分类效果越好,但有可能会过拟合(default C=1)
- kernel='rbf'时,为高斯核,gamma值越小,分类界面越连续;gamma值越大,分类界面越“散”,分类效果越好,但有可能会过拟合。
我们来看一个简单的例子,数据为[-5.0 , 9.0] 的随机数组,函数如下 :
![]()
下面分别使用三种核SVR:两种乘法系数高斯核rbf和一种多项式核poly。代码如下:
from sklearn import svm
import numpy as np
from matplotlib import pyplot as plt
import warnings
warnings.filterwarnings('ignore')
X = np.arange(-5.0 , 9.0 , 0.1)
# print(X)
X = np.random.permutation(X)
# print('1X:',X)
X_ = [[i] for i in X]
b = 0.5
y = 0.5 * X ** 2.0 + 3.0 * X + b + np.random.random(X.shape) * 10.0
y_ = [i for i in y]
# degree = 2 , gamma=, coef0 =
rbf1 = svm.SVR(kernel='rbf',C=1,)
rbf2 = svm.SVR(kernel='rbf',C=20,)
poly = svm.SVR(kernel='poly',C=1,degree=2)
rbf1.fit(X_ , y_)
rbf2.fit(X_ , y_)
poly.fit(X_ , y_)
result1 = rbf1.predict(X_)
result2 = rbf2.predict(X_)
result3 = poly.predict(X_)
plt.plot(X,y,'bo',fillstyle='none')
plt.plot(X,result1,'r.')
plt.plot(X,result2,'g.')
plt.plot(X,result3,'b.')
plt.show()
结构图如下:

蓝色是poly,红色是c=1的rbf,绿色c=20的rbf。其中效果最好的是C=20的rbf。如果我们知道函数的表达式,线性规划的效果更好,但是大部分情况下我们不知道数据的函数表达式,因此只能慢慢实验,SVM的作用就在这里了。
9,总结
支持向量机是一种分类器。之所以称为“机”是因为它会产生一个二值决策结果,即它是一种决策“机”。支持向量机的泛化错误率较低,也就是说它具有良好的学习能力,且学到的结果具有很好的推广性。这些优点使得支持向量机十分流行,有些人认为它是监督学习中最好的定式算法。
支持向量机视图通过求解一个二次优化问题来最大化分类间隔。在过去,训练支持向量机常采用非常复杂并且低效的二次规划求解方法。John Platt 引入了SMO算法,此算法可以通过每次只优化2个 α 值来加快SVM的训练速度。
核方法或者说核技巧会将数据(有时候是非线性数据)从一个低维空间映射到一个高维空间,可以将一个在低维空间中的非线性问题转化为高维空间下的线性问题来求解。核方法不止在SVM中适用,还可以用于其他算法。而其中的径向基函数是一个常用的度量两个向量距离的核函数。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号